“有人称我们为“普鲁什金斯”,我想说我们是档案保管员。”
Wayback Machine总监Mark Graham概述了每个人喜欢的档案的规模
 在Online News Association 2018上观看Wayback Machine德克萨斯州奥斯丁。
在Online News Association 2018上观看Wayback Machine德克萨斯州奥斯丁。 不管有多少订户服务都不想让您相信这一点,但是并非所有内容都可以在Amazon或Netflix上找到。 例如,是否
要阅读布雷特·卡瓦诺(Brett Cavanaugh)法官
的书 (甚至是
臭名昭著的年度报告 )? 好奇地看到一堆
老式吸烟广告海报吗? 怎样看
世界上藏传佛教文献最多 ? 如今,您可以在一个地方完成所有这一切,而您(经常)访问的不是Google或某些海盗网站。
“我有一个政府视频, 介绍如何洗手或准备进行核战争 ,”互联网档案馆Wayback Machine主管Mark Graham说。 “我们可以轻松地在具有.mil域(军事工业PowerPoint复合体)的所有站点上列出.ppt文件的列表。”
格雷厄姆最近与2018年在线新闻协会会议的几个小组成员进行了交谈,而Ars Technica很幸运能出席会议。 后来他对会议做了完整的介绍,现在
可以以音频格式获得 。 基本思想是,如今的Internet档案馆的规模可能与Internet本身的规模一样难以理解。
非营利性的物理空间仍然很容易理解,至少这就是格雷厄姆希望的那样。 今天,Internet档案库的所有活动都是在旧金山的一个古老教堂(甚至没有拆除长椅)上进行的,大约有200人。 档案馆还包含最近的仓库,用于存储物理媒体,不仅包括书籍,还包括黑胶唱片。 格雷厄姆开玩笑说,这里的主要计量单位是“运送容器”。 档案每两周收到一次。
该公司目前是仅次于Google的全球第二大图书扫描仪。 Graham已确保当前的扫描总数超过400万。 该档案馆甚至对接下来的150万次扫描都有一个愿望清单,其中包括Wikipedia上引用的所有内容。 Wayback Machine试图防止您单击Wikipedia上的链接时弹出
404错误 (Graham最近告诉BBC,Wayback僵尸程序恢复了近600万由于链接失败而丢失的页面)。 今天,可以通过Internet档案馆免费下载1923年以前出版的书籍,以后您可以借用其中许多书籍的数字副本。
推文翻译:
互联网档案馆: 修复了超过900万个维基百科错误链接
WikiResearch:非常感谢@internetarchive的朋友所做的出色工作,以解决404错误,并数字保存了Wikipedians在创建世界上最大的百科全书时引用的站点和源的链接。
当然,如今,Internet存档提供的不仅仅是文本。 他的新闻集涵盖了超过160万个新闻节目,其中包括诸如在字幕中搜索单词和访问最新新闻的工具(广播会在24小时后提供,然后以两分钟可搜索的段落形式提供给访问者)。 Internet档案馆中不断增长的音频和音乐部分涵盖了广播新闻,播客和物理媒体(例如,波士顿图书馆最近捐赠的
200册78年代专辑 )。 而且,正如Ars所写,该组织拥有
广泛的经典视频游戏收藏 ,任何人都可以将其上传到基于浏览器的模拟器中进行研究或休闲。 正式地,该部分包括大约300,000多个标题,“格雷厄姆说:“因此,您现在可以在浏览器中的旧Apple C计算机上实际播放Oregon Trail-无需广告,无需用户跟踪。
他说:“有些人可能称我们为普鲁什金斯。” “我想说我们是档案保管员。”
格雷厄姆说,一般来说,每年将4 PB的信息添加到Internet存档(上下文中为400万GB)。 当前的组织数据为22 PB,但是Internet档案馆实际上拥有44 PB。 “因为我们偏执,”格雷厄姆说。 “汽车可能会失败,而且我们享有声誉。” 这款
受NASA启发的信条帮助一家非营利组织度过了一场火灾,这场火灾造成的
损失近60万美元 ,而这一切都没有丢失档案数据。
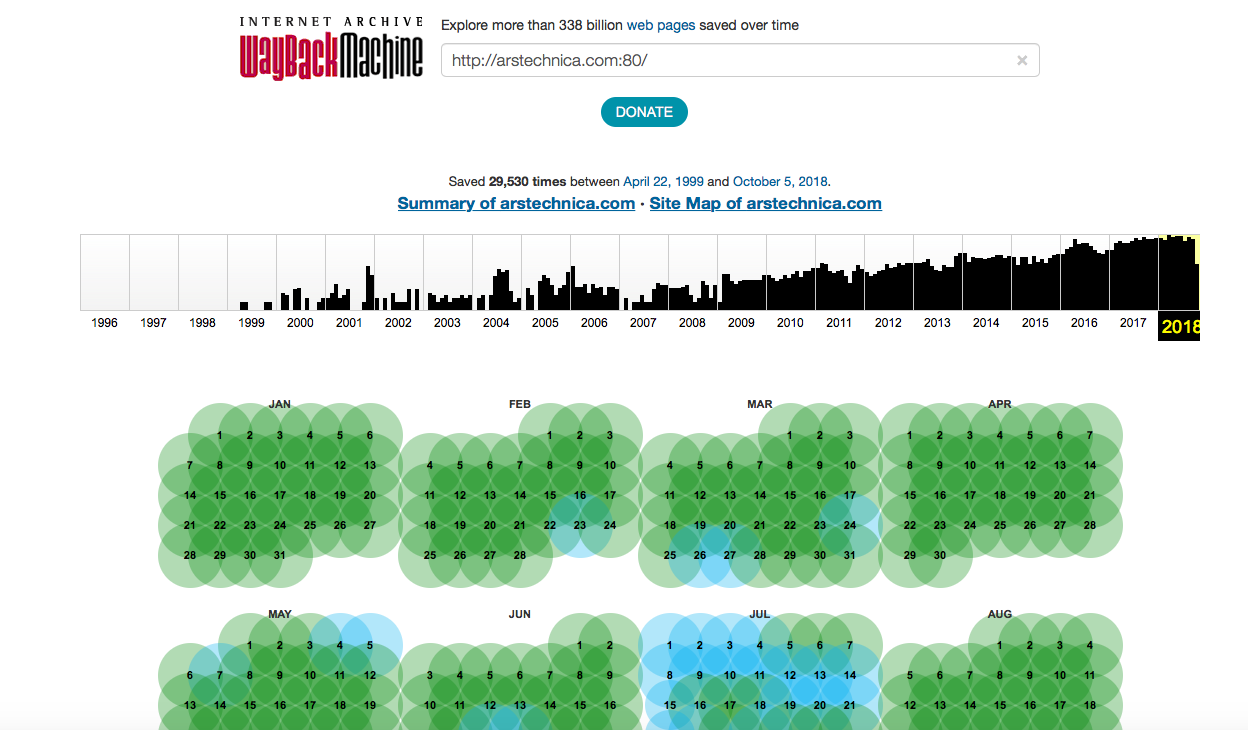 30,000个输入? 还不错,而且Wayback Machine机器人似乎肯定增加了对Ars的喜爱。
30,000个输入? 还不错,而且Wayback Machine机器人似乎肯定增加了对Ars的喜爱。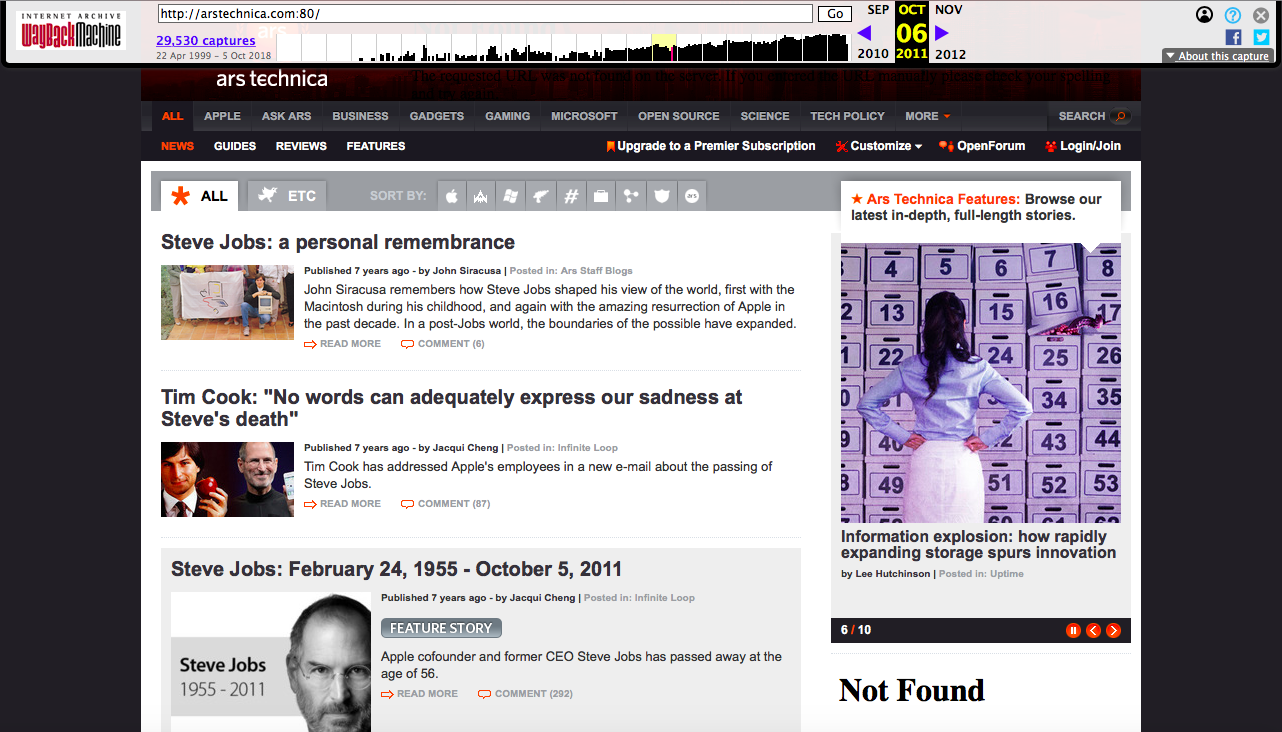 使用Wayback Machine,您可以记住并思考Ars如何掩盖了史蒂夫·乔布斯(Steve Jobs)在2011年10月去世的情况。
使用Wayback Machine,您可以记住并思考Ars如何掩盖了史蒂夫·乔布斯(Steve Jobs)在2011年10月去世的情况。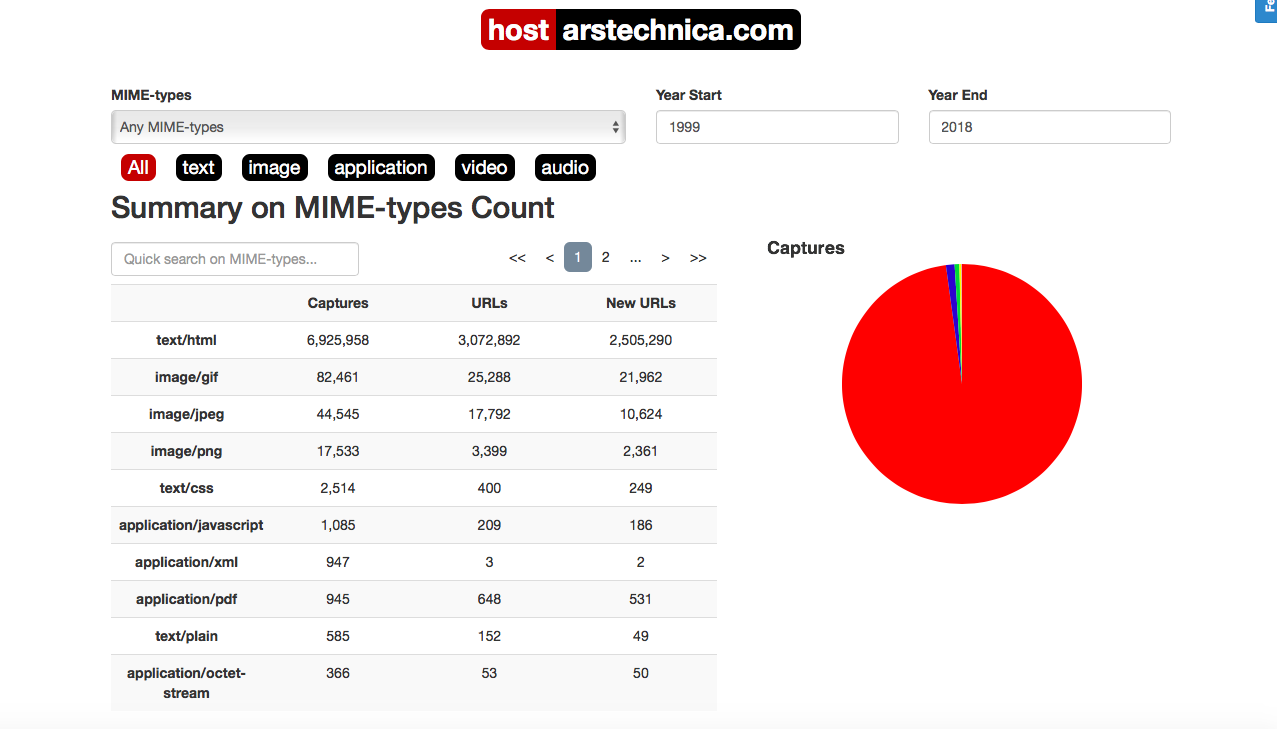 嗯...也许我仍然有机会成为Arsian / Arsian,以下载Internet Archive捕获的第1000个PDF。
嗯...也许我仍然有机会成为Arsian / Arsian,以下载Internet Archive捕获的第1000个PDF。普遍获取知识(以及事实,大量事实)
在过去22年中,Internet存档的总体概念很简单:
“对所有知识的普遍访问”。 当然,在Internet时代,这意味着要引入一小群僵尸程序,Graham指出Internet Archive始终具有收集内容的软件。 整个网络中大约有7,000个并发进程,最终每周将收到15亿个不同的项目。 某些内容(例如Google主页或《纽约时报》)一天可以查看多次; 其他人的观看频率可能会降低。
“我们正在努力获取所有东西,但这很难,” Graham指出。 “嵌入式,JavaScript,交互式应用程序-我们无法获得其中的一些材料,但我们正在努力。”
我们正在处理的事物的缓存包括诸如Snapchat或Telegram公共团体之类的临时媒体,而Wayback Machine则在某些媒体档案或服务器可能面临风险的地方维护本地联系人(Graham最近在以埃及为例)。
所有这些的结果是,Wayback Machine变得比过去有趣的LiveJournals有用得多。 Ars多次将其用于各种目的,从
捕获Comcast的网络中立性变化到国防分布式组织描述的演变。 格雷厄姆(Graham)指出
,2018年特朗普总统
在推特上发文称,谷歌并未在其首页上促进与美国的良好关系(与过去一样),最近
有争议 。 在Google回答这个问题之前,该公司通过一个简单的问题转向Internet存档-是否有副本?
格雷厄姆说:“我爱Google,但他们的工作不是每10分钟复制一次主页。” “这是我们的工作。”
格雷厄姆分享了Wayback Machine实际上在2018年1月查获了835份Google主页。 “通过这种方式,我们能够帮助收集记录。 我们不是站在一边,但我们是为了真理。”
当白宫最近
删除其新闻通讯的所有存档时,该网站发挥了类似的作用,许多组织(不仅是新闻组织,还包括环境组织或ACLU)都需要它们。 从Wayback Machine获得的资料
被用作法庭证据 。 他补充说:“就时间而言,发生了许多事件。” 作为前NBC新闻副总裁(也许因此他希望参加ONA),格雷厄姆还自豪地指出,该媒体每天被该网站引用5次。
Graham说Wayback Machine正在努力改进其用户工具以改善站点。 在Wayback Machine主页的左下角,您会找到例如
公共API 。 Graham指出,人们使用它们来创建类似
差异化器的功能 ,您可以在其中进行两次扫描,将它们并排放置并查看更改。 用户创建的另一个吸引了他注意力的工具,使您可以查看站点并制作
放射状树形图,以查看其结构随时间的变化 。
尽管对于所有人来说,最简单,最有效的工具可能是直接来自Wayback Machine的技术,但该站点允许某人手动将链接发送到Internet存档,以直接从其主页进行存档。 “如果我在花园里walk猫,并且在Google新闻上看到一个故事,则可以打印它。 但是今天您也可以将其发送到Internet存档,” Graham说。 根据他的估计,结果可能是每周大约一百万张照片。
他说:“我们在不作弊的情况下在一个非常大的网络上查找信息。” 而且,无论是机器人还是档案馆的业余爱好者发现了什么,其他人都可以欣赏发现内容的能力,这是
Ars Technica的
初衷 。 (幸运的是,在20年之后,还没有人告诉我们“
非常糟糕的事情,例如NT,Linux和BeOS内容在一个屋顶下。”)
翻译:戴安娜·谢列米诺娃(Diana Sheremyova)

关于#philtech#philtech(技术+慈善事业)是公开的,公开描述的技术,通过创建透明的平台进行交互以及访问数据和知识,从而使尽可能多的人的生活水平保持一致。 并满足filtech的原则:
1.开放和复制,非竞争性专有。
2.建立在自组织和横向互动的原则上。
3.可持续和以观点为导向,而不是追求本地利益。
4.建立在[开放]数据之上,而不是传统和信仰
5.非暴力和非操纵性。
6.具有包容性,不能为一群人工作而以其他人为代价。
PhilTech社会技术初创公司加速器是一项旨在早期项目密集开发的计划,旨在使获得信息,资源和机会的机会均等。 第二流:2018年3月– 6月。
在电报中聊天一群开发filtech项目或仅对社会部门的技术主题感兴趣的人。
#philtech新闻电报频道,其中包含有关#philtech意识形态项目的新闻,以及指向有用资料的链接。
订阅每周新闻