精华液
事实证明,为此只需运行以下命令即可:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
然后用脚本进行后期处理
python3 process_wikipedia.py
结果是完成的.csv文件.csv携带。
很明显:
- 可以将
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2更改为所需的语言,更多详细信息请参见[4] ; - 关于
wikiextractor参数的所有信息都可以在手册中找到(与法术力不同,似乎连官方基座都没有更新);
后处理脚本将Wiki文件转换为如下表:
| IDX | article_uuid | 句子 | 整句 | 整句长度 |
|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon(潘特夫尔伯爵)Jean I de Chatillon ... | 吉恩·德·沙蒂隆伯爵夫人五世 | 38 |
| 1个 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | 在罗伯特·德·维拉的保护下,伯爵O ... | 受到罗伯特·德·维拉·图·牛津的守卫... | 18岁 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | 但是,亨利·德·格罗蒙(Henry de Gromont) | 但是,亨利·德·格罗蒙·格拉斯对此表示反对。 | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | 国王为他提供了妻子的另一个重要特征... | 国王提出了他妻子的另一个重要的身份。 | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | 吉恩于138年获释并返回法国... | 吉恩释放了法国一年的婚礼 | 52 |
article_uuid-伪唯一键,在进行此类预处理后,应保留想法顺序。
为何
也许目前,机器学习工具的开发已达到[8]的水平,从字面上讲,几天就足以建立一个有效的NLP模型/管道。 仅在缺少可靠的数据集/现成的嵌入/现成的语言模型的情况下才会出现问题。 本文的目的是通过证明几个小时就足以处理整个Wikipedia(理论上讲是NLP中训练单词嵌入的最受欢迎的语料库),从而减轻您的痛苦。 毕竟,如果几天就足以建立一个简单的模型,那么为什么要花更多的时间为该模型获取数据呢?
脚本原理
wikiExtractor将Wiki文章另存为以<doc>块分隔的文本。 实际上,该脚本基于以下逻辑:
- 取得输出中所有文件的列表;
- 我们将文件分为文章;
- 删除所有剩余的HTML标签和特殊字符;
- 使用
nltk.sent_tokenize将句子分为几部分; - 为了使代码不会增加到很大的规模并保持可读性,每篇文章都分配了自己的uuid;
作为文本预处理,它很简单(您可以自己轻松剪切):
数据集是什么,现在呢?
主要用途
实际上,在大多数情况下,在NLP中,您必须处理构建嵌入的任务。
要解决此问题,通常使用以下工具之一:
- 现成的矢量/单词嵌入[6];
- CNN的内部状态接受了诸如确定错误句子/语言建模/分类等任务的培训[7];
- 以上方法的结合;
另外,已经多次显示[9],作为嵌入句子的良好基准,人们还可以简单地取平均(带有几个次要细节,现在将省略)。
其他用例
- 我们使用来自Wiki的随机句子作为三元组损失的负面例子;
- 我们使用假短语的定义训练句子的编码器[10];
俄语Wiki的一些图表
俄语维基百科句子的长度分布
无对数(在X轴上,值限制为20)
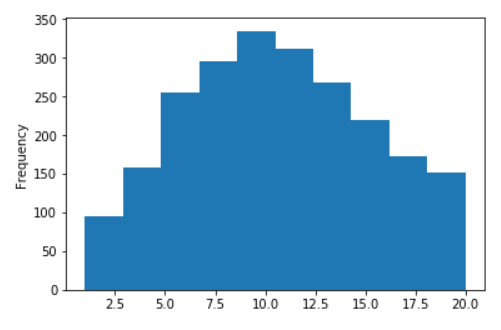
以十进制对数
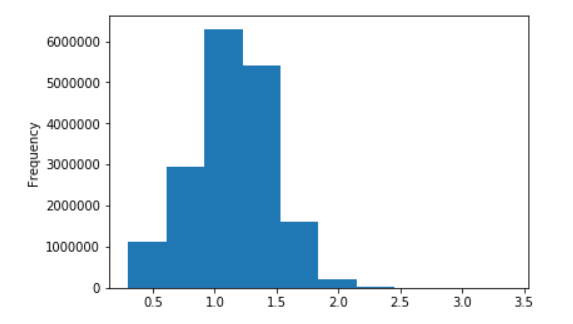
参考文献
- 在Wiki上训练的快速文本词向量 ;
- 俄语的快速文本和Word2Vec 模型 ;
- 很棒的python维基提取器库 ;
- 带有Wiki链接的官方页面 ;
- 我们的后处理脚本 ;
- 有关单词嵌入的主要文章: Word2Vec , 快速文本 , 调优 ;
- 当前的几种SOTA方法:
- 推断 ;
- 生成式预训练 CNN;
- ULMFiT ;
- 语境表示法 (Elmo);
- NLP中的 Imagenet时刻?
- 嵌入提案1,2,3,4的基准;
- 报价编码器伪造词的定义;