
无论是互联网新闻,诗歌还是古典小说,我们每个人都以自己的方式感知文本。 这同样适用于机器学习的算法和方法,这些算法和方法通常以多维矢量空间的形式感知数学形式的文本。
本文致力于使用Word-Vec单词的多维矢量表示计算出的t-SNE进行可视化。 可视化将有助于更好地理解Word2Vec的原理以及在进一步用于神经网络和其他机器学习算法之前如何解释单词向量之间的关系。 本文着重于可视化,未考虑进一步的研究和数据分析。 作为数据源,我们使用Google新闻的文章和L.N.的经典著作。 托尔斯泰。 我们将在Jupyter Notebook中使用Python编写代码。
T分布随机邻居嵌入
T-SNE是一种基于非线性降维方法的用于数据可视化的机器学习算法,在原始文章[1]和
Habré上进行了详细描述。 t-SNE操作的基本原理是在保持相对位置的同时减小点之间的成对距离。 换句话说,该算法将多维数据映射到较低维的空间,同时保持点邻域的结构。
单词和Word2Vec的矢量表示
首先,我们需要以向量形式呈现单词。 对于此任务,我选择了Word2Vec分布语义实用程序,该实用程序旨在显示矢量空间中单词的语义含义。 Word2Vec通过假设在相似的上下文中发现了语义相关的单词来查找单词之间的关系。 您可以在原始文章[2]中以及
此处和
此处阅读有关Word2Vec的更多信息。
作为输入,我们采用Google新闻和L.N.的小说中的文章。 托尔斯泰。 在第一种情况下,我们将使用Google
在项目页面上发布的Google新闻数据集(约1000亿个单词)中预先训练的向量。
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
除了使用Gensim库[3]预先训练的向量外,我们还将在L.N.的文本中训练另一个模型。 托尔斯泰。 由于Word2Vec接受一组句子作为输入,因此我们使用NLTK软件包中经过预先训练的Punkt句子标记器模型来自动将文本拆分为句子。 可以
从此处下载俄语模型。
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
接下来,使用Gensim库,我们将使用以下参数训练Word2Vec模型:
- size = 200-属性空间的尺寸;
- window = 5-算法分析的上下文中的单词数;
- min_count = 5-该单词必须至少出现五次,以便模型将其考虑在内。
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
使用t-SNE可视化单词的矢量表示
T-SNE对于可视化多维空间中对象之间的相似性非常有用。 随着数据量的增加,建立可视化图表变得越来越困难,因此在实践中,将相关单词组合成组以进一步可视化。 例如,从以前在Google新闻中训练过的Word2Vec模型的词典中拿几个单词。
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
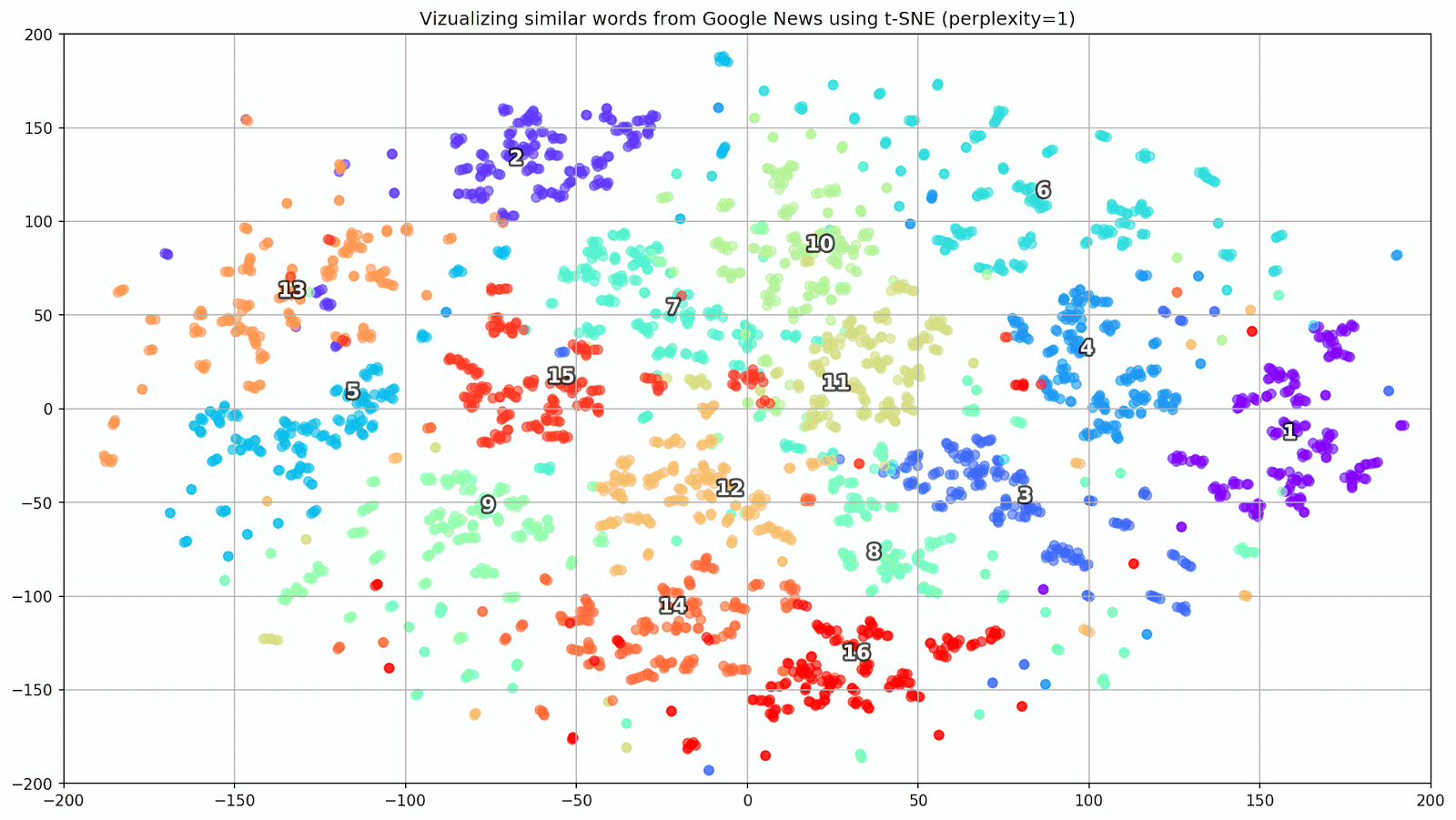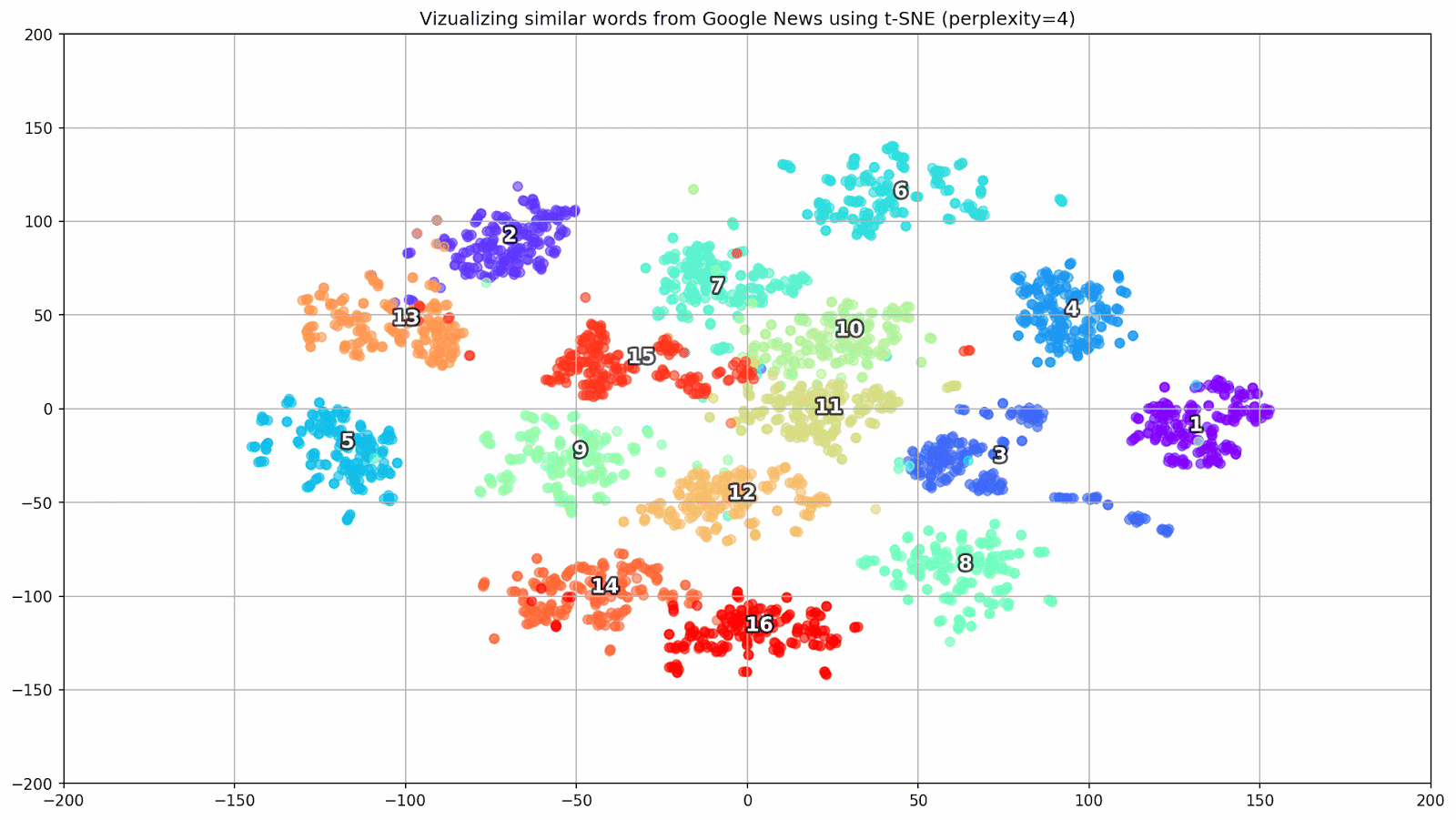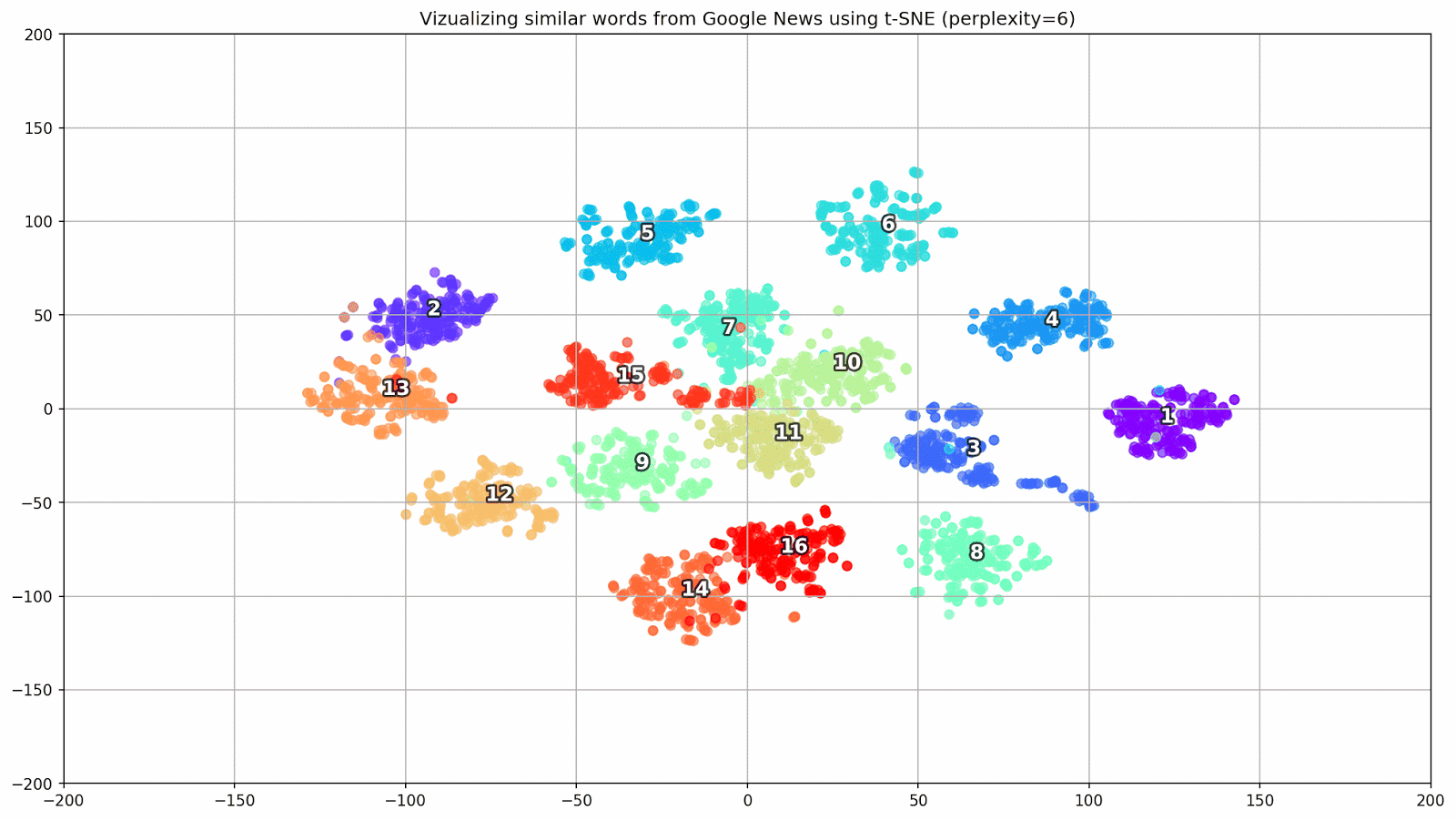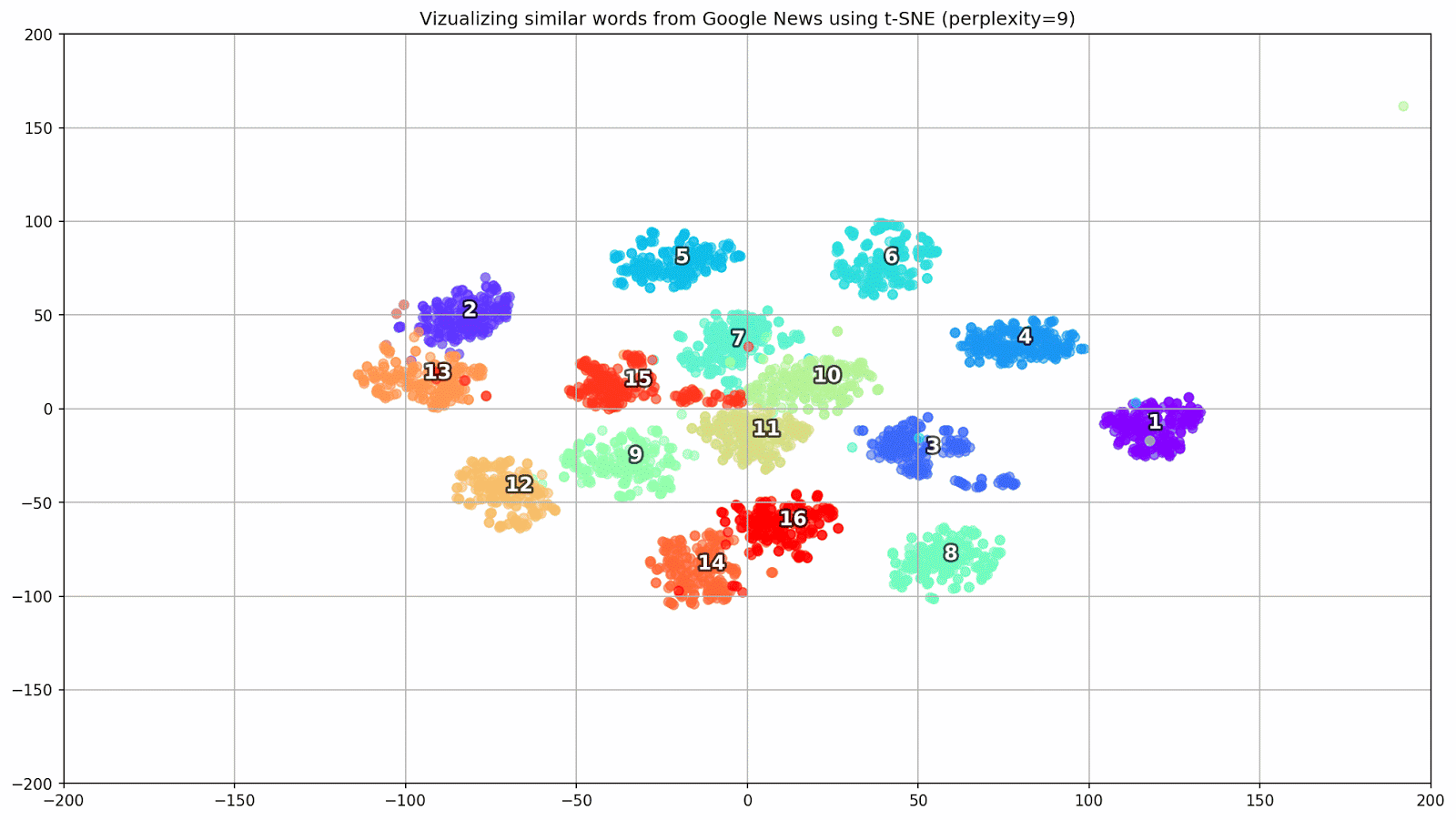 图1.来自Google新闻的相似词组,具有不同的复杂性值。
图1.来自Google新闻的相似词组,具有不同的复杂性值。接下来,我们转到本文最引人注目的片段,即t-SNE配置。 在这里,首先,您应注意以下超参数:
- n_components-组件数,即值空间的维数;
- 困惑 -困惑,在t-SNE中的值可以等于邻居的有效数量。 它与最近邻居的数量有关,在其他基于品种的学习模型中使用了该邻居(请参见上图)。 建议将其值[1]设置在5-50的范围内;
- init-向量的初始初始化类型。
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
以下是使用Matplotlib构建二维图形的脚本,Matplotlib是用于在Python中可视化数据的最受欢迎的库之一。
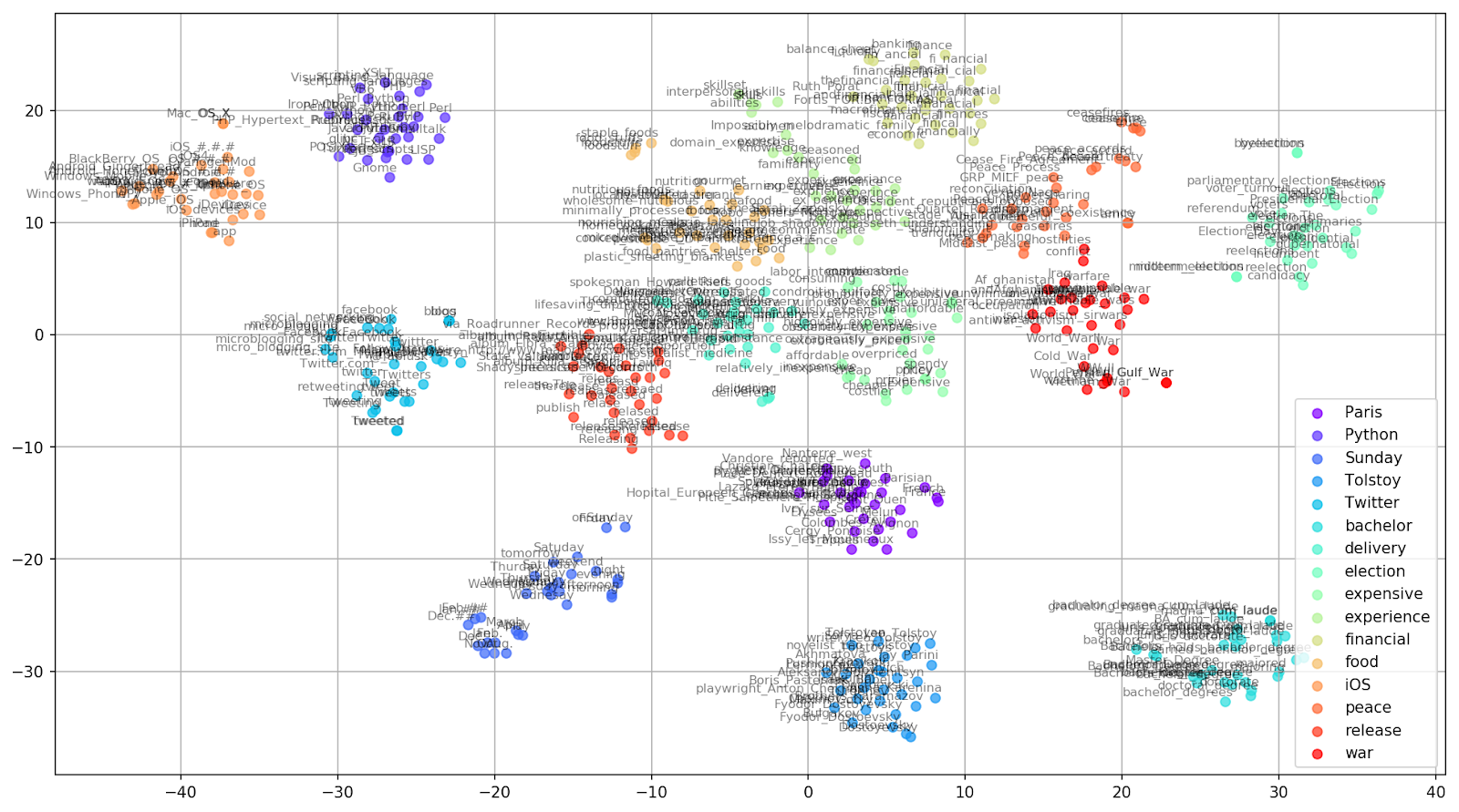 图2.来自Google新闻的相似词组(复杂度= 15)。
图2.来自Google新闻的相似词组(复杂度= 15)。 from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
有时有必要建立不是单独的单词簇,而是整个字典。 为此,让我们分析一下安娜·卡列尼娜(Anna Karenina),这是关于激情,背叛,悲剧和赎罪的伟大故事。
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
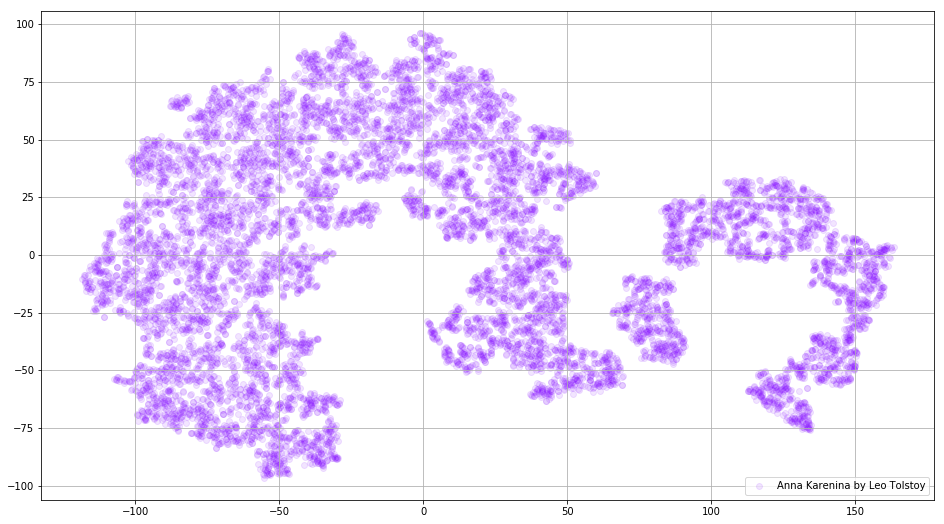
 图3.以小说《安娜·卡列尼娜》为训练对象的Word2Vec模型字典的可视化。
图3.以小说《安娜·卡列尼娜》为训练对象的Word2Vec模型字典的可视化。如果我们使用三维空间,图片将变得更加有用。 看一下《战争与和平》,这是世界文学的主要小说之一。
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
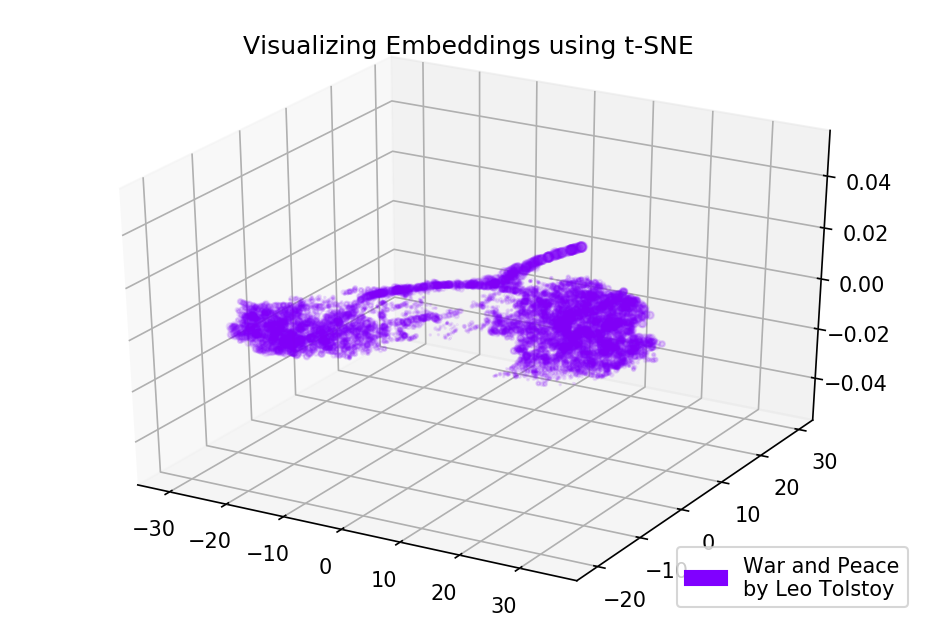 图4. Word2Vec模型字典的可视化,该字典经过小说《战争与和平》的训练。
图4. Word2Vec模型字典的可视化,该字典经过小说《战争与和平》的训练。源代码
该代码可在
GitHub上获得 。 在这里您可以找到用于渲染动画的代码。
资料来源
- Maaten L.,Hinton G.使用t-SNE可视化数据//机器学习研究杂志。 -2008年-T. 9-S. 2579-2605。
- 单词和短语的分布式表示及其组成性// 神经信息处理系统的进展 。 -2013 .-- S.3111-3119。
- Rehurek R.,Sojka P.用于大型语料库主题建模的软件框架//在NREC框架新挑战LREC 2010研讨会的论文集中。 -2010年。