检查一台服务器不是问题。 您可以检查清单并按顺序检查:处理器,内存,磁盘。 但是,如果有一百台服务器,则此方法不太可能很好用。 为了排除人为因素,使检查更可靠,更快捷,有必要使过程自动化。 谁需要比托管服务提供商更好地做到这一点。 HighLoad ++ Siberia上的Artyom Artemyev告诉我们可以使用哪些方法,什么方法可以更好地运行,以及哪种方法可以实现自动化。 此外,该报告的文本版本会提示您使用烙铁的任何需要定期检查其性能的提示都可以重复。
 关于演讲者:
关于演讲者: Artyom Artemyev(
artemirk )是大型托管服务提供商FirstVDS的技术总监,他使用Iron。
FirstVDS有两个数据中心。 首先是他们自己,他们自己建造建筑物,带来并安装机架,自己维护,担心数据中心的电流和散热。 第二个数据中心是一个出租的大型数据中心中的一个大房间,一切都比较容易,但是它也存在。 总共有60个机架和大约3000个铁服务器。 有一些东西可以实践和测试不同的方法,这意味着我们正在等待实践确认的建议。 让我们开始查看或阅读报告。
大约6至7年前,我们意识到仅将操作系统放在服务器上是不够的。 操作系统已打开,服务器已醒来并准备战斗。 我们在生产中启动它-令人费解的重启和冻结开始。 目前尚不清楚该怎么办-该过程正在进行中,将整个工作草案转移到一块新的金属上很难,昂贵且痛苦。 在哪里跑?
现代部署方法使我们能够避免这种情况,并在5秒钟内运输服务器,但是我们的客户(尤其是6年前)只是没有在云端飞翔,没有在地面上行走并使用了普通的铁片。

在本文中,我将告诉您我们尝试了哪些方法,扎根了哪些方法,未扎根了哪些方法,哪些方法可以手动运行以及如何使所有这些自动化。 我会给您建议,如果您有铁的需求并且您有这样的需要,您可以在公司中重复。
怎么了
从理论上讲,检查服务器不是问题。 最初,我们有一个过程,如下图所示。 一个人坐下,检查清单,检查:处理器,内存,磁盘,前额皱纹,做出决定。
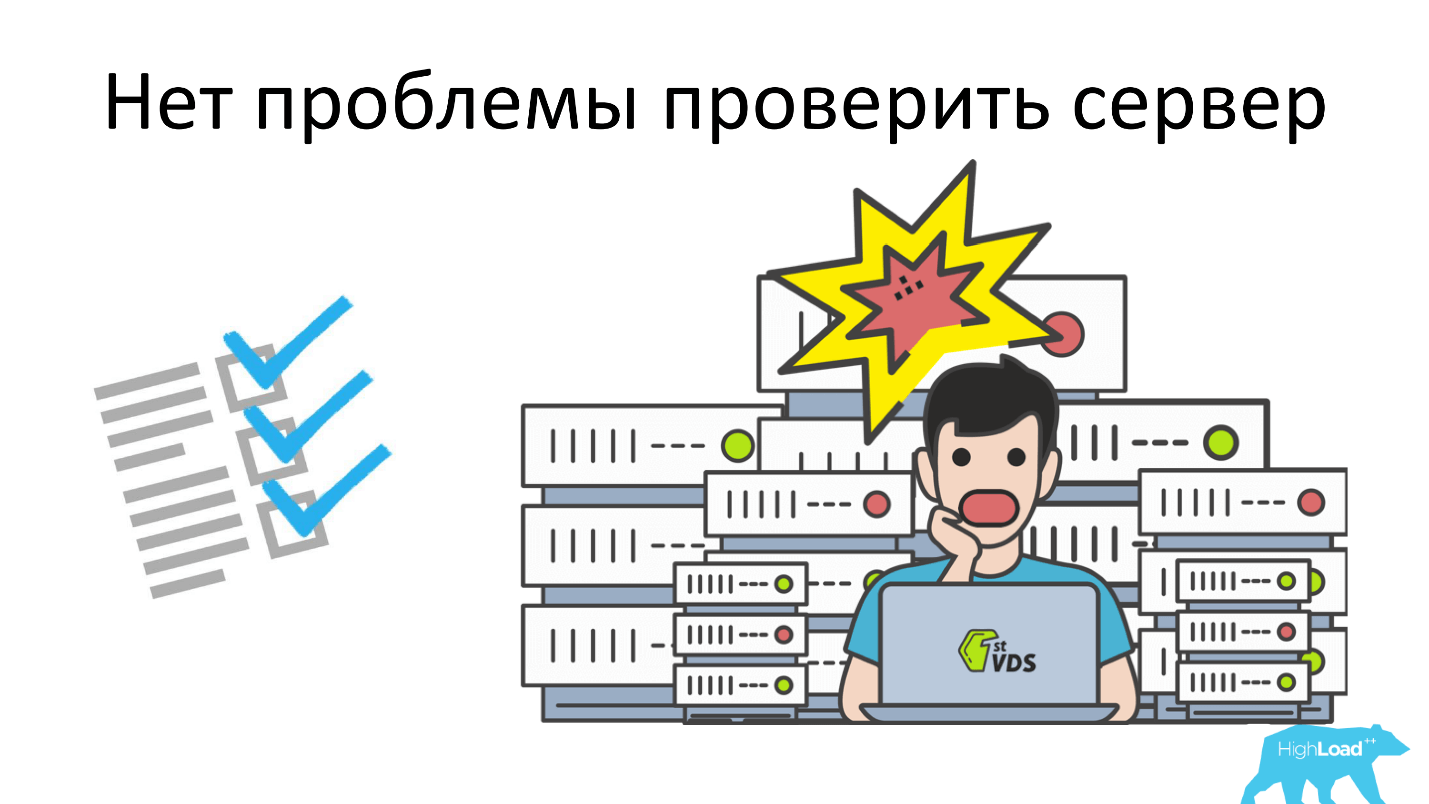
然后每月安装3台服务器。 但是,当服务器越来越多时,此人开始哭泣并抱怨自己快死了。 一个人越来越容易出错,因为验证已成为常规。
我们做出了决定:我们实现自动化! 一个人会做更多有用的事情。
短途旅行
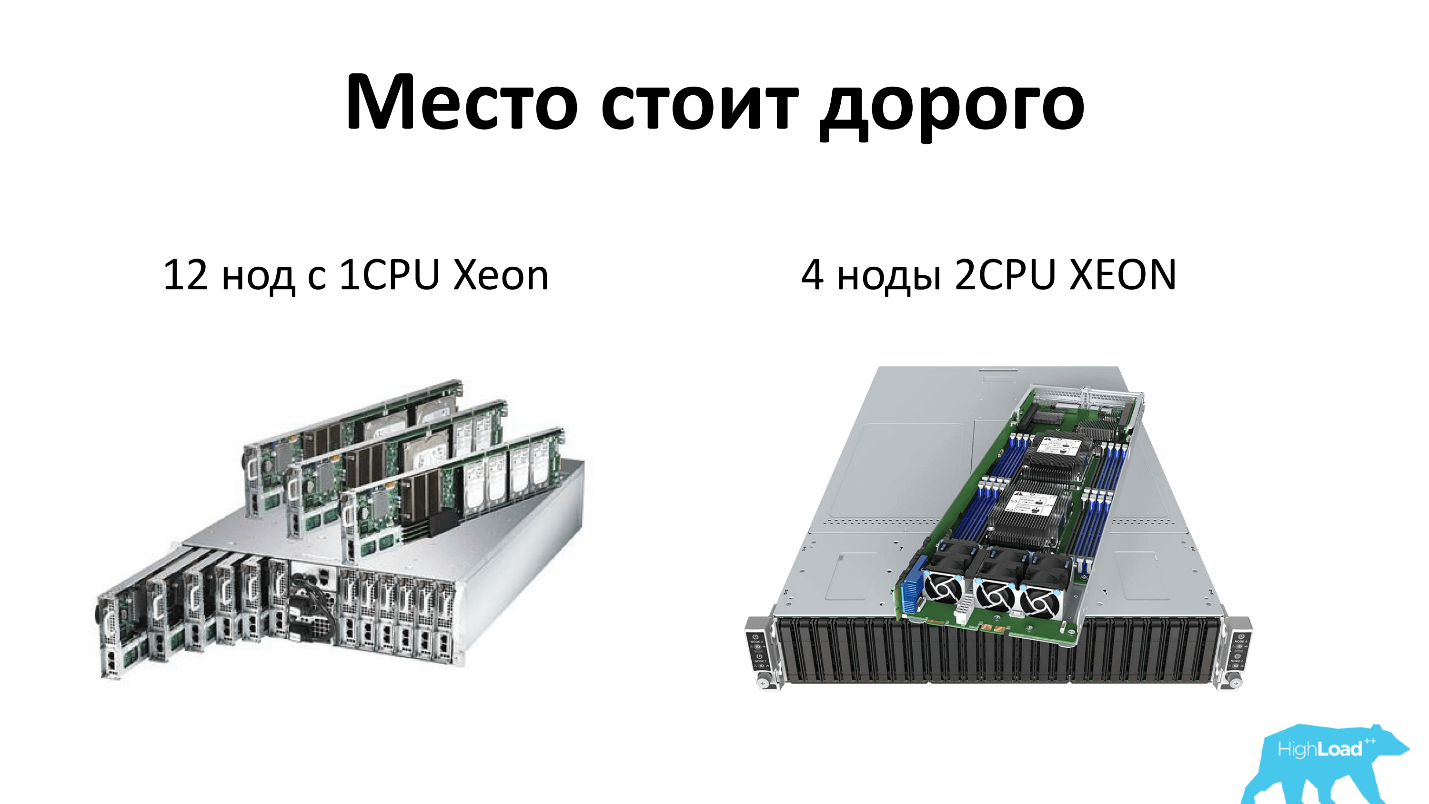
我将在今天谈论服务器时阐明我的意思。 与其他所有人一样,我们节省了机架空间并使用了高密度服务器。 今天,它有2个单元,可以容纳12个单处理器服务器节点或4个双处理器服务器节点。 也就是说,每个服务器都有4个磁盘-老实说。 另外,机架中有两个电源,也就是说,一切都是多余的,每个人都喜欢。
铁从哪里来?
我们的供应商(通常是超微和英特尔)将铁运到我们的数据中心。 在数据中心,我们的操作员将服务器安装在机架中的空白空间中,并连接两根电线,网络和电源。 操作员还负责在服务器中配置BIOS。 也就是说,连接键盘,监视并配置两个参数:
Restore on AC/Power Loss — [Power On] ,以便在电源出现后服务器始终打开。 它应该不间断地工作。 第二个
First boot device — [PXE] ,也就是说,我们将第一个引导设备放置在网络上,否则我们将无法访问服务器,因为它不是立即具有磁盘等事实。

此后,操作员将打开Iron服务器的记帐面板,您需要在其中记录安装服务器的事实,并为此进行指示:
此后,出于安全目的,操作员安装新服务器的网络端口将转到一个特殊的隔离VLAN,该隔离VLAN也挂起DHCP,Pxe,TFtp。 接下来,服务器加载我们最喜欢的Linux,该Linux具有所有必需的实用程序,然后开始诊断过程。
由于服务器仍然是网络上的第一个引导设备,因此对于投入生产的服务器,端口将切换到另一个VLAN。 另一个VLAN中没有DHCP,因此我们不担心会意外地重新安装生产服务器。 为此,我们有一个单独的VLAN。
碰巧已经安装了服务器,一切都很好,但是它没有启动到诊断系统中。 通常会发生这种情况,这是因为在交换VLAN时存在延迟,并非所有网络交换机都会快速交换VLAN等。

然后,操作员将用手接收重新启动服务器的任务。 以前,没有IPMI,我们设置了远程套接字,并固定了服务器套接字的端口,通过网络拉出套接字,然后服务器重新启动。
但是,受管理的出口也并非总是能正常工作,因此我们现在通过IPMI管理服务器电源。 但是,当服务器是新服务器时,未配置IPMI,只能通过向上并按按钮来重新引导它。 因此,一个人坐着,等待-灯亮-运行并按下按钮。 这是他的工作。
如果此后服务器没有启动,则将其输入特殊列表进行修复。 此列表包括未启动诊断或结果不令人满意的服务器。 一个热爱铁的人每天都会坐着和拆卸,他们会收集,看东西,为什么不起作用。
中央处理器
一切都很好,服务器已经启动,我们开始测试。 首先,我们将处理器作为最重要的元素之一进行测试。

第一个冲动是使用供应商的应用程序。 我们几乎拥有所有的英特尔处理器-我们去了网站,下载了英特尔处理器诊断工具-一切都很好,它显示了很多有趣的信息,包括服务器的工作小时数(小时)和功耗图。
但是问题在于,英特尔PTD在Windows下可以运行,我们不再喜欢了。 要在其中开始测试,只需移动鼠标,然后按“开始”按钮,测试就会开始。 结果显示在屏幕上,但是无法将其导出到任何地方。 这不适合我们,因为该过程不是自动化的。

我们去阅读了论坛,发现了两种最简单的方法。
- 永恒的循环cat / dev / zero> / dev / null 。 您可以排在最前面-100%使用一个内核。 我们计算核心数,运行所需的cat / dev / zero数,再乘以所需的核心数。 一切正常!
- 效用/箱/压力 。 她在内存中建立矩阵,并开始不断将它们翻转。 一切也都很好-处理器正在预热,有负载。
我们将服务器投入生产,用户回来后说处理器不稳定。 已检查-处理器不稳定。 他们开始调查,并通过了服务器,服务器通过了检查,但是它在战斗中崩溃,在Linux中打开了调试内核,并收集了Core dump。 重新启动之前,服务器会将崩溃前内存中的所有内容刷新到文件中。

处理器中内置了各种优化功能,可以频繁运行。 我们可以看到一些标志,这些标志反映了处理器支持的优化,例如,用于浮点数的优化,多媒体优化等。 但是我们的/ bin /压力以及永恒的周期只会在一次操作中烧毁处理器,并且不会使用其他功能。 调查表明,尝试使用内置标志之一的功能时CPU崩溃。
第一个冲动是离开/垃圾箱/压力-让处理器变热。 然后在一个周期中,我们遍历所有标志,将其拉出。 在考虑如何实现此功能(调用哪个命令以调用每个标志的功能)的同时,我们阅读了论坛。
在超频论坛上,我们偶然发现了一个有趣的项目,用于搜索质数
Great Internet Mersenne Prime Search 。 科学家们已经建立了一个分布式网络,任何人都可以连接到该网络并帮助找到素数。 科学家们不相信任何人,因此该程序运行得非常巧妙:首先运行它,它会计算它已经知道的素数,并将结果与已知的结果进行比较。 如果结果不匹配,则说明处理器出现故障。 我们真的很喜欢这个属性:废话容易掉下来。
此外,该项目的目标是找到尽可能多的质数,因此该程序针对新处理器的属性进行了不断优化,因此产生了很多障碍。
Mprime没有时间限制,如果不停止,它将永远有效。 我们运行了30分钟。
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
完成工作之后,我们检查result.txt中是否没有错误,并查看内核日志,尤其是在/ proc / kmsg文件中查找错误。
另一个游览

在2018年1月3日,他们找到了第50个梅森素数(2
p -1)。 其中只有2300万个数字。 您可以下载它进行查看-
这是
一个12 Mb的zip存档 。
为什么我们需要质数? 首先,任何RSA加密都使用质数。 我们知道的素数越多,您的SSH密钥越可靠。 其次,科学家检验他们的假设和数学定理,我们不介意帮助科学家-这不花任何钱。 事实证明双赢的历史。

因此,处理器正常工作,一切都很好。 仍然需要找出它是哪种处理器。 我们使用dmidecode -t处理器,查看主板上的所有插槽以及这些插槽中的哪些处理器。 这些信息进入我们的会计系统,我们将在以后进行解释。
赶上
因此,令人惊讶地,发现了腿部骨折。 / bin /压力和永续周期奏效,Mprime倒下。 他们开车行驶了很长时间,经过搜索,发现-下图中的结果-此处一切都清晰可见。

这样的处理器根本无法启动。 操作员非常强大,使用了错误的处理器-但可以交付。

另一个漂亮的案例。 下方照片中的黑色行是风扇,箭头显示了空气如何吹动。 我们看到:散热器横穿溪流。 当然,一切都过热并关闭。

记忆
有了内存,一切都变得非常简单。 这些是我们在其中写入信息的单元格,过了一会儿我们再次读取它。 如果仍然存在我们记下的内容,则此单元正在工作。

每个人都知道很好的,直接经典的
Memtest86 +程序,该程序可以通过任何介质,网络甚至是软盘运行。 这样做是为了检查尽可能多的存储单元。 无法再检查任何已占用的单元格。 因此,memtest86 +具有最小大小,以便不占用内存。 不幸的是,
memtest86 +只在屏幕上显示其统计信息 。 我们试图以某种方式对其进行扩展,但这全都归结为一个事实,即程序内部甚至没有网络堆栈。 为了扩展它,必须带上Linux内核和其他所有东西。
该程序有一个付费版本,它已经知道如何将信息拖放到磁盘上。 但是,我们的服务器并不总是具有磁盘,并且这些磁盘上也不总是具有文件系统。 但是,我们已经发现,网络驱动器无法连接。
我们开始进一步挖掘,发现了一个类似的
Memtester程序。 该程序从Linux的OS级别运行。 最大的缺点是OS本身和Memtester占用了一些内存单元,因此将不检查这些单元。
Memtester使用以下命令启动:memtester`cat / proc / meminfo | grep MemFree | awk'{print $ 2-1024}''k 5
在这里,我们传输的可用内存量为1 MB。 这样做是因为,否则Memtester会占用所有内存,而down killer会杀死它。 我们将这个测试驱动5个周期,在输出处,我们有一个板合格或不合格。
| 卡住的地址 | 好啦 |
| 随机值 | 好啦 |
| 比较异或 | 好啦 |
| 比较SUB | 好啦 |
| 比较MUL | 好啦 |
| 比较DIV | 好啦 |
| 比较或 | 好啦 |
| 比较AND | 好啦 |
我们保存最终结果,并进一步分析故障。

要了解问题的严重程度-我们最小的服务器具有32 GB的内存,带有Memtester的Linux映像占用60 MB,因此
我们不检查2%的内存 。 但是根据过去6年的统计,还没有发生过这样的事情,坦率地说,内存投入生产了。 这是我们同意的折衷办法,对于我们来说,它是昂贵的,并且我们可以忍受。
在此过程中,我们还收集了dmidecode -t内存,该内存提供了主板上我们拥有的所有内存库(通常最多24个),并且每个库中都有裸片。 如果我们要升级服务器,则此信息很有用-我们将知道在哪里添加内容,要带多少条带以及要去哪台服务器。
储存装置
6年前,所有的碟片都带有旋转的薄煎饼。 一个单独的故事是仅汇总所有磁盘的列表。 有几种不同的方法,因为不相信您可以只看ls / dev / sd。 但是最后,我们不再关注ls / dev / sd *和ls / dev / cciss / c0d *。 在第一种情况下,它是SATA设备,第二种是SCSI和SAS。

从字面上看,今年他们开始销售nvme磁盘,并在此处添加了nvme列表。
编译完磁盘列表后,我们尝试从中读取0字节,以了解这是一个块设备,一切都很好。 如果您看不懂它,那么我们相信这是一种鬼影,并且我们也从未拥有过这样的磁盘。
第一种检查磁盘的方法是显而易见的:“让我们将随机数据写入磁盘并查看速度”
dd -o nocache -o direct if=/dev/urandom of=${disk} 。 通常,煎饼盘的输出速度为130-150 Mb / s。 我们起眼睛,自己决定是90 MB / s的数字,然后才是可用的磁盘,所有较小的磁盘都出现故障。
但是再次,用户开始返回并说硬盘坏了。 原来,阴险的物理学又在和我们开玩笑。
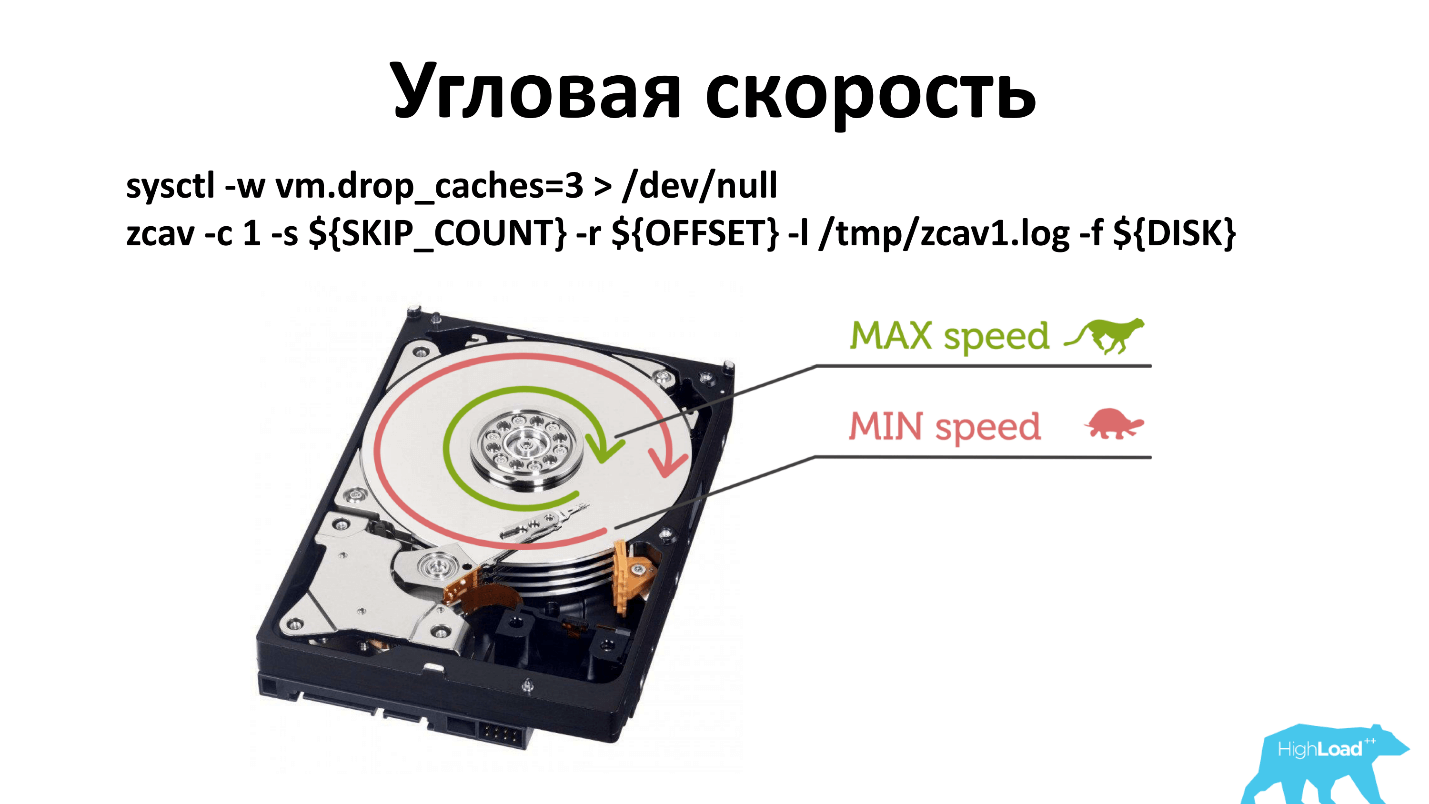
有角速度,通常,当您运行-dd时,它会写在主轴附近。 如果由于某种原因主轴速度降低了,那么这与从光盘边缘进行写入相比不太明显。
我不得不改变验证的原则。 现在我们检查三个位置:靠近主轴,中间和外部。 可能只能从外部进行检查,但这是历史上发生的情况。 什么有效,请勿触摸。
您可以使用
smartctl询问磁盘运行情况。 我们相信这是一个很好的驱动器:
- 没有重新分配的扇区(“ 重新分配的扇区数= 0”) ,即所有离开工厂工作的扇区。
- 我们不会使用4年以上的光盘 ,尽管它们可以正常工作。 在介绍这种做法之前,我们已经使用了7年的光盘。 现在,我们相信磁盘已经使用了4年,我们还没有准备好承受磨损的风险。
- 没有要重新分配的扇区( Current_Pending_Sector = 0 )。
- UltraDMA CRC错误计数= 0-这些是SATA电缆上的错误。 如果有错误,您只需要更换导线,就不需要更换磁盘。

分布式固态硬盘通常是出色的驱动器,它们工作迅速,不会产生噪音,不会发热。 我们认为,好的SSD的写入速度可超过200 MB / s。 我们的客户喜欢低廉的价格,发布320-350 MB / s的服务器型号并不总是可以找到我们。
对于SSD,我们也看起来很聪明。 相同的重新分配的Power_On_Hours,Current_Pending_Sector。 所有SSD都可以显示磨损程度,它显示参数Media_Wearout_Indicator。 我们会擦拭光盘直至其寿命达到5%,然后才将其取出。 此类光盘有时会在员工的个人需求中找到第二生命。 例如,我最近发现,在2年内,这种磁盘在员工笔记本电脑中又磨损了1%,尽管在我们国家,固态硬盘缓存下的磁盘在大约10个月内消耗了95%。
但是问题在于,并非所有磁盘制造商都同意参数名称,例如,该Media_Wearout_Indicator被称为Toshiba的Percent_Lifetime_Used,其他损耗均衡计数,其他制造商的剩余寿命百分比,或者仅仅是*磨损*。
Crucial根本没有此选项。 然后,我们只考虑光盘的重写量-“已写入字节”-我们已经向该光盘写入了多少字节。 此外,根据规范,我们试图找出制造商对该磁盘进行了多少次重写。 通过基础数学,我们可以确定他还能活多少。 如果该改变了,那就改变。
磁盘阵列
我不知道为什么在现代世界中我们的客户仍然需要RAID。 人们购买了RAID,并在其中放置了4个SSD,这比该RAID(6 Gb)快得多。 他们有某种指示,他们会收集。 我认为这几乎是不必要的事情。
曾经有3家制造商:Adaptec; 3件; 英特尔 我们有3个实用程序,我们很麻烦,但是我们为所有人运行了诊断程序。 现在,LSI收购了所有人-仅剩一个实用程序。
当我们的诊断系统看到RAID时,它将逻辑卷解析为单独的磁盘,以便您可以测量每个磁盘的速度并读取其Smart。 之后,RAID仍然可以检查电池。 谁不知道-RAID上有足够的电池可以使所有磁盘再旋转2个小时。 也就是说,您关闭服务器,将其取出,然后它将磁盘再旋转2小时以完成所有记录。
联播网
有了网络,一切都变得非常简单-数据中心内部的空间应小于300 Mbit。 如果更少,则需要修复它。 我们还将查看接口上的错误。
网络接口上的错误根本不应该是 ,如果是,那么一切都是不好的。
我们正在尝试一路更新BIOS和IPMI固件。 原来,我们不喜欢所有的BIOS。 我们仍然有不知道如何使用UEFI和我们使用的其他功能的BIOS。 我们尝试自动更新它,但这并不总是有效,那里的一切都不是那么简单。 如果不起作用,那么该人会去动手进行更新。
我们不会将IPMI Supermicro推向世界,而是通过OpenVPN将其放在灰色地址上。 但是,我们担心有一天另一种漏洞会出来,我们将遭受痛苦。 因此,我们尝试仅使IPMI固件始终保持最新状态。 如果不是这样,则进行更新。
奇怪的是,最近发现10和40千兆位网卡上的Intel不包含PXE引导。 事实证明,如果服务器位于只有40 GB卡的机架中,则无法通过网络进行引导,因为您需要引导至千兆卡。 我们分别在40G上闪存网卡,以便它们具有PXE并可以继续使用。
检查完所有内容后,服务器将立即开始销售 。 计算价格,然后将其放在网站上并出售。

总计,我们每月大约进行350次检查,其中69%的服务器可用,31%的服务器不可用。 这是由于我们拥有悠久的历史,有些服务器已经使用了10年。 大多数没有通过测试的服务器,我们只是抛出。
出于好奇:我们有3个客户仍住在奔腾IV上,不想离开任何地方。 它们具有512 MB的RAM。
未来来了! 如果今天我要围堵这个系统...

发行了一个很棒的实用程序
Hardware Lister (lshw),它可以与内核通信,精美地显示内核中包含哪种硬件,内核可以检测到什么。 并不需要所有这些舞蹈。 如果您重复-我强烈建议您查看并使用此实用程序。 一切都会变得更加简单。
总结:
- 妥协还不错,这只是价格问题。 如果解决方案非常昂贵,则需要寻找一个可以接受的可靠性和价格水平。
- 非核心程序有时很适合测试。 仍然只有找到它们。
- 测试您所达到的一切!
下一个大型HighLoad ++已于11月8日至9日在莫斯科举行。 该计划包括著名专家和新名字,传统和新任务。 例如,在DevOps部分中,以下内容已被接受:
研究报告列表,并赶快加入。 或订阅我们的时事通讯,您将定期收到报告,新文章和视频报告的评论。