您好,哈布罗夫斯克市民! EastBanc Technologies有大量与移动开发相关的项目。 在这方面,需要整个设备的动物园来进行所有阶段的测试。 而且,典型地,各种各样的人不断需要每一个设备,即使在几十个人的移动开发部门中找到它也是一个故事。 更不用说最后有测试人员,设计师,项目经理!
为了不丢失电话,而是清楚地知道它在哪里以及与谁在一起,我们使用了一个在线数据库,该数据库可以根据员工的面孔来识别他们。 现在,我们将告诉我们如何实现它并实现它。

历史背景
我们有一个带有基本信息的设备“卡”的标牌,还有一块用来指示员工的磁铁。 每个人都提到要携带设备。

该系统有其缺点-不是很严重,但通常不舒服:
- 磁铁从一个地方移动到另一个地方并不是那么容易。
- 要查看这样的董事会,您肯定必须去另一个办公室。
- 而且,某人可能一次需要很多设备……这意味着每个员工需要几个磁铁。
- 哦,是的,甚至有时员工也会辞职而新员工来了,还需要制造磁铁。
行动应用程式
在一家从事业务流程自动化的公司中,使用上述“模拟”解决方案不是很健康。 自然,我们决定自动化寻找合适设备的任务。 第一步是编写一个移动应用程序,该应用程序可以通过Wi-Fi接入点确定并报告其在房间中的位置。 在整个过程中,为方便起见,他们使设备能够通知服务器有关OS版本的信息,并显示了诸如电池电量之类的重要特性。
看来问题已解决。 您查看数据库中设备上次看到Wi-Fi的列表,然后转到那里并...
在操作中,事实证明并非一切都那么简单。 我们在测试设备上安装了该应用程序,并使用了几个月。 原来,此选项很方便,但也不理想。
设备放电后,只需关闭电源,将Wi-Fi接入点从一个位置重新布置到另一个位置,而地理位置本身仅表示该设备在办公室中。 谢谢队长!
您当然可以尝试优化现有系统,但是为什么不基于21世纪的技术来重新发明它呢? 言归正传。
我们希望它成为
我们提出了一种系统的概念,该系统可以识别员工的脸孔,通过特殊标签测试设备,请求确认设备状态的变化,然后对在线数据库进行更改,任何员工都可以看到在线数据库而无需从椅子上站起来。
人脸识别
人脸识别整体上解决了2018年的问题。 因此,我们并没有重新发明轮子并尝试训练自己的模型,而是利用了现成的解决方案。
FaceRecognition模块似乎是最方便的选择,因为 它不需要额外的培训,即使没有在GPU上加速也可以非常快速地工作。
使用
face_locations函数,
可以在员工照片
中检测到面部,并使用
face_encodings从中提取特定员工的面部特征。
收到的数据收集在数据库中。 为了使用
face_distance函数确定特定员工,考虑了检测到的员工编码与数据库编码之间的“差异”。
通常,在这一阶段,可以进一步创建分类器,例如,基于
KNN的分类器,以便该系统对员工面孔动态的敏感度降低。 但是,实际上这需要大量时间。 如今,在数据库中的人脸与系统发现的更改设备状态的人脸之间的平均编码达到了平庸的平均水平,这足以避免在实践中累积错误。
人脸识别码face_locations = face_recognition.face_locations(rgb_small_frame) face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations) face_names = [] for face_encoding in face_encodings: matches = face_recognition.face_distance( known_face_encodings, face_encoding) name = "Unknown" if np.min(matches) <= 0.45: best_match_index = np.argmin(matches) name = known_face_info[str(best_match_index)]['name'] else: best_match_index = None
设备识别
最初,出现了使用
QR码进行设备识别的想法,在此同时输入有关设备的信息。 然而,为了稳定地识别QR码,必须将其非常靠近相机,这很不方便。
结果,出现了使用增强现实标记的想法。 它们携带的信息较少,但是被更稳定地识别。 在实验过程中,相机识别出了30毫米的标记,与垂直方向(3-5度)的偏差很小,最远可达两米半。
这个选项看起来好多了。
ARuco是从整套增强现实
标记中选择的 ,
opencv-contrib-python发行版中提供了使用它们的所有必需工具。
ARuco令牌识别码 self.video_capture = cv2.VideoCapture(0) ret, frame = self.video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) markers = cv2.aruco.detectMarkers(gray, self.dictionary)
结果,为每个设备分配了一个数字索引,标记与此索引相关联。
是帽子吗?
看来我们已经学会了识别设备和面部,这项工作已经完成。 夸奖,鼓掌! 可能还需要什么?
实际上,这项工作才刚刚开始。 现在,必须使系统的所有组件在战斗中稳定,快速地工作。
有必要优化空闲状态下服务器资源的成本,仔细考虑用户案例并了解其图形外观。
介面
此类系统开发中最重要的一点也许就是接口。 有人可能会争论,但是在这种情况下,用户是核心要素。
您可以尽快使用
Tkinter实现前端部分。
该界面由卡片组成,其中包含有关设备以及当前正在使用该设备的用户的信息。 屏幕的大部分内容都被卡目录占据-主要的会计工具。 顶部有一个过滤器,您可以使用该过滤器按平台或操作系统版本过滤目录。
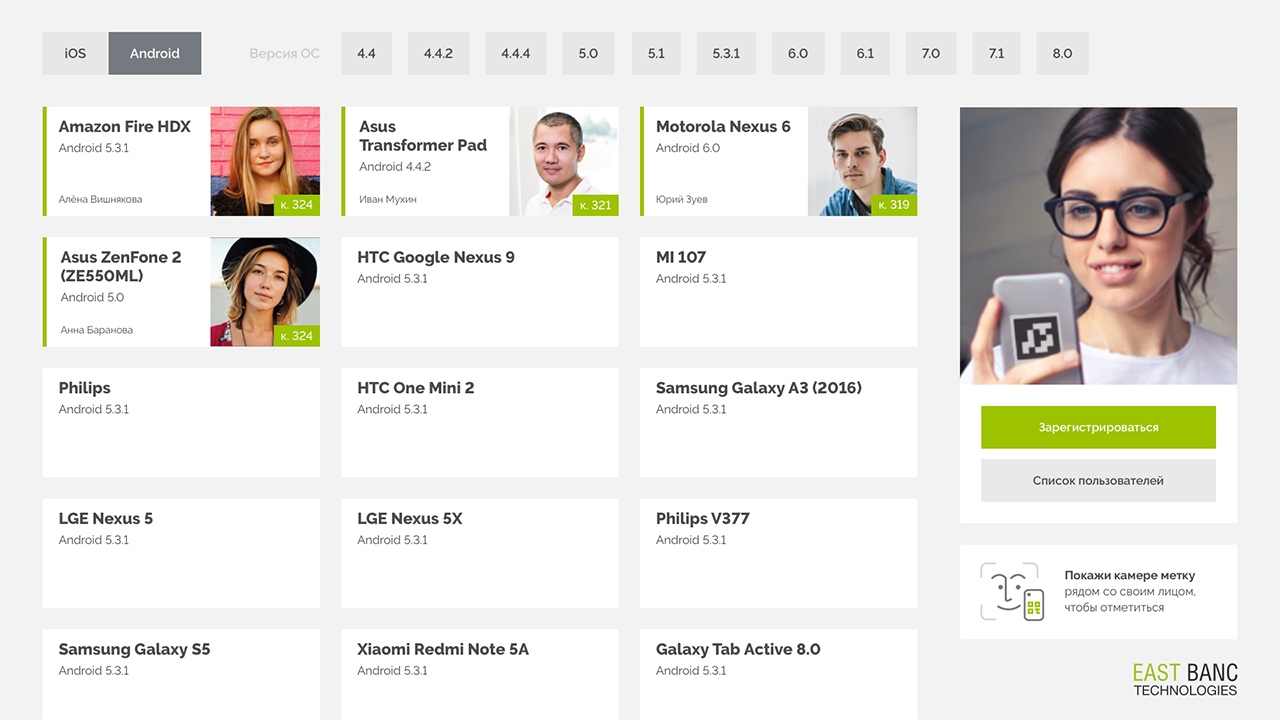
以下是界面的关键组件:
- 装置
设备卡将显示在屏幕上,其中包含操作系统的版本,设备的名称和ID以及当前已注册该设备的用户。 - 照相定影
右侧是控制单元,用于显示来自网络摄像头的图像,以及用于注册和编辑个人信息的按钮。
我们显示图像以给用户反馈-您一定会在屏幕上看到设备标签。 - 操作系统版本选择
我们列出了感兴趣的操作系统版本,因为 通常,对于测试,您不需要特定的设备,而需要特定版本的Android或iOS。 版本筛选器水平放置,以节省空间并在一个屏幕上无需滚动即可访问版本列表。
最佳化
系统任何组件的一次通过都不会花费太多时间。 但是,如果您同时开始识别标记和面部,则尝试识别相机每秒提供的所有30帧图像将导致在没有GPU的情况下完全耗尽计算机资源。
显然,系统将有99%的时间闲置此工作。
为了避免这种情况,做出了以下优化决策:
- 仅每第八帧被送入处理。
代号 if self.lastseen + self.rec_threshold > time.time() or self.frame_number != 8: ret, frame = self.video_capture.read() self.frame_number += 1 if self.frame_number > 8: self.frame_number = 8 return frame, None, None, None
系统的响应延迟上升到大约8/30秒,而人类的反应时间大约是一秒钟。 因此,这种延迟对于用户而言仍然不会被注意到。 而且我们已经减少了八倍于系统的负载。 - 首先,在框架中搜索设备标记,并且只有在检测到它时,才启动面部识别。 由于在帧中搜索标记的成本比搜索面部大约便宜300倍,因此我们决定在待机模式下,我们将仅检查标记的存在。
- 为了减少在图像中没有人脸时搜索人脸时的“刹车”,在face_locations函数中禁用了number_of_time_to_upsample参数。
face_locations = face_recognition.face_locations(rgb_small_frame,number_of_times_to_upsample = 0)
因此,在其上没有面部的帧的处理时间等于在其中容易检测面部的帧的处理时间。
结果如何?
目前,该系统已成功部署在即将推出的MacMini 2009上的两个Core 2 Duo内核上。 作为测试的一部分,它甚至可以在Docker容器中的一个具有1024 MB RAM和4 GB只读内存的虚拟内核上运行得非常成功。 MacMini连接了触摸屏,使外观简约。
现在,即使是那些不热衷于使用旧板的用户,也对自己注册设备微笑的人,搜索失败的情况要少得多!
接下来是什么?
毫无疑问,当前系统中还有很多可以改进的方面:
- 确保在出现对话框时没有出现OS控件(现在这是Tkinter包中的消息框)。
- 通过接口处理将计算和服务器请求分成不同的线程(现在它们在主线程mainloop Tkinter中执行,该主线程在将请求发送到在线数据库时冻结了接口)。
- 将接口与其他公司资源用于同一设计。
- 制作完整的Web界面以远程查看数据。
- 使用语音识别来确认/取消操作并填写文本字段。
- 同时实现多个设备的注册。
PS这就是它的工作原理。以GUI测试版录制的视频