您好,卫兵。 今天的帖子将讨论如何在使用TensorFlow进行机器学习并实现您的目标的众多选择中迷失自我。 设计这篇文章是为了使读者了解机器学习原理的基础知识,但尚未尝试自己动手做。 结果,我们在Android上获得了一个有效的演示,该演示可以识别出相当高的准确性。 但是首先是第一件事。

在查看了最新资料后,决定与Tensorflow接触 ,后者现在正迅速发展,并且用英语和俄语撰写的文章似乎足以不深入研究所有内容并能够弄清楚是什么。
花了两个星期,在办公室学习文章和大量样本。 网站上,我意识到自己一无所知。 关于如何使用Tensorflow的太多信息和选项。 应用到我的任务中,它们提供了多少不同的解决方案以及如何处理这些问题,我已经感到不解。

然后,我决定尝试从最简单,最现成的选项(其中要求我在gradle中注册依赖项并添加几行代码)到更复杂的选项(其中我必须自己创建和训练图模型并学习如何在移动设备中使用它们)中的所有内容应用程序)。
最后,我不得不使用一个复杂的版本,下面将对此进行详细讨论。 同时,我为您汇编了同样有效的简单选项列表,只是每个选项都适合其目的。

最容易使用的解决方案-您可以使用几行代码:
- 文字识别(文字,拉丁字符)
- 人脸检测(人脸,情绪)
- 条形码扫描(条形码,二维码)
- 图像标签(图像中类型有限的对象)
- 地标识别(景点)
有点复杂。使用此解决方案,您还可以使用自己的TensorFlow Lite模型,但是转换为这种格式会带来困难,因此尚未尝试此项。
正如这个后代的创造者所写的那样,使用这些开发可以解决大多数任务。 但是,如果这不适用于您的任务,则必须使用自定义模型。

使用图像创建和训练自定义模型的非常方便的工具。
在Pros中-有一个免费版本,可让您保留一个项目。
缺点-免费版本将“传入”图像的数量限制为3,000。 尝试建立一个中等精度的网络-足够了。 对于更精确的任务,您需要更多。
用户所需要做的就是添加标记的图像(例如-image1是“ racoon”,image2是“ sun”),训练并导出图形以备将来使用。
充满爱心的Microsoft甚至提供了自己的示例 ,您可以使用该示例试用收到的图表。
对于已经“处于主题中”的人-图形已经在“冻结”状态下生成,即 您不需要执行任何操作或对其进行任何转换。
当您在训练中有大量样本和(注意)不同类别的很多时,此解决方案是很好的。 因为 否则在实践中会有很多错误的定义。 例如,您接受过浣熊和太阳的培训,如果入口处有人,那么该系统可以将一个人与另一个人相等地定义为一个人。 虽然事实上-两者都不是。
3.手动创建模型

当您需要自己微调模型以进行图像识别时,可以使用输入图像选择进行更复杂的操作。
例如,我们不想限制输入样本的数量(如上一节所述),或者我们想通过自己设置历元数和其他训练参数来更精确地训练模型。
在这种方法中,Tensorflow提供了几个示例来描述过程和最终结果。
以下是一些示例:
它提供了一个示例,说明如何基于开放的ImageNet图片数据库创建颜色类型分类器-准备图片,然后训练模型。 还很少提及如何使用一个非常有趣的工具TensorBoard。 它具有最简单的功能-可以从许多方面清楚地说明您完成的模型的结构以及学习过程。
萝卜包含原始模型(已经为该任务准备好了),有关如何训练,转换模型以及最后如何运行Android项目以检查其全部工作方式的说明
根据这些示例,您可以弄清楚如何在Tensorflow中使用自定义模型,并尝试制作自己的模型或采用github上组装的预训练模型之一:
Tensorflow的模型
说到“预训练”模型。 使用这些时的有趣细微差别:
- 他们的结构已经为特定任务做好了准备。
- 他们已经接受了大样本量的培训。
因此,如果您的样品填充不足,则可以采用预训练的模型,该模型的范围接近您的任务。 使用此模型,添加您自己的训练规则,您将获得比尝试从头开始训练模型更好的结果。
4.对象检测API +手动模型创建
但是,所有前面的段落都没有得到期望的结果。 从一开始就很难理解需要做什么以及采用什么方法。 然后找到了一篇有关对象检测API的不错的文章,该文章讲述了如何在一张图像上找到多个类别以及相同类别的多个实例。 在处理此样本的过程中,有关识别自定义对象的源文章和视频教程被证明更为方便(链接将在最后)。
但是,如果没有关于皮卡丘识别的文章,就无法完成这项工作-因为在那里指出了一个非常重要的细微差别,出于某种原因,在一个指南或示例中都没有提及该细节。 没有它,所有完成的工作都是徒劳的。
因此,现在最后是关于尚要做的事情以及即将发生的事情。
- 首先是Tensorflow安装的面粉。 谁不能安装它,或使用标准脚本创建,训练模型的人,请耐心等待和使用Google。 几乎所有问题都已经写在githib或stackoverflow上。
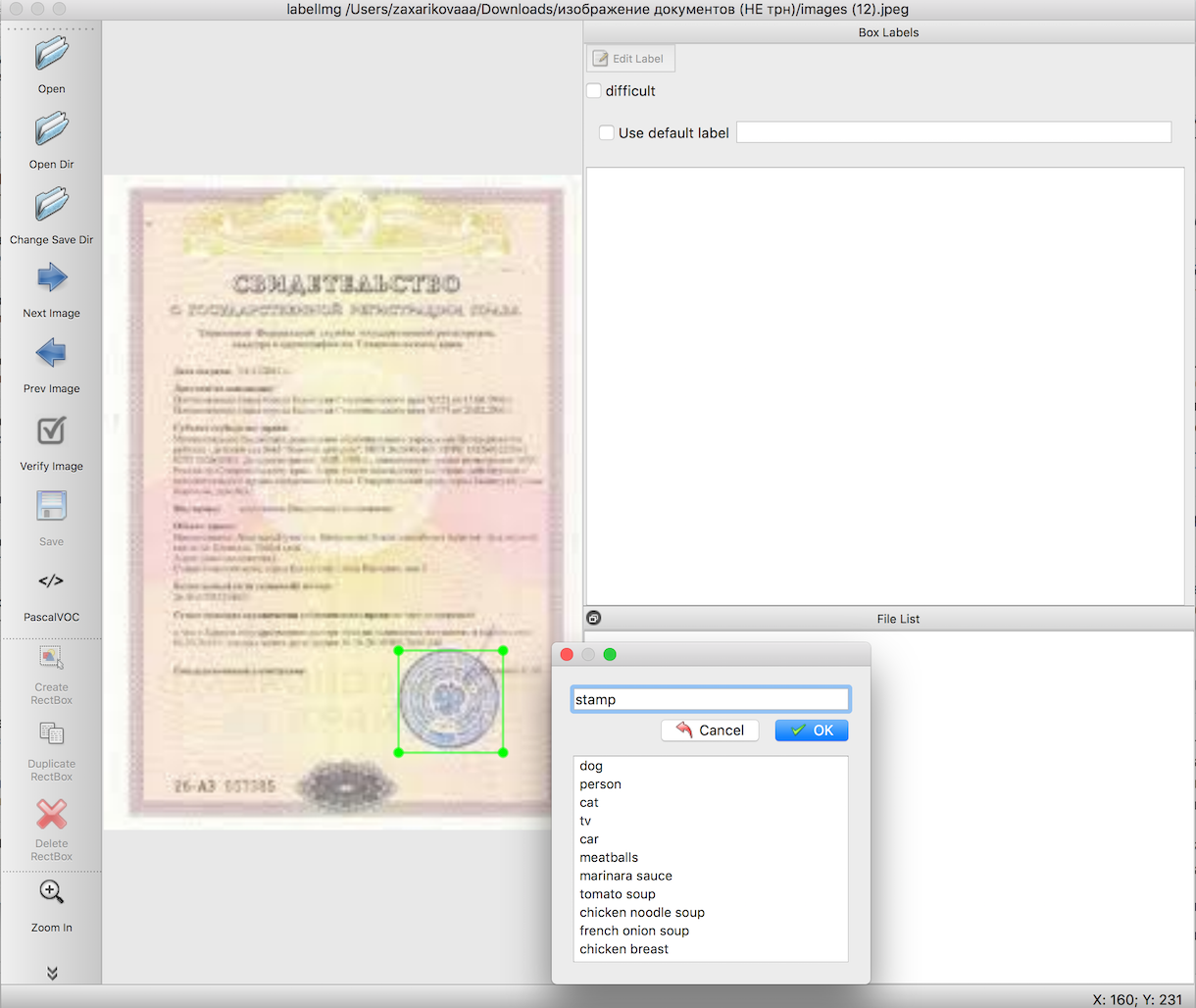
根据对象识别的说明,我们需要在训练模型之前准备输入样本。 这些文章详细描述了如何使用便捷的工具labelImg来执行此操作。 这里唯一的困难是在突出我们需要的对象的边界方面做非常长时间而细致的工作。 在这种情况下,请在文档图像上盖章。
下一步,使用现成的脚本,我们首先将步骤2中的数据导出到csv文件,然后导出到TFRecords-Tensorflow输入数据格式。 这里不应该出现任何困难。
选择预训练模型,在此模型的基础上,我们将对图形进行预训练,以及训练本身。 这是可能发生最多数量的未知错误的地方,其原因是工作所需的软件包被卸载(或错误安装)。 但是您会成功,不要失望,结果值得。

将训练后收到的文件导出为“ pb”格式。 只需选择最后一个文件“ ckpt”并导出即可。
在Android上运行工作示例。
从Tensorflow github-
TF Detect下载官方对象识别样本。 在其中插入带有标签的模型和文件。 但是 什么都行不通。

奇怪的是,这是所有工作中最大的麻烦发生了-好吧,Tensorflow示例并不想以任何方式工作。 一切都下降了。 只有强大的皮卡丘在他的文章中设法帮助使一切正常工作。
labels.txt文件中的第一行必须是题词“ ???”,因为 在对象检测API中,默认情况下,对象的ID号不是像往常一样以0开头,而是以1开头。由于保留了null类,因此应该指出魔术问题。 即 您的标记文件将如下所示:
??? stamp
然后-运行示例,查看对象的识别以及对其的信任程度。
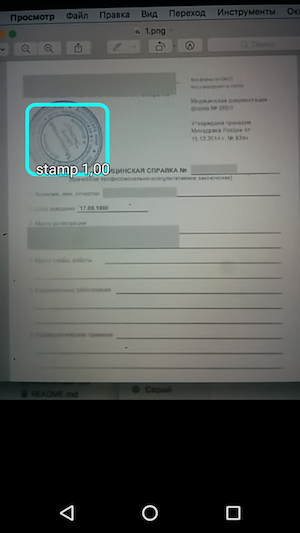
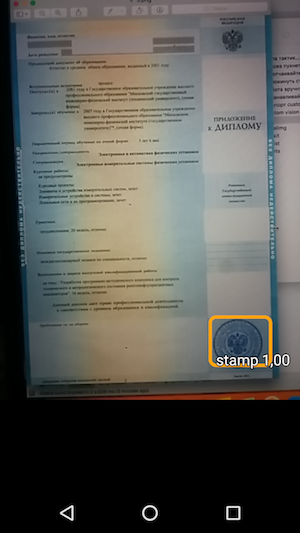
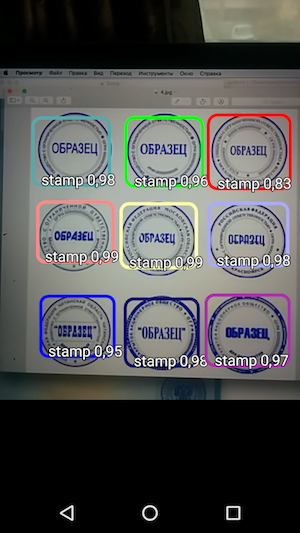
因此,结果是一个简单的应用程序,当您将鼠标悬停在相机上时,它可以识别文档上的图章边界,并与识别精度一起指示它们。
而且,如果我们排除了寻找正确方法并尝试启动它所花费的时间,那么总的来说,这项工作很快就完成了,而且实际上并不复杂。 在开始工作之前,您只需要了解细微差别。
作为一个附加部分(如果您对信息感到厌倦,可以在这里关闭文章),我想写一些生活技巧,以帮助解决所有这些问题。
tensorflow脚本经常无法正常运行,因为它们是从错误的目录运行的。 此外,它在不同的PC上也有所不同:有人需要从tensroflowmodels/models/research目录运行以进行工作,而有人则tensroflowmodels/models/research/object-detection从tensroflowmodels/models/research/object-detection更深入的tensroflowmodels/models/research/object-detection
请记住,对于每个打开的终端,您需要使用以下命令再次导出路径
export PYTHONPATH=/ /tensroflowmodels/models/research/slim:$PYTHONPATH
如果您不使用自己的图,并且想要查找有关它的信息(例如,“ input_node_name ”,稍后需要),请从根文件夹运行两个命令:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ /frozen_inference_graph.pb"
其中“ / /frozen_inference_graph.pb ”是您要了解的图形的路径
要查看有关图形的信息,可以使用Tensorboard。
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
您需要在其中指定图的路径( model_dir )和训练期间收到的文件的路径( log_dir )。 然后,只需在浏览器中打开localhost并查看您感兴趣的内容。
最后一部分-有关在对象检测API说明中使用python脚本的信息-为您准备了下面的小备忘单,其中包含命令和技巧。
备忘单从labelimg导出到csv(从object_detection目录)
python xml_to_csv.py
此外,下面列出的所有步骤应从同一Tensorflow文件夹(“ tensroflowmodels/models/research/object-detection ”或上一层-取决于您的操作方式)执行-仅此tensroflowmodels/models/research/object-detection在开始工作之前,必须将输入选择的图像,TFRecords和其他文件复制到此目录中。
从csv导出到tfrecord
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
*不要忘记更改文件本身(generate_tfrecord.py)中的路径中的“ train”和“ test”行,以及
class_text_to_int函数中识别的类的名称(在训练图形之前必须在将创建的pbtxt文件中重复这些pbtxt )。
培训课程
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
**在进行培训之前,请不要忘记检查文件“ training/object-detection.pbtxt ”-应该有所有可识别的类,并且文件“ training/ssd_mobilenet_v1_coco.config ”-您需要将参数“ num_classes ”更改为您的班级数量。
将模型导出到PB
python export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=training/pipeline.config \ --trained_checkpoint_prefix=training/model.ckpt-110 \ --output_directory=output
感谢您对此主题的关注!
参考文献
- 有关物体识别的原始文章
- 有关英文物体识别的文章的录像带循环
- 原始文章中使用的脚本集