在社交网络中,由于严格限制消息的长度,Twitter被迫放置所有最重要的内容,因此,Twitter比其他网络更适合提取文本数据。
我建议猜猜这个词云采用什么技术?
使用Twitter API,您可以提取和分析各种信息。 有关如何使用编程语言R进行此操作的文章。
编写代码不需要花费太多时间,但由于Twitter API的更改和收紧而可能导致困难,显然,在对“俄罗斯黑客”对2016年美国大选影响力进行调查后,该公司在美国国会被撤出后,该公司严重担心安全问题。
存取API
为什么有人需要从Twitter检索工业数据? 好吧,例如,它有助于对体育赛事的结果做出更准确的预测。 但我确定还有其他用户方案。
首先,您显然需要拥有一个带电话号码的Twitter帐户。 这是创建应用程序所必需的,正是这一步可以访问API。
我们转到开发人员页面,然后单击创建应用程序按钮。 接下来是您需要在其中填写有关应用程序信息的页面。 当前页面由以下字段组成。
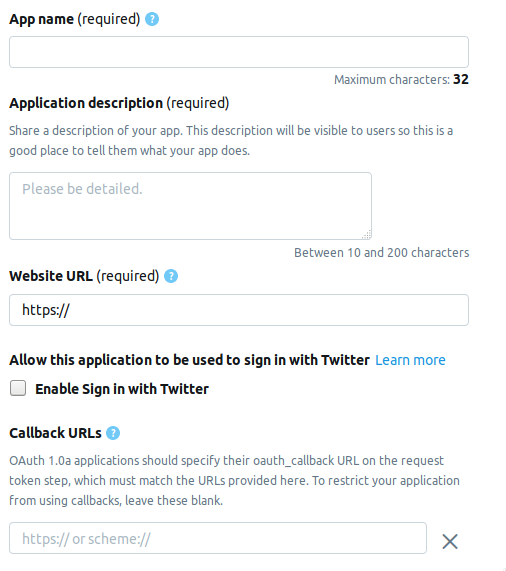
- AppName-应用程序名称(必填)。
- 应用程序描述 -应用程序描述(必填)。
- 网站网址 -应用程序网站的页面(必填),您可以输入任何看起来像网址的内容。
- 启用“使用Twitter登录” (复选框)-可以忽略从Twitter上的应用程序页面登录。
- 回调URL-身份验证期间对应用程序的回调 (必需), 必要时 ,您可以离开
http://127.0.0.1:1410 。
以下是可选字段:服务条款的页面地址,组织名称等。
创建开发者帐户时,请选择三个可能的选项之一。
- 标准 -基本版本,您可以免费搜索≤7天的记录。
- 高级 -一种更高级的选项,您可以搜索2006年以来≤30天的记录。免费,但是考虑应用程序时它们不会立即消失。
- 企业 -商务舱,收费可靠。
我选择了Premium ,大约需要一个星期的时间才能等待批准。 我无法告诉所有人他们是否连续把它给我,但是无论如何还是值得尝试的,而且Standard不会随处可见。
Twitter连接
创建应用程序后,包含以下元素的集合将出现在“ 密钥和标记”选项卡中。 以下是R的名称和相应的变量。
消费者API密钥
- API密钥
api_key - API密钥
api_secret
访问令牌和访问令牌密钥
- 访问令牌
access_token - 访问令牌机密
access_token_secret
安装必要的软件包。
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
这段代码看起来像这样。
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
身份验证后,R将提示您将OAuth代码保存在磁盘上以备后用。
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
两种选择都是可以接受的,我选择了第一种。
搜索和过滤结果
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
include_rts键可让您控制是否在搜索中包含或不包含转发。 在输出中,我们得到一个包含许多字段的表,其中包含每个记录的详细信息。 这是前20个。
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
您可以编写更复杂的搜索字符串。
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
搜索结果可以保存在文本文件中。
write.table(tweets$text, file="datamine.txt")
我们合并到正文中,从服务词,标点符号中过滤掉并将所有内容转换为小写。
还有另一个搜索功能searchTwitter ,它需要twitteR库。 在某些方面,它比search_tweets方便,但在某些方面却不如它。
加号 -按时间显示过滤条件。
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
减号 -输出的不是表,而是status类型的对象。 为了在我们的示例中使用它,我们需要从输出中提取一个文本字段。 这使得第二行变得很sapply 。
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
在第二行中,需要tm_map函数才能将任何表情符号字符转换为小写,否则使用tolower转换为小写将失败。
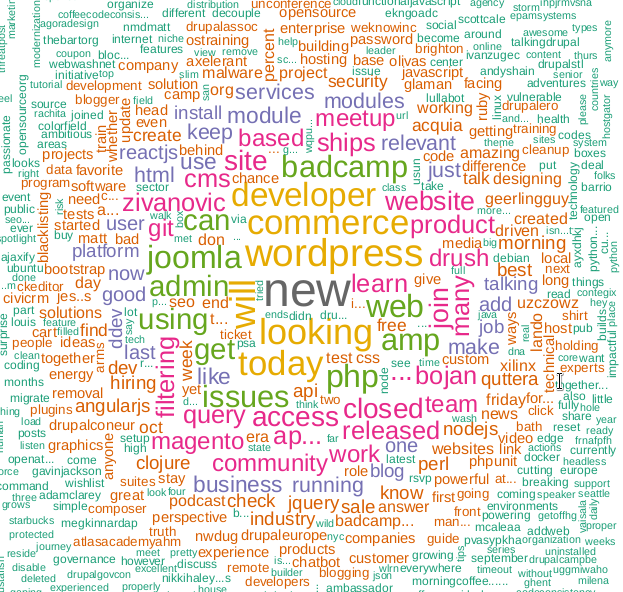
建立文字云
据我所知,词云首次出现在Flickr照片托管上,此后逐渐流行。 对于此任务,我们需要wordcloud库。
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
search_string函数允许您将语言设置为参数。
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
但是,由于R的NLP软件包的俄化程度很差,尤其是没有服务或停用词的列表,因此,我没有用俄语进行搜索来构建词云。 如果您在评论中找到更好的解决方案,我将非常高兴。
好吧,实际上...
整个剧本 library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
用过的材料。
短链接:
原始链接:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS提示,该程序中未使用KDPV上的cloud关键字,它与我以前的文章相关联。