本文将重点介绍为REST API项目编写和支持有用且相关的规范,该规范将节省大量额外的代码,并从整体上提高整个项目的完整性,可靠性和透明度。
什么是RESTful API?
这是一个神话。
认真地说,如果您认为您的项目具有RESTful API,那么几乎可以肯定会弄错。 RESTful的想法是构建一个在所有方面都符合REST样式描述的体系结构规则和限制的API,但是在实际情况下,这几乎是不可能的 。
一方面,REST包含太多模糊不清的定义。 例如,HTTP方法和状态码词典中的某些术语在实践中并未按预期目的使用,而其中许多根本没有使用。
另一方面,REST创造了太多的限制。 例如,现实世界中资源的原子使用对于移动应用程序使用的API是不合理的。 完全拒绝在请求之间存储状态实质上是对许多API中使用的用户会话机制的禁止。
但是,等等,并不是所有的事情都那么糟糕!
为什么我们需要REST API规范?
尽管存在这些缺点,但采用合理的方法,REST仍然是设计真正出色的API的良好基础。 这样的API应该具有内部统一性,清晰的结构,方便的文档记录和良好的单元测试覆盖范围。 所有这些都可以通过为您的API制定质量规范来实现。
通常,REST API 规范与其文档相关联。 与第一个文档不同(后者是API的正式描述),该文档旨在供人们阅读:例如,使用API的移动或Web应用程序的开发人员。
但是,除了实际创建文档外,正确的API描述仍然可以带来很多好处。 在本文中,我想分享一些示例,说明如何有效使用规范,您可以:
- 使单元测试更简单,更可靠;
- 配置输入数据的预处理和验证;
- 自动序列化并确保响应的完整性;
- 甚至利用静态类型。
Openapi
今天,描述REST API的公认格式是OpenAPI ,也称为Swagger 。 该规范是JSON或YAML格式的单个文件,由三个部分组成:
- 标头,其中包含API的名称,说明和版本,以及其他信息;
- 对所有资源的描述,包括其标识符,HTTP方法,所有输入参数以及响应主体的代码和格式,以及指向定义的链接;
- JSON模式格式的对象的所有定义,都可以在输入参数和响应中使用。
OpenAPI有一个严重的缺点- 结构复杂,通常还有冗余 。 对于一个小型项目,规范JSON文件的内容可以迅速增长到几千行。 无法以这种形式手动维护此文件。 随着API的发展,这对维护最新规范的想法构成了严重威胁。
有许多可视化编辑器可让您描述API并形成最终的OpenAPI规范。 反过来,其他服务和云解决方案也基于它们,例如Swagger , Apiary , Stoplight , Restlet等。
但是,对我来说,由于难以快速编辑规范并将其与代码编写过程结合在一起,因此此类服务并不是很方便。 另一个缺点是对每个特定服务功能集的依赖。 例如,几乎不可能仅通过云服务来实施全面的单元测试。 尽管看起来很有可能,但是代码生成甚至为端点创建“插件”实际上都没有用。
Tinyspec
在本文中,我将使用基于本地REST API描述格式-tinyspec的示例 。 格式是小的文件,这些文件以直观的语法描述了项目中使用的端点和数据模型。 文件存储在代码旁边,可让您在编写文件时对其进行检查和编辑。 同时,tinyspec会自动编译为成熟的OpenAPI,可立即在项目中使用。 现在该告诉您确切的方法了。
在本文中,我将提供Node.js(koa,express)和Ruby on Rails中的示例,尽管这些实践适用于大多数技术,包括Python,PHP和Java。
当规范非常有用时
1.端点的单元测试
行为驱动开发(BDD)是开发REST API的理想选择。 编写单元测试的最方便方法不是针对单个类,模型和控制器,而是针对特定端点。 在每个测试中,您都模拟一个真实的HTTP请求并检查服务器响应。 在Node.js中,为了模拟测试请求,在Ruby on Rails- airborne中提供了supertest和chai-http 。
假设我们有一个User模式和一个返回所有用户的GET /users端点。 这是tinyspec语法,对此进行了描述:
- User.models.tinyspec文件:
User {name, isAdmin: b, age?: i}
- 文件users.endpoints.tinyspec :
GET /users => {users: User[]}
这是我们的测试结果:
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
当我们有描述服务器响应格式的规范时,我们可以简化测试,并仅根据该规范检查响应 。 为此,我们将利用我们的tinyspec模型被转换为OpenAPI定义这一事实,该定义又对应于JSON Schema格式。
可以测试JS中的任何文字对象 (或Ruby中的Hash ,Python中的dict ,PHP中的关联数组 ,甚至Java中的Map )是否符合JSON方案。 甚至还有用于测试框架的相应插件,例如RSpec的jest-ajv (npm), chai-ajv-json-schema (npm)和json_matchers (rubygem)。
使用方案之前,必须将它们连接到项目。 首先,我们将基于tinyspec生成openapi.json规范文件(此操作可以在每次测试运行之前自动执行):
tinyspec -j -o openapi.json
Node.js
现在,我们可以在项目中使用接收到的JSON,并从中获取definitions键,其中包含所有JSON方案。 方案可以包含交叉引用( $ref ),因此,如果我们有嵌套方案(例如Blog {posts: Post[]} ),则需要“扩展”它们以便在验证中使用它们。 为此,我们将使用json-schema-deref-sync (npm)。
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200);
Ruby on Rails
json_matchers可以处理$ref链接,但是需要以某种方式在文件系统中使用带有方案的单独文件,因此首先您必须将swagger.json “拆分”为许多小文件(有关更多信息,请swagger.json 此处 ):
之后,我们可以这样编写测试:
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
注意:用这种方式编写测试非常方便。 特别是在您的IDE支持运行测试和调试(例如WebStorm,RubyMine和Visual Studio)的情况下。 因此,您完全不能使用任何其他软件,并且该API的整个开发周期缩短为3个连续的步骤:
- 规范设计(例如在tinyspec中);
- 为添加/更改的端点编写一套完整的测试;
- 开发满足所有测试要求的代码。
2.输入验证
OpenAPI不仅描述了响应的格式,而且还描述了输入数据的格式。 这使我们可以在请求期间验证从用户权限接收的数据 。
假设我们具有以下描述更新用户数据以及所有可更改字段的规范:
之前我们看过测试中用于验证的插件,但是对于更一般的情况,有ajv (npm)和json-schema (rubygem)验证模块,让我们使用它们并编写一个带有验证的控制器。
Node.js(Koa)
这是Express的后继者Koa的一个示例,但是对于Express,代码将看起来相似。
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router();
在此示例中,如果输入数据不符合规范,则服务器将向客户端返回500 Internal Server Error响应。 为了防止这种情况的发生,我们可以拦截验证器错误并形成自己的响应,该响应将包含有关尚未通过测试的特定字段的更详细信息,并且还应符合规范 。
在FieldsValidationError文件中添加FieldsValidationError模型的描述:
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
现在,我们将其指示为端点的可能答案之一:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
这种方法将允许您编写单元测试,以使用从客户端接收到的不正确数据来验证错误形成的正确性。
3.模型的序列化
几乎所有现代服务器框架都以一种或另一种方式使用ORM 。 这意味着系统内部API中使用的大多数资源都以模型,其实例和集合的形式呈现。
生成这些实体的JSON表示形式以在API响应中传输的过程称为序列化 。 有许多用于执行序列化功能的不同框架的插件,例如: sequelize-to-json (npm), acts_as_api (rubygem), jsonapi-rails (rubygem)。 实际上,这些插件允许特定的模型指定必须包含在JSON对象中的字段列表以及其他规则,例如重命名它们或动态计算值。
当我们需要使用同一模型的几种不同的JSON表示形式,或者当一个对象包含嵌套实体(关联)时,就会出现困难。 需要继承,重用和链接序列化程序 。
不同的模块以不同的方式解决这些问题,但是让我们想想,规范可以再次为我们提供帮助吗? 实际上,事实上,有关JSON表示的要求的所有信息,所有可能的字段组合(包括嵌套实体)都已包含在其中。 因此,我们可以编写一个自动序列化器。
我提请您注意一个小模块sequelize-serialize (npm),它使您可以对Sequelize模型进行此操作。 它采用模型或数组的实例以及所需的电路,并考虑所有必需的字段并为关联实体使用嵌套电路,以迭代方式构造一个序列化对象。
因此,假设我们需要从API中返回所有拥有博客帖子的用户,包括对这些帖子的评论。 我们使用以下规范对此进行描述:
现在,我们可以使用Sequelize构建查询并返回与上述规范完全匹配的序列化对象:
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
几乎是魔术,对不对?
4.静态打字
如果您太酷了,以至于正在使用TypeScript或Flow,您可能已经想知道, “亲爱的静态类型呢?!” 。 使用sw2dts或swagger-to-flowtype模块,您可以基于JSON方案生成所有必要的定义,并将它们用于测试,输入数据和序列化程序的静态类型。
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
现在我们可以在控制器中使用类型:
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
在测试中:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
请注意,生成的类型定义不仅可以在API项目本身中使用,而且可以在客户端应用程序项目中使用,以描述API工作的功能类型。 Angular客户开发人员将对此礼物特别满意。
5.查询字符串的类型转换
如果由于某种原因您的API接受MIME类型为application/x-www-form-urlencoded而不是application/json的请求,则请求正文将如下所示:
param1=value¶m2=777¶m3=false
这同样适用于查询参数(例如,在GET请求中)。 在这种情况下,Web服务器将无法自动识别类型-所有数据都将以字符串形式( 这是 qpm npm模块存储库中的讨论 ),因此在解析之后,您将获得以下对象:
{ param1: 'value', param2: '777', param3: 'false' }
在这种情况下,将不会根据方案验证请求,这意味着有必要手动验证每个参数的格式正确,并将其转换为所需的类型。
您可能会猜到,这可以使用我们规范中所有相同的方案来完成。 想象一下,我们有这样一个端点和方案:
这是对此类端点的请求示例
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
让我们编写一个castQuery函数,它将所有参数castQuery为我们所需的类型。 它看起来像这样:
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
它的更完整的实现支持嵌套模式,数组和null类型,可在模式转换 (npm)中使用。 现在我们可以在代码中使用它:
router.get('/posts', async (ctx) => {
注意端点代码的四行,以及规范中的三种使用方案。
最佳实务
用于创建和修改的单独方案
通常,描述服务器响应的方案与描述用于创建和修改模型的输入的方案不同。 例如,应严格限制POST和PATCH请求的可用字段列表,而在PATCH请求中,通常将方案的所有字段都设为可选。 确定答案的方案可能更免费。
tinyspec CRUDL端点的自动生成使用“ New和“ Update后缀。 User*可以定义如下:
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
尽量不要对不同类型的操作使用相同的方案,以避免由于重用或继承旧方案而导致意外的安全问题。
模式名称中的语义
同一模型的内容可能在不同的端点中有所不同。 在架构名称中使用With*和For*后缀以显示它们之间的区别以及它们的用途。 在tinyspec模型中,模型也可以彼此继承。 例如:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
后缀可以更改并组合。 最主要的是,它们的名称反映了本质,并简化了对文档的熟悉。
按客户端类型分隔端点
通常,根据客户端的类型或访问端点的用户角色,相同的端点会返回不同的数据。 例如,对于您的移动应用程序的用户和后台管理人员, GET /users和GET /messages的端点可能会非常不同。 同时,更改端点本身的名称可能会非常复杂。
要多次描述同一端点,可以在路径后的方括号中添加其类型。 此外,使用标签很有用:这将有助于将端点的文档分为几组,每组将针对API的特定客户端组而设计。 例如:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
REST API文档
一旦有了tinyspec或OpenAPI格式的规范,就可以使用HTML生成漂亮的文档,并将其发布给使用API的开发人员。
除了前面提到的云服务之外,还有一些CLI工具可将OpenAPI 2.0转换为HTML和PDF,之后您可以将其下载到任何静态主机。 范例:
您知道更多示例吗? 在评论中分享它们。
不幸的是,一年前发布的OpenAPI 3.0仍然得不到很好的支持,我找不到基于它的有价值的文档示例:无论是在云解决方案中,还是在CLI工具中。 由于相同的原因,tinyspec中尚不支持OpenAPI 3.0。
发布到GitHub
发布文档最简单的方法之一是GitHub Pages 。 只需在存储库设置中为/docs目录启用静态页面支持,并将HTML文档存储在此文件夹中。
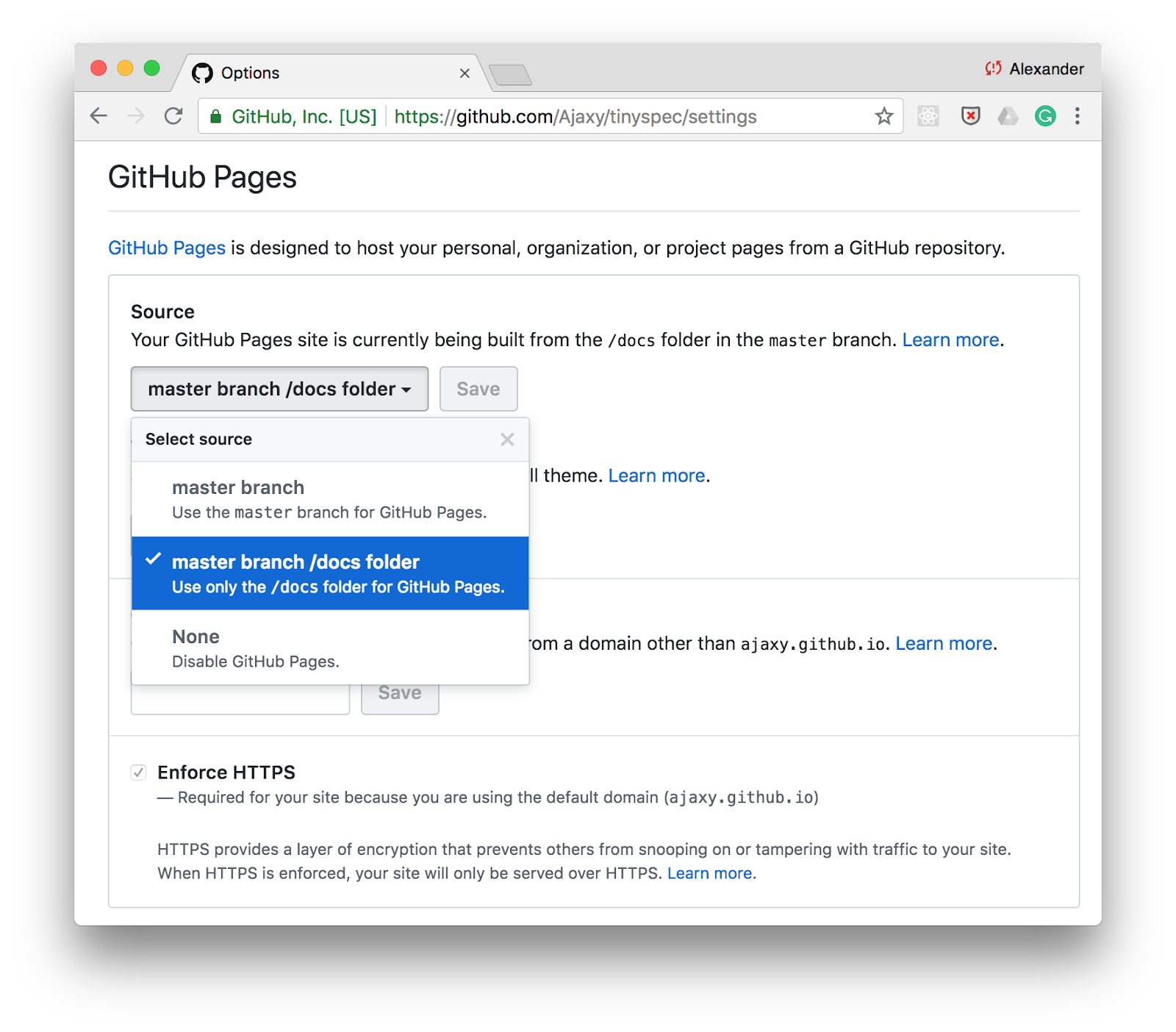
您可以在package.json scripts中添加命令通过tinyspec或另一个CLI工具生成文档,并在每次提交时更新文档:
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
持续整合
您可以在CI周期中包含文档生成并将其发布,例如,根据环境或API版本在不同地址下的Amazon S3中发布,例如: /docs/2.0 /docs/stable /docs/2.0 , /docs/staging 。
Tinyspec云
如果您喜欢tinyspec语法,则可以在tinyspec.cloud上注册为早期采用者。 我们将在其基础上构建云服务和CLI,以自动发布具有多种模板的文档,并具有开发自己的模板的能力。
结论
开发REST API可能是在现代Web和移动服务上工作的过程中最有趣的活动。 没有浏览器,操作系统和屏幕尺寸的动物园,一切都在我们的控制之下-“唾手可得”。
同时提供各种自动化形式来保持当前的规格和奖金,使此过程变得更加令人愉悦。 这样的API变得结构化,透明和可靠。
确实,实际上,即使我们从事神话的创造,但为什么我们不使它变得美丽呢?