一次,在一次采访中,一位俄罗斯著名音乐家说:“我们正在努力躺在天花板上随地吐痰。” 我不得不同意这一说法,因为懒惰是技术发展的驱动力这一事实不能被争论。 的确,仅在上个世纪,我们才从蒸汽机转向了数字化工业,如今,上世纪的科幻小说家和未来学家描述的人工智能正日益成为我们世界上越来越大的现实。 电脑游戏,移动设备,智能手表等 基本上使用与机器学习机制相关的算法。
如今,由于图形处理器的计算能力的增长以及已出现的大量数据的出现,神经网络已变得越来越流行,通过它们可以解决分类和回归问题,并在准备好的数据上进行训练。 已经有很多文章介绍了如何训练神经网络以及为此使用哪些框架。 但是还有一个更早的任务需要解决,这是形成数据数组(数据集)以进一步训练神经网络的任务。 这将在本文中讨论。
不久前,需要建立一种声学汽车噪声分类器,该分类器能够从常见的音频流中提取数据:碎玻璃,打开车门并以各种模式操作汽车发动机。 分类器的开发并不困难,但是从哪里获取数据集以使其满足所有要求?
Google采取了拯救行动(Yandex并没有冒犯-我稍后再谈其优势),借助它,可以挑选出包含必要数据的几个主要集群。 我想提前指出,本文中指出的资源包括大量的声音信息,具有各种类别,可让您为不同的任务创建数据集。 现在我们转向这些来源的概述。
Freesound.org Freesound.org
Freesound.org最有可能提供最大数量的声学数据,它是获得许可的音乐样本的联合存储库,目前有23万多个声音效果副本。 每个声音样本都可以在不同的许可下分发,因此最好事先熟悉
许可协议 。 例如,
零(cc0)许可证的状态为“无版权”,它允许您复制,修改和分发,包括商业用途,并允许您绝对合法地使用数据。
为了方便在各种freesound.org中查找声学信息元素,开发人员提供了一个
API,旨在分析,搜索和下载存储库中的数据。 要使用它,您需要获得访问权限,为此,您需要转到
表单并填写所有必需的字段,然后将生成单个密钥。

Freesound.org开发人员为各种编程语言提供了
API ,从而允许使用不同的工具解决相同的问题。 下面列出了支持的语言列表以及在GitHub上访问它们的链接。
为了实现该目标,使用了python,因为这种精美的动态类型编程语言由于易于使用而广受欢迎,从而完全消除了软件开发复杂性的神话。 可以从github.com存储库中克隆用于python的
freesound.org的模块 。
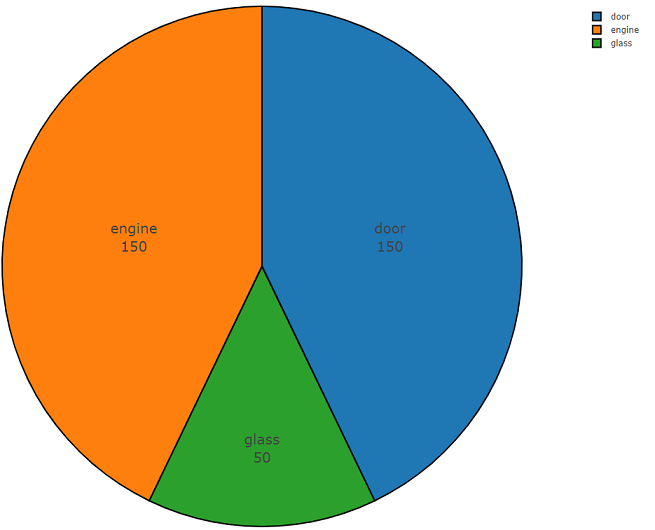
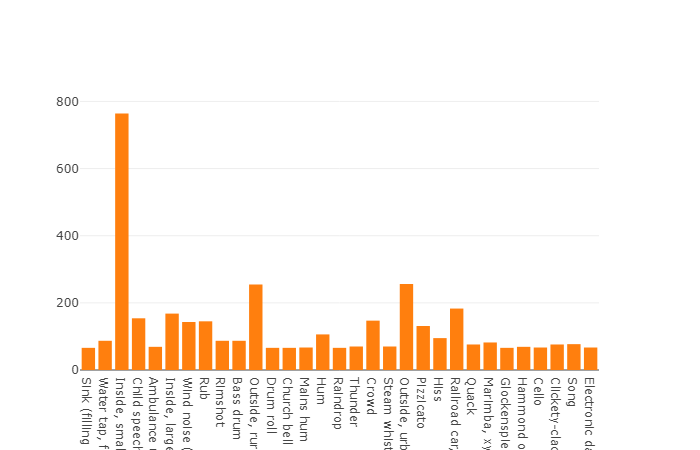
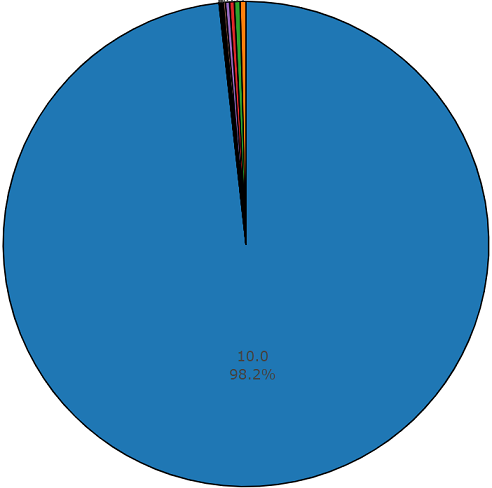
下面是两部分的代码,演示了此API的易用性。 程序代码的第一部分执行数据分析任务,其结果是每个请求类的数据分发密度,第二部分从freesound.org存储库上载选定类的数据。 下面以饼图的形式显示了使用关键字“
玻璃,发动机,门”搜索声学信息时的分布密度。
Freesound.org数据分析示例代码
import plotly import plotly.graph_objs as go import freesound import os import termcolor
下载freesound.org数据的样本代码
freesound的一个功能是无需下载音频文件即可进行音频数据分析,从而使您可以获得MFCC,频谱能量,频谱质心和其他系数。 在
freesound.ord文档中阅读有关低级信息的更多信息。
使用freesound.org API,可以最大程度地减少获取和下载数据所花费的时间,从而使您节省了研究其他信息源的工作时间,因为高精度声学分类器需要具有较大可变性的大型数据集,从而在一个和多个谐波上代表不同谐波的数据。同类事件。
YouTube-8M和AudioSet
我认为演示文稿中并没有特别要求youtube,但是,维基百科告诉我们youtube是一个向用户提供视频显示服务的视频托管网站,忘记了youtube是一个庞大的数据库,并且该来源必须用于机器学习中。 ,而Google Inc为我们提供了一个名为
YouTube-8M数据集的项目。
YouTube-8M数据集是一个数据集,其中包含来自YouTube的超过一百万个高质量的视频文件,以提供更准确的信息,截至2018年5月,有610万个视频具有3862个类别。 此数据集已根据
国际知识共享署名4.0(CC BY 4.0)许可。 这样的许可证允许您以任何媒介和格式复制和分发材料。
您可能想知道:当任务需要声学信息时,视频数据会从哪里进入,您将是对的。 事实是Google不仅提供视频内容,而且还为子项目单独分配了一个名为
AudioSet的音频数据。
 AudioSet-
AudioSet-提供从YouTube视频获得的数据集,其中使用
本体文件在类层次结构中显示了很多数据,其图形表示位于下面。
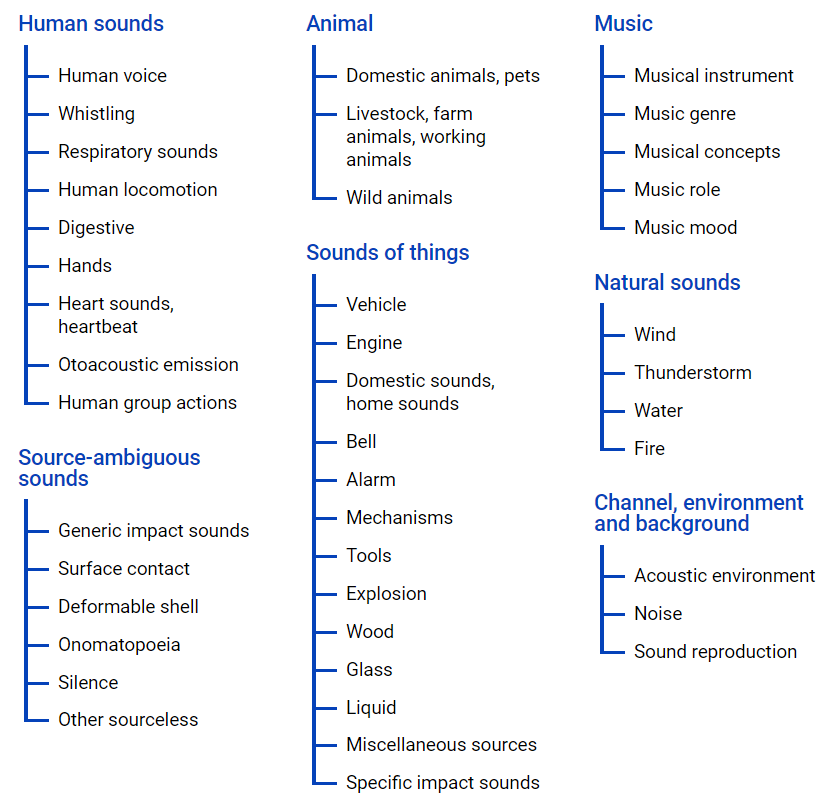
该文件使您可以了解类的嵌套,以及访问youtube视频的信息。 要从Internet空间上传数据,可以使用python模块-youtube-dl,该模块允许您根据所需任务下载音频或视频内容。
AudioSet代表一个分为三组的集群:测试,训练(平衡)和训练(非平衡)
数据集 。
让我们看一下这个集群,并分别分析每个集合,以了解其中包含的类。
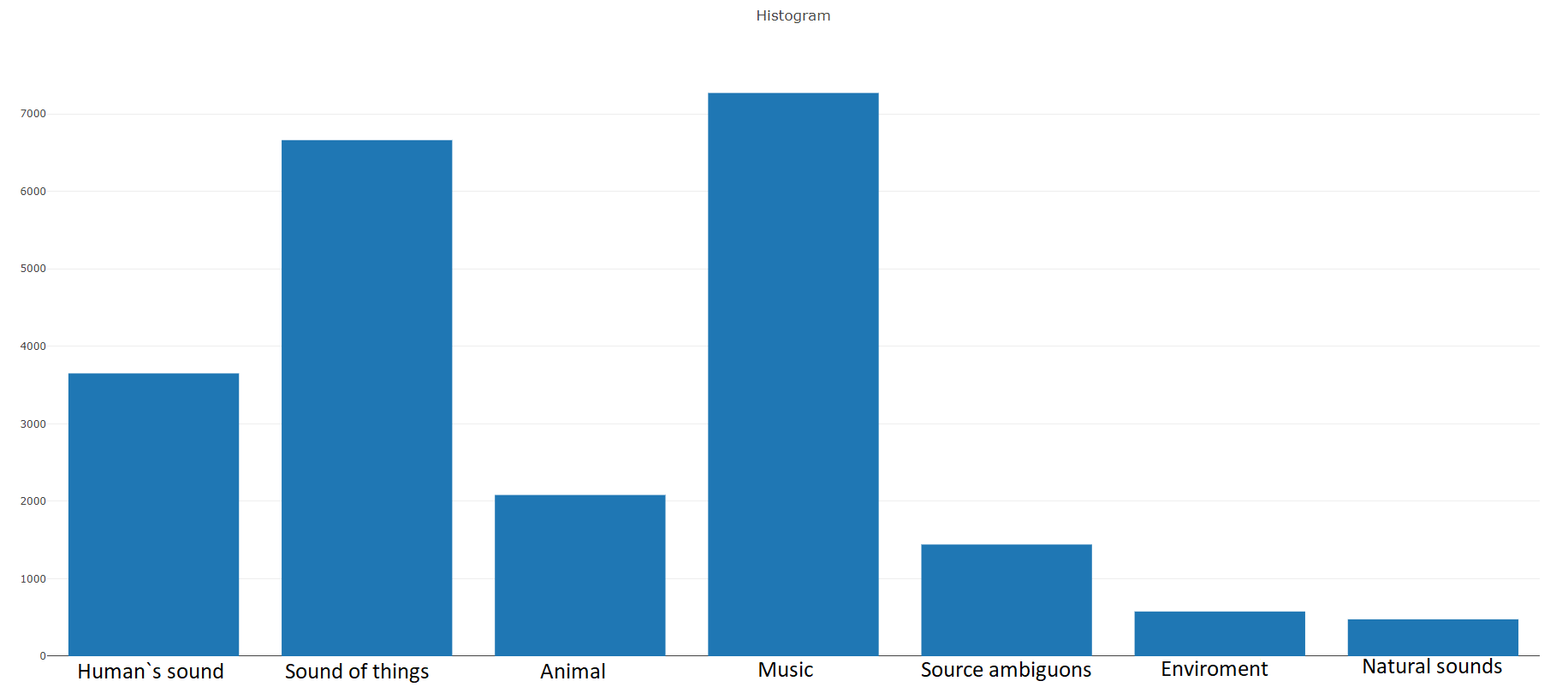
训练(平衡)根据文档,此数据集包含
22176个片段 ,
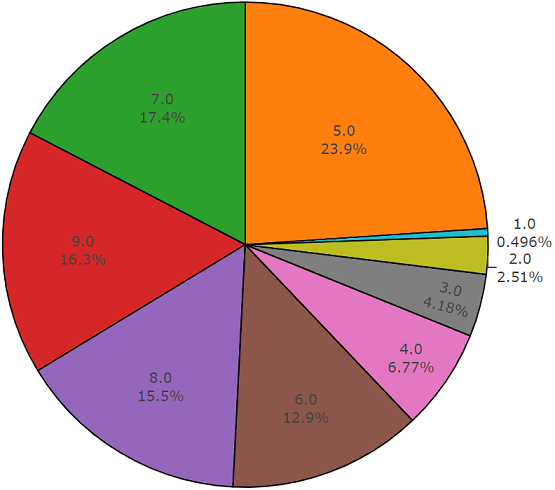
这些片段是通过关键字选择的各种视频中获得的,每个类别至少提供59个副本。 如果我们查看根类在集合层次结构中的分布密度,我们将看到Music类是最大的音频文件组。
有组织的类被分解为类的子集,使您在使用它时可以获得更多详细信息。 这种平衡的训练集具有分布密度,很明显在该分布密度上存在平衡,但是单个类与一般视图非常不同。
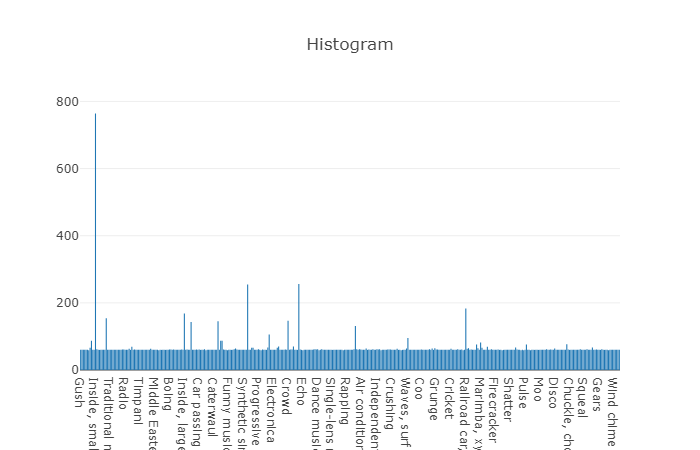
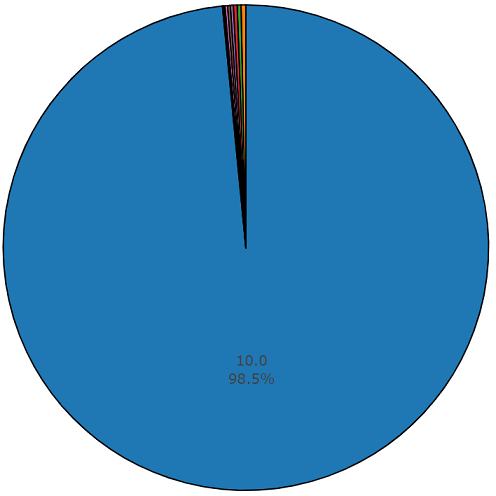
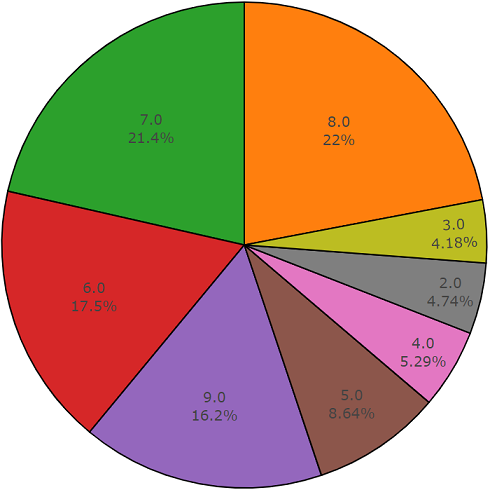
元素数量超过平均值的类的分布
每个音频文件的平均持续时间为10秒,磁盘图显示了更详细的信息,该信息表明某些文件的持续时间与主要文件不同。 此图也显示。
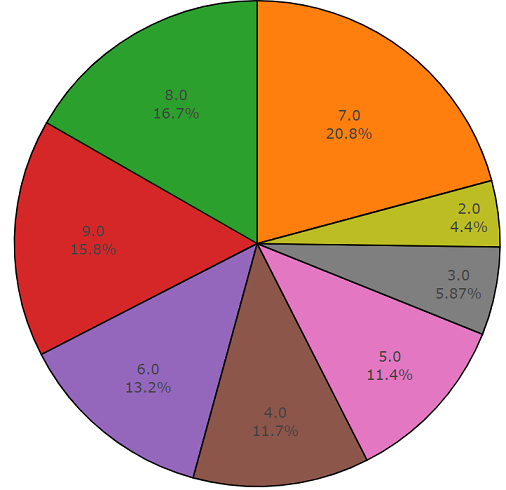
平衡的一组音频集的非平均持续时间的百分之一半的示意图
 培训(不平衡)
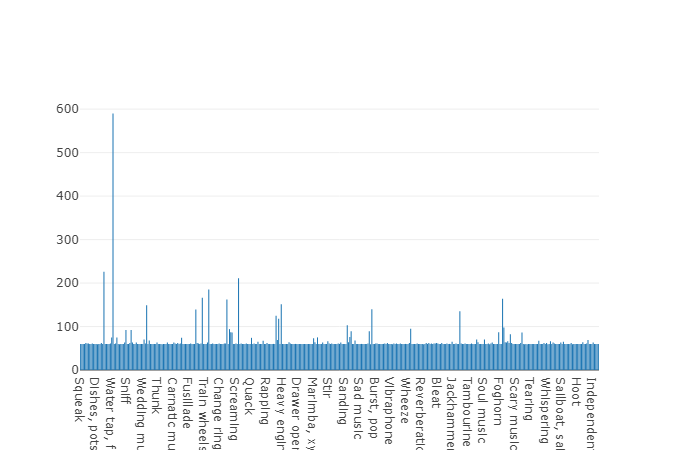
培训(不平衡)该数据集的优点是其大小。 试想一下,根据文档,该集合包括2,042,985个段,并且与平衡数据集相比,它表现出很大的可变性,但是该集合的熵要高得多。
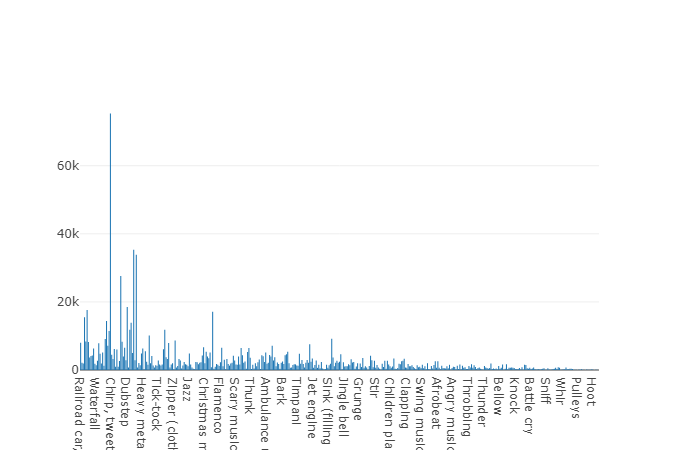
在此集合中,每个音频文件的平均持续时间也等于10秒,此数据集的磁盘图如下所示。
一组不平衡的音频集的非平均持续时间图
 测试集
测试集该集合与平衡集合非常相似,其优点是这些集合的元素不相交。 它们的分布如下。
元素数量超过平均值的类的分布
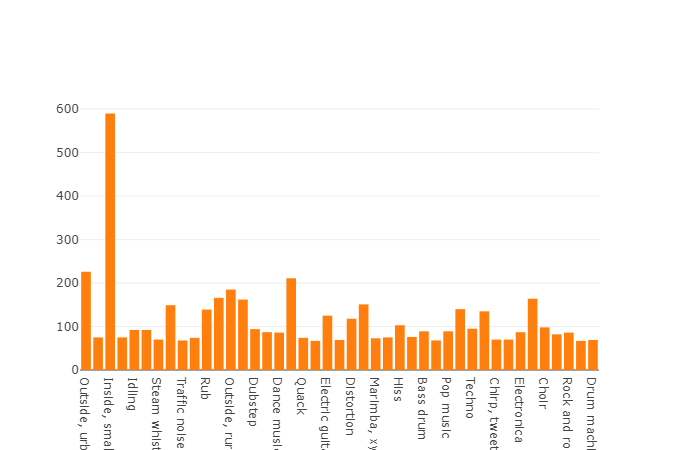
该数据集中一个片段的平均持续时间也等于10秒
其余部分的持续时间如磁盘图所示
根据所选数据集分析和下载声学数据的示例代码:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
要获得有关音频集数据分析的更多详细信息,或根据
本体文件和选定
的音频集集从yotube空间上传此数据,程序代码可免费提供给
GitHub存储库 。
都市之声
Urbansound是具有标记声音事件的最大数据集之一,其类别属于城市环境。 该集合称为分类学(分类),即 每个类均分为其子类。 这样的众多群体可以表示为一棵树。
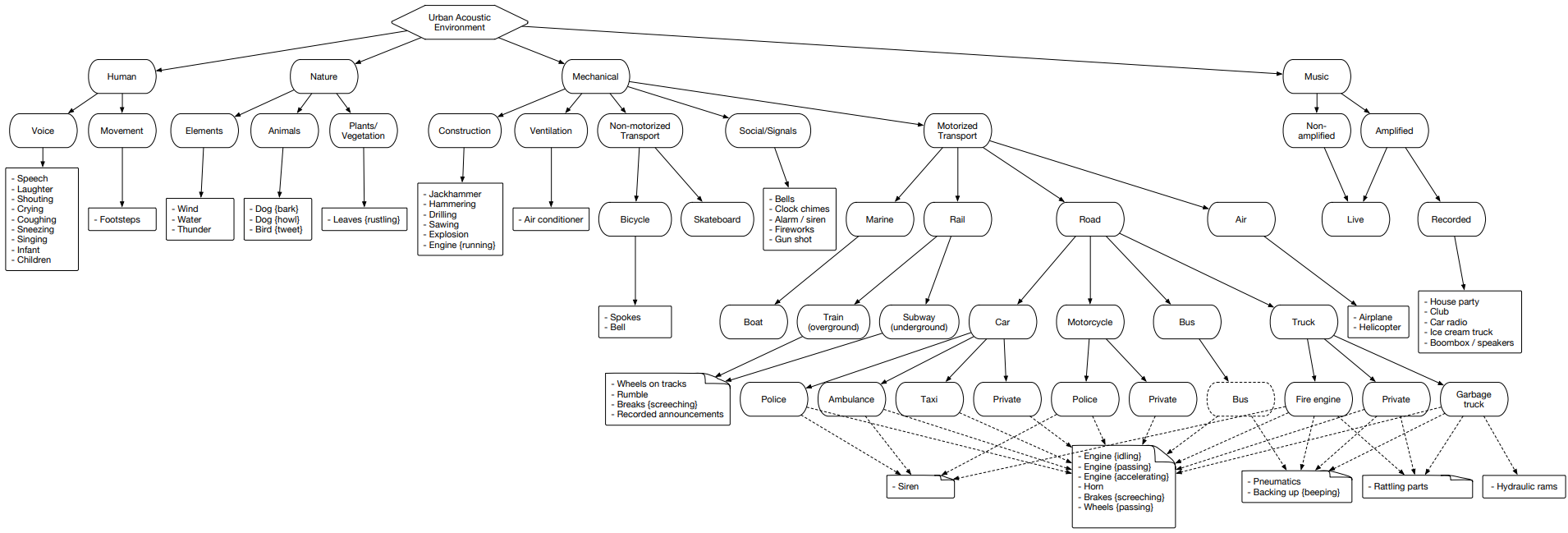
要上传Urbansound数据供以后使用,只需转到该页面,然后点击
下载 。
由于该任务不需要使用所有子类,并且只需要与汽车关联的一个类,因此首先需要使用解压缩下载文件时获得的目录根目录中的元文件来过滤必要的类。
从列出的源中卸载了所有必要的数据后,结果形成了一个包含15,000多个文件的数据集。 如此大量的数据使我们可以继续进行声学分类器的训练任务,但是关于数据的“纯度”(即纯度)仍未解决。 训练集包括与解决问题的必要类别无关的数据。 例如,在听“玻璃破碎”类的文件时,您会发现人们在谈论“玻璃破碎是多么不好”。 因此,我们面临着过滤数据的任务,作为解决此类问题的工具,这是非常适合的工具,该工具的核心是白俄罗斯人开发的,并使用了奇怪的名称“ Yandex.Toloka”。
Yandex.Toloka
Yandex.Toloka是一个于2014年创建的众筹项目,用于标记或收集大量数据以进一步用于机器学习。 实际上,此工具允许您使用人力资源来收集,标记和过滤数据。 是的,该项目不仅可以解决问题,还可以使其他人赚钱。 在这种情况下,经济负担将由您自己承担,但由于表演者的行动超过10,000名托克尔,因此不久将收到工作成果。 您可以在
Yandex博客上找到有关此工具操作的详细说明。
一般而言,使用Crush并不是特别困难,因为任务的发布仅需要在
网站上注册,最低金额为10美元和正确执行的任务。 如何正确地制定任务,可以查看
Yandex.Tolok文档,或者
在Habr上没有不好的
文章 。 从我本人到本文,我想补充一点,即使缺少适合您任务要求的模板,其开发也将花费不超过几个小时的时间,还需要喝咖啡和抽烟,并且可以在工作日结束时获得表演者的成绩。
结论在机器学习中,解决分类或回归问题时,主要任务之一是开发可靠的数据集-数据集。 在本文中,考虑了具有大量声学数据的信息源,这使得有可能形成和平衡用于特定任务的必要数据集。 所提供的程序代码使我们可以简化上传数据的操作,从而减少了接收数据并将剩余时间用于开发分类器的时间。
对于我的任务,在从本文介绍的所有来源收集数据并随后对数据进行过滤之后,我设法形成了必要的数据集,用于训练基于神经网络的声学分类器。 我希望本文将使您和您的团队节省时间,并将其花费在新技术的开发上。
PS一个用python开发的软件模块,用于分析和上传每个呈现源的声学数据,您可以在
github存储库中找到