 Python的完整机器学习入门:第三部分
Python的完整机器学习入门:第三部分许多人不喜欢机器学习模型是
黑匣子 :我们将数据放入其中,并获得没有任何解释的答案-通常是非常准确的答案。 在本文中,我们将尝试弄清楚我们创建的模型是如何进行预测的以及它可以告诉我们正在解决的问题的信息。 最后,我们讨论了机器学习项目中最重要的部分:我们记录已完成的工作并展示结果。
在
第一部分中,我们检查了数据清理,探索性分析,设计和功能选择。 在
第二部分中,我们研究了缺失数据的填充,机器学习模型的实现和比较,使用带有交叉验证的随机搜索的超参数调整,以及最终模型的评估。
所有
项目代码都在GitHub上。 与本文相关的第三个Jupyter Notebook位于
此处 。 您可以将其用于您的项目!
因此,我们正在使用机器学习或更确切地说使用监督回归来解决问题。 根据
纽约建筑物的能源数据,我们创建了一个预测能源之星得分的模型。 我们已经获得了“
基于梯度提升的回归 ”模型,该模型能够根据测试数据在9.1点(范围从1到100)之间进行预测。
模型解释
基于梯度提升的回归大约位于
模型可解释性范围的中间:模型本身很复杂,但是由数百个相当简单的
决策树组成 。 有三种方法可以了解我们的模型如何工作:
- 评估症状的重要性 。
- 可视化决策树之一。
- 应用LIME方法-本地可解释模型无关的解释,本地解释与模型无关的解释。
前两种方法是树集成的特征,而第三种方法(可以从其名称中了解)可以应用于任何机器学习模型。 LIME是一种相对较新的方法,在
解释机器学习的操作方面迈出了重要的一步。
症状的重要性
标志的重要性使您可以查看每个标志与预测目的之间的关系。 此方法的技术细节很复杂(测量了
由于包含特征而导致的平均减少的杂质或
误差的
减少 ),但是我们可以使用相对值来了解哪些特征更相关。 在Scikit-Learn中,您可以从任何基于树的“学生”集合中
提取属性的重要性 。
在下面的代码中,
model是我们训练有素的模型,并且使用
model.feature_importances_可以确定属性的重要性。 然后,将它们发送到Pandas数据框并显示10个最重要的属性:
import pandas as pd
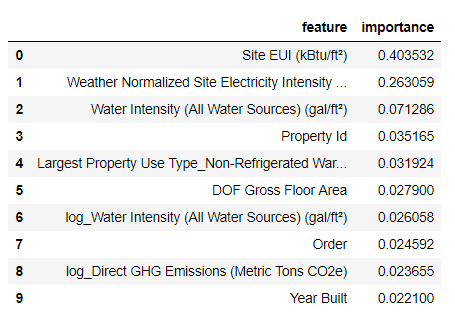
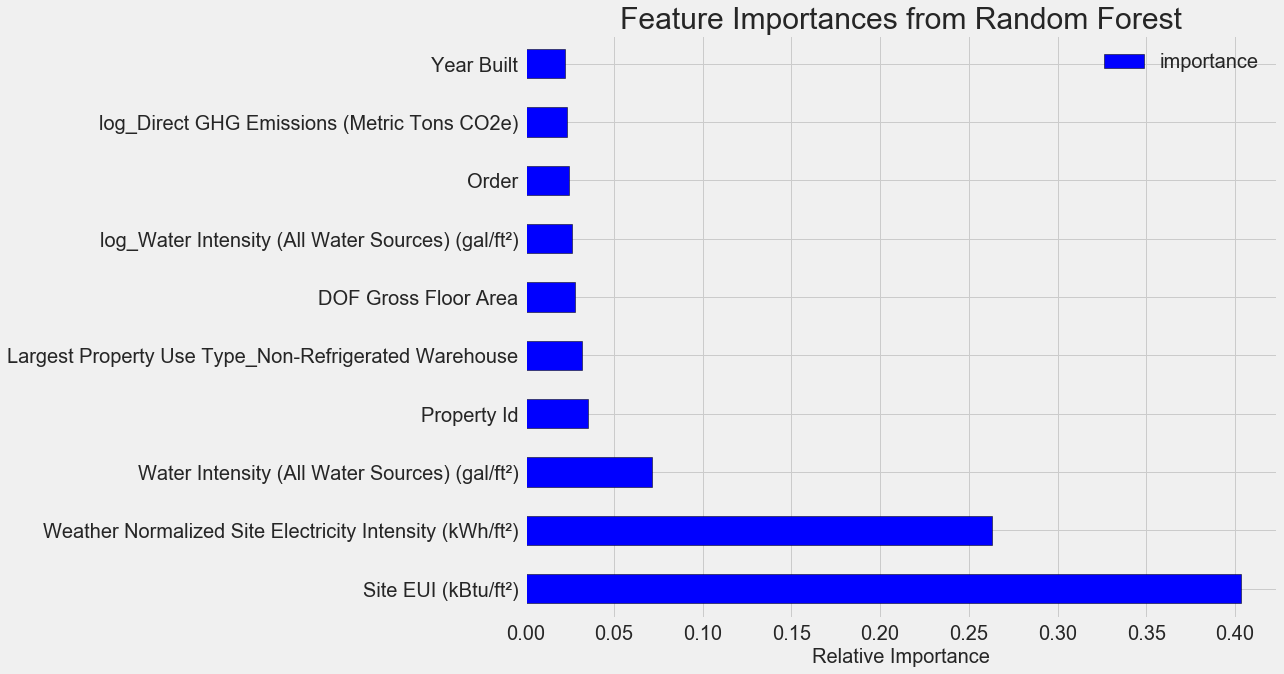
最重要的功能是
Site EUI (
能源消耗强度 )和
Weather Normalized Site Electricity Intensity ,占总重要性的66%以上。 在第三个属性上,重要性已经显着降低,这
表明我们不需要使用所有64个属性来实现较高的预测准确性(在
Jupyter笔记本中,仅使用10个最重要的属性对这一理论进行了测试,并且该模型不是很准确)。
根据这些结果,可以最终回答一个最初的问题:能源之星评分的最重要指标是站点EUI和天气归一化站点电强度。 我们不会
太过深入探讨属性的重要性 ,我们只会说,有了它们,您就可以开始通过模型来了解预测机制。
可视化单个决策树
很难理解基于梯度提升的整个回归模型,这对于单个决策树是无法说的。 您可以使用
Scikit-Learn- export_graphviz可视化任何树。 首先,从集合中提取树,然后将其另存为点文件:
from sklearn import tree
使用
Graphviz可视化工具,通过键入以下内容将点文件转换为png:
dot -Tpng images/tree.dot -o images/tree.png得到了完整的决策树:

有点麻烦! 虽然这棵树只有6层深,但很难追踪所有过渡。 让我们更改
export_graphviz函数
export_graphviz并将树的深度限制为两层:
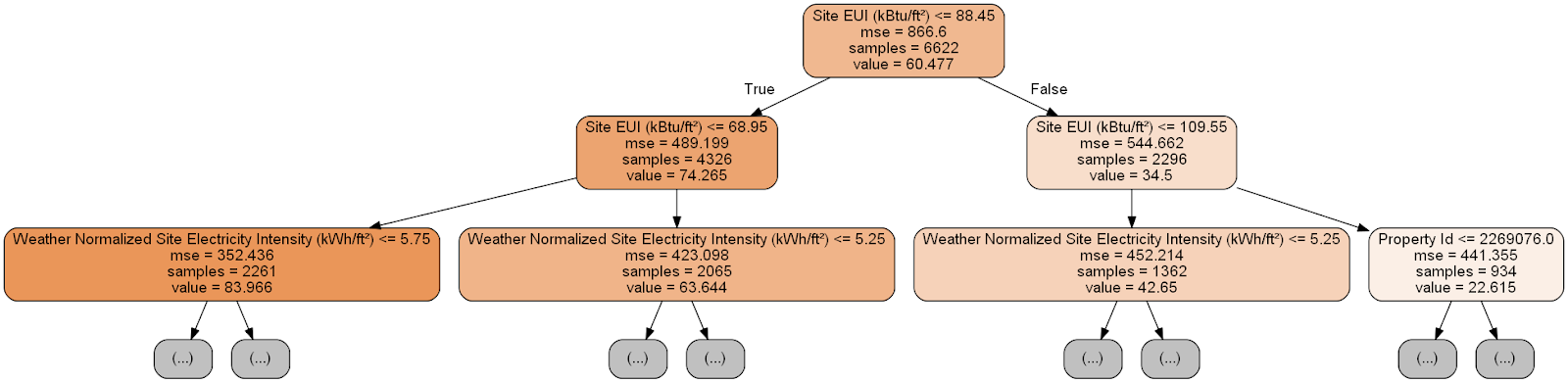
树的每个节点(矩形)包含四行:
- 有关特定维度的符号之一的值的询问的问题:这取决于我们将退出该节点的方向。
Mse是节点错误的度量。Samples -节点中数据样本(度量)的数量。Value -节点中所有数据样本的目标评估。
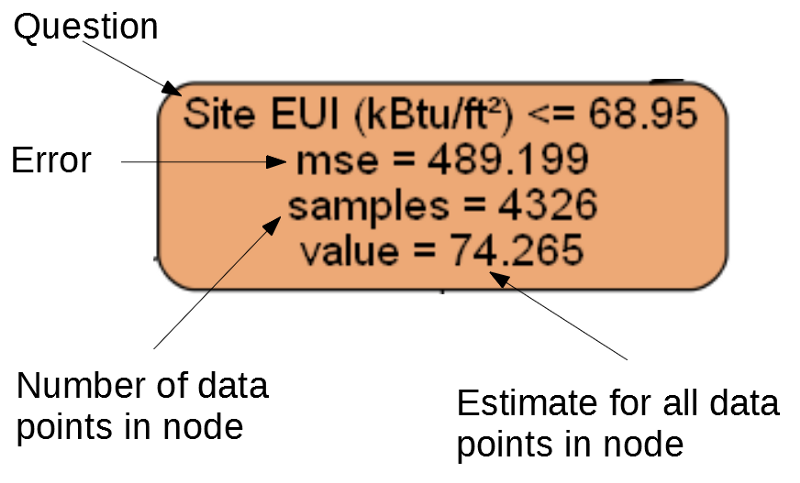 单独的节点。
单独的节点。(叶子仅包含2。–4。,因为它们代表最终得分,并且没有子节点)。
在决策树中对给定度量的预测从最高节点(即根)开始,然后在该树中下降。 在每个节点中,您需要回答“是”或“否”的问题。 例如,上一个插图询问:“站点EUI建筑物是否小于或等于68.95?” 如果是,则算法转到右侧的子节点,否则,算法转到左侧的子节点。
在树的每一层上重复此过程,直到算法到达最后一层上的叶节点为止(这些节点未在带有简化树的图中显示)。 工作表中任何维度的预测都是
value 。 如果有几项测量结果,则每个测量结果都会收到相同的预测。 随着树的深度增加,训练数据上的误差将减小,因为将有更多的叶子并且样本将被更仔细地划分。 但是,过深的树将导致
对训练数据进行
再训练,并且无法将测试数据进行概括。
在
第二篇文章中,我们设置了控制每棵树的模型超参数的数量,例如,树的最大深度和每张纸所需的最小样本数。 这两个参数极大地影响了学习过度与学习不足之间的平衡,决策树的可视化将使我们能够了解这些设置的工作原理。
尽管我们无法研究模型中的所有树木,但对其中一棵树木进行分析将有助于了解每个“学生”的预测。 这种基于流程图的方法与人如何做出决策非常相似。
决策树的集合结合了众多单个树的预测,这使您可以创建具有更少可变性的更准确的模型。 这样的合奏
非常准确并且易于解释。
本地可解释模型相关解释(LIME)
您可以尝试使用的最后一个工具来弄清楚我们的模型如何“思考”。 LIME允许您解释
如何为任何机器学习模型生成单个预测 。 为此,在本地进行一些测量之后,将在简单模型(例如线性回归)的基础上创建一个简化模型(详细信息在此工作中进行了描述:
https :
//arxiv.org/pdf/1602.04938.pdf )。
我们将使用LIME方法研究模型的完全错误的预测,并理解为什么会出错。
首先,我们发现这个错误的预测。 为此,我们将训练模型,生成预测并选择误差最大的值:
from sklearn.ensemble import GradientBoostingRegressor
预测:12.8615
实际值:100.0000然后,我们创建一个解释器,并为其提供训练数据,模式信息,训练数据标签和属性名称。 现在可以将观测数据和预测功能传达给解释器,然后要求他们解释预测误差的原因。
import lime
预测说明图:
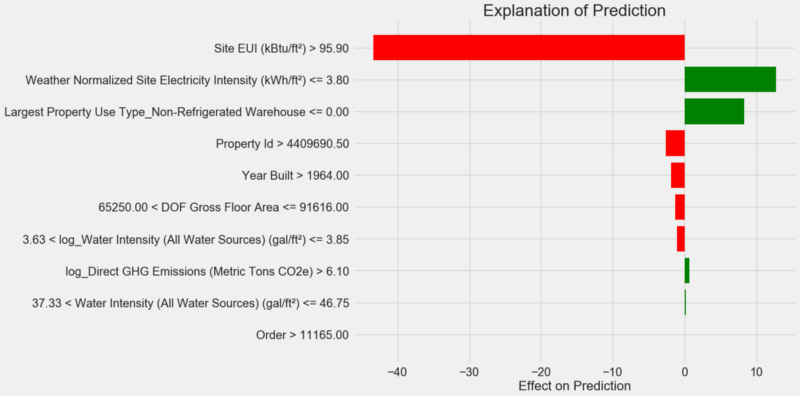
如何解释该图:沿Y轴的每条记录均指示变量的一个值,红色和绿色的条形图反映了该值对预测的影响。 例如,根据上层记录,
Site EUI的影响大于95.90,因此,从预测中减去了大约40点。 根据第二个记录,
Weather Normalized Site Electricity Intensity的影响小于3.80,因此将大约10点添加到了预测中。 最终预测是截距和每个列出的值的影响之和。
让我们
.show_in_notebook()一种方式来看一下,并调用
.show_in_notebook()方法:

模型的决策过程显示在左侧:直观显示每个变量对预测的影响。 右表显示了给定测量的变量的实际值。
在这种情况下,模型预测了大约12点,但实际上是100点。起初,您可能想知道为什么会发生这种情况,但是如果您对解释进行分析,结果发现这并不是一个非常大胆的假设,而是基于特定值的计算结果。
Site EUI相对较高,并且可以预期到能源之星得分较低(因为它受到EUI的强烈影响),我们的模型确实如此。 但是在这种情况下,这种逻辑被证明是错误的,因为实际上该建筑获得了最高的“能源之星”评分-100。
模型错误可能会使您感到不安,但是此类说明将帮助您理解模型错误的原因。 此外,多亏了这些解释,您可以开始探究尽管站点EUI很高的建筑物仍获得最高分数的原因。 如果我们不开始分析模型错误,也许我们会学到一些有关任务的新知识,而这会引起我们的注意。 这样的工具不是理想的,但是它们可以极大地促进对模型的理解并做出
更好的决策 。
工作记录和结果介绍
许多项目很少关注文档和报告。 您可以做世界上最好的分析,但是如果您不能
正确呈现结果 ,那就没关系了!
通过记录数据分析项目,我们打包了所有版本的数据和代码,以便其他人可以复制或收集该项目。 请记住,代码的阅读频率比书面的阅读频率高,因此,如果我们在几个月后恢复使用该代码,那么其他人和我们也应该清楚我们的工作。 因此,在代码中插入有用的注释并解释您的决定。
Jupyter Notebook是一个很好的文档记录工具;它们使您可以首先解释解决方案,然后显示代码。
同样,Jupyter Notebook是与其他专家进行交互的良好平台。 使用
笔记本的
扩展名,您可以
在最终报告中隐藏代码 ,因为无论多么难以置信,并非所有人都希望在文档中看到大量代码!
您可能不想挤压,但要显示所有详细信息。 但是,在介绍您的项目时
了解听众并相应地
准备报告很重要。 这是我们项目本质摘要的一个示例:
- 使用有关纽约建筑物能源消耗的数据,您可以构建一个模型,该模型可以预测9.1星的“能源之星”积分数量。
- 站点EUI和天气归一化电强度是影响预报的主要因素。
我们在Jupyter Notebook中编写了详细的描述和结论,但我们将.tex文件转换为
Latex ,而不是PDF,然后在
texStudio中
对其进行了编辑,并将
最终版本转换为PDF。 事实是,从Jupyter到PDF的默认导出结果看起来还不错,但是只需短短几分钟的编辑就可以大大改善。 此外,Latex是功能强大的文档准备系统,对自己有用。
归根结底,我们工作的价值取决于其做出的决定,因此能够“亲自交付商品”非常重要。 通过正确记录,我们可以帮助其他人重现我们的结果并提供反馈,这将使我们变得更有经验,并依赖将来获得的结果。
结论
在我们的一系列出版物中,我们从头到尾涵盖了机器学习教程。 我们首先清除数据,然后创建一个模型,最后我们学习了如何解释它。 回顾一下机器学习项目的总体结构:
- 清洁和格式化数据。
- 探索性数据分析。
- 设计和选择功能。
- 几种机器学习模型的指标比较。
- 最佳模型的超参数调整。
- 在测试数据集上评估最佳模型。
- 解释模型的结果。
- 结论和有据可查的报告。
步骤的设置可能会因项目而异,并且机器学习通常是迭代而不是线性的,因此本指南将在将来为您提供帮助。 我们希望您现在可以放心地实施您的项目,但是请记住:没有人一个人行动! 如果您需要帮助,可以在许多非常有用的社区中获得建议。
这些资源可以帮助您: