我曾经在这里写过有关从亚洲搬到欧洲的信息 ,现在我想写我在这个欧洲正在做的事情。 有这样的专业DevOps ,或者说不是,但是恰好这就是我现在正在做的事情。 现在,对于在docker中运行的所有内容进行编排,我们使用了rancher ,我也写过 。 但是随后发生了一件可怕的事情,Rancher 2.0出现并转移到了kubernetes(以下简称为k8s),并且由于k8s现在实际上已经成为管理集群的标准,因此人们希望再次与二十一点和图书馆员一起构建整个基础架构。 令人不安的是,该公司不断聘请来自不同国家和不同传统的不同专家,有人ansible带来ansible ,有人比ansible ,有人通常认为Makefile + bash是我们的一切。 因此,对于一切应该如何工作根本没有明确的意见,但我确实希望这样做。
这样的技术和工具动物园过去曾被组装:

基础设施管理
- 迷你库
- ke
- 地貌
- 科普斯
- Kubespray
- Ansible
应用管理
- Kubernetes
- 牧场主
- Kubectl
- 头盔
- 康德
- Kompose
- 詹金斯
记录与监控
- 弹性搜索
- 基巴纳
- 流利的位
- Telegraf
- Influxdb
- 扎比克斯
- 普罗米修斯
- 格拉法纳
- 卡帕托
接下来,我将尝试简要描述这个动物园的每个点,描述为什么有必要,以及为什么选择这种解决方案。 实际上,几乎所有项目都可以用十几种类似物替代,我们仍然不确定完全可以选择,因此,如果有人有任何意见或建议,我会很乐意在评论中阅读。
Kubernetes将成为一切的中心,因为现在它确实是一个根本没有替代方案的解决方案,从Amazon和Microsoft到mail.ru的所有提供商都支持。 如何考虑替代品
Swarm -从未起飞Nomad -似乎是陌生人为掠食者写的Cattle是Ranger 1.x的引擎,从原理上讲,我们现在生活在该引擎上,一切都很好,但牧场主已经放弃了它,转而使用k8,因此不会进行开发。
基础建设
首先,我们需要创建基础架构,并在其上部署k8s集群。 有几种选择,它们都起作用,因此很难选择最好的。
Minikube是用于出于测试目的在开发人员的计算机上启动集群的绝佳选择。
Rke -Rancher kubernetes引擎,就像一扇门一样简单;只需最少的配置即可创建集群外观
nodes: - address: localhost role: [controlplane,worker,etcd]
仅此而已,这足以在本地计算机上启动集群,同时它使您可以创建可用于生产环境的HA集群,更改配置,升级集群,转储etcd数据库等等。
Kops-不仅允许您创建集群,而且还可以在AWS或GCE中预先创建实例。 它还允许您生成Terraform的配置。 一个有趣的工具,但我们尚未扎根。 它被terraform + rke完全取代,同时更简单,更灵活。
Kubespray-实际上,它只是一个荒诞的角色,它创建了一个k8s集群,功能强大,灵活,可配置。 实际上,这是部署k8的默认解决方案。
Terraform是用于在AWS,Azure或其他许多地方构建基础结构的工具。 灵活,稳定-我建议。
Ansible并不是真的与k8s有关,但我们在任何地方也都使用它:调整配置,安装/更新软件,分发证书。 便宜又开朗。
应用管理
因此,我们有了一个集群,现在我们需要启动一个有用的集群,剩下的就是如何做到这一点的问题。
选项一:使用裸k8全部使用kubectl部署。 原则上,该选择权具有生命权。 Kubectl是一个功能强大的工具,它使我们能够执行所需的一切,包括部署,升级,监视当前状态,即时更改配置,查看日志以及连接到特定容器。 但是有时候我希望一切都变得更加方便,所以我们继续前进。
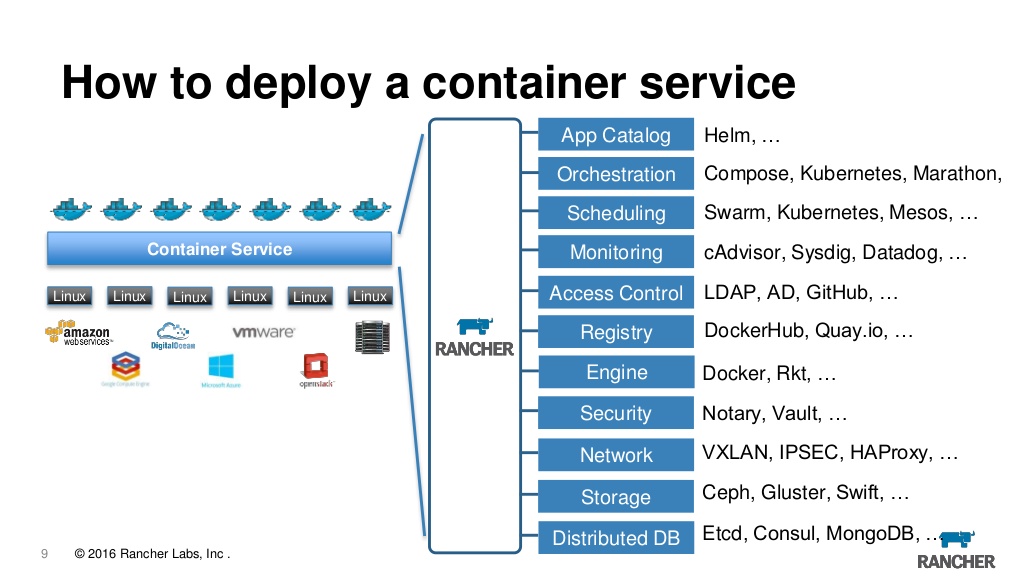
实际上,现在的牧场主是用于管理k8的网络枪口,与此同时,许多小面包也增加了便利性。 在这里,您可以查看日志,访问控制台以及配置和升级应用程序以及基于角色的访问控制和内置元数据服务器,警报,日志重定向,机密管理等。 我们已经使用第一个版本的牧场主已有几年了,并且对此感到完全满意,尽管我们必须承认,切换到k8s时会出现一个问题,我们是否真的需要它。 可以将以前创建的任何群集导入到牧场主中,也可以从任何提供程序中导入,这很好,即可以从azure从EKS导入群集并在本地创建并将其从一处驱动到一台服务器。 此外,如果您突然感到无聊,则可以简单地拆卸服务器,然后继续通过kubeclt或任何其他工具继续使用集群。
现在,将一切都作为代码的非常正确的概念广为流行。 例如,使用terraform实现作为代码的基础架构,通过jenkins pipeline实现作为代码的jenkins pipeline 。 现在轮到该应用程序了。 应用程序的安装和配置也应在某些清单中进行描述,并保存在git中。 Rancher版本1.x使用了标准docker-compose.yml ,一切都很好,但是当他们移至k8s时,他们切换到了helm charts 。 从我的角度来看, Helm与奇怪的逻辑和体系结构是绝对可怕的共享。 这是那些项目的其中一个,它仍然让人感觉它是由掠食者为陌生人写的,反之亦然。 唯一的问题是,在k8s掌舵世界中,别无选择,这实际上是标准。 因此,我们会被刺痛哭泣,但会继续使用头盔。 在3.x版中,开发人员承诺从头开始重写它,排除所有麻烦并简化体系结构。 到那时我们将he愈,但现在我们将吃些什么。
我们在这里至少还需要提及jenkins ,它与kubernetis主题没有直接关系,但是借助它的帮助,可以将应用程序部署到集群。 他是,他在工作,他是另一篇文章的主题。
监控方式
现在我们有了一个集群,它甚至在旋转某种应用程序,似乎您可以呼气,但实际上,一切都刚刚开始。 我们的应用程序有多稳定? 多快 他有足够的资源吗? 集群中通常会发生什么?
是的,下一个主题是监视和日志记录。 只有三个明确的答案。 将日志存储在kibana ,通过kibana观看它们,在kibana绘制图形。 对于所有其他问题,有许多正确答案。
在这里,我们从grafana本身开始,它实际上什么也没做,但是它可以像美丽的面孔一样固定在以下所述的任何系统上,并获得精美甚至有时清晰的图表,此外,您可以立即设置警报,但是最好为此使用其他解决方案,例如prometheus alertmanager和ElastAlert 。
从我的角度来看,目前这是最好的日志聚合器和路由器,此外,它开箱即用,具有k8s支持。 也有Fluentd但是它用卢布编写,并且拉了太多的遗留代码,这使其吸引力大大降低。 因此,如果需要尚未从fluentd移植到fluent-bit的特定模块,请在其余所有模块中使用它-bit是最佳选择。 它更快,更稳定,消耗更少的内存。 允许您从所有或选定的容器中收集日志,过滤它们,通过添加特定于kubernetis的数据来丰富它们,并将其全部发送到elasticsearch或许多其他存储库。 如果将其与传统的logstash + docker-bit + file-bit该解决方案在所有方面都绝对更好。 从历史上看,我们仍然使用logspout + logstash但一定会流利。
专为微服务架构编写的监视系统。 此外,业界事实上的标准还存在一个专为k8s编写的名为Prometheus Operator的项目。 每个人都可以决定选择什么,但是最好是从简单的普罗米修斯入手,只是为了理解他的工作逻辑,它与通常的系统有很大的不同。 我们还需要提到node-exporter和prometheus-rancher-exporter,后者可让您收集计算机级别的指标,而prometheus-rancher-exporter则允许您通过rancher api收集指标。 通常,如果您在kubernetes上有一个集群,那么必须使用prometheus。
一个可以在这里停下来,但是从历史上看,我们有几个监视系统。 首先,对于zabbix ,在一个面板上查看整个基础架构的所有问题非常方便。 自动发现的存在使您可以快速查找并添加新的网络,节点,服务,以及几乎所有要监视的内容,这使其成为监视动态基础结构的便捷工具。 另外,在4.0版中,来自prometheus出口商的一组度量标准被添加到zabbix中,事实证明,所有这些都可以非常精美地集成到一个系统中。 尽管仍然不确定是否需要将zabbix拖入k8s集群,但是尝试确实很有趣。
作为替代方案,您可以使用TIG (telegraf + influxdb + grafana)配置简单,运行稳定,允许您按容器,应用程序,节点等汇总指标,但实际上是重复了普罗米修斯功能,只剩下一个。
因此,事实证明,在开始任何有用的操作之前,您需要通过数十个辅助服务和工具来安装和配置绑定。 同时,本文没有提出管理持久性数据,秘密和其他奇怪事物的问题,这些问题,问题和秘密都可以拉到单独的出版物中。
您如何看待理想的基础架构?
如果您有任何意见,请在评论中写,或者甚至加入我们的团队并帮助将它们整合在一起。