第一部分R提取并绘制
当然,PostgreSQL最初是作为通用DBMS创建的,而不是作为专用OLAP系统创建的。 但是Postgres的一大优点是它对编程语言的支持,您可以用它来做任何事情。 鉴于内置的程序语言丰富,它根本没有平等。 PL / R-R的服务器实现-分析人员喜欢的语言-其中之一。 但是稍后会更多。
R是一种具有特殊数据类型的惊人语言-例如
list ,不仅可以包含不同类型的数据,还可以包含函数(通常,该语言是折衷的,我们不会谈论它属于特定家族的内容,以免引起分散注意力的讨论)。 它具有模仿RDBMS表的漂亮的
data.frame数据类型-它是一个矩阵,其中的列包含在列级别通用的不同数据类型。 因此(出于其他原因)在R中使用数据库非常方便。
我们将在
RStudio环境中的命令行上工作,并通过
ODBC RpostgreSQL驱动程序连接到PostgreSQL。 它们易于安装。
由于R是为从事统计工作的人员创建的,是
S语言的一种变体,因此我们还将提供具有简单图形的简单统计示例。 我们没有介绍该语言的目标,但是有一个目标是展示
R和PostgreSQL的交互。
有三种方法可以处理存储在PostgreSQL中的数据。
首先,您可以通过任何方便的方法从数据库中抽取数据,例如将其打包为JSON(R可以理解),然后再用R对其进行进一步处理。这通常不是最有效的方法,当然也不是最有趣的方法,我们在这里不予考虑。
其次,您可以使用ODBC / DBI驱动程序,以R环境作为客户端从R环境与数据库进行通信-从数据库读取数据并将数据转储到数据库中,然后在R中处理数据。我们将演示如何完成此操作。
最后,您可以使用PL / R作为集成的过程语言,使用数据库服务器上已有的R工具进行处理。 在许多情况下,这是有道理的,因为在R中,例如,有一些方便的方法可以聚合
pl/pgsql中没有的数据。 我们也将展示这个。
一种常见的方法是在项目的不同阶段中使用第二和第三选项:首先将代码作为外部程序进行调试,然后将其传输到基础。
让我们开始吧。 R解释语言。 因此,您可以按照以下步骤操作,也可以将代码转储到脚本中。 一个趣味问题:本文中的示例很简短。
首先,当然,您需要连接适当的驱动程序:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
如您所见,赋值操作在R中出现。 通常,在R a <-b中,它的含义与b-> a相同,但是第一种书写方式更为常见。
我们将获取完成的数据库:
航空运输演示数据库,由
Postgres Professional 培训材料使用。在
此页面上,您可以选择数据库选项以品尝(即大小)并阅读其说明。 为了方便起见,我们复制数据方案:
假设该基础安装在服务器192.168.1.100上,称为
demo 。 连接:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
我们继续。 让我们来看看这样的请求,哪些城市航班最晚到:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
为了延迟几分钟,我们使用postgres
extract(EPOCH FROM ...)构造从
timestamp字段中提取“绝对”秒,并除以60.0(而不是60),以避免除法时剩下的余数(被理解为整数)。 由于存在超过一个小时的延迟,因此不能使用
EXTRACT MINUTE 。 我们平均延迟
avg操作员。
我们将文本传递给变量,然后将请求发送到服务器:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
现在,我们确定请求以什么形式出现。 为此,R语言具有
class()函数
class (res1)
它将显示结果包装在
data.frame类型中,也就是说,我们回想起它是基表的类似物:实际上,它是具有任意类型的列的矩阵。 顺便说一下,她知道这些列的名称,并且可以访问这些列(例如,如果有的话),例如:
print (res1$city)
现在该考虑如何可视化结果了。 为此,您可以看到我们拥有的。 例如,从此
列表中选择适当的时间表:
- R条形图(条形图)
- R-Boxplots(库存)
- R直方图
- R线图(图形)
- R-散点图(点)
应该记住的是,对于每种输入类型,都提供了适合图像的数据类型。 选择一个条形图(斜条)。 它需要两个向量作为轴向值。 R中的“向量”类型只是一组相同类型的值。
c()是向量构造函数。
您可以从
data.frame类型的结果生成必要的两个向量,如下所示:
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
右侧的表达式看起来很奇怪,但这是一种方便的技术。 而且,各种表达式可以用R紧凑地编写。 在逗号之前的方括号中,序列的索引,在逗号之后的-列的索引。 逗号一文不值的事实意味着仅从相应的列中选择所有值。
时间类是
numeric ,城市类是
character 。 这些是向量的变种。
现在,您可以自己进行可视化。 您必须指定图片文件。
png(file = "/home/igor_le/R/pics/bars_horiz.png")
之后,将执行一个繁琐的过程:设置图表的参数(
par )。 并不是说R图形包中的所有内容都是直观的。 例如,
las参数确定沿轴相对于轴本身的值的标签位置:
- 0,默认情况下平行于轴;
- 1-始终为水平;
- 2-垂直于轴;
- 3-始终直立
我们不会绘制所有参数。 通常,它们有很多:田野,天平,颜色-寻找,随意闲逛。
par(las=1) par(mai=c(1,2,1,1))
最后,我们从横卧列中构建一个图形:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
这还不是全部。 我必须说最后一件事:
dev.off()

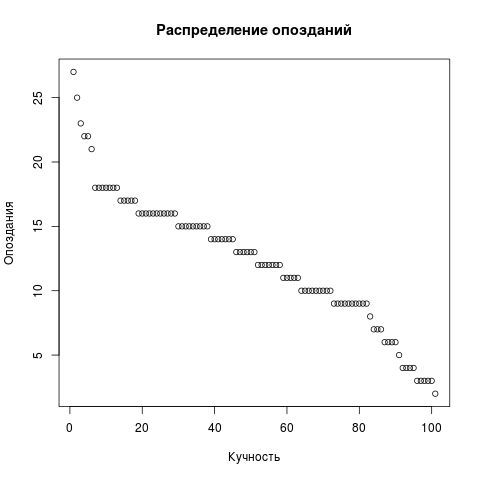
为了进行更改,我们将仍然绘制点阵图。 从请求中删除LIMIT,其余部分相同。 但是散点图需要一个向量,而不是两个。
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
为了进行可视化,我们使用了标准软件包。 显然,R是一种流行的语言,并且程序包存在于无穷大周围。 您可以询问已安装的此类文件:
library()
第二部分 R产生退休人员
R不仅可以方便地用于数据分析,还可以方便地用于其生成。 在具有丰富的统计功能的地方,不可能有用于创建随机序列的各种算法。 特别是,您可以使用典型(高斯)分布和不太典型(Zipf)分布来模拟数据库查询。
但是在下一部分中会对此有更多的介绍。