我在
hh.ru从事开发人员工作,我想学习datasines,但是到目前为止,技能还不够。 因此,在业余时间,我学习机器学习并尝试解决该领域的实际问题。 最近,他们把我的简历归类给了我。 这篇文章将讲述我如何使用聚集层次聚类解决问题。 如果您不想阅读,但是结果很有趣,那么您可以立即查看该
演示 。

背景知识
劳动力市场在不断变化,新兴的职业正在兴起,其他职业正在消失,我想对简历进行分类。 hh.ru上的专业领域和专业目录早已过时:与它有很多联系,因此很长一段时间未进行任何更改。 学习如何轻松地编辑这些类别将很有用。 我正在尝试自动识别这些类别。 我希望将来这将有助于解决问题。
关于所选方法和集群
通过聚类,我将了解一组中具有最相似特征的对象的组合。 在我的情况下,该对象下的被认为是简历,而该对象下的是摘要数据:例如,简历中“经理”一词的出现频率或薪水大小。 对象的相似性由预先选择的指标确定。 现在,您可以将其视为一个黑盒子,该黑盒子在输入处接收两个对象,并且输出产生一个数字,该数字反映了例如矢量空间中对象之间的距离:距离越小,对象越相似。
我使用的方法可以称为向上聚集层次聚类。 聚类的结果是一棵二叉树,在叶子中有单独的元素,树的根是所有元素的集合。 之所以称为上升,是因为聚类从树的最低层开始,有叶子,其中每个单独的元素都被视为一个簇。

然后,您需要找到两个最接近的群集并将它们合并到一个新的群集中。 必须重复执行此过程,直到只有一个群集包含所有对象。 组合群集时,将记录它们之间的距离。 将来,这些距离可用于确定这些距离足够大以将所选群集视为单独的位置。
大多数聚类方法都假定聚类的数目是预先已知的,或者尝试根据该算法和该算法的参数独立地隔离聚类。 分层聚类的优点是您可以尝试通过检查结果树的属性来确定所需的聚类数量,例如,选择在不同组之间具有不同距离的子树。 使用结果结构在其中搜索簇很方便。 方便地,这种结构只构建一次,而在搜索所需数量的集群时不需要重建。
在缺点中,我要提到的是,该算法对消耗的内存要求很高。 而且,我不想分配特定的类别,而是希望简历属于该类别,以便不着眼于最近的专业,而是着眼于整体。
数据收集与准备
处理数据中最重要的部分是其准备,选择和检索属性。 最终取决于获得哪些符号,这将取决于它们中是否有模式,这些模式是否与预期结果相对应以及该“预期结果”是否完全可能。 在将数据提供给某种机器学习算法之前,您需要了解每个符号,是否存在间隙,符号属于什么类型,这种符号具有什么属性以及该符号中的值的分布。 选择正确的算法来处理可用数据也很重要。
我拿了过去六个月更新的简历。 结果是270万,我从简历的数据中选择了最简单的标志,在我看来,简历的成员资格应取决于一个或另一组。 展望未来,我要说的是将所有简历立即聚类的结果令我不满意。 因此,我们必须首先将简历除以现有的28个专业领域。
对于每个特征,我都绘制了分布图,以了解数据的外观。 也许他们应该以某种方式被转变或完全被抛弃。
地区 为了使此功能的值可以相互比较,我将属于该区域的简历总数分配给每个区域,并从该数字中取对数以消除大城市和小城市之间的差异。
保罗 转换为二进制符号。
出生日期 。 以月数计算。 不是每个人都有生日。 我用这份简历所属专业领域的平均年龄来填补空白。
受教育程度 。 这是一个分类标志。 我用
LabelBinarizer对其进行了
编码 。
订单项的名称 。 我使用了一个
词干 分析器,使用ngram_range =(1,2)开车穿过
TfidfVectorizer 。
工资待遇 。 将所有值翻译成卢布。 我以与我年龄相同的方式填补了空白。 从值取对数。
工作时间表 。 编码的LabelBinarizer。
就业率 。 我将其制作成二进制文件,将其分为两部分:全职和其余部分。
语言能力 。 我选择了最常用的。 每种语言均设置为单独的功能。 所有权级别由0到5的数字匹配。
关键技能 。 我开车经过TfidfVectorizer。 作为停用词,我整理了一个小的通用技能词典,这些词汇在我看来并不影响专业。 所有单词都通过词干。 每个关键技能不仅可以包含一个单词,还可以包含多个单词。 对于关键技能中的几个单词,我对单词进行了排序,还将每个单词用作单独的属性。 该功能仅在专业领域“信息技术,互联网,电信”中运行良好,因为人们通常会指出与其专业相关的技能。 在其他专业领域,由于一般的语言技巧丰富,我没有使用它。
专长 我将每个用户指定的专业设置为二进制属性。
工作经验 。 取月数+1的对数,因为有些人没有工作经验。
标准化
结果,每个简历开始都是数字符号的载体。 所选的聚类算法基于对象之间的距离的计算。 如何确定每个要素应如何影响此距离? 例如,有一个二进制符号-0和1,而另一个符号可以采用0到1000之间的许多值。
标准化来了。 我使用
StandardScaler 。 他以如下方式变换每个特征,即其平均值为零,与均值的标准偏差为1。 因此,我们正在尝试将所有数据归为同一分布-标准正态分布。 当然,数据本身具有正态分布的性质远非事实。 这只是建立参数分布图的原因之一,并且很高兴它们看起来像高斯模型。
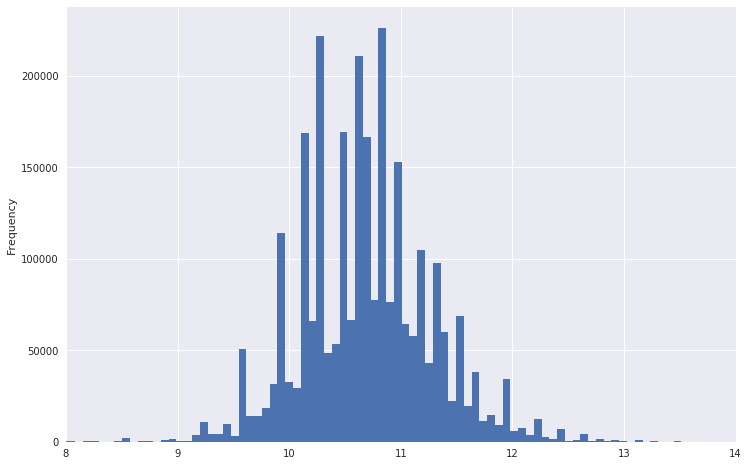
因此,例如,工资分配图看起来像。

可以看出他的尾巴很重。 为了使分布更接近正态分布,可以从该数据中取对数。 同时,排放不会那么强。
降级
现在,将数据传输到较小的空间是有意义的,以便将来聚类算法可以在可接受的时间和内存中消化它们。 我使用了
TruncatedSVD ,
因为它知道如何处理稀疏矩阵,并且在输出时会给出通常的密集矩阵,这是我们进一步工作所需要的。 顺便说一下,TruncatedSVD还需要提交标准化数据。
在同一阶段,值得尝试可视化结果数据集,并使用
t-SNE将其转换为二维空间。 这是非常重要的一步。 如果在结果图像中看不到任何结构,或者相反,此结构看起来很奇怪,则说明您的数据没有必要的规律性,或者某个地方发生了错误。
在一切顺利之前,我得到了很多非常可疑的图像。 例如,曾经有过如此美丽的影像:

产生蠕虫的原因是在数据集中获取了简历标识符。 这与事实更相似:

聚类
如果一切看起来都与数据一致,则可以开始聚类。 我使用了SciPy的
Hierarchical clustering包。 它允许使用
链接方法进行聚类。 我尝试了算法中建议的所有聚类距离度量。 最好的结果是通过
Ward方法得出的。
我遇到的主要问题是聚类算法计算所有元素之间的距离矩阵,这意味着元素数量与二次存储有关。 对于270万份简历,我没有成功,因为 所需的内存量为TB。 所有计算均在常规计算机上进行。 我没有太多RAM。 因此,在我看来,您可以首先合并附近的简历,以结果组的中心为准,并已将它们与所需的算法聚在一起,这似乎是合理的。 我带了
MiniBatchKMeans ,与它形成了30,000个集群,并将它们发送给分层集群。 它奏效了,但结果是马马虎虎。 许多最引人注目的简历组脱颖而出,但细节不足以找到高水平的专业化知识。
为了提高获得的专业知识的质量,我将数据分为专业领域。 原来,有40万份履历和更少的数据集。 那时,我想到对数据样本进行聚类比连续使用两种算法要好。 因此,我放弃了MiniBatchKMeans,每个专业化都占用了100,000个简历,以便链接方法可以消化它们。 32 Gb的RAM还不够,因此我为交换分配了额外的100 Gb。 结果,链接提供了一个矩阵,其中每个步骤组合的簇之间的距离以及所得簇中元素的数量。
作为比较不同版本的数据集和计算聚类之间距离的不同方法的质量控制指标,该算法使用了从
cophenet获得的cophenetic相关系数。 该系数显示得到的树状图如何很好地反映对象之间的不相似性。 该值越接近于统一,就越好。
可视化
验证集群质量的最佳方法是可视化。
树状图方法绘制生成的树状图,您可以在树上按距离或树中的级别选择聚类:

下图显示了聚类之间的距离与迭代步数的相关性,在该迭代步数上,两个最接近的聚类被组合为一个新的聚类。 绿线显示了加速度如何变化-连接的群集之间的距离速度。
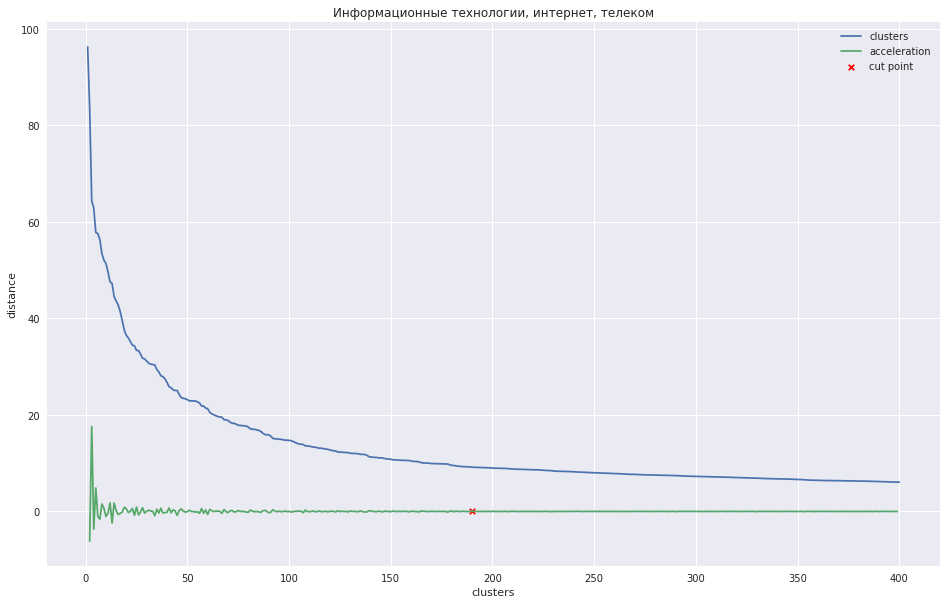
在集群数量较少的情况下,可以尝试在最大加速度(即两个集群组合在一起的那一刻的距离更大)的位置修剪树,并在下一步骤中将其缩小。 就我而言,一切都不尽相同-我有很多簇,我建议最好在加速度开始更加单调降低的位置上切割树状图,即在此级别上的簇之间的距离不再表示一个单独的组。 在图形上,此位置大约在绿线停止跳舞的位置。
人们可以想出一种编程方法,但是事实证明,用28个专业领域的28手标记这些位置
并将所需数量的簇传递给
fcluster方法会
更快 ,这将在正确的位置切割树。
我保存了之前从t-SNE获得的数据,并记录了在它们上产生的簇。 看起来不错:

结果,我创建了一个Web界面,您可以在其中查看每个集群的摘要,其在图表上的位置并提供有意义的名称。 为了方便起见,我推导出了最常见的简历标题-它通常很好地描述了群集的名称。
您可以在
此处查看集群的
结果 。
我自己得出结论,该系统原来正在运行。 虽然按组划分的方法并不完美,有些组彼此非常相似,但是相反,有些组可以分成几部分,但是专业市场的主要趋势清晰可见。 您还可以查看新组的形成方式。 例如,卸载简历是在夏天完成的,因此
想要在世界杯上工作的车手脱颖而出。 如果您学会了在发布之间相互匹配集群,那么您可以观察专业化的主要领域随时间变化的情况。 实际上,提高质量和发展的想法仍然很充裕。 如果我能找到合适的动力,我会进一步发展。
附加材料
有关在数据中搜索结构的课程中
有关聚集层次聚类的视频关于符号的缩放和归一化SciPy库中的
层次结构集群教程 ,我以此为基础
以sklearn库为例
比较不同类型的聚类小小的奖金。 我认为人们对某人如何完成任务很感兴趣。 我想说的是,在执行此项目时,在某些问题上我表现出色。 我尝试了各种选择,研究了一下,思考了这东西是如何工作的。 在许多地方,缺乏良好的数学基础被足智多谋和大量尝试所抵消。 并且,我想分享遭受苦难的
Evernote工作表 ,其中我在完成任务时会做笔记。 其中的反映仅是针对我的,有很多异端和不解,但我认为这是正常的。
UPD:我发布了带有
数据准备和
群集代码的笔记本电脑。 我不打算上传代码,对此质量感到抱歉。