9月,举行了第六届Hyperbaton-Yandex会议,讨论与技术文档相关的所有内容。 我们将发表Hyperbaton的一些演讲,我们认为这可能是Habr读者最感兴趣的。
文档和本地化部门主管Svetlana Kayushina:
-似乎世界上不再有手动翻译的人。 今天,我们要讨论可以帮助公司组织有效的本地化流程的工具和方法,而翻译人员可以更轻松地解决其日常问题。 今天,我们将讨论机器翻译,评估机器引擎的有效性以及用于翻译人员的自动翻译系统。
让我们从同事的报告开始。 我邀请Irina Rybnikova和Anastasia Ponomareva-他们将谈论Yandex在将机器翻译引入我们的本地化流程中的经验。
伊琳娜(Irina Rybnikova):
谢谢 我们将向您介绍机器翻译的历史以及我们如何在Yandex中使用它。

早在17世纪,科学家们就在考虑是否存在一种将其他语言连接起来的语言,这可能太长了。 让我们再靠近一点。 我们所有人都想了解我们周围的人-无论我们来自何方-我们都希望看到标志上写着什么,我们想阅读公告,音乐会信息。 巴比伦鱼的想法引起了科学家的注意,在文学,电影院中到处都有。 我们希望减少获取信息的时间。 我们想阅读有关中国技术的文章,了解我们所看到的任何站点,并希望在现在和现在得到它。

在这种情况下,不可能不谈论机器翻译。 这有助于解决此问题。

起点是1954年,当时在IBM 701机器上,在美国将60篇关于有机化学的一般主题的句子从俄语翻译成英语,所有这些都是基于250个词汇术语和六个语法规则。 这被称为乔治敦实验,令人震惊,以至于报纸充斥着头条新闻,又过了三到五年,问题将得到彻底解决,每个人都会高兴。 但是,正如您所知,一切都有些不同。
在20世纪70年代,出现了基于规则的机器翻译。 它也基于双语词典,但也基于有助于描述任何语言的那些规则集。 任何,但有限制。

要求制定规则的认真的语言专家。 这是一项相当复杂的工作,它仍然不能考虑上下文,完全覆盖任何语言,但是他们都是专家,因此不需要很高的计算能力。

如果我们谈论质量,那么经典的例子就是圣经中的一句话,然后像这样翻译。 还不够。 因此,人们继续致力于质量。 在90年代,出现了统计翻译模型SMT,它谈到了单词和句子的概率分布,并且该系统从根本上不同,因为它对规则和语言学一无所知。 她收到了大量相同的文本,以一种语言和另一种语言配对,然后自己做出决定。 它易于维护,不需要大量专家,无需等待。 您可以下载并获得结果。

传入数据的需求相当平均,从1到1000万个细分市场。 段-句子,小短语。 但是他们仍然遇到困难,没有考虑到具体情况;一切都不是一件容易的事。 以俄罗斯为例。

我也喜欢翻译GTA游戏的例子,结果很棒。 一切都没有停滞不前。 2016年是神经机器翻译开始的重要里程碑。 这是一个相当划时代的事件,极大地改变了生活。 我的同事看了翻译以及我们如何使用它们后说:“很酷,他用我的话说。” 这真的很棒。
有什么特点? 入学要求高,培训教材。 在公司内部很难维护,但是质量的显着提高正是其初衷。 只有高质量的翻译才能解决任务,并使过程中的所有参与者都变得更轻松,那些不想纠正错误翻译的翻译者,他们想要执行新的创造性任务,并为机器提供例行短语。
机器翻译有两种方法。 对文本进行专家评估/语言分析,即由真正的语言学家,专家验证其是否符合语言的含义,素养。 在某些情况下,专家仍然被种植,他们被允许减去翻译后的文本,并从这一角度评估其有效性。

这种方法有什么特点? 不需要样本翻译,我们现在查看完成的翻译文本,然后对任何部分进行客观评估。 但是它很昂贵而且很长。

还有第二种方法-自动参考指标。 它们有很多,每个都有其优点和缺点。 我不会更深入地介绍,您以后可以阅读有关这些关键字的更多信息。
有什么功能? 实际上,这是翻译后的机器文本与某些示例性翻译的比较。 这些是定量指标,显示了示例性翻译和发生的事情之间的差异。 它快速,便宜并且可以很方便地完成。 但是有功能。

实际上,大多数情况下,他们使用混合方法。 在这种情况下,最初会自动评估某些内容,然后分析错误矩阵,然后在较小的文本正文中进行专家语言分析。

最近,当我们不在这里打电话给语言学家而只是在打电话给用户时,这种做法仍然很普遍。 正在建立一个界面-显示您最喜欢的翻译。 或者,当您访问在线翻译时,您可以输入文字,并且无论这种方法是否合适,您都可以经常对自己最喜欢的内容进行投票。 实际上,我们所有人现在都在训练这些引擎,并且它们将所有训练内容用于训练和提高其质量。
我想告诉我们我们如何在工作中使用机器翻译。 我把这个词传给了阿纳斯塔西娅。
Anastasia Ponomareva:
-本地化部门Yandex很快就意识到了机器翻译技术的巨大潜力,并决定尝试在日常工作中使用它。 我们从哪里开始? 我们决定进行一个小实验。 我们决定通过常规的神经网络翻译器翻译相同的文本,并组装经过培训的机器翻译器。 为此,在Yandex从事这些语言的文本本地化工作的这些年中,我们已经准备了一对俄语-英语文本语料库。 然后,我们将这段语料库带给Yandex的同事,翻译并要求训练引擎。

在对引擎进行培训后,我们翻译了下一批文本,正如Irina所说,在专家的帮助下,我们评估了结果。 我们要求翻译人员研究读写能力,风格,拼写和含义的传递。 但是转折点是一位翻译说“我认识我的风格,我认识我的翻译”。
为了增强这些感觉,我们决定计算统计指标。 首先,我们计算了通过常规神经网络引擎进行的转移的BLEU系数,得出了这个数字(0.34)。 似乎需要将其与某些事物进行比较。 我们再次去找Yandex.Translator的同事,要求解释什么BLEU系数被认为是真实人进行交易的门槛。 这是0.6。
然后,我们决定检查经过培训的翻译的结果是什么。 得到了0.5。 结果确实令人鼓舞。

我举一个例子。 这是Direct文档中真正的俄语短语。 然后,它通过常规的神经网络引擎进行传输,然后通过本文中经过训练的神经网络引擎进行传输。 在第一行中,我们已经注意到传统的Direct广告类型尚未得到认可。 在经过训练的神经网络引擎中,我们的翻译已经出现,甚至缩写几乎是正确的。
我们对结果感到非常鼓舞,并决定值得在其他对,其他文本中使用该引擎,而不仅是在基本的技术文档集上。 进行了数月的一系列实验。 面对许多功能和问题,这些是我们必须解决的最常见问题。

我会告诉您更多有关这两者的信息。

如果像我们一样,您打算制造定制引擎,则将需要大量的高质量并行数据。 大型发动机可以接受1万个报价的培训,在我们的案例中,我们已经准备了13.5万个并行报价。

并非在所有类型的文本上,您的引擎都会显示同样好的结果。 在技术文档中,如果句子,结构,用户文档较长,甚至在界面中也存在简短但清晰的按钮,则很可能会很好。 但是也许像我们一样,您会遇到营销问题。
我们进行了一个实验,翻译了音乐播放列表,并得到了一个例子。

这就是机器翻译对明星工厂工人的看法。 劳动鼓手是什么?

通过机器引擎进行翻译时,不会考虑上下文。 从Yandex.Direct的技术文档中,这不再是一个荒谬的例子,而是真实的。 当您阅读技术文档时,这些似乎是可以理解的,这些是技术性的。 但是不,引擎没有命中。

您还必须考虑翻译的质量和含义在很大程度上取决于原始语言。 我们将短语从俄语翻译成法语,得到一个结果。 我们得到了具有相同含义的相似短语,但是从英语中得到的结果却有所不同。

如果您像我们在本文中一样具有大量的标签,标记和一些技术功能,则很可能您将不得不跟踪它们,编辑和编写一些脚本。
以下是来自浏览器的真实短语示例。 括号中是不应翻译的技术信息,尤其是多种形式。 在英语中,它们是英语,而在德语中,它们也必须保持英语,但必须进行翻译。 您将必须跟踪这些要点。
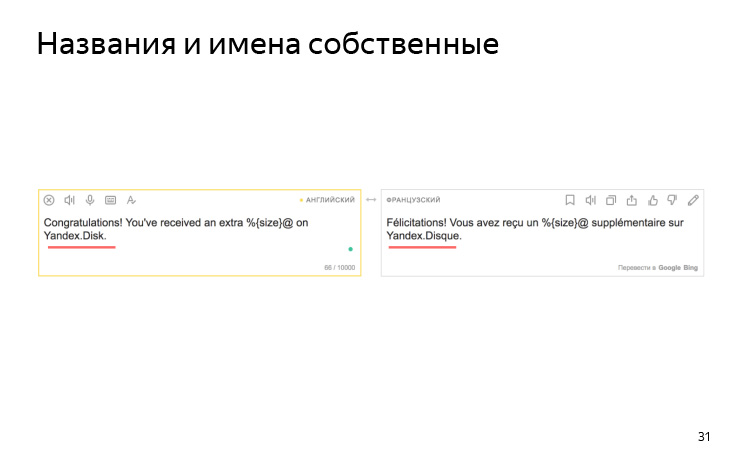
引擎对您的命名约定一无所知。 例如,我们有一个协议,我们始终以所有语言用拉丁语称Yandex.Disk。 但是用法语,他变成了法语的光盘。

缩写有时可以正确识别,有时不能正确识别。 在此示例中,BY表示白俄罗斯的广告技术要求,成为英语的借口。

我最喜欢的例子之一是新词和借来的词。 这是一个很酷的例子,免责声明一词是“最初是俄语”。 必须对文本的每个部分进行术语验证。
还有一个,不是那么重要的问题-过时的写作。

以前,互联网是一个新事物,它在所有文本中都被大写,并且当我们训练引擎时,互联网到处都是大写。 现在是一个新时代,互联网已经用小写字母书写。 如果您希望引擎继续用小写字母编写Internet,则必须对其进行重新培训。

我们没有绝望,解决了这些问题。 首先,他们改变了文本的军团,试图翻译其他主题。 我们将评论发送给Yandex.Translator的同事,重新训练了神经网络并查看了结果,进行了评估并要求完成。 例如,标签识别,HTML标记处理。
我将展示实际用例。 我们为技术文档提供了很好的机器翻译。 这是真实情况。

这是英文和俄文的短语。 适当地选择术语,对处理本文档的译者感到非常鼓舞。 另一个例子。

译者赞赏选择而不是破折号,该短语的结构已更改为英语,对正确的术语进行了适当的选择,而单词you则不是原文,但使该翻译完全是英语,很自然。

另一种情况是即时转换接口。 其中一项服务决定在启动时不打扰本地化和翻译文本。 但是,在大约每月更换一次引擎之后,“交付”一词发生了变化。 我们建议团队不要连接普通的神经网络引擎,而应该使用经过技术文档培训的我们的神经网络引擎,以便始终使用相同的术语,并与文档中已有的团队达成一致。

所有这些如何在金钱上发挥作用? 最初是这样的,一对俄语-乌克兰语只需要对乌克兰语翻译进行最小程度的编辑。 因此,几个月前,我们决定切换到后期编辑系统。 这就是我们的储蓄增长的方式。 9月尚未结束,但我们认为我们已将乌克兰语的后期编辑成本降低了约三分之一,并且除行销文本外,我们将编辑几乎所有内容。 这个词伊琳娜总结。
伊琳娜:
-对于每个人来说,很明显有必要使用它,这已经是我们的现实,不可能将其排除在我们的流程和利益之外。 但是您需要考虑一些事情。

确定文档的类型,使用的上下文。 这项技术适合您吗?
第二刻 我们谈论Yandex.Translator的原因是因为我们之间的关系很好,我们可以直接与开发人员联系,等等,但是实际上您需要确定哪种引擎最适合您,针对您的语言和您的主题。
下一份报告将专门讨论该主题。 准备好仍然存在困难,引擎的开发人员正在共同解决这些困难,但是到目前为止,他们仍然在开会。

我想了解未来的情况。 但是实际上,这还不是进一步,而是我们当前的时间,现在和现在的情况。 我们都宁愿根据我们的术语,我们的文本进行定制,而这正是现在公开的内容。 现在,每个人都在努力确保您不会进入公司,不同意特定引擎的开发人员,以及如何为您优化这一点。 您将可以在API上的公共开放引擎中收到它。
自定义不仅在文本中,而且在术语中也是如此,以根据您自己的需要配置术语。 这是重要的一点。 第二个主题是交互式翻译。 当翻译人员翻译文本时,该技术使他可以考虑源语言即源文本来预测以下单词。 这种螺旋钻可以极大地方便工作。
那现在真的很贵。 每个人都认为如何用更少的文字来教一些引擎的效率大大降低。 这就是无处不在,无处不在的事情。 我认为该主题非常有趣,然后它将变得更加有趣。
我们收集了一些您可能感兴趣的文章。 谢谢你
-
两种模式比一种更好。 Yandex.Translator的经验-Yandex如何应用人工智能技术翻译网页-
机器翻译。 从冷战到二战