嗨,我叫Maxim,我是系统管理员。 三年前,我和我的同事开始将产品转移到微服务,并决定使用Openstack作为平台,在自动化测试电路时,我们遇到了许多明显的麻烦。 这篇文章是关于设置OpenStack的细微差别的,这些细节很难在搜索引擎结果的第五页上找到(或者更好的是,它们很容易出现在第一页上)。
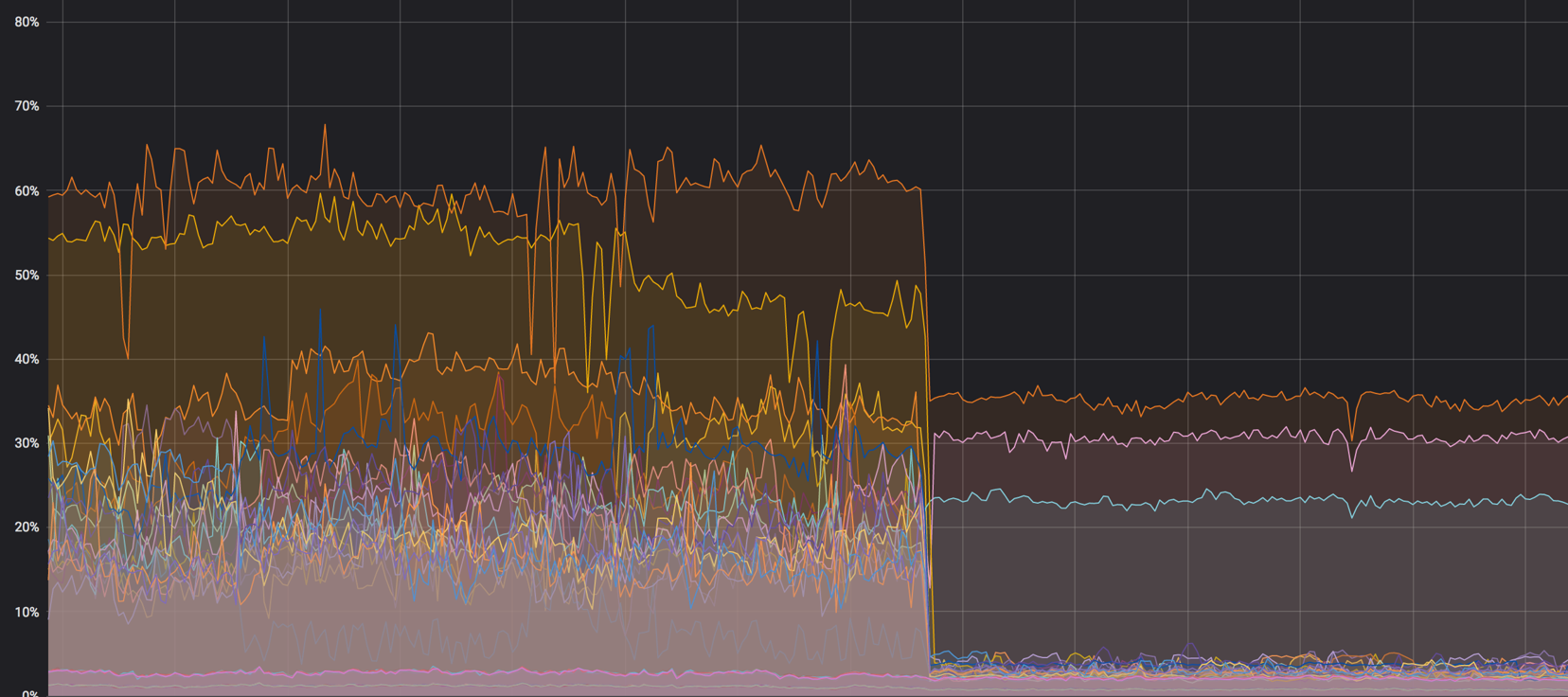
核心上的负载:原来是-它变成了
NAT
在某些情况下,我们使用双栈。 这是虚拟机一次接收两个地址-IPv4和IPv6的时候。 首先,我们确保在内部网络中通过NAT分配了“浮动” v4地址,并且该机器通过BGP接收了v6,但这存在一些问题。
NAT-网络中的另一个节点,即使没有该节点,您也需要监视正常的负载分配。 NAT在网络上的出现几乎总是会导致调试困难-主机上有一个IP,数据库中有另一个IP,因此很难跟踪请求。 开始大规模搜索,并且解决方案仍将在OpenStack中。
NAT仍然不允许对项目之间的访问进行正常的分段。 所有项目都有自己的子网,浮动IP不断迁移,使用NAT绝对不可能管理它。 在某些安装中,他们谈论使用NAT 1合1(内部地址与外部地址没有区别),但这仍然在与外部服务的交互链中留下了不必要的链接。 我们得出的结论是,对我们而言,最佳选择是BGP网络。
越简单越好
我们尝试了各种自动化工具,但选择了Ansible。 这是一个很好的工具,但是在某些困难的情况下,其标准功能(甚至考虑其他模块)可能还不够。
例如,通过Ansible模块,您无法指定要从哪个子网地址分配。 即,您可以指定一个网络,但不能设置特定的地址池。 创建浮动IP的shell命令将在此处提供帮助:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
缺少功能的另一个示例:由于双协议栈,我们无法正确地为v4和v6创建带有两个端口的路由器。 这是bash脚本派上用场的地方:
该脚本创建一个路由器,向其中添加v4和v6子网,并分配一个外部网关。
重试
在任何无法理解的情况下-重新启动。 再试一次,创建一个实例,一个路由器或一个DNS记录,因为您并不总是能很快理解问题所在。 重试可以延迟服务的降级,这时您可以冷静地,毫不费力地解决问题。
上面的所有技巧实际上都可以与Terraform,Puppet和其他任何工具一起使用。
一切都有它的位置
任何大型服务(OpenStack也不例外)结合了许多较小的服务,这些服务可能会干扰彼此的工作。 这是一个例子。
网络代理Neutron-L2-agent负责OpenStack中的网络连接。 如果所有其他代理均部分位于控制器上,则L2(由于特定原因)随处可见。
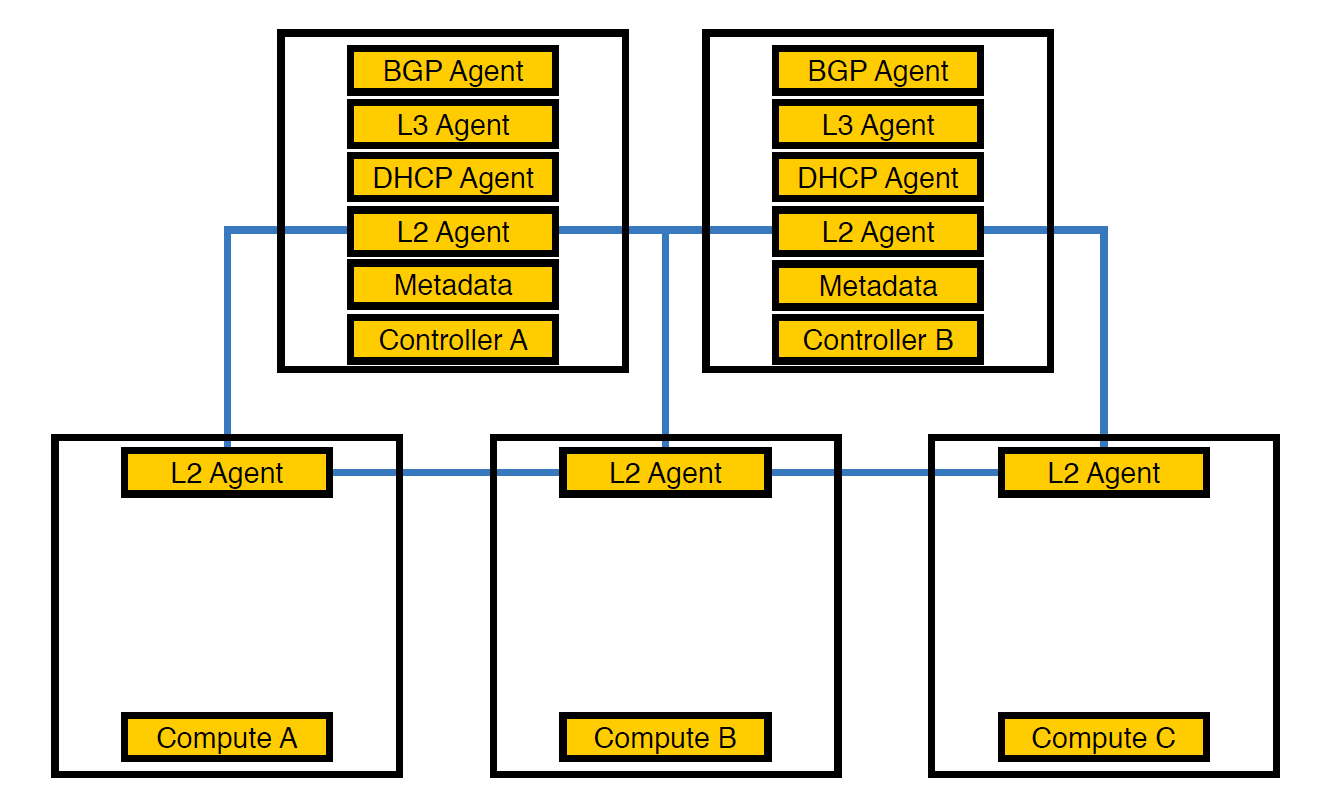
这是我们的基础架构从一开始就看待的方式,直到方案数量超过50
至此,我们意识到由于代理的这种安排,控制器无法应付负载,因此将代理转移到计算节点。 它们比控制器更强大,此外,控制器不必处理所有事情-它必须将任务交给执行节点,然后节点将执行该任务。

将代理转移到计算节点
但是,这还不够,因为这样的安排会对虚拟机的性能产生不良影响。 由于每个物理设备具有14个虚拟核心的密度,如果一个网络代理开始加载流,这可能会同时影响多个虚拟机。
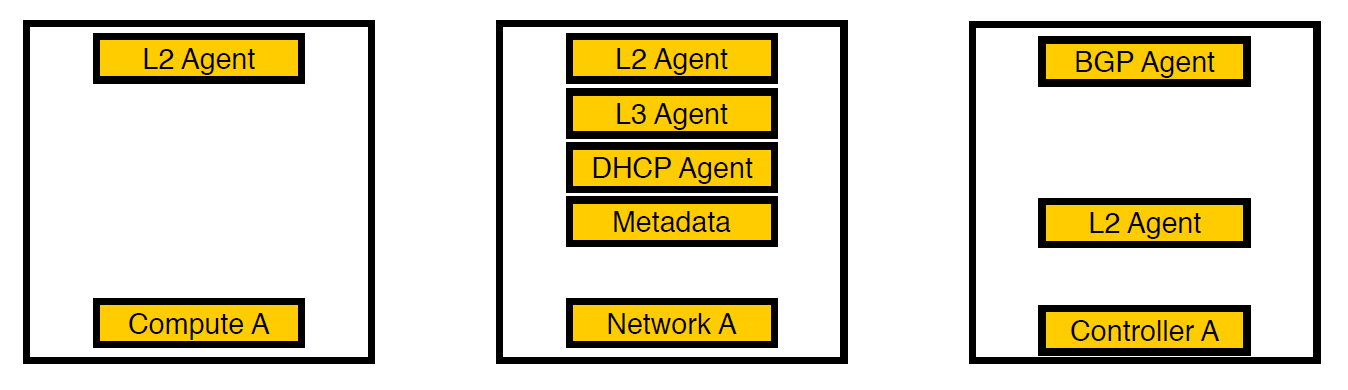
第三次迭代。 出现选定的节点。
我们考虑并将代理移动到单独的网络节点。 现在,只有虚拟机服务保留在计算节点上,所有代理都在网络节点上工作,并且仅处理v6网络的bgp代理保留在控制器上(因为一个bgp代理只能服务一种类型的网络)。 L2仍然无处不在,因为没有它,正如我们上面所写的,网络上将没有连接。
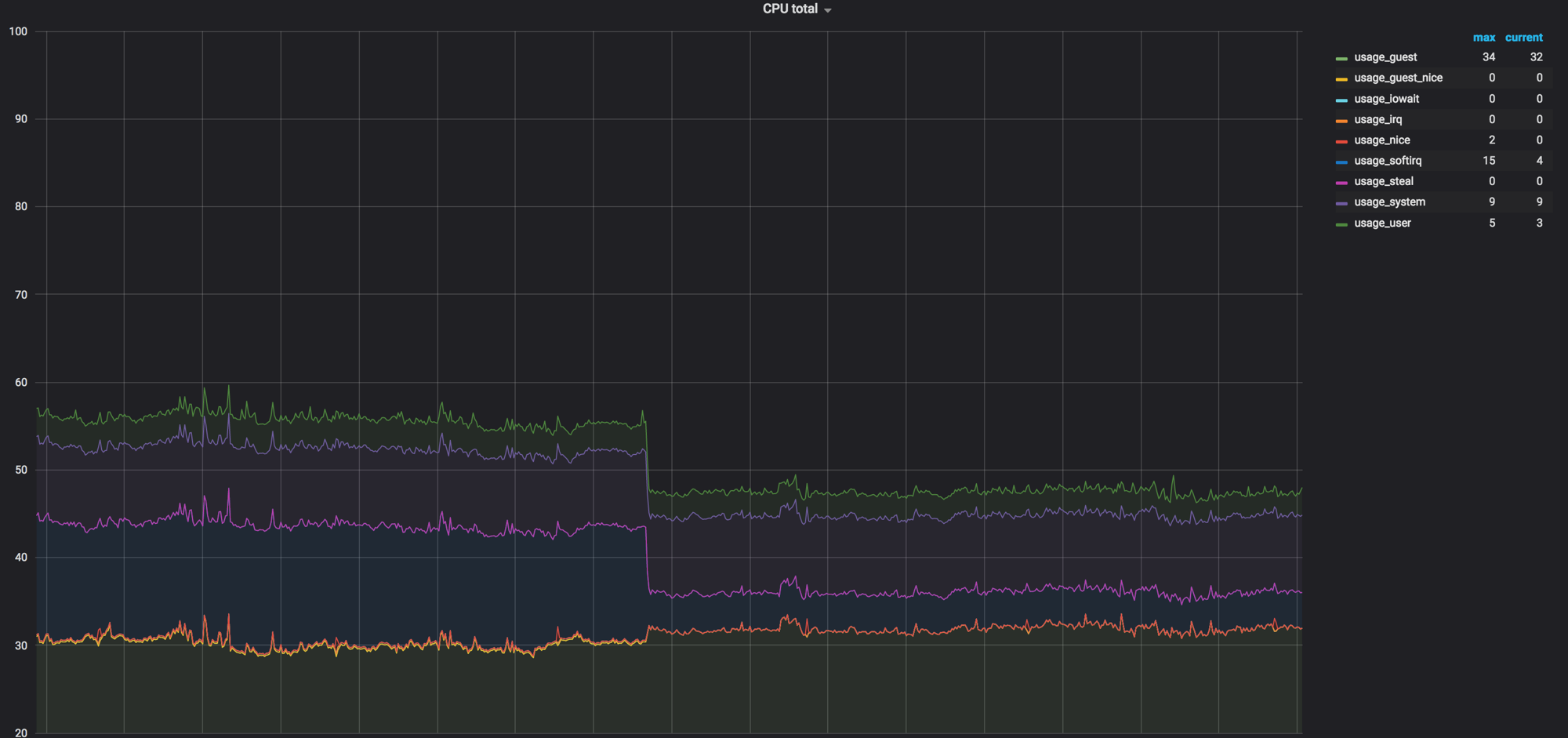
混合所有内容之前先加载计算节点的图。 大约是60%,但是负载下降的幅度很小

网络代理删除计算节点之前,softirq上的负载。 3个内核仍处于加载状态。 当时我们以为很正常
代码作为文档
有时候,代码就是文档,尤其是在OpenStack这样的大型服务中。 在六个月的发布周期中,开发人员忘记了或者根本没有时间记录一些东西,结果就像下面的示例所示。
关于超时
一旦我们看到Neutron对Open vSwitch的调用在5秒钟内就不适合并且超时了。
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
当然,我们假设设置中的某个位置是固定的。 我们查看了配置,文档和deb软件包,但起初他们什么都没找到。 结果,在搜索结果的第五页上找到了所需设置的描述-我们再次查看代码,找到了正确的位置。 设置是这样的:
ovs_vsctl_timeout = 30
我们将其设置为30秒(当时为5秒),一切开始变得更好一些。
这是另一个不明显的问题-重新启动网络组件时,某些Open vSwitch设置可能会重置。 例如,这发生在ovs-vsctl inactivity_probe中。 这也是一个超时,但是会影响ovs-vsctl本身对其数据库的调用。 我们将其添加到systemd init中,这使我们能够使用启动时所需的参数来启动所有开关。
ovs-vsctl set Controller "br-int" inactivity_probe=30000
关于网络堆栈设置
我们还必须与其他服务器使用的网络堆栈中普遍接受的设置稍有不同。
这是将ARP记录存储在表中需要多长时间的设置:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
默认值为1天。 通常,一个方案可以生存数周,但是每天可以重新创建方案4-6次,并且MAC地址和IP地址的对应关系不断变化。 为了不堆积垃圾,我们将时间设置为一分钟。
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
此外,我们在提升网络接口时强制发送ARP通知。 我们还增加了conntrack表,因为在使用NAT和浮动ip时,我们没有默认值。 增加到一百万(默认值为262144),一切都变得更好。
我们更正了Open vSwitch本身的MAC表的大小:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

完成所有设置后,40%的负载几乎变为零
rx流哈希
为了在所有队列和处理器线程之间分配对udp流量的处理,我们包括了rx-flow-hash。 在Intel网卡上,即在i40e驱动程序中,默认情况下禁用此选项。 我们的基础架构中有72个核心的虚拟机管理程序,如果只有一个繁忙,这不是最佳选择。
这样做是这样的:
ethtool -N eno50 rx-flow-hash udp4 sdfn

一个重要的结论:您可以配置所有东西。 默认配置会在某个时候适合(就像我们所做的那样),但是超时问题使得有必要进行搜索。 这是正常的。
安全规则
根据安全服务的要求,公司内的所有项目都有个人和全局规则-其中有很多。 当我们将300个虚拟机迁移到一个虚拟机监控程序时,所有这些都流入了iptables的8万条规则。 对于iptables本身而言,这不是问题,但是Neutron将这些规则从RabbitMQ加载到一个流中(因为它是用Python编写的,在那里使用多线程使一切感到可悲)。 Neutron代理冻结,由于超时而失去与RabbitMQ的连接和连锁反应,并且在恢复后,Neutron重新请求所有规则,开始同步,然后一切重新开始。
同时,用于创建看台的时间从20-40分钟增加到最多一个小时。
最初,我们只是将所有内容都包裹在检索上(在此阶段,我们已经意识到问题不能很快解决),然后我们开始使用FWaaS 。 有了它,我们取出了带有计算节点的安全规则,以将路由器本身所在的网络节点分开。

来源-docs.openstack.org
因此,在项目内部可以完全访问所需的所有内容,并且将安全规则应用于外部连接。 因此,我们减少了Neutron的负载,并返回到创建测试环境的20-30分钟。
总结
OpenStack是一件很酷的事情,您可以在其中回收铁,创建内部云并基于它创建其他内容。 除此之外,Telegram中还有一个庞大的社区和一个活跃的团体 ,他们在这里提示我们超时。
仅此而已。 提出问题,我和我的同事准备回答并分享我们的经验。