用于图像识别的深度神经网络的发展为机器学习研究的已知领域注入了新的活力。 这样的领域之一是领域适应。 这种调整的本质是对来自源域(源域)的数据训练模型,以使其在目标域(目标域)上显示可比的质量。 例如,源域可以是可以廉价生成的合成数据,目标域可以是用户照片。 然后,领域自适应的任务是在合成数据上训练模型,该模型将与“真实”对象一起很好地工作。
在机器视觉小组Vision.BIZ.Ru中,我们正在研究各种应用问题,其中经常有一些培训数据很少。 在这些情况下,合成数据的生成和对其进行训练的模型的改编可以极大地帮助您。 这种方法的一个很好的应用示例是检测和识别商店货架上的商品的任务。 获取此类架子的照片并对其进行标记非常费力,但可以非常简单地生成它们。 因此,我们决定更深入地研究领域适应性主题。

领域适应性研究会影响神经网络在一项新任务中获得的先前经验的使用。 网络是否能够从源域中提取某些功能并将其用于目标域? 尽管机器学习中的神经网络仅与人脑中的神经网络有很远的联系,但是,人工智能研究人员的圣杯却是向神经网络教授人拥有的可能性。 人们能够利用以前的经验和积累的知识来理解新概念。
此外,领域自适应可以帮助解决深度学习的基本问题之一:要以较高的识别质量训练大型网络,需要大量的数据,而在实践中并不总是这样。 一种解决方案可能是对可以以几乎无限量生成的合成数据使用域适应方法。
在应用问题中,经常会有这样一种情况,即只有一个域的数据可用于训练,而该模型必须应用于另一域。 例如,确定摄影的美学质量的网络可以在网络上从业余网站收集的数据库中进行训练。 并且计划在普通照片中使用该网络,其质量级别与专业照片站点的照片级别平均不同。 作为解决方案,我们可以考虑使模型适应普通的未标记照片。
这些理论和应用问题都在适应领域。 在本文中,我将基于深度学习讨论该领域的主要研究,以及用于比较不同方法的数据集。 深度域自适应的主要思想是在源域上训练一个深度神经网络,该神经网络会将图像转换成这样的嵌入(通常是网络的最后一层),以便在目标域上使用时可以获得高质量的图像。
核心基准
就像在机器学习的任何领域一样,随着时间的流逝,在领域适应方面积累了一定数量的研究,必须将它们相互比较。 为此,社区开发了数据集,在数据集的训练部分对模型进行了训练,并在测试部分将它们进行了比较。 尽管深度域适应的研究领域还相对较年轻,但已经有相当多的文章和这些文章中使用的数据库。 我将列出主要内容,重点是使合成数据的领域适应“真实”。
人物
显然,根据Yann LeCun (深度学习的先驱之一,Facebook AI Research的负责人)建立的传统,在计算机视觉中,最简单的数据集与手写数字或字母相关联。 有几个带有数字的数据集最初是为试验图像识别模型而出现的。 在有关域适应的文章中,可以在源-目标域对中找到它们的各种组合。 在这些数据集中:
从训练用于“真实”世界的综合数据的任务的角度来看,最有趣的是两对:
- 资料来源:MNIST,目标:SVHN;
- 资料来源:USPS,目标:MNIST;
- 来源:合成器编号,目标:SVHN。

大多数方法在“数字”数据集上都有基准。 但是在所有文章中都找不到其他类型的域。
办公室
该数据集包含31个类别的各个项目,每个类别都在3个域中表示:来自Amazon的图像,来自网络摄像头的照片和来自数码相机的照片。

这对于检查模型将如何响应向目标域添加背景和质量很有用。
交通标志
另一对用于在合成数据上训练模型并将其应用于“真实”数据的数据集:

这对数据库的一个特点是,来自Synth Signs的数据与“真实”数据非常相似,因此域非常接近。
从车窗
用于细分的数据集。 非常有趣的一对,最接近实际情况。 使用游戏引擎(GTA 5)获得源数据,而目标数据来自现实生活。 类似的方法用于训练自动驾驶汽车中使用的模型。
- SYNTHIA或GTA 5引擎-使用游戏引擎从车窗上看到的城市景观图片;
- 城市景观 -在50个不同城市中拍摄的汽车图片。

威士达
该数据集用于“ 视觉域适应挑战”中 ,该挑战是ECCV和ICCV研讨会的一部分。 源域包含使用CAD生成的12类标记对象,例如飞机,马匹,人等。 目标域包含来自ImageNet的相同12类的未标记图像。 在2018年举行的比赛中,添加了第13类:未知。
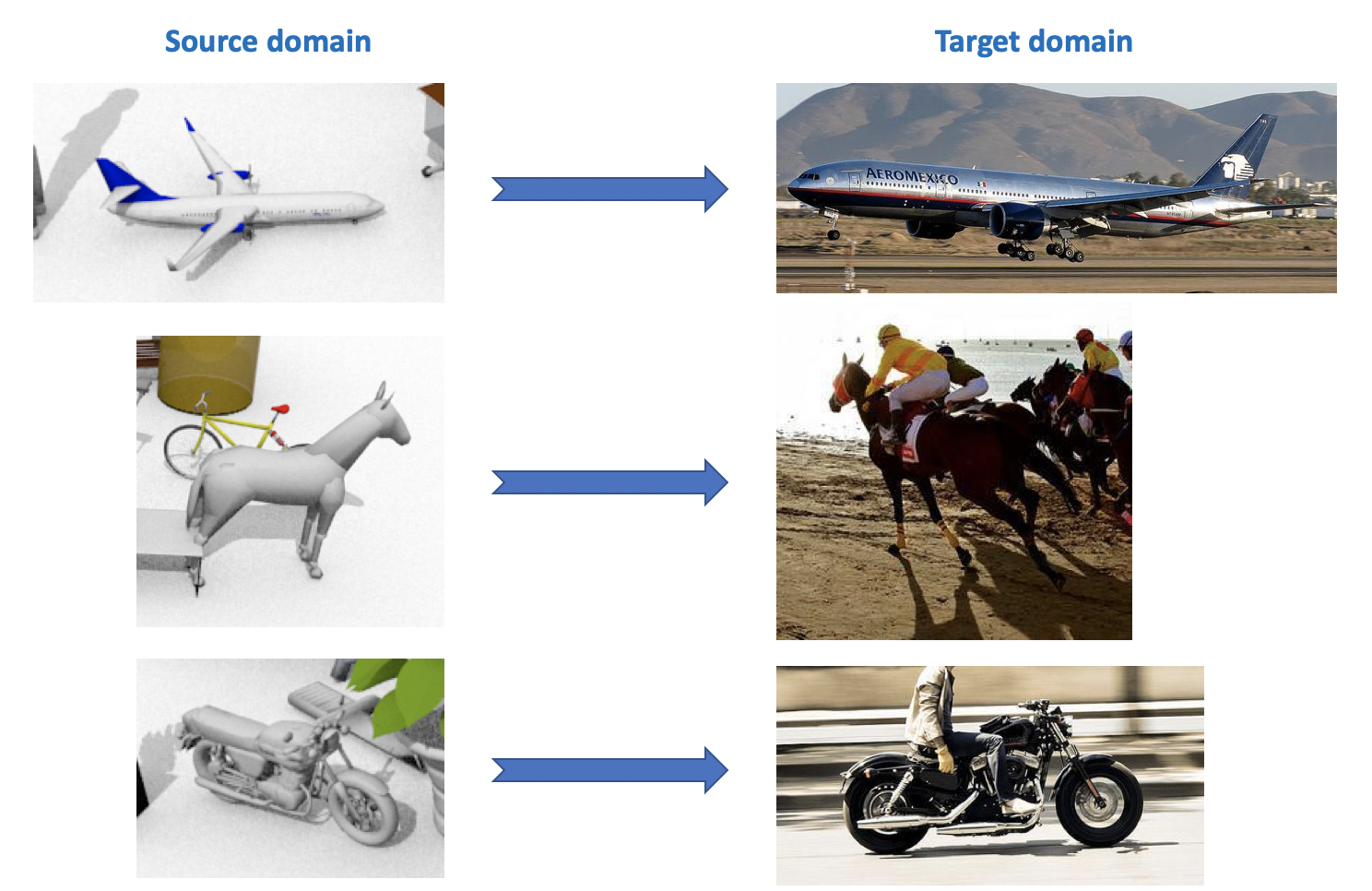
从以上所有内容可以看到,有很多有趣且多样化的领域适应数据集,您可以针对各种任务(分类,分割,检测)和各种条件(合成数据,照片,街道景观)为其训练和测试模型。
深度领域适应
域适应方法的分类相当广泛和多样(例如,请参见此处 )。 我将在本文中根据其主要功能对方法进行简化划分。 深度域适应的现代方法可以分为3大类:
- 基于差异的方法 :通过将这种距离引入损失函数中来最小化源域和目标域上矢量表示之间的距离的方法。
- 基于对抗的 :这些方法使用GAN中引入的对抗损失功能来训练域不变网络。 在最近的几年里,这个家庭的方法得到了积极的发展。
- 混合方法不使用对抗性损失,而是采用基于差异的家庭的思想以及深度学习的最新发展:自我组装,新层次,损失函数等。 这些方法在VisDA竞赛中显示出最佳结果。
我认为,从每个部分来看,都会考虑过去1-3年获得的一些基本结果。
基于差异
当出现使模型适应新数据的问题时,首先想到的是使用微调,即 在新数据上重新训练模型。 为此,请考虑域之间的差异。 这种类型的领域适应可以分为三种方法:类标准,统计标准和体系结构标准。
班级标准
当我们可以访问目标域中的标记数据时,主要使用该家族的方法。 分类标准的一种流行选择是深度转移度量学习方法。 顾名思义,它是基于度量学习的,其本质是训练从神经网络获得的矢量表示,以便根据给定的度量,一类代表在该表示中彼此接近(最常用 大号2 或余弦指标)。 在“ 深度传输度量学习(DTML)”一文中 ,由项之和组成的损失用于实现此方法:
- 一类代表彼此之间的接近度(类内紧凑度);
- 不同类别代表之间的距离增加(类间可分离性);
- 域之间的最大平均差异(MMD)指标。 此度量标准属于统计标准族(请参阅下文),但也用于分类标准中。
域之间的MMD表示为
MMD2(Ds,Dt)=\垂直 frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Vert2H,
在哪里 phi(x) -这是我们的核心-网络的矢量表示, xsi,i in1 ldotsM -来自源域的数据, xti,i in1 ldotsN -来自目标域的数据。 因此,在训练过程中最小化MMD指标时,会选择这样的网络 phi(x) 因此,它在两个域上的平均矢量表示都接近。 DTML的主要思想是:
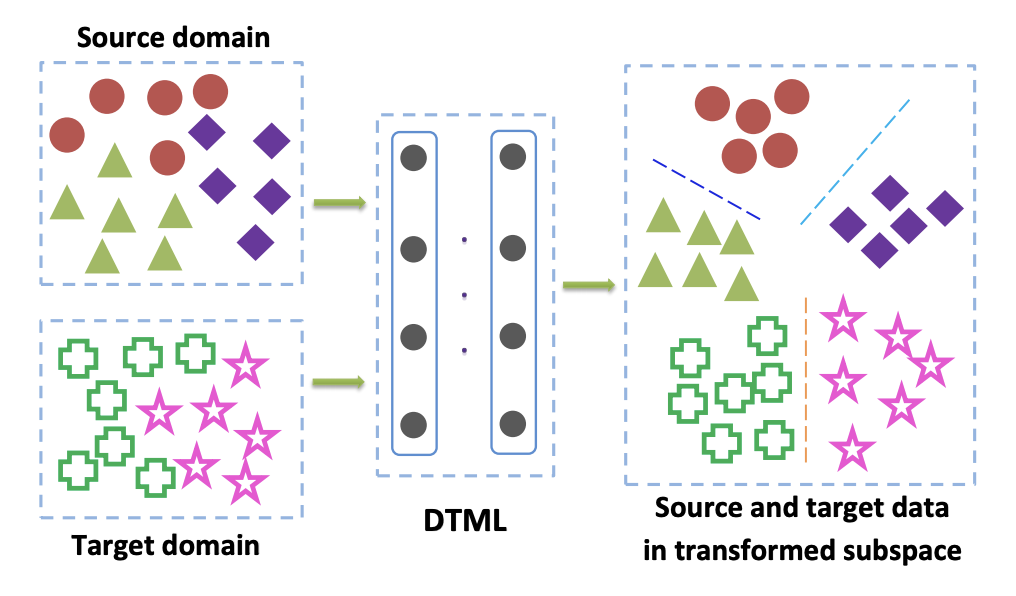
如果目标域中的数据是非监督域自适应,则请注意类别权重偏差:无监督域自适应的加权最大均值差异中描述的方法建议在源域上训练模型,并使用该模型获取伪标签(伪伪标签)。 即 来自目标域的数据通过网络运行,其结果称为伪标签。 然后将它们用作目标域的标记,这允许将MMD标准应用于损失函数(对负责不同域的组件具有不同的权重)。
统计标准
与此家族相关的方法用于解决无监督域自适应问题。 在许多任务中都发生了未分配目标域的情况,并且本文稍后将讨论的所有域自适应方法都可以解决此类问题。
基于统计标准的方法尝试测量从源域和目标域的数据获得的网络矢量表示的分布之间的差异。 然后,他们使用计算出的差异将这两个分布放在一起。
这些标准之一是上面已经描述的最大平均差异(MMD) 。 它的变体用于多种方法:
这三种方法的示意图如下所示。 在它们中,MMD变体用于确定应用于源域和目标域的卷积神经网络各层上的分布之间的差异。 请注意,它们每个人都将MMD修改用作卷积网络各层之间的损耗(图中的黄色数字)。

借助深层CORAL网络, CORAL准则(CORrelation ALignment)及其扩展旨在学习数据的表示形式,以使域之间的二阶统计量匹配到最大值。 为此,使用网络的矢量表示的协方差矩阵。 在某些情况下,两个域上的二阶统计量的收敛性使人们可以获得比MMD更好的适应结果。
LCORAL= frac14d2 VertCS−CT Vert2F,
在哪里 ||∗||2F 是Frobenius矩阵范数的平方,并且 Cs 和 Ct -分别来自源域和目标域的协方差矩阵数据, d -向量表示的尺寸。
在Office数据集上,对Amazon和Webcam域对使用Deep CORAL进行适应的平均质量为72.1%。 在Synth Signs-> GTSRB道路标志域上,结果也非常平均:目标域的准确性为86.9%。
MMD和CORAL概念的发展是中央矩差(CMD)准则 ,该准则比较了所有订单的源域和目标域中的数据的中心矩,直至 K 包容性( K -算法参数)。 在Office数据集上,成对的Amazon和Webcam域对的平均CMD适应质量为77.0%。
建筑标准
这种类型的算法基于以下假设:负责适应新域的基本信息已嵌入到神经网络的参数中。
在许多论文[1] , [2]中,当使用损耗函数对每对层训练源域和目标域的网络时,针对这些域的权重研究相对于域不变的信息。 下面给出了此类架构的示例。
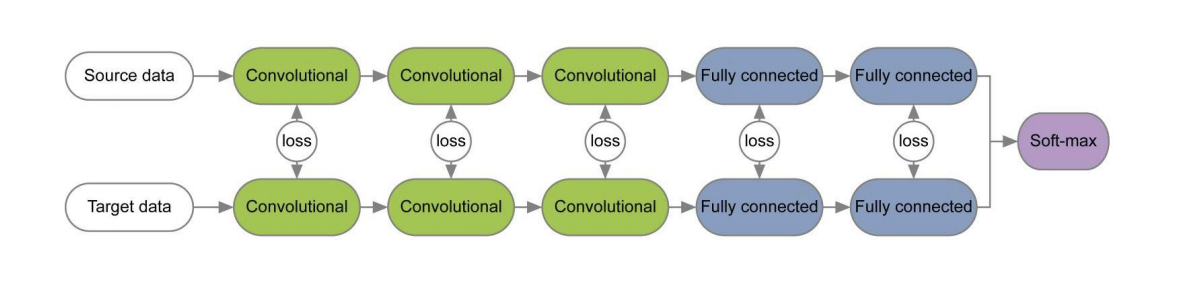
在文章“ 重新讨论用于实际域自适应的批处理规范”中,提出了这样的想法:网络规模包含与网络正在研究的类别有关的信息,并且域信息嵌入到批处理规范化(BN)层的统计信息(均值和标准差)中。 因此,为了适应,有必要重新计算来自目标域的数据的这些统计信息。 将此技术与CORAL结合使用可以将Office和Amazon Webcam域对的Office数据集的适应质量提高多达75.0%。 然后表明 ,使用实例规范化(IN)层代替BN可以进一步提高适配质量。 与BN按批次归一化输入张量不同,IN计算通道的归一化所需的统计量,因此与批次无关。
基于对抗的方法
在过去的1-2年中,深度域适应的大多数结果都与基于对抗的方法有关。 这主要归因于生成对抗网络(GAN)的快速发展和普及,因为基于对抗的域适应方法在训练中使用了与GAN相同的对抗目标功能。 通过对其进行优化,此类深域自适应方法可将源域和目标域上的矢量数据表示的经验分布之间的距离最小化。 通过以这种方式训练网络,他们尝试使其相对于域不变。
GAN包含两个模型:生成器 G ,在其输出中获得某个目标分布的数据; 和鉴别器 D ,它确定训练集中的数据还是使用 G 。 这两个模型是使用对抗目标函数训练的:
minG maxDV(D,G)= mathbbEx simpdata(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))]
通过这样的训练,生成器将学会“欺骗”鉴别器,这使您可以更接近目标域和源域的分布。
在基于对抗的域自适应中,有两种主要方法,它们是否使用生成器有所不同。 G 。
非生成模型
该族方法的关键特征是训练神经网络,其矢量表示相对于源域和目标域是不变的。 这样,在标记的源域上训练的网络就可以理想地在目标域上使用,而实际上不会损失分类质量。
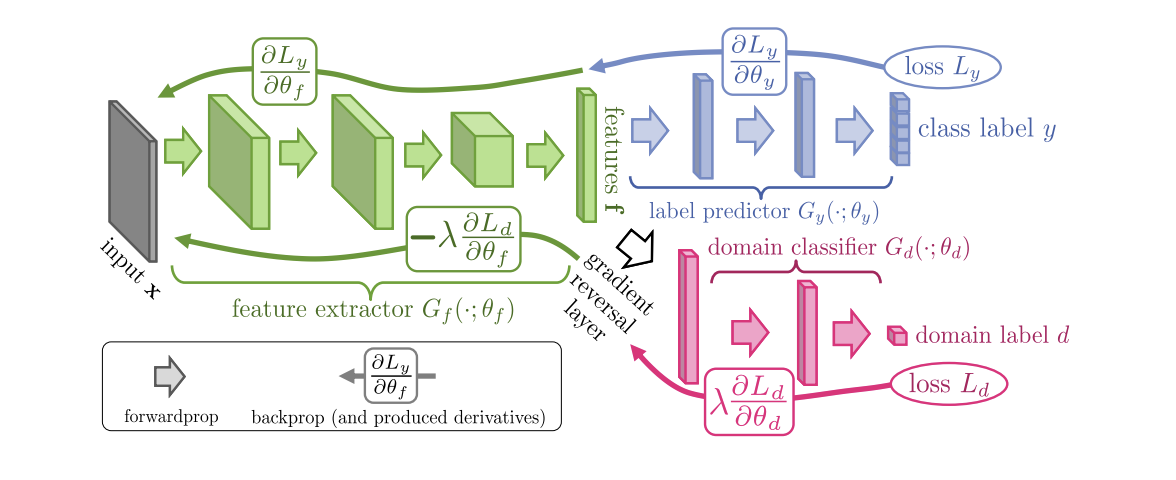
2015年推出的神经网络领域专家训练(DANN)算法 ( 代码 )包括3个部分:
- 在主网络的帮助下获得矢量表示(特征提取器)(下图中的绿色部分);
- “负责人”负责源域的分类(插图中的蓝色部分);
- 学会区分源域和目标域中数据的“头部”(图中红色部分)。
使用梯度下降(SGD)进行训练时(图中输入箭头),分类和域损失最小。 此外,在向负责域的“头部”的学习错误向后传播期间,使用了梯度反转层(图中的黑色部分),它将通过它的梯度乘以负常数,从而增加了域损耗。 这确保了在两个域上向量表示的分布变得紧密。
DANN基准测试结果:
- 在一对数字域上,合成器编号-> SVHN:91.09%。
- 在Synth Signs-> GTSRB道路标志上,它以88.7%的结果超过了CORAL。
- 在Office数据集上,Amazon和Webcam域对的平均适应质量为73.0%。
非生成模型家族的下一个重要代表是对抗性区分域自适应(ADDA)方法 ( 代码 ),该方法涉及将源域的网络与目标域的网络分离。 该算法包括以下步骤:
- 首先,我们在源域上训练分类网络。 我们表示它的向量表示 Ms 和 mathbfXs -源域。
- 现在,使用上一步中的训练后的网络来初始化目标域的神经网络。 让她 Mt 和 mathbfXt -目标域。
- 让我们继续进行对抗训练:我们将训练鉴别器 D 固定的 Ms 和 Mt 使用以下目标函数:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt)))]
- 冻结鉴别器并重新训练 Mt 在目标域上:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[\日志D(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
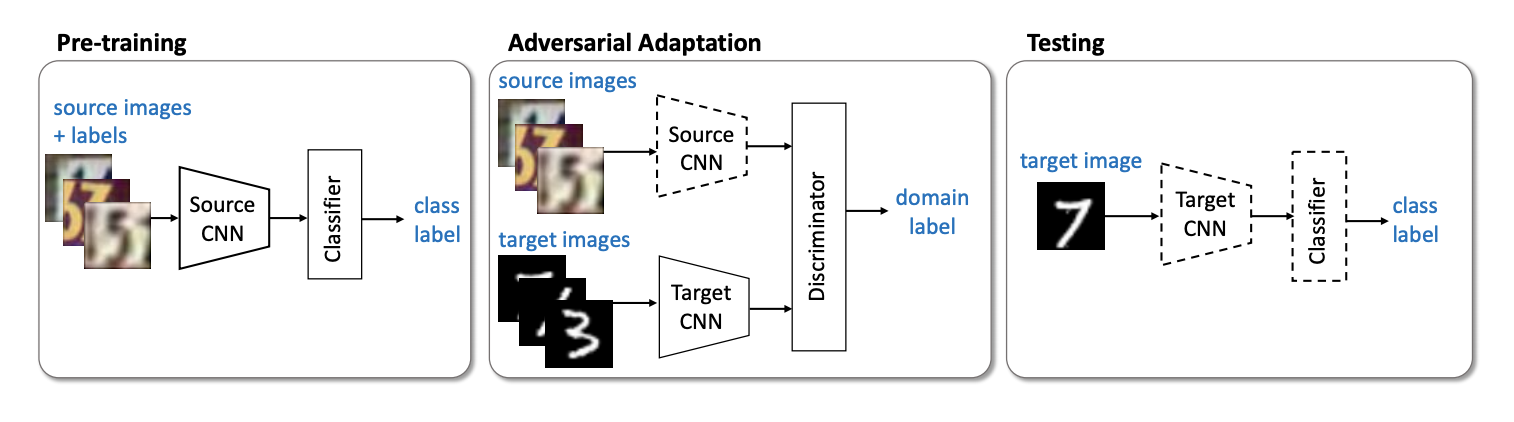
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K 。
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
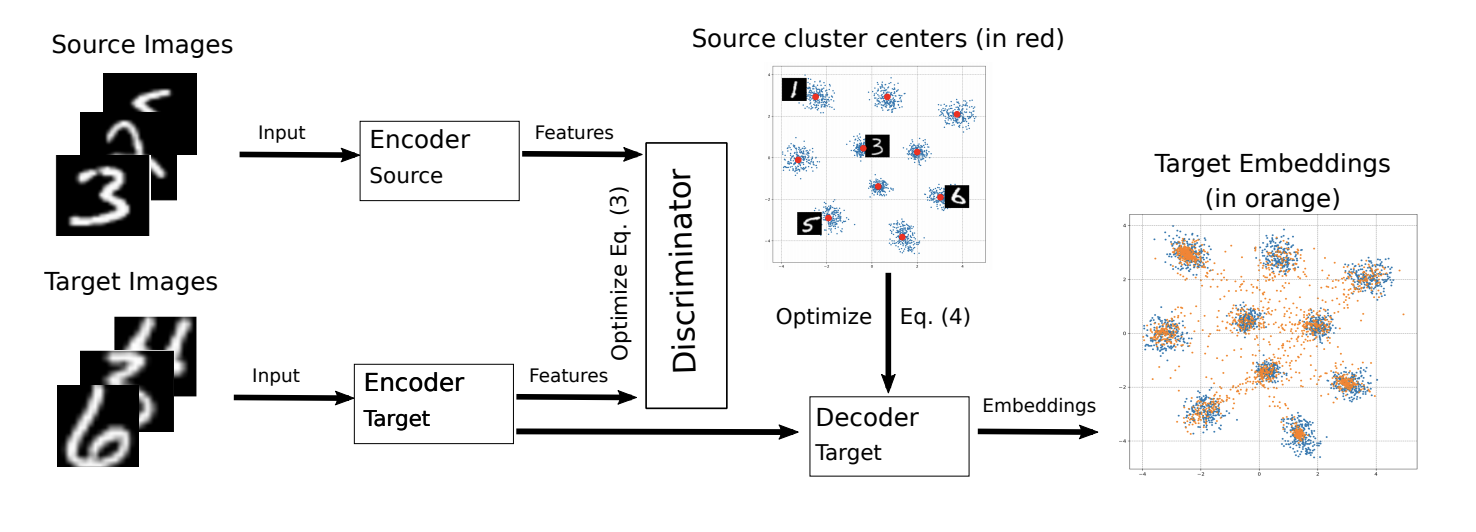
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 和 F2 — , . , G , F1 和 F2 -; , ; , ; F1 和 F2 。
, adversarial-, G , .
(Discrepancy Loss)
d(p1,p2)=1KK∑k=1|p1k−p2k|,
K — , p1kp2k — softmax k - F1 和 F2 .
3 :
- A. G , F1 和 F2 。
- B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
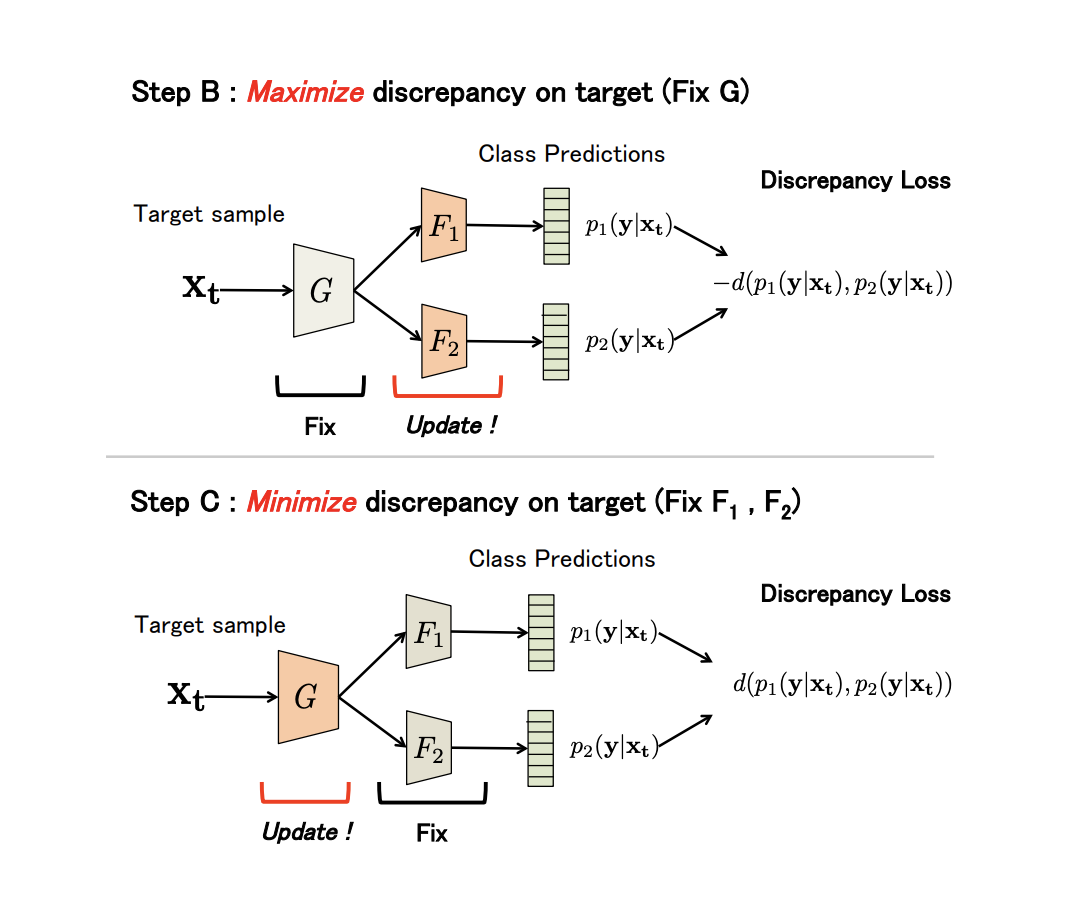
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
我们研究了域适应的主要数据集,基于差异的方法:类标准,统计标准和体系结构标准,以及第一个基于对抗性方法的非生成族。这些方法的模型在基准上显示出良好的性能,并且适用于许多适应任务。在下一部分中,我们将考虑最复杂和有效的方法:生成模型和基于非对抗性的混合方法。