我将向您介绍本文第二部分,该部分基于基于Enron Dataset的数据搜索可疑欺诈。 如果您没有阅读第一部分,则可以在这里熟悉它。
现在,我们将讨论构建,优化和选择模型的过程,该模型将给出答案:值得怀疑一个欺诈者吗?
之前,我们分析了一个开放数据集,该数据集提供有关安然案中的嫌疑人及其欺诈的信息。 还纠正了初始数据中的偏差,填充了间隙(NaN),此后将数据标准化并完成了属性选择。
结果为许多人所熟悉:
- X_train和y_train-用于训练的样本(111条记录);
- X_test和y_test-一个样本,将在该样本上检查我们模型的预测的正确性(28个条目)。
说到模型...为了正确地预测一个人是否值得怀疑,我们将根据表征其活动的一些迹象来使用该分类。 解决该问题的主要模型类型可以从Sklearn中获取:
- 朴素贝叶斯(朴素贝叶斯分类器);
- SVM(参考向量机);
- K近邻(查找最近邻居的方法);
- 随机森林(随机森林);
- 神经网络。
还有一张图片很好地说明了它们的适用性:
其中有许多人都熟悉的决策树(决策树),但也许在一项任务中将这种方法与随机森林一起使用是没有意义的,后者是决策树的集合 。 因此,将其替换为Logistic回归,可以用作分类器并产生期望的选项之一(0或1)。
开始
我们使用默认值初始化所有提及的分类器:
from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.neural_network import MLPClassifier from sklearn.ensemble import RandomForestClassifier random_state = 42 gnb = GaussianNB() svc = SVC() knn = KNeighborsClassifier() log = LogisticRegression(random_state=random_state) rfc = RandomForestClassifier(random_state=random_state) mlp = MLPClassifier(random_state=random_state)
我们还将对它们进行分组,以便更方便地将它们作为一个整体来使用,而不是为每个人编写代码。 例如,我们可以一次训练它们:
classifiers = [gnb, svc, knn, log, rfc, mlp] for clf in classifiers: clf.fit(X_train, y_train)
对模型进行训练之后,就该对它们的预测质量进行首次测试了。 另外,我们使用Seaborn可视化我们的结果:
from sklearn.metrics import accuracy_score def calculate_accuracy(X, y): result = pd.DataFrame(columns=['classifier', 'accuracy']) for clf in classifiers: predicted = clf.predict(X_test) accuracy = round(100.0 * accuracy_score(y_test, predicted), 2) classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'accuracy': accuracy}, ignore_index=True) print('Accuracy is {accuracy}% for {classifier_name}'.format(accuracy=accuracy, classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='accuracy', palette=cmap, data=result)
让我们看一下分类器准确性的一般概念:
calculate_accuracy(X_train, y_train)
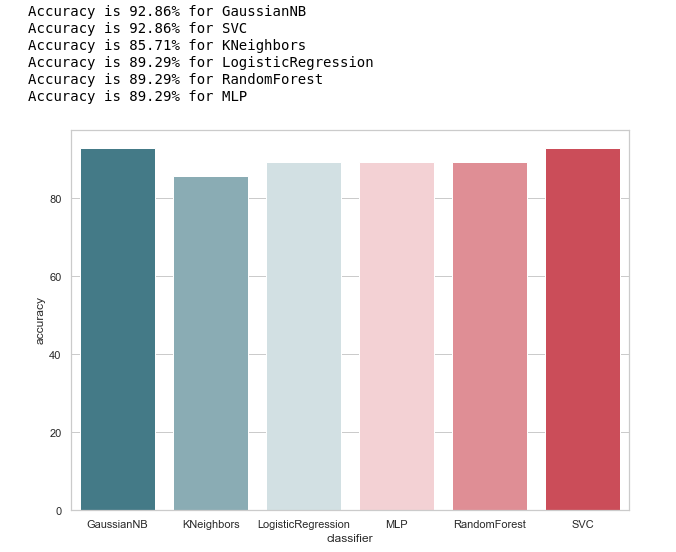
乍一看,它看起来还不错,对测试样本的预测准确性在90%左右波动。 看来任务很出色!
实际上,并非所有事情都如此乐观。高精度并不保证正确的预测。 我们的测试样本有28条记录,其中4条与嫌疑人相关,而24条与那些令人怀疑的记录相关。 想象一下,我们创建了某种形式的算法:
def QuaziAlgo(features): return 0
然后他们在入口处给了我们我们的测试样品,他们得知所有28个人都是清白的。 在这种情况下,算法的准确性如何?
有趣的是,KNeighbors具有相同的预测精度...
但是,在奉承之前,让我们为预测结果建立一个混淆矩阵:
from sklearn.metrics import confusion_matrix def make_confussion_matrices(X, y): matrices = {} result = pd.DataFrame(columns=['classifier', 'recall']) for clf in classifiers: classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') predicted = clf.predict(X_test) print(f'{predicted}-{classifier}') matrix = confusion_matrix(y_test,predicted,labels=[1,0]) matrices[classifier] = matrix.T return matrices
我们计算每个分类器的误差矩阵,并与其一起查看它们的预测结果:
matrices = make_confussion_matrices(X_train,y_train)

即使是分类器工作结果的文本表示,也足以理解明显出问题的地方。
最近邻法完全没有揭示测试样品中的单个可疑物。 出现两个问题:
- KNeighbors分类器出现此行为的原因是什么?
- 如果不使用误差矩阵,而只看预测结果,为什么还要建立误差矩阵?
深入了解
让我们从第二个问题开始。 让我们尝试可视化我们的错误矩阵,并以图形格式显示数据,以了解发生分类错误的位置:
import itertools from collections import Iterable def draw_confussion_matrices(row,col,matrices,figsize = (16,12)): fig, (axes) = plt.subplots(row,col, sharex='col', sharey='row',figsize=figsize ) if any(isinstance(i, Iterable) for i in axes): axes = list(itertools.chain.from_iterable(axes)) idx = 0 for name,matrix in matrices.items(): df_cm = pd.DataFrame( matrix, index=['True','False'], columns=['True','False'], ) ax = axes[idx] fig.subplots_adjust(wspace=0.1) sns.heatmap(df_cm, annot=True,cmap=cmap,cbar=False ,fmt="d",ax=ax,linewidths=1) ax.set_title(name) idx += 1
我们将它们显示为2行3列:
draw_confussion_matrices(2,3,matrices)
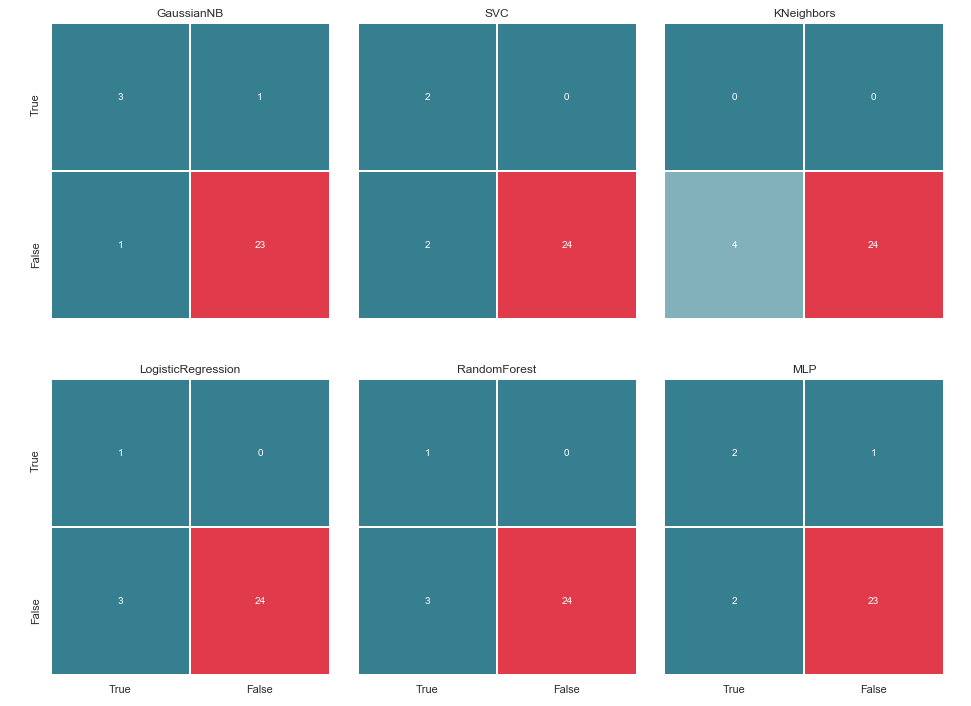
在继续之前,值得澄清一下。 位于特定分类器错误矩阵左侧的名称True,表示分类器认为该人为可疑人,值False表示该人不可怀疑。 类似地,图像底部的对与错为我们提供了真实的事务状态,这可能与分类器的决策不一致。
例如,当分类器将24位毫无疑问的人列入相似列表时,我们可以看到KNeighbors决策的预测准确度为85.71%,与真实情况相符。 但是,从嫌疑犯名单中的4个人也被包括在此名单中。 如果分类者做出决定,也许有人可以避免上法庭。
因此,错误矩阵是了解分类问题出了什么问题的很好的工具。 它们的主要优点是可见度,因此我们吸引他们。
指标
一般而言,可以通过以下图片进行说明:

在这种情况下,TP,TN,FP和某种FN是什么?
换句话说,我们努力确保分类器的答案与实际情况保持一致。 即,确保所有数字都在小区TP和TN之间分配(真解),而不会落入FN和FP(假解)中。
并非每件事总是那么戏剧性和明确例如,在诊断为癌症的典型案例中,FP比FN更为可取,因为在对癌症作出错误判断的情况下,将为患者开处方药并接受治疗。 是的,这将影响他的健康和钱包,但仍然被认为不如FN危险,而且错过了可以通过小手段战胜癌症的错过时期。
那我们案中的嫌疑人呢? FN可能不如FP差。 但是稍后会更多...
既然我们在谈论缩写,是时候回顾准确性(Precision)和完整性(Recall)的指标了。
如果您偏离正式记录,那么Precision可以表示为:
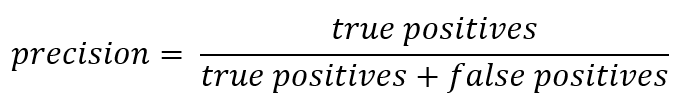
换句话说,记录了从分类器接收到的正确回答有多少是正确的。 准确性越高,错误命中的次数就越少(如果没有FP,则准确性为1)。
召回通常表示为:
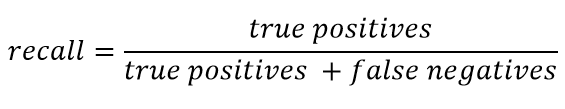
回忆是表征分类器“猜测”尽可能多的肯定答案的能力。 完整性越高,FN越低。
通常,他们会尝试在两者之间取得平衡,但在这种情况下,优先级将完全交给Precision。 原因是:采用更人性化的方法,希望减少误报的数量,从而避免对无辜者的怀疑。
我们为分类器计算Precision:
from sklearn.metrics import precision_score def calculate_precision(X, y): result = pd.DataFrame(columns=['classifier', 'precision']) for clf in classifiers: predicted = clf.predict(X_test) precision = precision_score(y_test, predicted, average='macro') classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'precision': precision}, ignore_index=True) print('Precision is {precision} for {classifier_name}'.format(precision=round(precision,2), classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='precision', palette=cmap, data=result) calculate_precision(X_train, y_train)
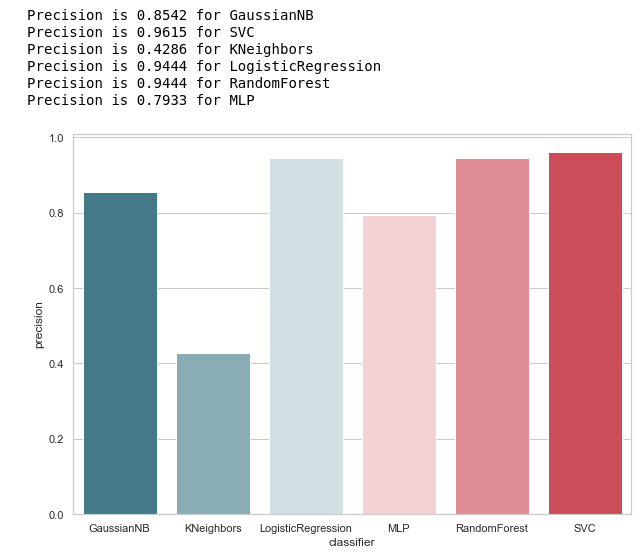
从图中可以看出,结果出乎意料:由于TP值最低,因此KNeighbors精度最低。
同时,有一篇很好的文章介绍了有关哈布雷(Habré)指标的信息,那些想深入研究该主题的人应该熟悉它。
超级参数选择
找到最适合所选条件的度量标准(减少FP的数量)之后,我们可以回到第一个问题:KNeighbors分类器的这种行为是什么原因?
原因在于创建此模型的默认设置。 而且,很可能有很多人会惊叹于这个阶段:为什么要训练默认参数? 有特殊的选择工具,例如常用的GridSearchCV。
是的,现在该到了诉诸它的时候了,
但在此之前,我们从列表中删除了贝叶斯分类器。 它允许一个FP,并且与此同时,该算法不接受任何可变参数,因此结果不会改变。
classifiers.remove(gnb)
微调
我们为每个分类器定义一个参数网格:
parameters = {'SVC':{'kernel':('linear', 'rbf','poly'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'KNeighbors':{'algorithm':('ball_tree', 'kd_tree'), 'n_neighbors':[i for i in range(2,20)]}, 'LogisticRegression':{'penalty':('l1', 'l2'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'RandomForest':{'n_estimators':[i for i in range(10,101,10)],'random_state': (random_state,)}, 'MLP':{'activation':('relu','logistic'),'solver':('sgd','lbfgs'),'max_iter':(500,1000), 'hidden_layer_sizes':[(7,),(7,7)],'random_state': (random_state,)}}
此外,我想注意MLP中的层/神经元数量。
决定不通过详尽搜索所有可能的值来设置它们,而是仍然基于以下公式 :
我想马上说,仅对训练样本进行训练和交叉验证。 我认为您可以对所有数据执行此操作,就像使用Iris Dataset的示例一样 。 但是,在我看来,这种方法并不完全合理,因为不可能信任测试样品的验证结果。
我们将进行优化,并用改进后的版本替换分类器:
from sklearn.model_selection import GridSearchCV warnings.filterwarnings('ignore') for idx,clf in enumerate(classifiers): classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') params = parameters.get(classifier) if not params: continue new_clf = clf.__class__() gs = GridSearchCV(new_clf, params, cv=5) result =gs.fit(X_train, y_train) print(f'The best params for {classifier} are {result.best_params_}') classifiers[idx] = result.best_estimator_

选择评估指标并执行GridSearchCV之后,我们准备绘制最后一行。
总结一下
误差矩阵v.2
matrices = make_confussion_matrices(X_train,y_train) draw_confussion_matrices(1,2,first_row,figsize = (10.5,6)) draw_confussion_matrices(1,3,second_row,figsize = (16,6))

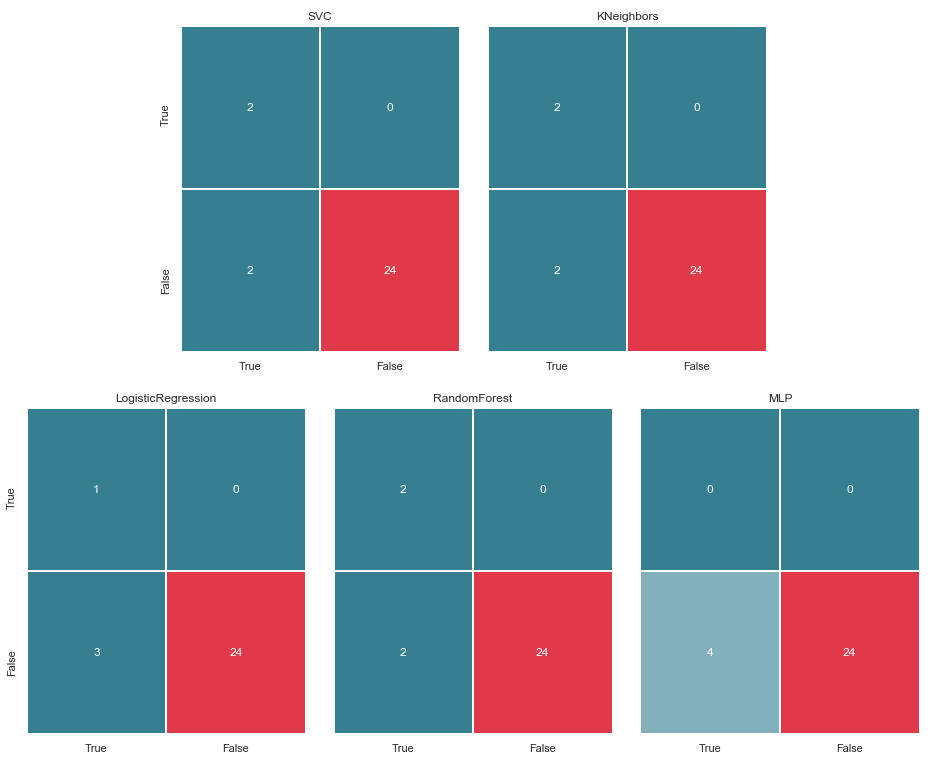
从矩阵中可以看出,MLP表现出降解,并认为测试样品中没有可疑物质。 随机森林获得了准确性,并纠正了假阴性和真阳性的参数。 KNeighbors的预测有所改善。 对其他人的预测没有改变。
准确性v.2
现在,我们目前的分类器都没有误报错误,这是个好消息。 但是,如果我们用数字语言来表示所有内容,则会得到以下图片:
calculate_precision(X_train, y_train)
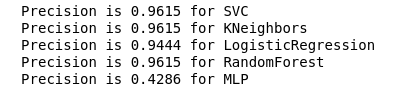
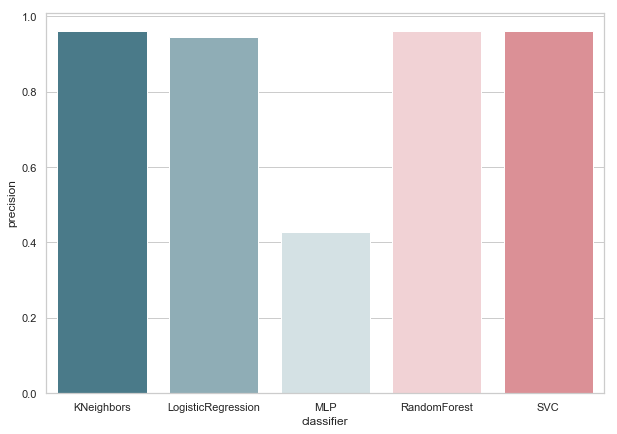
确定了3个具有最高Precision得分的分类器。 根据误差矩阵,它们具有相同的值。 选择哪个分类器?
谁更好?
在我看来,这是一个相当困难的问题,没有一个普遍的答案。 但是,在这种情况下,我的观点将如下所示:
1.分类器的技术实施应尽可能简单。 这样,他的再培训风险就会降低(可能是MLP发生这种情况)。 因此,这不是随机森林,因为该算法是30棵树的集合,因此依赖于它们。 与Python Zen的思想之一相呼应:简单胜于复杂。
2.算法直观时还不错。 也就是说,与具有潜在多维空间的SVM相比,KNeighbors的感知更为简单。
反过来,这又类似于另一种说法:显式优于隐式。
因此,我认为具有3个邻居的KNeighbors是最佳候选人。
这是第二部分的结尾,描述了使用安然数据集作为机器学习中分类任务的示例。 基于Udacity的机器学习入门课程的材料。 还有一个python笔记本,反映了整个描述的操作顺序。