注意事项 佩雷夫 :原始文章由Google的技术作家撰写,致力于Kubernetes的文档(Andrew Chen)和SAP的软件工程总监(Dominik Tornow)。 它的目标是清楚,清楚地解释在Kubernetes中组织和实现高可用性的基础。 在我们看来作者成功了,因此我们很高兴分享翻译。
Kubernetes是一个容器编排引擎,旨在在通常称为集群的多个节点上运行容器化的应用程序。 在这些出版物中,我们使用系统建模方法来提高对Kubernetes及其基本概念的理解。 鼓励读者已经对Kubernetes有了基本的了解。
Kubernetes是一个可扩展且可靠的容器编排引擎。 在此,可伸缩性由负载存在时的响应能力确定,而可靠性由存在故障时的响应能力确定。
请注意,Kubernetes的可伸缩性和可靠性并不意味着在其中运行的应用程序的可伸缩性和可靠性。 Kubernetes是一个可扩展且可靠的平台,但是每个K8s应用程序都必须经过某些步骤才能成为一体并避免瓶颈和单点故障。
例如,如果将应用程序部署为副本集或部署,则Kubernetes(重新)计划和(重新)启动受节点崩溃影响的Pod。 但是,如果将应用程序部署为Pod,则在节点故障的情况下Kubernetes将不会采取任何措施。 因此,尽管Kubernetes本身仍可运行,但是您的应用程序的响应能力取决于所选的体系结构和部署决策。
该出版物侧重于Kubernetes的可靠性。 她谈到Kubernetes在出现故障时如何保持响应能力。
Kubernetes体系结构
 方案1.主人和工人
方案1.主人和工人从概念上讲,Kubernetes组件分为两个不同的类:
主组件和辅助组件。
主人负责管理除炉床执行以外的所有事务。 该向导的组件包括:
工人负责管理炉床的执行。 它们具有一个组成部分:
工作程序是非常可靠的:集群中任何工作程序的临时或永久故障都不会影响主数据库或其他集群工作程序。 如果正确部署了该应用程序,Kubernetes会(重新)计划并(重新)启动受工作人员故障影响的任何人。
单向导配置
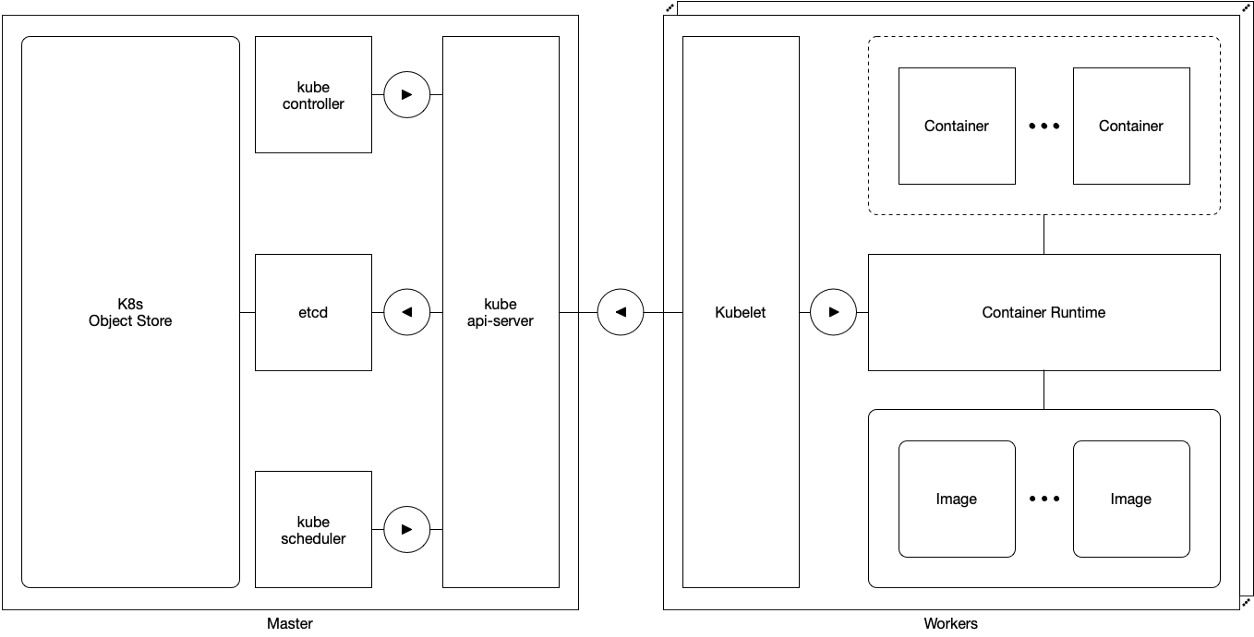 方案2.使用一个主服务器进行配置
方案2.使用一个主服务器进行配置在单主机配置中,Kubernetes集群由一个主机和许多工作程序组成。 后者直接连接到kube-apiserver向导并与其交互。
在这种配置下,Kubernetes的响应能力取决于:
因为唯一的主服务器是单点故障,所以此配置不属于高可用性类别。
多向导配置
 方案3.具有许多主设备的配置
方案3.具有许多主设备的配置在多主机配置中,Kubernetes集群由许多主机和许多工作人员组成。 工作人员可以连接到任何主服务器的kube-apiserver,并通过高度可访问的负载平衡器与其进行交互。
在此配置中,Kubernetes独立于:
由于此配置中没有单点故障,因此认为它是高度可访问的。
Kubernetes的领导者和追随者
在多向导配置中,涉及众多的kube控制器管理器和kube调度程序。 如果两个组件修改相同的对象,则会发生冲突。
为了避免潜在的冲突,对于kube-controller-manager和kube-scheduler,Kubernetes实施了“
主从 ”
(领导者/跟随者)模式。 每个小组选择一个领导者
(或多个领导者) ,其余的成员则充当跟随者的角色。 在任何给定时间,只有一个领导者是主动的,而跟随者是被动的。
 图4.详细的冗余部署组件向导
图4.详细的冗余部署组件向导此图显示了一个详细示例,其中kube-controller-1和kube-scheduler-2在kube-controller-manager和kube-scheduler中处于领先地位。 由于每个小组都选择自己的领导者,因此他们根本不必是同一位大师。
潜在客户选择
小组成员在启动时或领导者跌倒时会选择新的领导者。 Lead-具有所谓的
领导者租约 (当前为“租用”领导者身份)的成员。
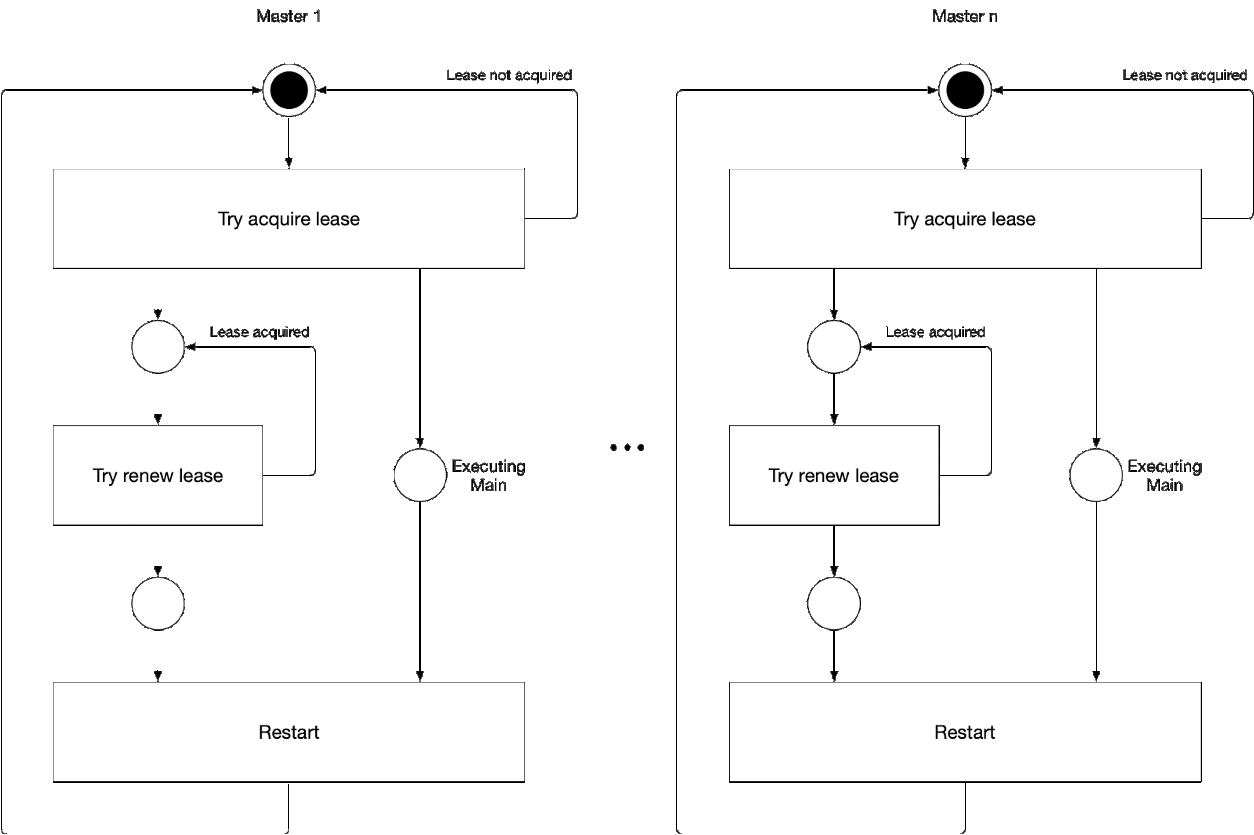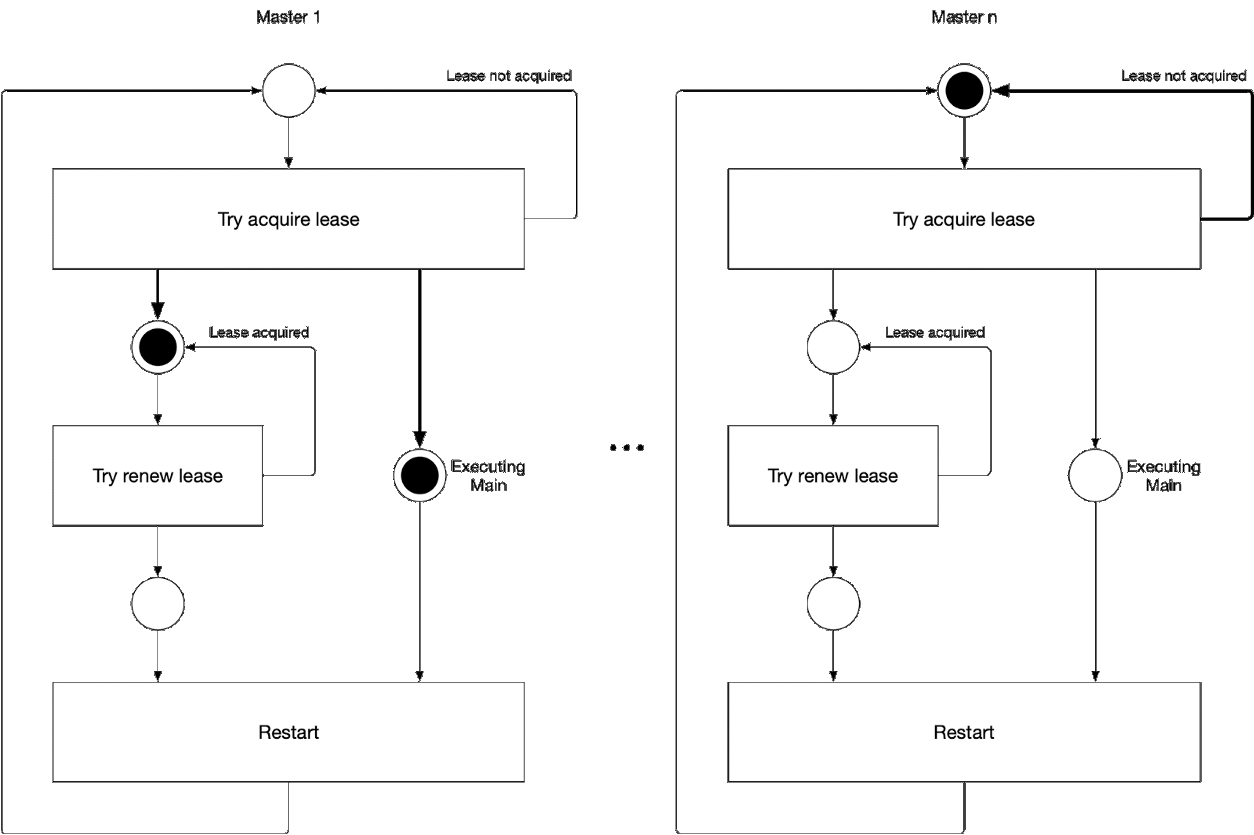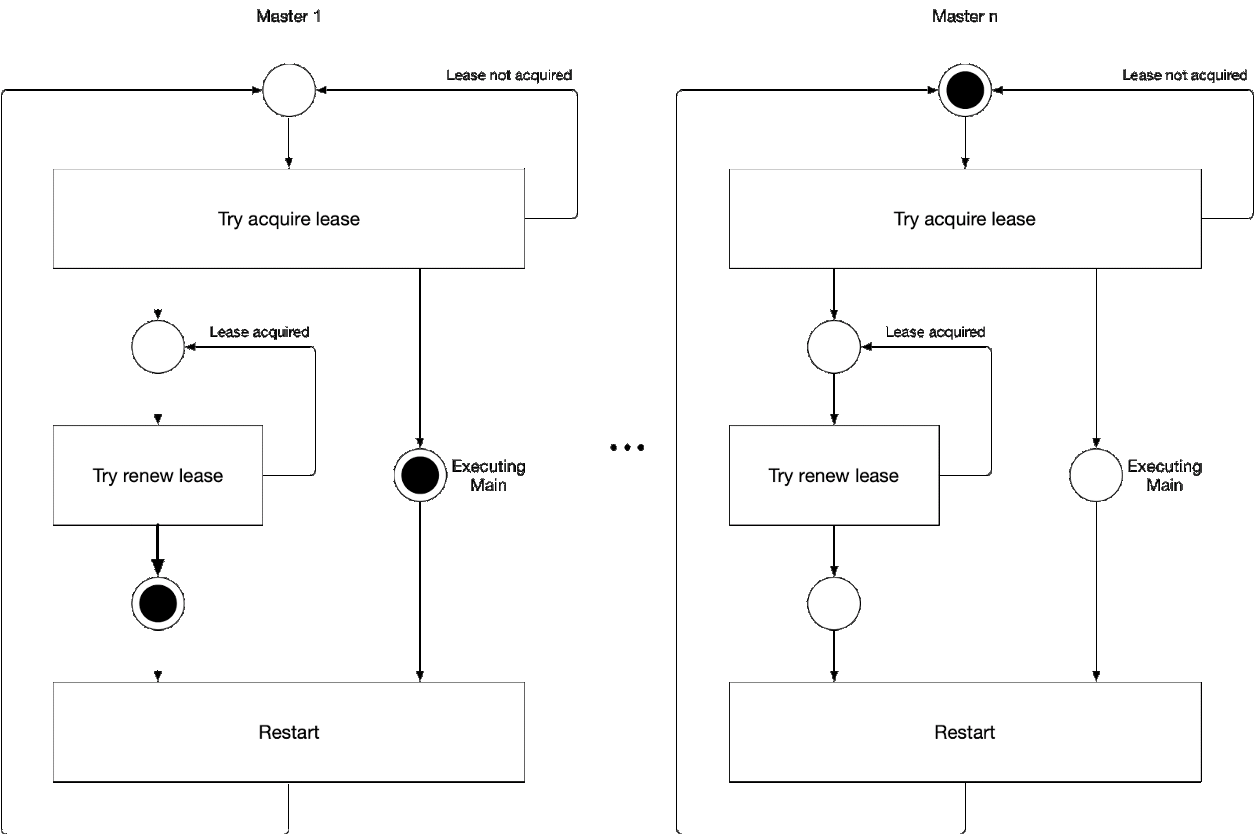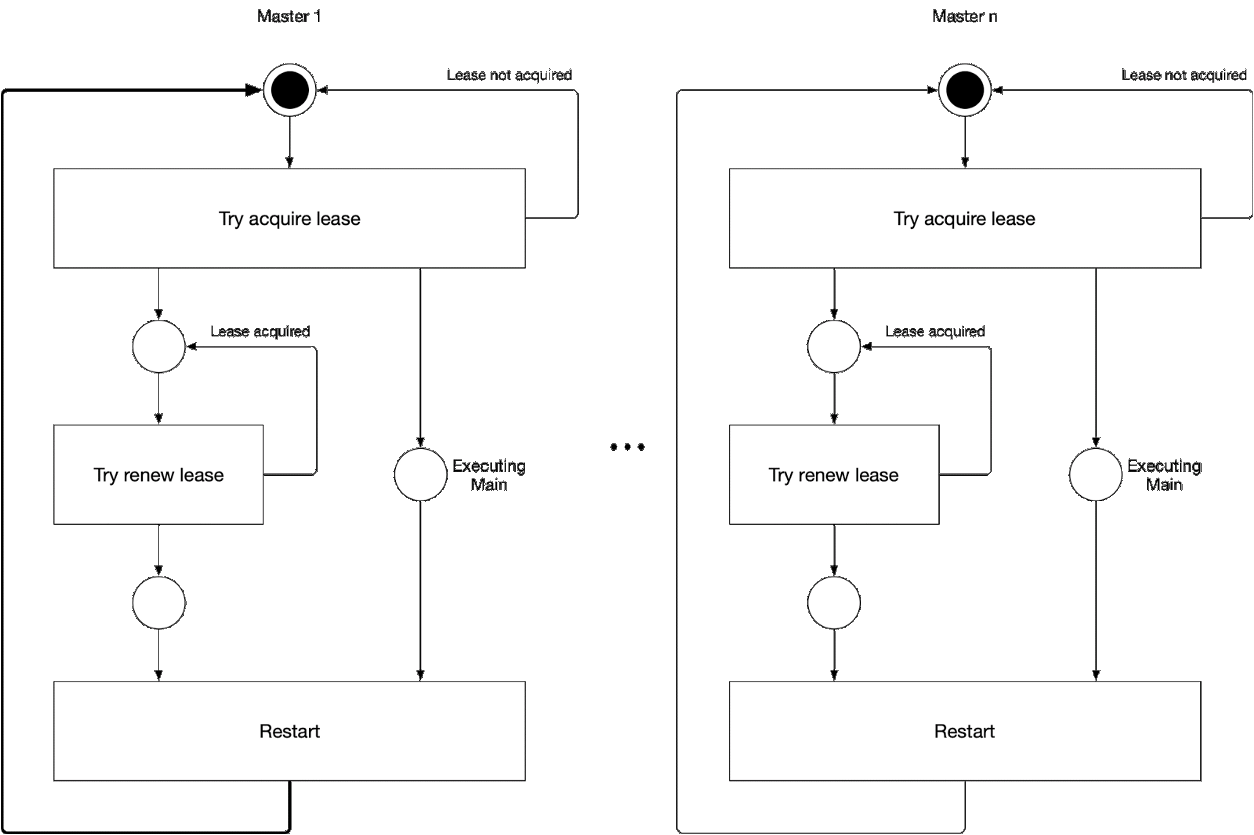 图5. 选择向导的主组件的过程
图5. 选择向导的主组件的过程此图演示了kube-controller-manager和kube-scheduler的主选择过程。 此过程的逻辑如下:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'领先追踪
kube-controller-manager和kube-scheduler的当前领导者状态永久存储在Kubernetes对象存储中,作为
kube-system命名空间中的
终结点对象 。 由于两个Kubernetes对象不能同时具有相同的名称,类型
(种类)和名称空间,因此kube-scheduler和kube-controller-manager只能有一个
端点 。
使用
kubectl控制台实用程序进行演示:
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
端点的kube-scheduler和kube-controller-manager将领导者信息存储在注释
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
尽管Kubernetes保证一次只能有一位大师,但Kubernetes并不能保证向导的两个或更多组件不会
错误地假设他们现在是领导者-这种状态被称为
大脑裂 。
关于分裂脑的话题和可能的解决方案的指导性讨论可以在Martin Kleppmann的“
如何做分布式锁定”文章中找到。
Kubernetes不使用任何裂脑对策。 取而代之的是,他依靠自己在一段时间内争取理想状态的能力,从而减轻了冲突决策的后果。
结论
在多主机配置中,Kubernetes是可伸缩且可靠的容器编排引擎。 在这种配置中,Kubernetes使用各种向导和许多工作程序来提供可靠性。 许多主服务器都按照主/从模式工作,而工人则并行工作。 Kubernetes有其自己的主机选择过程,其中主机信息存储为
端点对象 。
有关如何准备Kubernetes高可用性集群以进行操作的信息,请参阅
官方文档 。
关于出版
这篇文章是CNCF,Google和SAP联合倡议的一部分,旨在增进对Kubernetes及其底层概念的理解。译者的PS
另请参阅我们的博客: