哈Ha! 我叫Nikolai Izhikov,我在开源解决方案开发团队的Sberbank Technologies工作。 用Java进行15年商业开发的背后。 我是Apache Ignite提交者和Apache Kafka的贡献者。
在猫的下面,您将找到有关Apache Ignite Meetup的报告的视频和文本版本,内容涉及如何将Apache Ignite与Apache Spark结合使用以及我们为此实现了哪些功能。
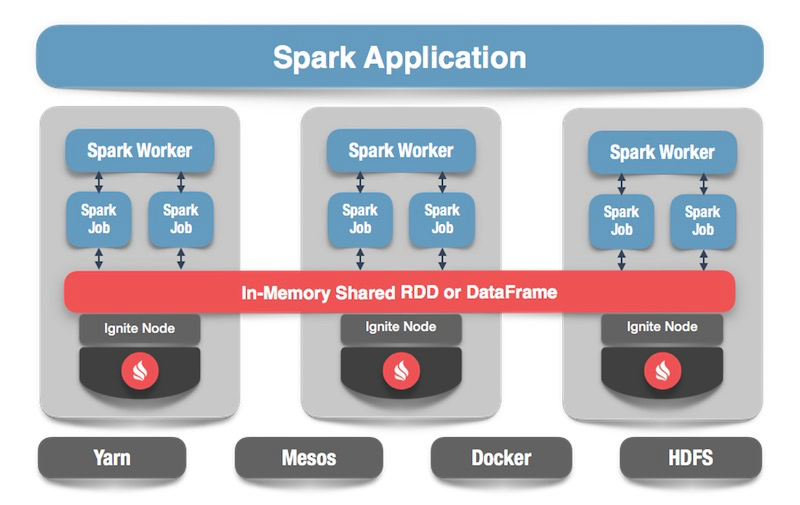
Apache Spark可以做什么
什么是Apache Spark? 此产品使您可以快速执行分布式计算和分析查询。 基本上,Apache Spark是用Scala编写的。
Apache Spark具有丰富的API,可用于连接到各种存储系统或接收数据。 该产品的功能之一是通用的类似SQL的查询引擎,用于从各种来源接收数据。 如果您有多种信息来源,则希望将它们组合起来并获得一些结果,那么Apache Spark是您所需要的。
Spark提供的关键抽象之一是Data Frame,DataSet。 就关系数据库而言,这是一个表,它是一种以结构化方式提供数据的源。 每列的结构,类型,名称等是已知的。 可以从各种来源创建数据框。 示例包括json文件,关系数据库,各种hadoop系统和Apache Ignite。
Spark支持SQL查询中的联接。 您可以合并来自各种来源的数据并获得结果,执行分析查询。 此外,还有一个用于保存数据的API。 完成查询并进行研究后,Spark可以将结果保存到支持此功能的接收器中,从而解决数据处理问题。
我们实现了将Apache Spark与Apache Ignite集成的哪些功能
- 从Apache Ignite SQL表读取数据。
- 将数据写入Apache Ignite SQL表。
- IgniteSparkSession中的IgniteCatalog-使用所有现有的Ignite SQL表而无需“手动”注册的能力。
- SQL优化-在Ignite中执行SQL语句的能力。
Apache Spark可以从Apache Ignite SQL表读取数据,并以这种表的形式写入数据。 Spark中形成的任何DataFrame都可以另存为Apache Ignite SQL表。
Apache Ignite允许您在Spark Session中使用所有现有的Ignite SQL表,而无需“手工”注册-使用标准SparkSession扩展-IgniteSparkSession中的IgniteCatalog。
在这里,您需要更深入地了解Spark设备。 就常规数据库而言,目录是元信息存储的地方:哪些表可用,表中有哪些列,等等。 当请求到达时,从目录中提取元信息,并且SQL引擎对表和数据进行处理。 默认情况下,在Spark中,所有读取表(无关紧要,来自关系数据库Ignite和Hadoop)都必须在会话中手动注册。 结果,您就有机会在这些表上进行SQL查询。 Spark发现了有关它们的信息。
要使用我们上传到Ignite的数据,我们需要注册表。 但是,我们无需手动注册每个表,而是实现了自动访问所有Ignite表的功能。
这里有什么功能? 由于某些原因,我不知道,Spark中的目录是一个内部API,即 局外人无法来创建自己的目录实现。 而且,由于Spark来自Hadoop,因此仅支持Hive。 并且您必须用手注册其他所有内容。 用户经常问您如何解决此问题并立即进行SQL查询。 我实现了一个目录,该目录使您无需注册〜和sms〜即可浏览和访问Ignite表,并最初在Spark社区中提出了此补丁,我收到了答复:由于某些内部原因,这种补丁并不有趣。 而且他们没有给出内部API。
现在,Ignite目录是使用Spark内部API实现的有趣功能。 要使用此目录,我们有自己的会话实现,这是通常的SparkSession,您可以在其中执行请求,处理数据。 区别在于我们将ExternalCatalog集成到其中以用于Ignite表以及IgniteOptimization,这将在下面进行描述。
SQL优化 -在Ignite中执行SQL语句的能力。 默认情况下,在执行联接,分组,聚合计算和其他复杂的SQL查询时,Spark会逐行读取数据。 数据源唯一能做的就是有效地过滤掉行。
如果使用联接或分组,Spark将使用指定的过滤器将表中的所有数据拉入其内存中的工作器中,然后将它们分组或执行其他SQL操作。 在Ignite的情况下,这不是最佳选择,因为Ignite本身具有分布式体系结构,并且了解其中存储的数据。 因此,Ignite本身可以有效地计算聚合并进行分组。 此外,可能会有很多数据,要对它们进行分组,您将需要减去所有数据,并在Spark中提升所有数据,这是非常昂贵的。
Spark提供了一个API,您可以使用该API更改SQL查询的初始计划,执行优化并将可在此处执行的SQL查询部分转发到Ignite。 就速度和内存消耗而言,这将是有效的,因为我们不会使用它来提取将立即分组的数据。
如何运作
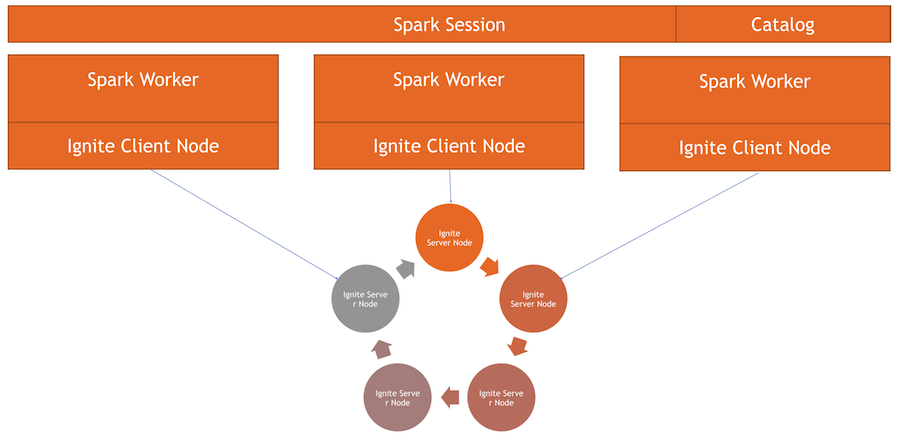
我们有一个Ignite群集-这是图片的下半部分。 没有Zookeeper,因为只有五个节点。 有火花工作程序,每个工作程序内部都会引发Ignite客户端节点。 通过它,我们可以发出请求并读取数据,并与集群进行交互。 此外,客户端节点将在IgniteSparkSession内部上升,以使目录正常工作。
点燃数据框
我们来看代码:如何从SQL表读取数据? 就Spark而言,一切都非常简单和良好:我们说我们要计算一些数据,并指定格式-这是一个一定的常数。 此外,我们有几个选项-客户端节点配置文件的路径,该路径在读取数据时开始。 我们指出我们要读取的表,并告诉Spark加载。 我们获得了数据,我们可以用它做我们想做的事情。
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
生成数据后-可以选择从Ignite或从任何来源生成数据-通过指定格式和相应的表,我们可以轻松地保存所有内容。 我们命令Spark编写,我们指定一种格式。 在配置中,我们规定了要连接到哪个集群。 指定我们要保存的表。 此外,我们可以规定实用程序选项-指定在此表上创建的主键。 如果数据只是在不创建表的情况下发生故障,则不需要此参数。 最后,单击保存,数据被写入。
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
现在,让我们看看它是如何工作的。
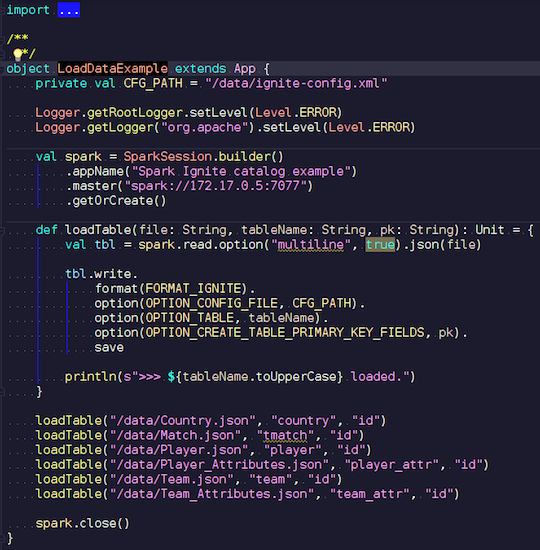 LoadDataExample.scala
LoadDataExample.scala这个显而易见的应用程序将首先演示记录功能。 例如,我选择了足球比赛的数据,并从知名资源下载了统计数据。 它包含有关比赛的信息:联赛,比赛,球员,球队,球员属性,球队属性-描述欧洲国家(英格兰,法国,西班牙等)联赛中足球比赛的数据。
我想将它们上传到Ignite。 我们创建一个Spark会话,指定向导的地址,并通过传递参数来调用这些表的加载。 该示例使用Scala,而不是Java,因为Scala不太冗长,因此更好。
我们传输文件名,将其读取,表明它是多行的,这是一个标准的json文件。 然后我们用Ignite编写。 文件的结构无处可描述-Spark本身确定了我们拥有的数据以及它们的结构。 如果一切顺利,则会创建一个表,其中包含所需数据类型的所有必要字段。 这就是我们可以在Ignite中加载所有内容的方式。
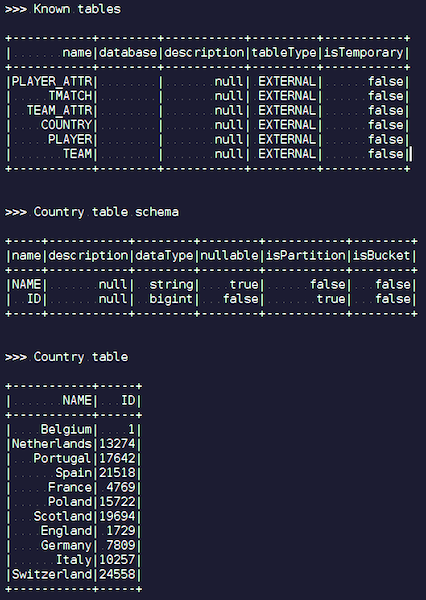
加载数据后,我们可以在Ignite中查看并立即使用它。 举一个简单的例子,一个查询让您知道哪个队比赛次数最多。 我们有两列:hometeam和awayteam,主机和来宾。 我们选择,分组,计数,求和并结合命令上的数据-输入命令的名称。 Ta-dam-以及我们从Ignite中获得的json-chiks中的数据。 我们看到了图卢兹的巴黎圣日耳曼-我们有很多关于法国队的数据。
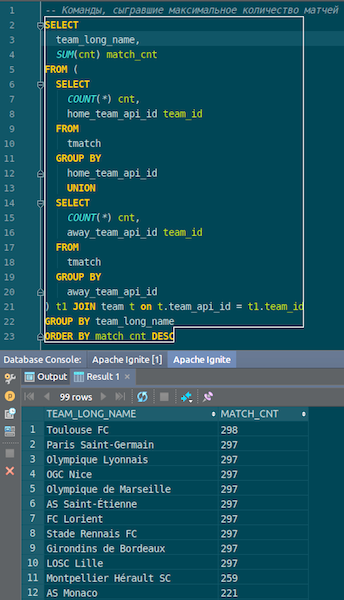
我们总结一下。 现在,我们已经将数据从源json文件上载到Ignite,而且速度很快。 从大数据的角度来看,这也许不是太大,但对于本地计算机而言却不错。 表模式以其原始形式从json文件中获取。 表已创建,列名称已从源文件复制,主键已创建。 ID无处不在,主键是ID。 这些数据进入Ignite,我们可以使用它。
IgniteSparkSession和IgniteCatalog
让我们看看它是如何工作的。
 CatalogExample.scala
CatalogExample.scala您可以用一种非常简单的方式访问和查询所有数据。 在上一个示例中,我们开始了标准的spark会话。 而且那里没有Ignite的特殊性-除了必须放置带有正确数据源的jar-通过公共API完全标准地工作。 但是,如果您想自动访问Ignite表,则可以使用我们的扩展名。 不同之处在于,我们编写了IgniteSparkSession而不是SparkSession。
一旦创建IgniteSparkSession对象,您就会在目录中看到所有刚刚加载到Ignite中的表。 您可以看到他们的图表和所有信息。 Spark已经了解Ignite拥有的表,您可以轻松获取所有数据。
点火优化
当您使用JOIN在Ignite中进行复杂查询时,Spark首先提取数据,然后才对它们进行分组。 为了优化流程,我们提供了IgniteOptimization功能-它优化了Spark查询计划,并允许您转发可在Ignite内部的Ignite内部执行的请求部分。 我们会根据特定要求显示优化。
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
我们满足要求。 我们有一个人表-一些员工,人。 每个员工都知道他所居住城市的ID。 我们想知道每个城市有多少人。 我们过滤-一个人居住的城市。 这是Spark构建的初始计划:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
关系只是一个点燃表。 没有过滤器-我们只是通过群集中的网络从Person表中抽取所有数据。 然后,Spark根据请求聚合所有这些内容,并返回请求的结果。
显而易见,所有带有过滤器和聚合的子树都可以在Ignite中执行。 这比从Spark中潜在的大表中提取所有数据要有效得多-这就是我们的IgniteOptimization功能所做的。 在分析和优化树之后,我们得到以下计划:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
结果,由于我们优化了整个树,因此我们只有一种关系。 在内部,您已经可以看到Ignite将发送与原始请求足够接近的请求。
假设我们要连接不同的数据源:例如,我们有一个来自Ignite的DataFrame,第二个来自json,第三个又来自Ignite,第四个是某种关系数据库。 在这种情况下,将仅在计划中优化子树。 我们优化我们可以做的事情,将其放入Ignite中,Spark会完成其余工作。 因此,我们可以提高速度。
JOIN的另一个示例:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
我们有两个表。 我们按值排列在一起,然后从中选择所有值-ID,值。 Spark提供了这样的计划:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
我们看到他将从一个表中提取所有数据,从第二个表中提取所有数据,将它们加入自己的内部并给出结果。 经过处理和优化后,我们得到了与Ignite完全相同的请求,该请求在此相对较快地执行。
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
我会给你看一个例子。
 OptimizationExample.scala
OptimizationExample.scala我们正在创建一个IgniteSpark会话,其中所有的优化功能已经自动包含在内。 这里的要求是这样的:找到评分最高的球员并显示他们的名字。 在播放器表中,其属性和数据。 我们正在加入,过滤垃圾数据并显示评分最高的玩家。 让我们看看优化后得到了什么样的计划,并显示了此查询的结果。
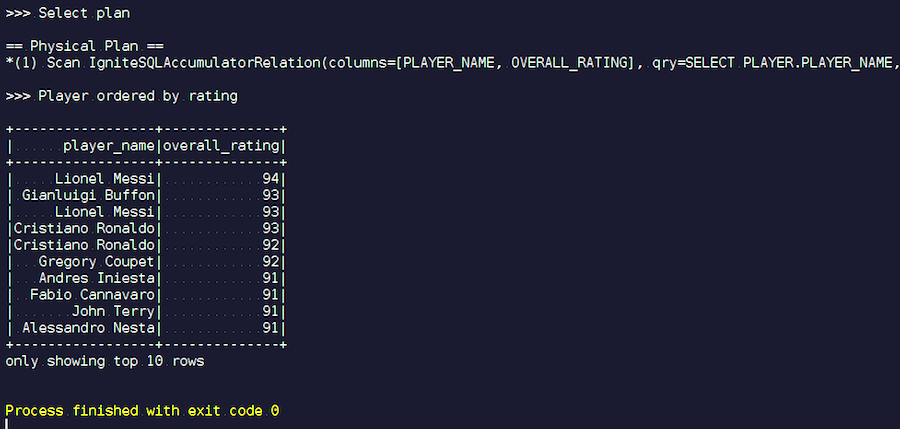
我们开始。 我们看到了熟悉的姓氏:梅西,布冯,罗纳尔多等。 顺便说一句,有些人出于某种原因以两种身份相遇-梅西和罗纳尔多。 足球爱好者可能会发现陌生的球员出现在名单上很奇怪。 这些是守门员,是具有很高特征的球员-在其他球员的背景下。 现在我们来看一下已执行的查询计划。 在Spark中,几乎什么也没做,也就是说,我们再次将整个请求发送给了Ignite。
Apache Ignite开发
我们的项目是一个开源产品,因此我们总是对开发人员的补丁和反馈感到满意。 非常欢迎您的帮助,反馈和补丁。 我们在等他们。 Ignite社区中90%的人说俄语。 例如,对我而言,直到我开始从事Apache Ignite的开发工作之前,对英语的最佳了解并不是一种威慑力。 在开发者列表上用俄语写作几乎是不值得的,但是即使您写错了内容,他们也会为您提供帮助。
这种集成可以改进什么? 如果您有这样的愿望,我该如何帮助? 在下面列出。 星号表示复杂性。

要测试优化,您需要使用复杂的查询编写测试。 上面,我显示了一些明显的问题。 很明显,如果您编写了很多分组和很多联接,那么某些事情可能会失败。 这是一个非常简单的任务-快来做。 如果我们根据测试结果发现任何错误,则需要对其进行修复。 那里会更难。
另一个清晰有趣的任务是将Spark与瘦客户端集成。 它最初可以指定一些IP地址集,并且足以加入Ignite群集,这在与外部系统集成的情况下非常方便。 如果您突然想加入解决此问题的方法,我将亲自提供帮助。
如果您想加入Apache Ignite社区,这里有一些有用的链接:
我们有一个响应式开发人员列表,将为您提供帮助。 距离理想还很遥远,但是与其他项目相比,它确实很活跃。
如果您知道Java或C ++,那么您正在寻找工作并且想要开发开源代码(Apache Ignite,Apache Kafka,Tarantool等),请在此处编写:join-open-source@sberbank.ru。