
再次问好,Alexey Pristavko与我们联系,这是我有关基于Cloudian HyperStore的S3对象存储DataLine的故事的第二部分。
今天,我将详细讨论S3存储的安排方式以及在创建过程中遇到的困难。 确保触及“铁”主题并分析我们最终使用的设备。
走吧
如果在阅读期间您希望了解Cloudian解决方案的应用程序体系结构,则可以在
上一篇文章中找到其详细分析。 在这里,我们详细讨论了Cloudian内部设备,容错能力和内置SDS的逻辑。
物理设备的最终方案
从此以后,我们将讨论“选择的折磨”,我将立即给出最终的铁清单。 小小的免责声明:网络设备的选择主要是由于它存在于我们的仓库(非常可靠)中。
因此,在存储的物理级别上,我们具有以下设备:
名称
| 功能介绍
| 构型
| 数量
|
Lenovo System x3650 M5服务器
| 工作节点
| 1个Xeon E5-2630v4 2.2GHz,
4个16GB DDR4,
14个10TB 7.2K 6Gbps SATA 3.5英寸,
2个480GB SSD,
英特尔x520双端口10GbE SFP +,
2x750W HS PSU
| 4
|
HP ProLiant DL360 G9服务器
| 负载均衡器节点
| 2个E5-2620 v3,
128G RAM,
2 600 GB SSD,
4个SAS硬盘
英特尔x520双端口10GbE SFP +
| 2
|
思科C4500交换机
| 边界网关
| 催化剂WS-C4500X-16SFP +
| 2
|
思科C3750交换机
| 端口扩展器
| 带有C3KX-NM-10G的催化剂WS-C3750X-24T
| 2
|
思科C2960交换机
| 控制平面
| 催化剂WS-C2960 + 48PST-L
| 1个
|
为了更好地了解体系结构,我们将依次查看所有元素,并讨论它们的功能和任务。
让我们从服务器开始。 Lenovo服务器具有特殊配置,可以共同实施并完全符合Cloudian的建议和规范。 例如,他们使用具有直接磁盘访问权限的控制器。 由于在我们的案例中,RAID是在应用程序软件级别组织的,因此此模式提高了可靠性并加快了磁盘子系统的速度。 可以将完全相同的服务器连同所有许可证一起购买为Cloudian Appliance。
带有Nginx for CentOS的负载平衡服务器可确保在工作节点上均匀分配负载,并从内部流量组织中提取用户。 作为一项令人愉悦的奖励-如有必要,您可以在它们上组织一个缓存。
Cisco 4500X 16个10GB SFP +对是我们小型但引以为傲的存储网络的核心和边界。 当然,铁有些陈旧,但在可靠性方面并不逊色于“新”铁,它具有内部冗余,其功能可以满足我们的所有要求。 C3750发挥了工厂扩展的作用,无需将1G收发器推入10G插槽。 完全切换到10GB链接也没有多大意义。 如测试所示,我们较早地遇到了处理器和磁盘。
下图充分详细地说明了我描述的物理组织:
 1.物理存储组织方案
1.物理存储组织方案让我们来看看这个方案。 如您所见,通过将每个设备复制并连接到至少两个光链路来实现物理级别的容错,每个光链路成对存在。 这为我们保证了在任何网络设备或来自不同对的两个设备同时发生故障时电路中保持物理连接。
我们按照计划进行。 两个思科对(4500 / 4500、3750 / 3750)使用堆栈和VSS组合为单个逻辑设备。 堆栈通过两条10G光学链路和两条堆栈电缆VSS组装在一起。 这使您可以确保每对中的两个设备作为一个整体进行交互。 这种群集使我们能够通过一对两个设备在一个透明的L2网段的框架内工作,并使用LACP进行常规的链路聚合,因为服务器OS和Cisco IOS都原生支持此技术。 从服务器端看来,它正在使用一个交换机而不是两个交换机,并且在应用程序上方是一个聚合容量为两倍的聚合通道。
所有网络设备在其自身与传入信道之间的切换都是使用10G光纤链路完成的,服务器设备是使用10G Twinax Cisco电缆和1G铜缆连接的。
BGP用于传入通道的容错,而Round Robin DNS用于平衡外部IP地址。 外部地址本身停放在负载平衡服务器上,并且如有必要,可以使用Pacemaker / Corosync捆绑包在节点之间迁移。
通过IPMI进行监视和控制是通过直接的内部链接进行的。 所有管理接口(服务器和Cisco)均通过单独的控制平面交换机连接。 它们又包含在数据中心控制网络中。 这保证了我们在工作期间或由于外部网络事故而无法与设备通信的情况。 在最极端的情况下,KVM会有服务员。
逻辑网络
为了了解DataLine存储的S3逻辑网络如何工作,让我们转向另一种方案:
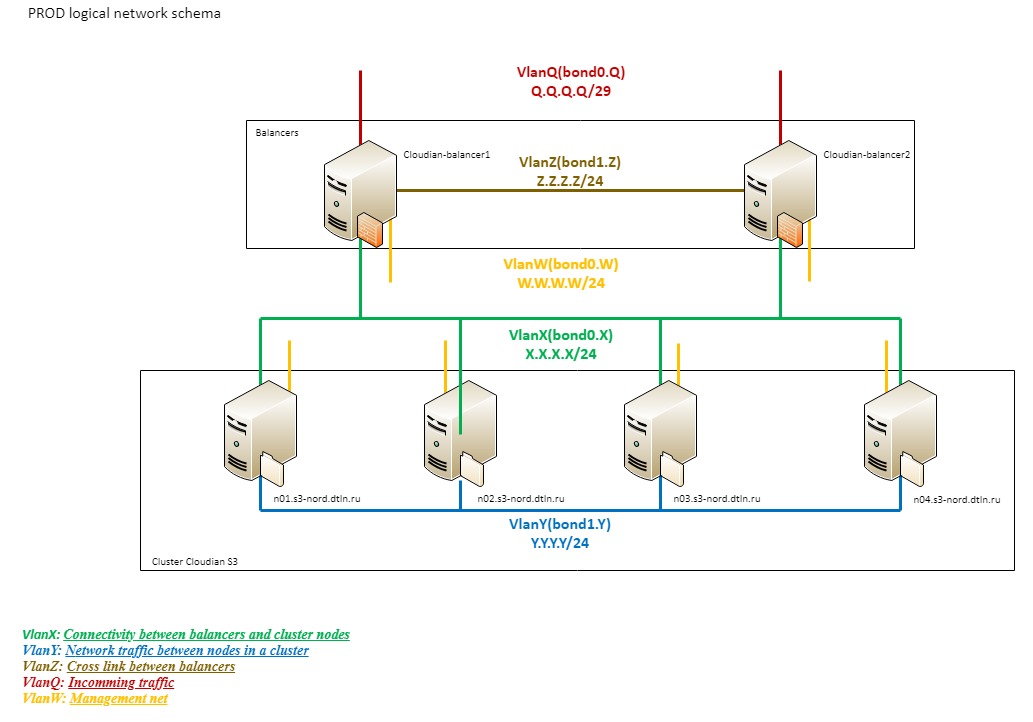 2.存储逻辑网络图
2.存储逻辑网络图如您所见,网络逻辑由几个部分组成。
总容量为20G的外部网络(Q)直接连接到提供商边缘。 其次是Cisco 4500和平衡器。
下一个逻辑块(X)是平衡器和工作节点之间的VLAN。 平衡器使用与传入流量相同的连接。 工作节点通过3750堆栈与4条1G链路连接(每个3750有2条链路)。 使用LACP,所有物理链接也被组装成一个逻辑链接。 该网络仅用于处理客户端流量。
Cloudian(Y)群集中的所有连接都经过基于10G的第三个逻辑段。 这样的组织有助于避免内部流量引起的外部通道问题,反之亦然。 对于集群的运行而言,这是一个极为重要的环节。 正是通过它复制了数据和元数据,再平衡过程等都使用了它,因此,我们将其“不可沉”性区分为单独的任务。
一点美
这就是一切的样子:
 3.网络设备和平衡器全面
3.网络设备和平衡器全面 4.相同,后视图
4.相同,后视图注意切换。 在以前的文章中,我的同事们谈到了彩色标记电缆的重要性,但是在这里接触这个主题并非没有错。
我们不仅将颜色切换用于网络,还将其用于电源。 这使我们的工程师可以在机架中快速导航,并减少切换过程中人为因素的影响。
 5.工作节点
5.工作节点 6.后视图
6.后视图在这张照片中,您可以清楚地看到正在工作的服务器被磁盘充满的程度-实际上,即使在背面也没有空插槽。 顺便说一下,将电缆组织成紧凑的束不仅可以起到美观的作用,而且还可以避免电源风扇重叠,从而避免铁过热。
白名单
在上一篇文章的评论中,我答应谈论更多有关白名单设备的信息。
如果出于某种原因,我们与客户达成协议,从数据中心内部或通过直接渠道连接到其设备,将与该存储区有关的所有工作从帐户中排除,那么我们需要组织一个到该存储区的专用连接。
还记得吗,在第一个图中,DIST和Cloud上有一个分支? 除了主要的20Gb Internet通道之外,我们还使用聚合通道来进行交换,在数据中心级别,所有客户端都连接到该通道。 如果客户端需要直接链接到存储,我们可以配置从客户端到4500X的VLAN,并构建一条单独的路由(或不使用它),然后启动L3。 之后,将在Cloudian本身已经存在的客户地址上配置与费率计划的绑定。 然后,对于与该资费计划相关的每个人,将不考虑使用白名单地址中的S3。
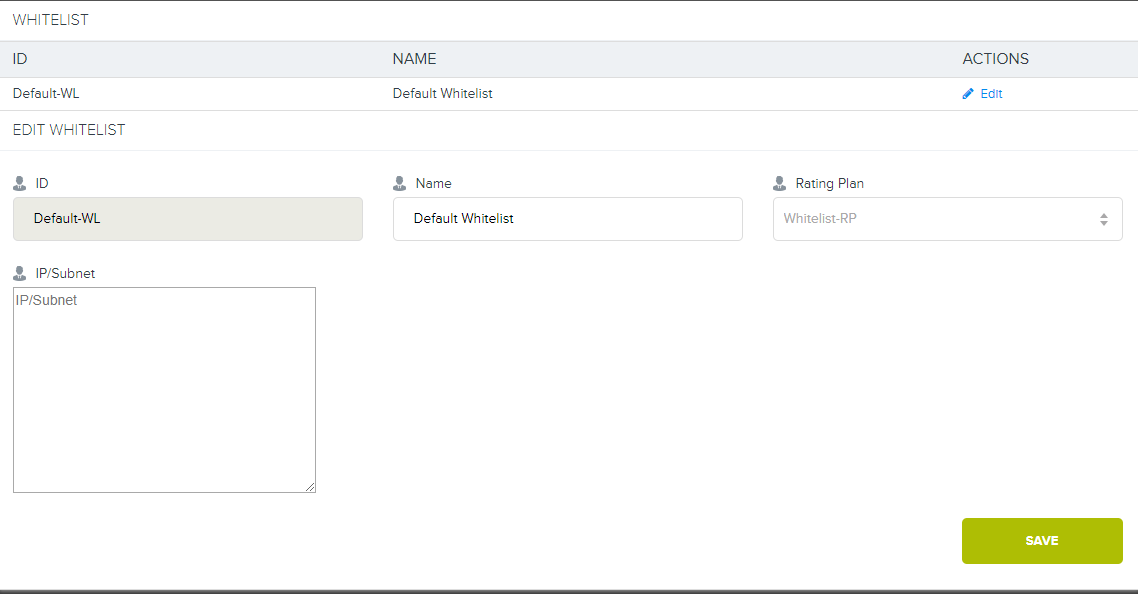 7.这是Cloudian中的特殊界面。
7.这是Cloudian中的特殊界面。现在,我们在电网中没有这样的关税,但是如果您确实愿意,我们可以提供。
施工历史
我们正在逐步接近历史上最有趣的部分-仓储设施的建设。 将会有很多照片,最多有3种尝试来组织流量平衡的尝试和一些错误提示。 我希望对我们在途中遇到的问题进行分析将对准备使用10Gb +速度的网络用户有用。
试用10G
在直接介绍本节的要点之前,我允许自己提出另一个小的免责声明。
按照既定的传统,在购买新的辅助设备之前,我们去仓库并选择或多或少合适的组件。 这使您可以快速进行测试并确定将来的购物清单。 当然,虽然我们没有达到100%的可靠结果,但在生产上却没有花任何钱。
就是这个时候。 如果思科不出意外,那么负载平衡器的“贪婪”几乎毁了我们。
初次体验。 超微服务器
在这里,我们以最小的成本进行快速测试的愿望而感到失望。 在仓库中,我们发现Supermicro服务器除了缺少SFP接口外,其他一切都很好。 我们决定在上面安装我们心爱的Intel 520DA2,并立即面临第一个问题:这些机器是单单元的,但是没有提升板。 同时,由于某种原因,我们的部队不在兼容性列表中,但是有很多本地上升者。
在创新开发总监Misha Solovyov的建议下,我们将所有产品与采矿场的柔性立管连接起来。 结果就是这样的“尸体”:
 8. 1号原型
8. 1号原型我不得不在某些地方使用著名的蓝色电工胶带,所以,上帝禁止,做任何简短的事情。 是的,集体农场。 是的,as愧。 但是这种“配置”在实验期间是完全可以接受的。
 9.后视图
9.后视图在iperf的屏幕截图中可以清楚地看到这些内容:
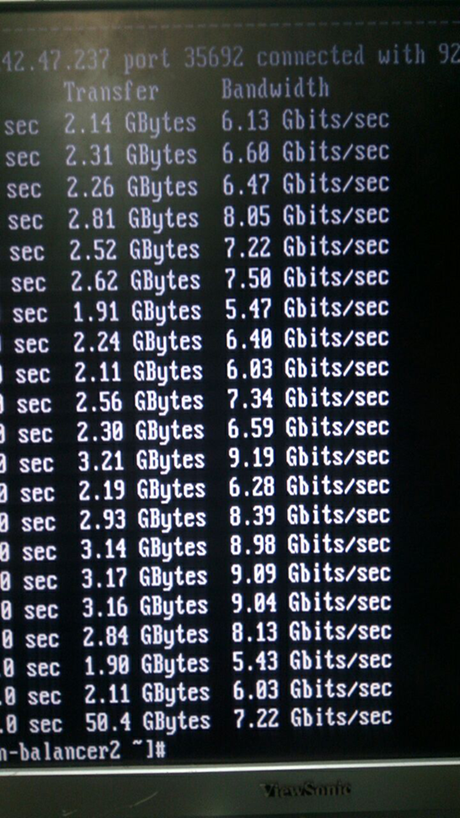 10.实际上这不是屏幕截图:)
10.实际上这不是屏幕截图:)指标非常有趣,对不对? 所以我们很难过。 起初,我们想到了间谍筹码,我们拆散并整理了所有东西。
 11.乍一看,这里没有间谍筹码
11.乍一看,这里没有间谍筹码他们回想起物理过程:电磁干扰,高频信号等。当然,以这样的数量和质量的“集体农场”继续进行实验是没有意义的。 因此,我们最终分解了系统,并将服务器放回原处。
第二次经验。 Citrix Netscaler MPX8005
在将服务器退还给该地点的过程中,我们发现了新的英雄:Citrix Netscaler MPX8005。 此外,这是一款绝妙的烙铁,几乎从未使用过。 他们看起来像这样:
 12.机架中的幻灯片的长度不合适,但是我们有远见的决定将其推迟到以后
12.机架中的幻灯片的长度不合适,但是我们有远见的决定将其推迟到以后将设备放在机架中,进行交换和配置。 这些是非常出色的“成人”铁片,每个有2个SFP插槽,每个10GB,HA,高级算法,甚至还有L7。 没错,根据许可,最多可容纳5吉比特,但我们仍使用L3,但没有这样的限制。
交叉手指,测试。 没有速度。 在接口上-有关不合适的收发器的可靠错误,约5吉比特的速度,不断下降。 他们想起了柔软的立管,再次感到难过。 即使在那儿,速度也更高,错误更少。 我们开始了解:
show channel LA/1 1) Interface LA/1 (802.3ad Link Aggregate) #10 flags=0x4100c020 <ENABLED, UP, AGGREGATE, UP, HAMON, HEARTBEAT, 802.1q> MTU=9000, native vlan=1, MAC=XXX, uptime 0h03m23s Requested: media NONE, speed AUTO, duplex NONE, fctl NONE, throughput 160000 Link Redundancy Throughput 80000 Actual: throughput 20000 LLDP Mode: NONE RX: Pkts(9388) Bytes(557582) Errs(0) Drops(1225) Stalls(0) TX: Pkts(10514) Bytes(574232) Errs(0) Drops(0) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) bandwidthHigh: 160000 Mbits/sec, bandwidthNormal: 160000 Mbits/sec. LA mode: AUTO > show interface 10/1 1) Interface 10/1 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #1 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m44s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8921) Bytes(517626) Errs(0) Drops(585) Stalls(0) TX: Pkts(9884) Bytes(545408) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set. > show interface 10/2 1) Interface 10/2 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #0 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m58s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8944) Bytes(530975) Errs(0) Drops(911) Stalls(0) TX: Pkts(10819) Bytes(785347) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set.
我们使用了本地Cisco收发器,从理论上讲,不会出现任何问题。 他们甚至检查了光学器件,以防万一更换了收发器-相同的图片。 我们的车没走,就是这样! 我们仔细观察。
“美丽”的思科收发器:
ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CISCO-AVAGO , part number XXX , 10G 0x10 1G 0x00 CT 0x00 *** Unsupported SFP+/SFP type!
无法正常检测收发器,不受支持!
我必须找到最“亲戚”:
 13.荒野西部最原始的收发器
13.荒野西部最原始的收发器 ix0: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe020-0xe03f mem 0xf7820000-0xf783ffff,0xf7844000-0xf7847fff irq 16 at device 0.0 on pci1 platform: Manufacturer Citrix Inc. platform: NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 675320 (28), manufactured at 8/10/2015 platform: serial 4NP602H7H0 platform: sysid 675320 - NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 ix0: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00 ix0: [ITHREAD] 10/2: Ethernet address: 00:e0:ed:45:39:f8 ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00
确定这些收发器没有任何问题,但这并不能挽救局面。 更新的固件-同样。 Citrix支持决定保持机密(不,不是因为收发器的血统)。
我们深呼吸,沉迷于硬件规格中。 原来,一直以来的答案都在我们的眼前:
ixgbe总线速度= 5.0Gbps,PCIe通道宽度=8。这是该卡的问题。 她本人缺乏PCIe速度。 对于所有带有
5.0Gbps收发器的卡,我们的Citrix具有PCI-e插槽的最高性能
,他一直向我们喊着。 就像Citrix在MPX8015上一样(硬件上完全相同!),他们希望提供15吉比特的存储容量,目前尚不清楚。 但是我们知道为什么这些“平衡式”平衡器一直都在仓库中。 它们原则上不能与10G链路一起正常工作。
最后的经验。 我们使用正确的熨斗使其美丽
在这里,我们的耐心以对人类的信念结束了,我们不得不使用“备用”技术从上述照片中获得HP ProLiant DL360 G9形式的常规硬件。 他们没有开始为我们安排惊喜,他们下载了10G,没有抱怨。 :)
负载测试
由于我们不接受过时的生产方法,并且我们从经验中知道,组装后未经测试且几乎100%保证的系统将无法操作,因此我们决定进行负载测试。 此外,借助它的帮助,您可以为将来做一些调整。
为了生成负载,选择了常用的工具-Apache Jmetr。 正如我
在后面
写的几篇文章
所述 ,仅此一项就非常不错,即使Java喜欢吃,这也是市场上最灵活的解决方案之一。 为了使用S3,我们使用了同样使用Java的,使用AWS SDK的自写模块。 在测试中,我们能够以12.5 Gbps的速度写入大于250兆字节的文件,并以5兆字节的块进行并行加载,而对于小于5兆字节的文件,则每秒可处理约3000个HTTP请求。 当同时运行两个测试时,每秒可产生约11吉比特和2200个请求。 同时,有可能改善混合负载和小物体的工作。 我们“埋”在CPU中,第二个插槽是空闲的。 在负载生成器上,从RAM中提取了测试文件,以排除对生成器本身的磁盘子系统结果的影响。 对于测试,记住了Java对RAM的热爱以及在并行加载期间需要使用大量线程的情况,我们使用HP DL980 g7服务器作为生成器。 这是一台八单元服务器,带有8个Intel E7-4870处理器和512Gb RAM。
在团队内部,深情的绰号Behemoth贴在他身上。
 14.我们的河马。 是的,类似吗?
14.我们的河马。 是的,类似吗? 15.后视图。 底部中心的吓人电缆是内部桥接总线的交叉连接
15.后视图。 底部中心的吓人电缆是内部桥接总线的交叉连接 16.这是两个服务器目标之一。 每个都有4个处理器和16个16 GB的RAM插槽
16.这是两个服务器目标之一。 每个都有4个处理器和16个16 GB的RAM插槽 17.为了在这样的服务器的控制台中舒适地使用Htop,您需要一个大监视器:)
17.为了在这样的服务器的控制台中舒适地使用Htop,您需要一个大监视器:)实际上,即使是这样强大的服务器,混合测试也已明显加载。
为了获得获得的性能结果,我们必须将群集的内部网络转移到9k巨型帧,并稍微调整平衡器和工作节点的网络堆栈(我们使用CentOS Linux),以及优化工作节点上的许多其他内核参数:
cat /etc/sysctl.conf … kernel.printk = 3 4 1 7 read_ahead_kb = 1024 write_expire = 250 read_expire = 250 fifo_batch = 128 front_merges = 0 net.core.wmem_default = 16777216 net.core.wmem_max = 16777216 net.core.rmem_default = 16777216 net.core.rmem_max = 16777216 net.core.somaxconn = 5120 net.core.netdev_max_backlog = 50000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_max_syn_backlog = 30000 net.ipv4.tcp_max_tw_buckets = 2000000 fs.file-max = 196608 vm.overcommit_memory = 1 vm.overcommit_ratio = 100 vm.max_map_count = 65536 vm.dirty_ratio = 40 vm.dirty_background_ratio = 5 vm.dirty_expire_centisecs = 100 vm.dirty_writeback_centisecs = 100 net.ipv4.tcp_fin_timeout=10 net.ipv4.tcp_congestion_control=htcp net.ipv4.netfilter.ip_conntrack_max=1048576 net.core.rmem_default=65536 net.core.wmem_default=65536 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.ipv4.ip_local_port_range=1024 65535
进行调整的主要设置是缓冲区的大小,网络连接数,端口连接数和防火墙监视的连接数以及超时。
思科C3750 + LACP =痛苦使用LACP / LAGp时,负载平衡是网络性能的另一个陷阱。 不幸的是,Cisco 3750s不能仅通过源地址和目标地址来平衡端口之间的负载。 为了实现正确的流量平衡,我不得不在工作节点的绑定接口上挂12个IP地址,“面向”客户端。 有条件地,每个物理链接3个。 使用此配置,可以在工作节点的“外部”接口上不使用LACP,因为所有地址都在Nginx配置中指定,但是如果链路断开,我们将自动减少平衡中节点的重量。 通过“转储”,LACP链接可让您保持对所有地址的完全可访问性。
bond0.10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 RX packets:2390824140 errors:0 dropped:0 overruns:0 frame:0 TX packets:947068357 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:18794424755066 (17.0 TiB) TX bytes:246433289523 (229.5 GiB) bond0.10:0 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:1 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:2 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:3 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:4 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:5 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:6 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:7 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:8 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:9 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XXMask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
功能测试
完成存储库的工作后,我们遇到了flexify.io服务。 它们有助于促进不同对象存储之间的迁移。 但是要成为Flexify合作伙伴,您必须通过严格的测试。 “为什么不呢?” -我们认为。 第三方测试始终是有益的体验。
测试的主要任务是通过与各种配置相关的代理来验证S3协议方法的操作,其中服务提供商可以支持任何一组与S3兼容的存储桶。
首先,检查适用于存储桶中对象的方法。 我们的存储使用了广泛的测试数据进行了测试,针对各种大小和内容的对象,包含各种Unicode字符组合的键对方法的行为进行了测试。
在负面测试中,他们试图尽可能地传输无效数据。 特别注意过程中数据的安全性。
也已测试了使用存储桶的方法,但主要是在积极的情况下进行的。 这些测试的目的是验证通过代理使用方法不会带来任何严重问题,例如数据损坏或崩溃。
可以通过代理和直接使用的测试来判断覆盖范围。 大多数测试(尤其是那些与对象一起使用的测试)都经过参数化,并且可以测试大量不同的对象,范围等。
实施对象测试没有可选参数的GET Object请求
GET Object请求多线程
使用提供的sse参数对加密对象的GET Object请求
对不提供sse参数的加密对象的GET Object请求
GET对象请求的范围与文件的字节范围相交
GET对象请求,其范围超出文件字节范围的范围
带有后缀范围参数的GET对象请求
带有后缀range参数的GET Object请求超出文件字节范围的范围
包含无效范围参数的GET对象请求
Head对象对现有对象的请求
对最近删除的对象的Head Object请求
具有桶中不存在的键的Head Object请求
头对象对具有提供的sse参数的加密对象的请求
没有提供sse参数的Head Object对加密对象的请求
列出对象请求
列出对象v2请求
具有提供的Marker参数的列表对象请求
具有提供的Prefix参数的列表对象请求
具有提供的Marker和Prefix参数的List Objects请求
使用带有提供的Marker和Prefix参数的List Object接收端点上的所有对象
具有跳过的Delimiter参数的列表对象请求
具有传递的Marker参数但具有跳过的Delimiter参数的List Objects请求
带有不存在的前缀的列表对象请求
带有不存在的标记的列表对象请求
使用本机upload_file()方法分段上传
使用本机upload_fileobj()方法分段上传
使用自定义方法分段上传
使用abort_multipart_upload()方法停止分段上传
执行带有不正确的uploadId的abort_multipart_upload()方法
使用不正确的Key和uploadId执行abort_multipart_upload()方法
使用同一密钥同时分段上传2个文件。 1日之前上传第二个文件
使用同一密钥同时分段上传2个文件。 第一个文件在第二个之前上传
同时使用不同的密钥分段上传2个文件。 第一个文件在第二个之前上传
分段上传,部分大小为512kb
分段上传,分段大小大于最大允许大小
分段上传文件,文件大小各不相同
列出分段上传请求
向具有提供的受让人ID的对象的PUT对象ACL请求
对具有授予的其他访问权限的对象的GET Object ACL请求
PUT对象标记方法
GET对象标记方法
删除对象标记方法
没有可选参数的PUT对象请求
PUT对象请求多线程
具有传递的可选加密参数的PUT对象请求
通过传递空的Body参数的PUT对象请求
带有本地download_file()方法的GET对象
带有本机download_fileobj()方法的GET Object
使用范围自定义方法获取对象
带有本地download_file()方法前缀的GET Object
带有本地download_fileobj()方法前缀的GET Object
使用范围自定义方法获取带前缀的对象
删除对现有对象的对象请求
将对象请求删除到不存在的对象
删除对象请求到具有现有对象的组
铲斗的已实现测试放置存储桶加密
获取存储桶加密
删除存储桶加密
PUT存储桶策略请求
使用策略向存储桶获取存储桶策略请求
使用策略将存储桶策略请求删除到存储桶
向没有策略的存储桶中获取存储桶策略请求
将存储桶策略请求删除到没有策略的存储桶
放入桶标签
获取存储桶标签
删除桶标记
使用现有存储桶名称创建存储桶请求
使用唯一的存储桶名称创建存储桶请求
使用现有存储桶名称删除存储桶请求
使用唯一的存储桶名称删除存储桶请求
向具有提供的被授予者ID的存储桶发送PUT存储桶ACL请求
对具有授予的其他访问权限的对象的GET Object ACL请求
您可能会猜到,这是一个相当艰巨的测试,但我们总体上通过了肯定。 由于当时缺乏对SSE的支持以及当时有Unicode支持的小型学校而出现了一些问题:
包含以下内容的键的apload失败:
- U + 0000-U + 001F-前32个不可读的控制字符。 例如,在亚马逊上,仅第一个U + 0000不直接注入。
- 还有U + 18D7C,U + 18DA8,U + 18DB4,U + 18DBA,U + 18DC4,U + 18DCE。 这些也是不可读的字符,但是Amazon接受它们作为键。 所有其他字符都没有问题。
读取存储桶中的内容时,在66,675键上存在问题,该键包含符号U + FFFE。 无法在包含具有此类密钥的对象的存储桶中获取完整的密钥列表。
否则,测试是成功的,并且在9月底,我们出现在可用供应商的列表中!
给读者的简短后记和加分
早些时候,我曾写过Cloudian HyperStore,尽管它有许多优点,但实际上在讲俄语的Internet中并未涉及。
第一篇文章介绍了与Cloudian合作的基础知识。 我们拆解了其内部结构,建筑细微差别,并阅读了官方文档的翻译。
今天,我讲述了我们如何构建自己的存储库以及遇到的细微差别和陷阱。
那些想要用笔触碰我们连续谈论2篇文章的人,可以使用
此页面上的反馈表
来亲自找出盐是什么。 作为标准,我们免费为15Gb的用户提供2周的免费访问时间。 如果您希望分享使用存储库的印象,请在PM中给我写信。 :)
对于2周内15 Gb不足的用户,我们有一个
小任务! 在文章的照片中,我们放置了三个河马。 找到它们的前50个人将在4周内收到30Gb。 要进行放大测试,请在注释中写下河马隐藏的图片编号,然后申请上面的链接。 不要忘记在应用程序中包含指向您的评论的链接。
按照传统,如果您有任何问题,请在评论中提出。
我很乐意回答他们。