我继续通过Pixonic DevGAMM Talks上载报告,Pixonic DevGAMM Talks是我们9月份针对高负载系统开发人员的会议。 他们分享了很多经验和案例,今天我发布了Saber Interactive Roman Rogozin后端开发人员的演讲记录。 他以管理玩家及其状态的示例为例介绍了应用参与者模型的做法(其他报告可以在文章末尾找到,列表进行了补充)。
我们的团队正在开发Quake Champions游戏的后端,我将讨论actor模型是什么以及如何在项目中使用它。
关于技术堆栈的一些知识。 我们分别用C#编写代码,所有技术都与之相关。 我想指出,在该语言的示例中将显示一些特定的内容,但是一般原理将保持不变。

目前,我们在Azure中托管我们的服务。 有一些我们不想放弃的非常有趣的原语,例如Table Storage和Cosmos DB(但为了跨平台项目,我们尽量不要过分紧缩它们)。
现在,我想简单介绍一下演员模型。 首先,它原则上出现于40多年前。
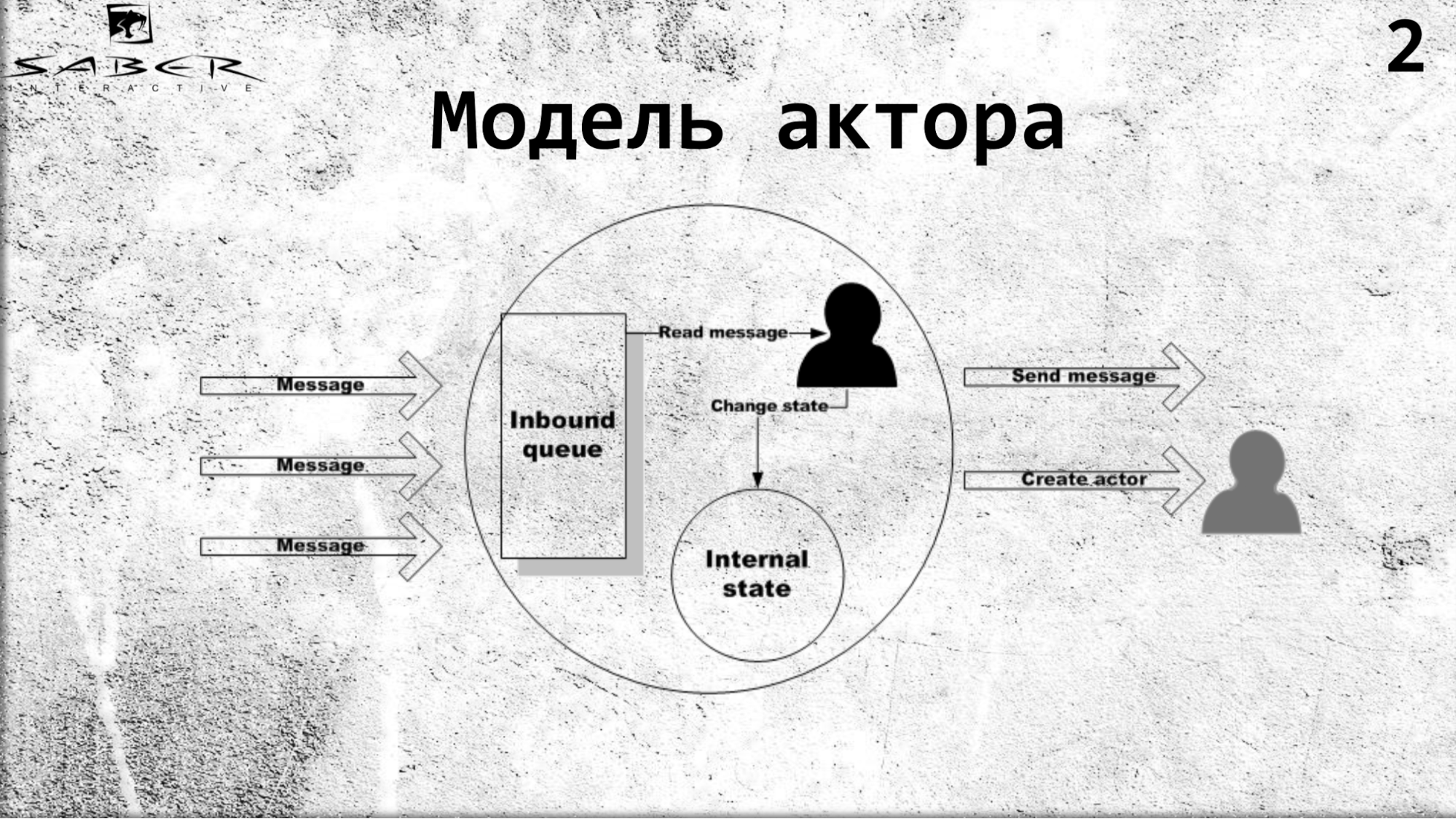
参与者是并行计算的模型,该模型声明存在某个隔离的对象,该对象具有其自己的内部状态并且具有独占访问权以更改此状态。 角色可以读取消息,并且可以顺序地执行某种业务逻辑(如果他想更改其内部状态),并将消息发送到包括其他角色的外部服务。 而且他知道如何创建其他演员。
Actor彼此异步通信,这使您可以创建高负载的分布式云系统。 在这方面,演员模型最近已被广泛使用。
总结一下,假设我们有一个云,那里有某种服务器集群,而我们的参与者正在这个集群上旋转。
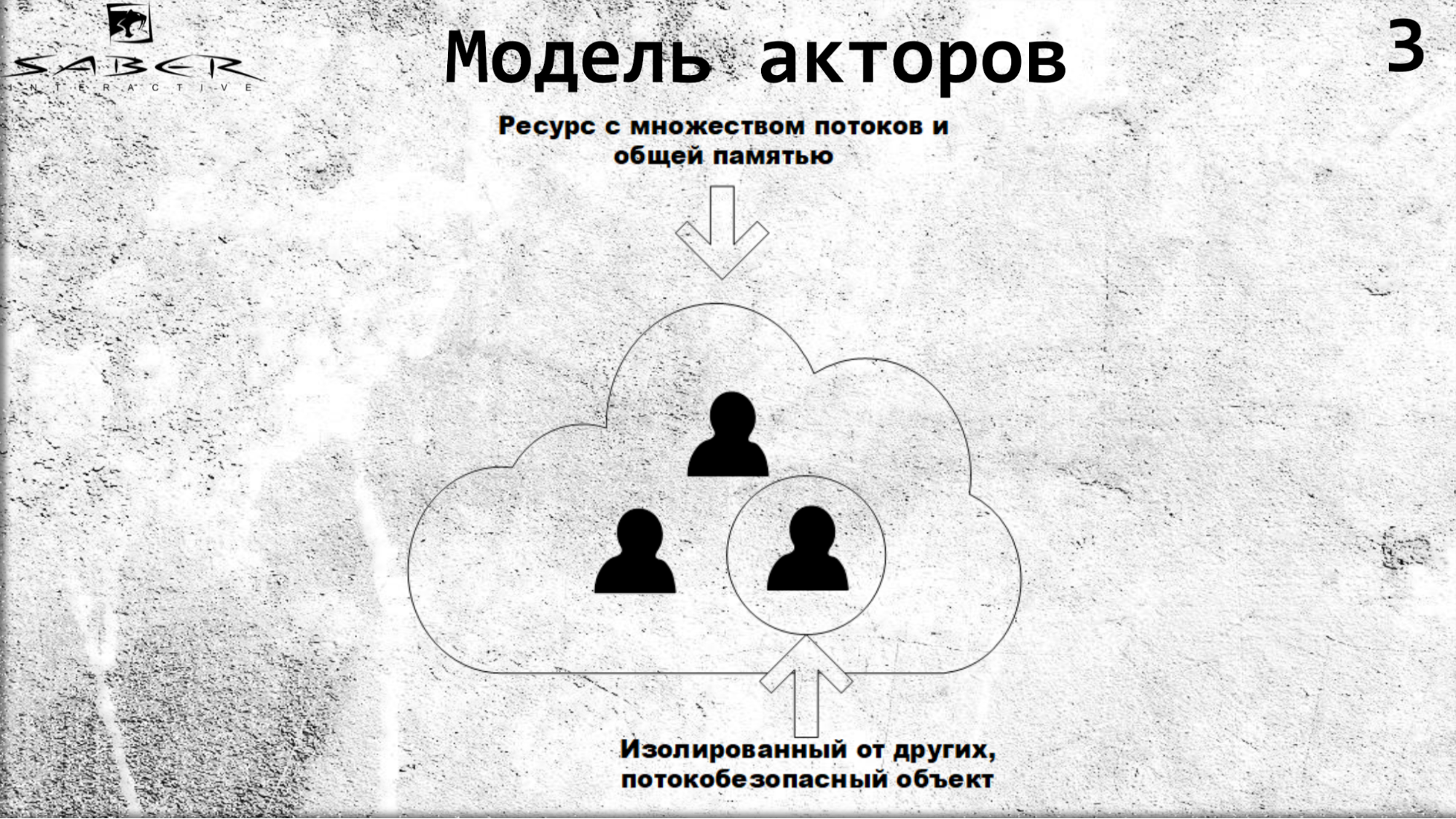
Actor彼此隔离,通过异步调用进行通信,并且在其内部,actor是线程安全的。
看起来如何。 假设我们有几个用户(负载不是很大),并且在某个时候我们知道有大量的玩家涌入,因此我们迫切需要进行升级。
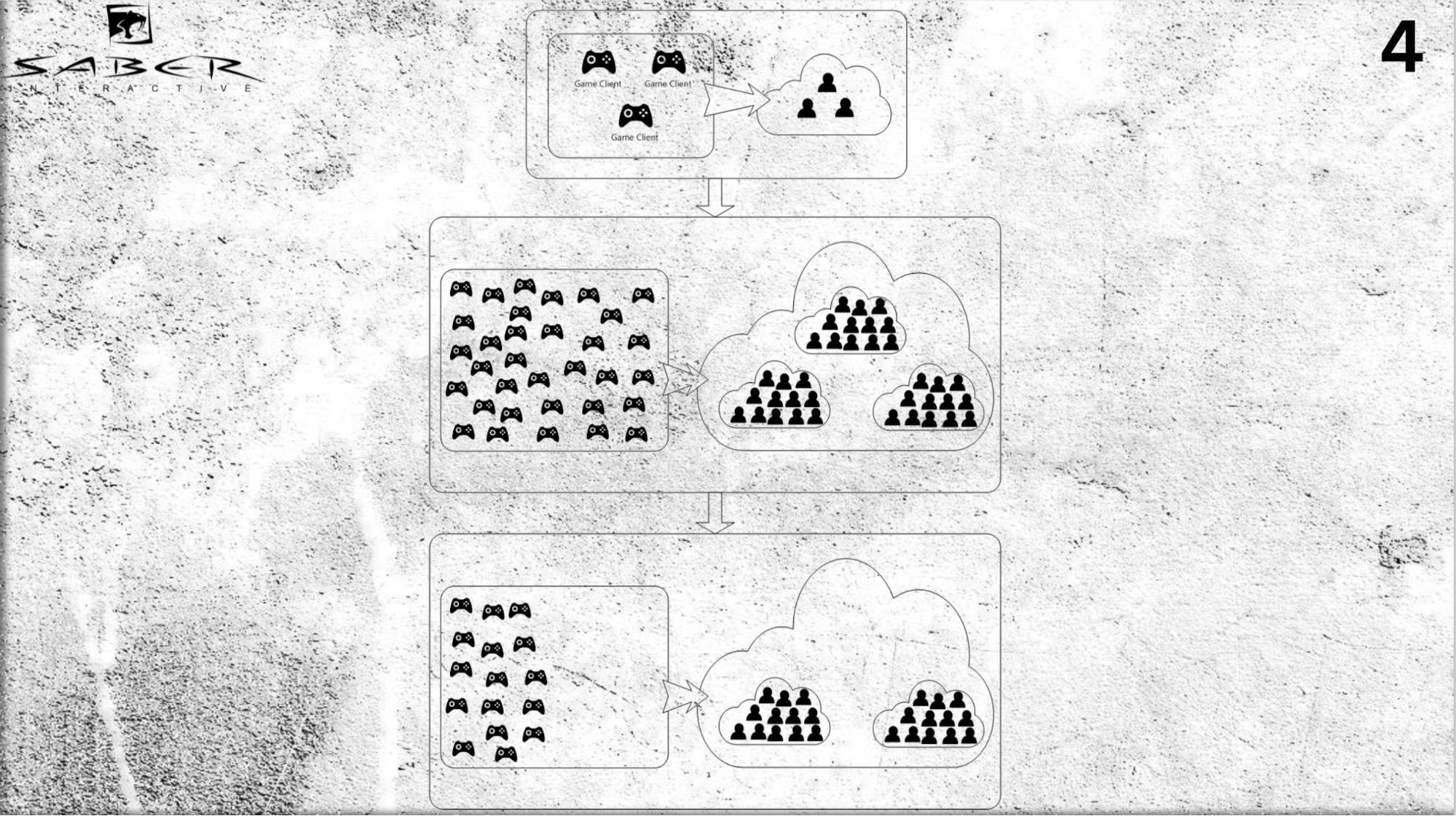
我们可以将服务器添加到我们的云中,并使用参与者模型来推送单个用户-分配每个单独的参与者,并在云中为此参与者分配用于内存和处理器时间的空间。
因此,参与者首先扮演了缓存的角色,其次,它是一个“智能缓存”,可以处理某些消息并执行业务逻辑。 同样,如果您需要缩小尺寸(例如,玩家离开了),将这些角色从系统中删除也没有问题。
我们在后端不使用经典的actor模型,而是基于Orleans框架。 有什么区别-我现在尝试告诉您。

首先,奥尔良引入了虚拟演员(也称为谷物)的概念。 与经典的角色模型不同,在传统的角色模型中,服务负责创建此角色并将其放置在某些服务器上,而奥尔良则接管了工作。 即 如果某个用户服务要求某个等级,那么Orleans将了解现在哪些服务器负载较少,它将把actor放在那儿并将结果返回给用户服务。
一个例子。 对于谷物,仅了解参与者的类型(例如,用户状态和ID)非常重要。 假设用户ID为777,我们获得该用户的粒度,并且不考虑如何存储此粒度,则我们不控制粒度的生命周期。 但是,奥尔良内部非常狡猾地存储了所有参与者的路径。 如果没有演员,则他创建角色,如果演员还活着,他将其返回,并且对于用户服务,一切看起来都如此,以便所有演员都一直活着。
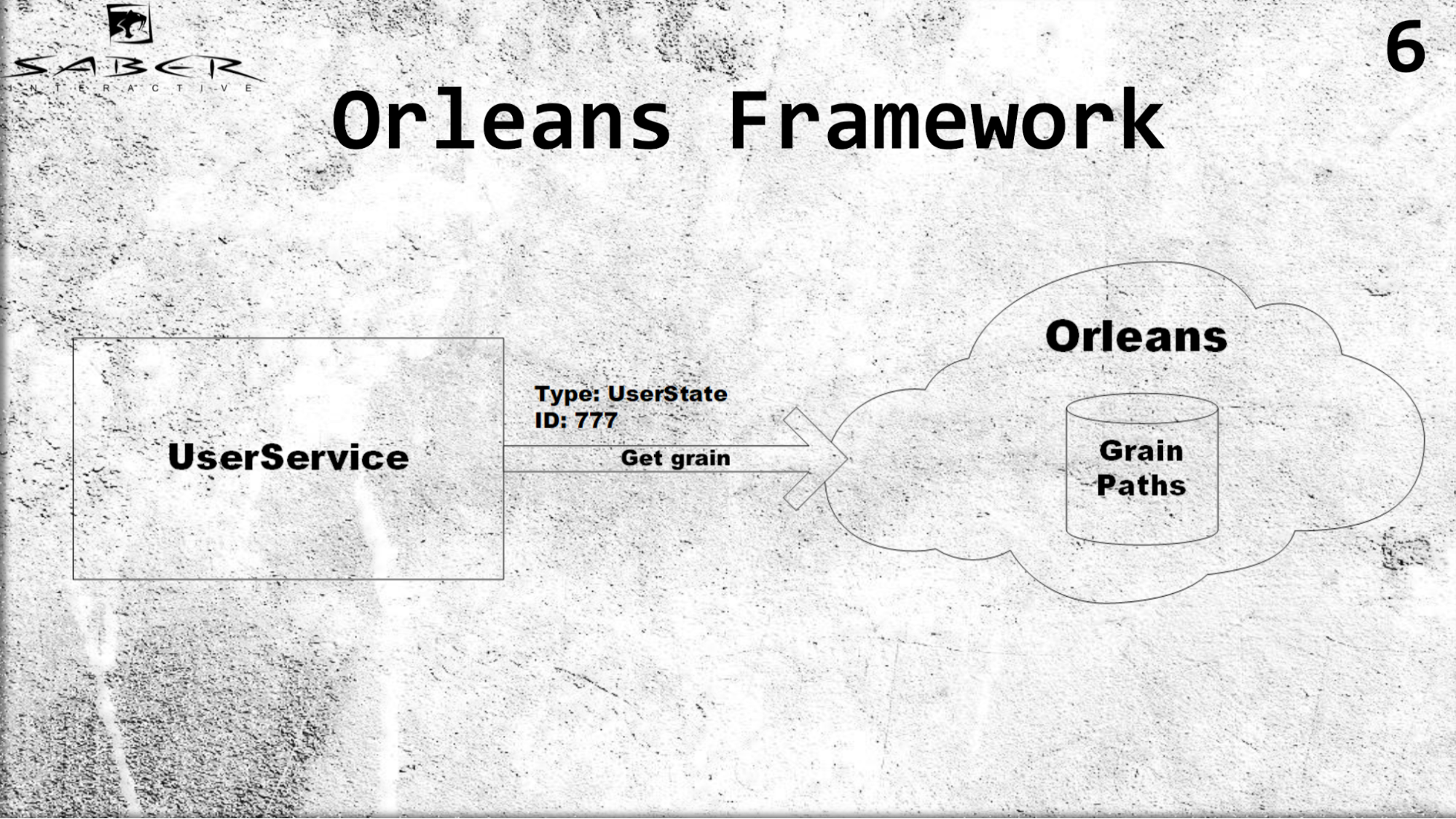
这给我们带来什么好处? 首先,由于程序员不需要自行管理角色的位置,因此实现了透明的负载平衡。 他只是简单地说Orleans,它已部署在多台服务器上:请从您的服务器中给我这样的角色。
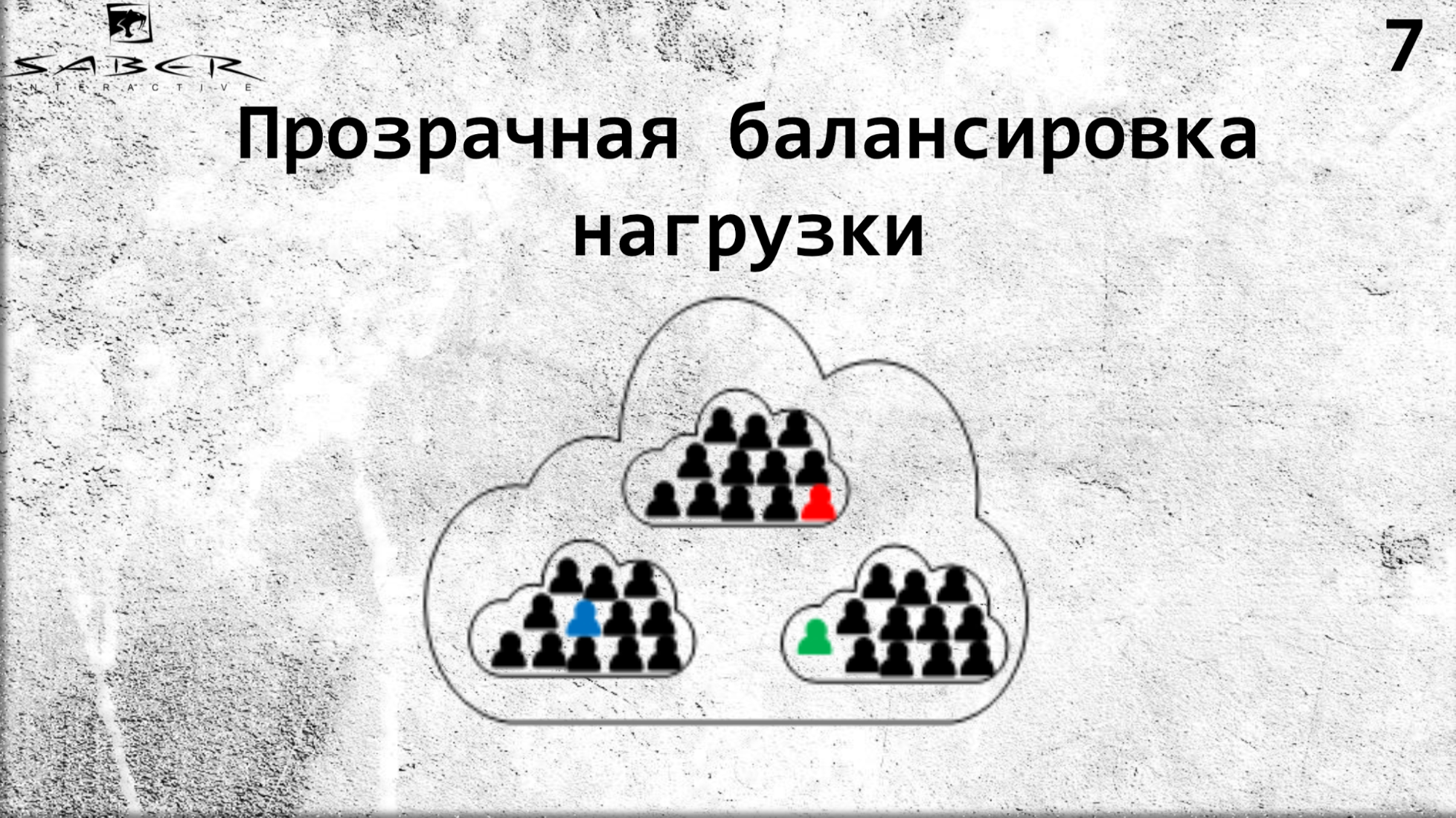
如果需要,如果处理器和内存的负载较小,则可以缩小比例。 同样,您可以沿相反方向进行放大。 但是服务人员对此一无所知,他要求提供服务,奥尔良给了他服务。 因此,奥尔良对谷物的生命周期进行了基础设施维护。
其次,奥尔良处理服务器崩溃。

这意味着,如果在经典模型中,程序员负责自己处理这种情况(他们将角色放置在某个服务器上,并且该服务器崩溃了,我们自己必须在活动服务器之一上提升该角色),这增加了更多的机械性或复杂的网络工作以供程序员使用,那么在奥尔良,它看起来是透明的。 我们请求一个粒度,Orleans认为它不可用,将其拾取(将其放置在某些实时服务器上)并将其返回给服务。
为了更清楚一点,让我们看一个有关用户如何读取其状态的小例子。
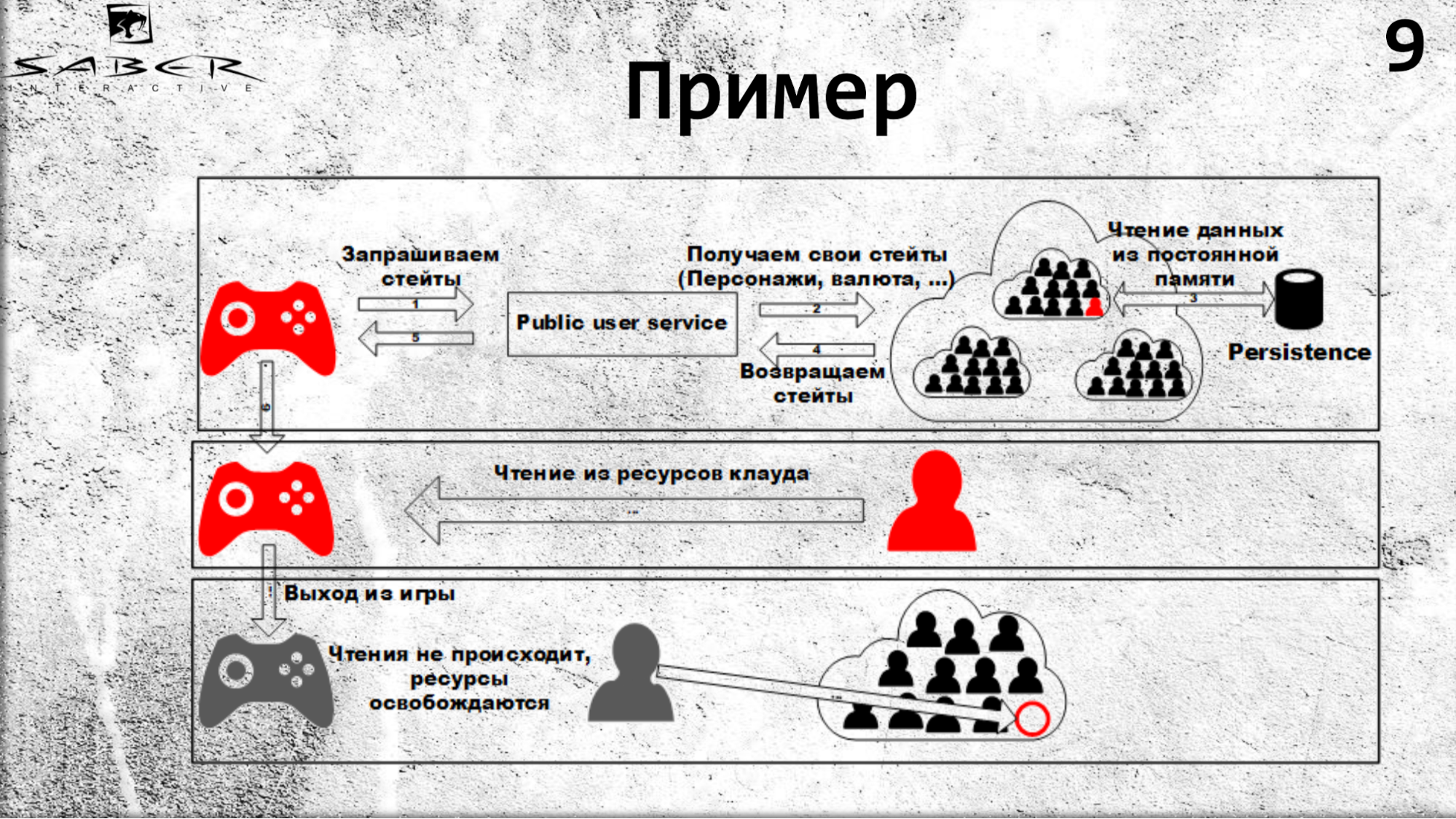
状态可能是他的经济状况,它存储该用户的装甲,武器,货币或拥护者。 为了获得这些状态,他调用了PublicUserService,该状态变为Orleans。 发生了什么:奥尔良发现还没有这样的参与者(即谷物),他在一个免费服务器上创建了它,并且谷物从某个持久性存储中读取了其状态。
因此,如幻灯片所示,下次您从云中读取资源时,所有读取都将来自高速缓存。 如果用户离开游戏,则不会出现读取资源的情况,因此Orleans知道任何人都不再使用谷物,可以将其停用。
如果我们有多个客户端(游戏客户端,游戏服务器),则它们可以请求用户状态,其中一个将提高这种状态。 更准确地说,它将使Orleans接听它,然后所有调用(如我们所知的)将依次在线程安全的线程中发生。 首先,客户端将接收状态,然后是游戏服务器。
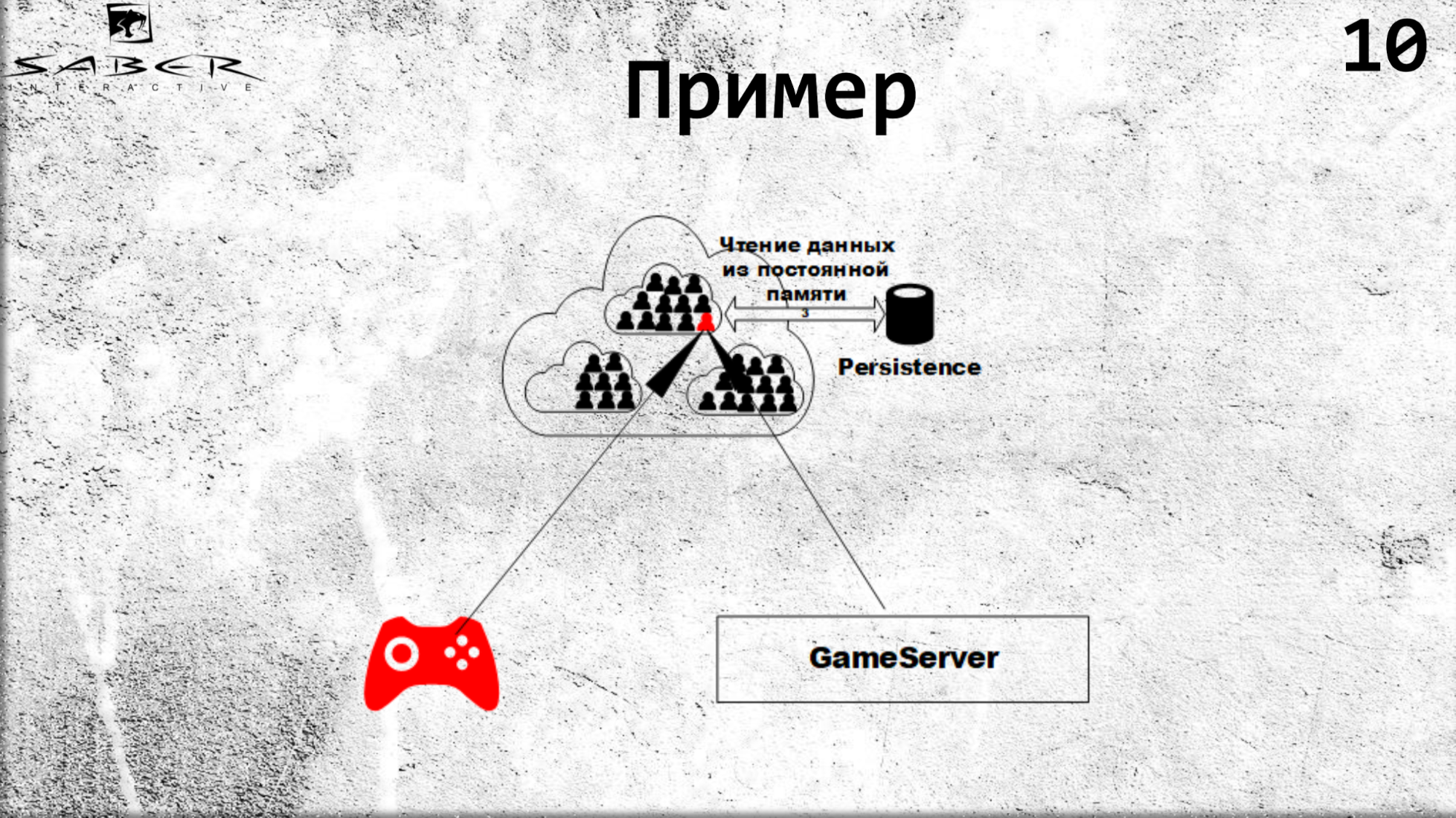
更新时的流程相同。 当客户想要更新状态时,他会将这种责任转移到谷物上,即 会告诉他:“给该用户10黄金”,并且谷物上涨,它使用谷物中的某种业务逻辑处理该状态。 然后是缓存的更新,如果需要,还可以更新持久性。

为什么在这里需要持久性? 这是一个单独的主题,其原因在于,有时对于谷物来说,不断地保持其持久性对我们而言并不特别重要。 如果这是在线播放器的状态,那么为了提高生产率,我们准备冒险失去它,如果它涉及经济,那么我们必须确保保留其状态。
最简单的情况:对于每个保存状态调用,将此更新写入Persistence。 因此,如果灰色突然意外下降,则其他一些服务器上的下一次纹理升高将导致使用当前数据进行缓存更新。
外观的一个小例子。

正如我已经说过的,一个grain由一个类型和一些键组成(在这种情况下,该类型是IPlayerState,键是IGrainWithGuidKey,这意味着它是Guid)。 我们有一个实现的接口,即 GetStates返回一些状态列表和ApplyState(适用某些状态)。 奥尔良方法返回Task。 这意味着什么:任务是一个诺言,它告诉我们状态返回时,诺言将处于已解决状态。 我们也有一些与GrainFactory一起使用的PlayerState。 即 在这里,我们获得了一个链接,但我们对该谷物的物理位置一无所知。 调用GetStates时,Orleans将提高粒度,将状态从Persistence存储区读取到其内存中,当ApplyState将应用新状态时,它还将在内存和Persistence中更新此状态。
我想在UserStates服务的高级体系结构上给出一个稍微复杂的示例。
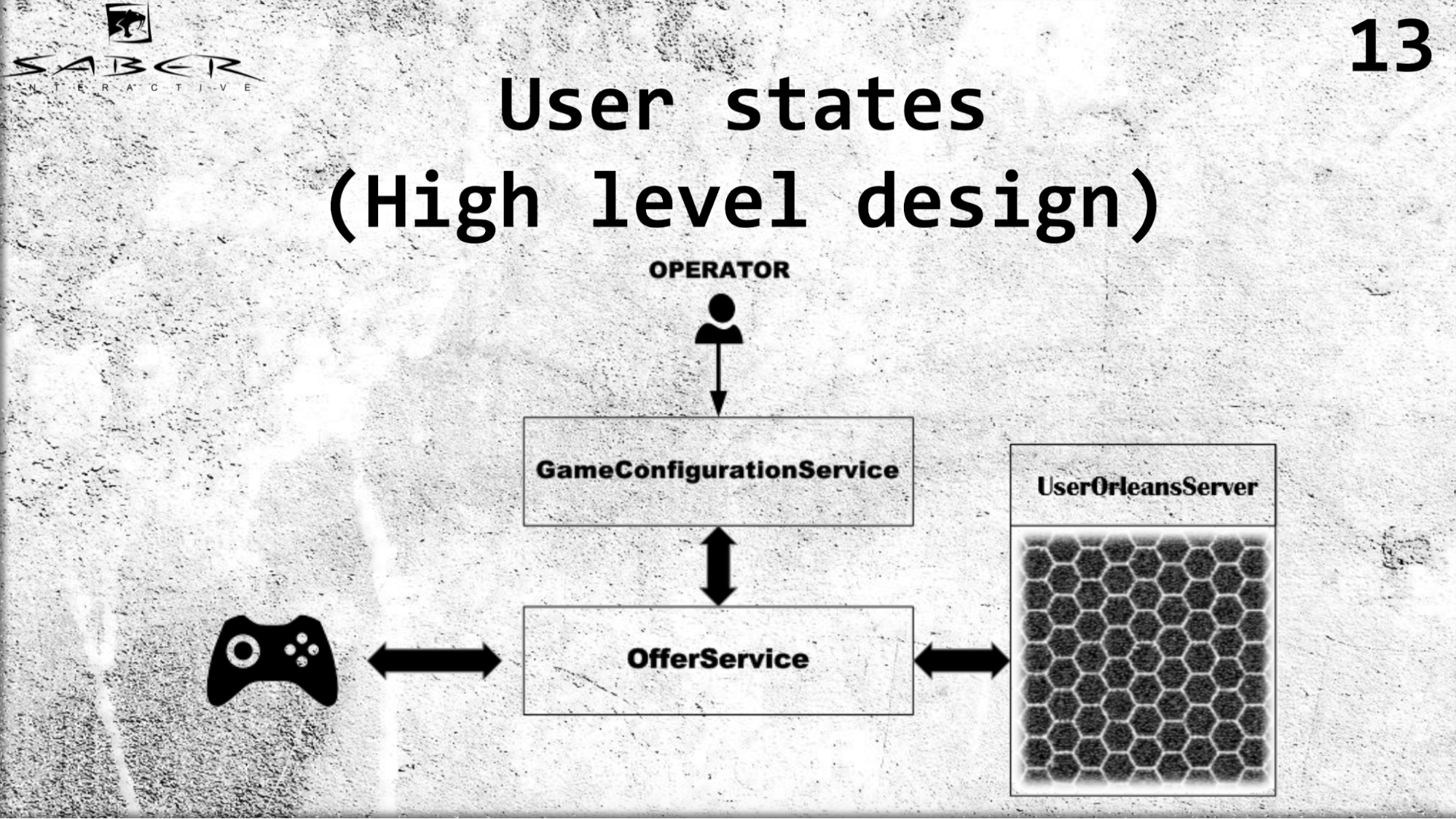
我们有某种游戏客户端可以通过OfferSevice获取其状态。 我们有一个GameConfigurationService,负责一组用户(在本例中为我们的用户)的经济模型。 而且我们有一家运营商正在改变这种经济模式。 根据它,用户请求OfferSevice接收其状态。 OfferSevice已经在访问由这些粒度组成的UserOrleans服务,它在内存中引发用户的这种状态,可能执行某种业务逻辑,然后通过OfferService将数据返回给用户。
总的来说,我想提醒大家一个事实,即奥尔良之所以具有高并行性,是因为晶粒彼此独立。 另一方面,在粒度内,我们不需要使用同步原语,因为我们知道对此粒度的每次调用都将保持一致。
在这里,我想指出这种模型的一些缺陷。

首先是过多的纹理。 由于greine中的所有调用都是线程安全的,一个接一个,因此,如果在greine上有一些油腻的逻辑,我们将不得不等待太久。 同样,为一个这样的颗粒分配了太多的内存。 没有确切的算法来确定晶粒的大小,因为晶粒太小也是不好的。 在这里,有必要从最佳值出发。 我不会确切说出哪一个,这要由程序员来决定。
第二个问题不是那么明显-这就是所谓的连锁反应。 当用户饲养一些谷物时,他又可以隐式饲养系统中的其他谷物。 这是如何发生的:用户收到他的状态,并且用户有朋友,并且他收到他的朋友的状态。 因此,整个系统将所有颗粒保留在内存中,如果我们有1000个用户,每个用户有100个朋友,则可以像这样激活100,000个颗粒。 还需要避免这种情况-以某种方式将朋友的状态存储在某种共享内存中。

好了,存在哪些技术可以实现参与者模型。 也许最著名的是Akka,它是Java附带的。 有一个名为Akka.NET for .NET的分支。 有Orleans作为一种实现,它是开源的,并且使用其他语言。 有诸如Service Fabric Actor之类的Azure原语-有很多技术。
听众的提问
-您如何解决经典问题,如CICD,更新这些参与者,是否使用Docker?是否需要它?-我们尚未使用docker。 通常,DevOps参与部署;他们在Azure云服务中部署我们的服务。
-持续更新,而无需停机,它是如何发生的? 奥尔良自己决定服务器将转到哪个服务器,请求将转到哪个服务器以及如何更新此服务。 即 一个新的业务逻辑已经出现,同一个参与者的更新已经出现-这些更新如何滚动?-如果我们正在谈论更新整个服务,并且已经更新了参与者的某些业务逻辑,则可以为其推出新的奥尔良服务。 通常,这可以通过我们称为拓扑的原语来解决。 我们推出了一项新的奥尔良服务,假设它现在是空的,并且没有参与者,则显示旧服务并将其替换为新服务。 系统中根本没有参与者,但是在下一个用户请求下,这些参与者已经被创建。 一开始可能会出现某种峰值。 在这种情况下,更新通常发生在早晨,因为早晨我们的玩家人数最少。
“奥尔良如何理解服务器已崩溃?” 您说他很快将演员扔到另一台服务器上...-他有一个Pingator,它会定期了解哪些服务器仍在运行。
-他是否对演员或服务器进行ping操作?-特别是服务器。
-这样的问题:演员内部发生错误,您说他每条指令都按部就班。 但是发生了错误,演员会发生什么? 假设未处理的错误。 演员快死了吗?-不,Orleans在标准.NET模式中引发异常。
-看,我们没有处理异常,演员显然死了。 玩家我不知道它的外观,但是接下来会发生什么呢? 您是否正在尝试以某种方式重新启动此演员或执行其他类似的操作?-它取决于哪种情况,取决于哪种情况。 例如可重试或不可重试。
-就是 这都是可配置的吗?-而是编程的。 我们正在处理一些例外情况。 即 我们清楚地看到,这样的错误代码以及一些未处理的异常已被进一步推送。
-您是否有几种持久性-它像数据库吗?-持久性,是的,具有持久性存储的数据库。
-假设有一个数据库(有条件地)存放了游戏资金。 如果演员无法联系到她,会发生什么? 您如何处理?-首先是存储。 目前,我们正在使用Azure表存储,而实际上发生了此类问题-存储崩溃。 通常,在这种情况下,您必须重新配置它。
-如果演员无法在Storage中获得任何东西,那么玩家会是什么样? 他只是没有钱,还是立即关闭游戏?-这些对于用户来说是至关重要的变化。 由于每种服务都有其自己的严重性,因此在这种情况下,用户服务是终端状态,客户端只会崩溃。
-在我看来,参与者的消息是通过异步队列发生的。 如何优化解决方案? 它不会膨胀吗,是否会使播放器挂断电话? 使用被动方法更好吗?-参与者中的队列问题是众所周知的,因为我们显然不能控制队列的大小,您是对的。 但是奥尔良首先要承担某种管理工作,其次我认为仅仅通过超时,对演员的访问就将减少,即 例如,我们无法联系演员。
-这会对玩家产生什么影响?-由于用户服务与参与者联系,因此他们将引发异常超时异常,并且,如果这是一项“关键”服务,则客户端将引发错误并关闭。 如果要求不太严格,则将等待。
-就是 您有DDoS威胁吗? 大量的小动作可以放一个玩家吗? 假设某人迅速开始邀请朋友等。-不,有一个请求限制器,不允许您太频繁地访问服务。
-您如何处理数据一致性? 假设我们有两个用户,我们需要从一个用户那里获取一些东西,然后向另一位用户收取一些东西,这样它就具有交易性。-好问题。 首先,奥尔良2.0支持Distributed Actor Transaction-这是第一个发行版。 更准确地说,已经有必要谈论经济。 作为最简单的方法-在上一个奥尔良,参与者之间的交易得以顺利进行。
-就是 它是否已经知道如何保证数据将保持完整性?-是的
通过Pixonic DevGAMM进行更多对话