在工作中经常遇到冗长而单调的任务,为此需要许多人的解决。 例如,解密数百个音频记录,标记数千个图像或过滤掉注释,注释的数量在不断增长。 为此,您可以保留数十名全职员工。 但是,所有这些都需要找到,选择,激励,控制,确保发展和职业发展。 而且,如果工作量减少,则必须重新培训或解雇他们。
在许多情况下,尤其是如果不需要特殊培训时,可以由Yandex众包平台
Toloka的执行者来进行此类工作。 这个系统很容易扩展:如果一个客户的任务较少,toloker将转到另一个客户,如果任务数量增加,他们只会很高兴。
下图是Toloka如何帮助Yandex和其他公司开发产品的示例。 所有标题都是可单击的-链接指向报告。

MIPT作为DeepHack.Chat hackathon的一部分,使用Toloka评估了聊天机器人的质量。 它涉及6个团队。 任务是开发一个聊天机器人,该聊天机器人可以根据给它的个人资料并简要描述个人特征来谈论自己。

独行者和漫游者收到了个人资料,不得不假装自己是在对话中给出描述的人,讲述自己,并更多地了解对话者。 对话参与者看不到对方的个人资料。
只有通过英语能力测试的用户才被允许执行该任务,因为黑客马拉松中的所有聊天机器人都说英语。 不可能直接通过Toloka来与机器人进行对话,因此在任务中将链接指向启动聊天机器人的Telegram频道。
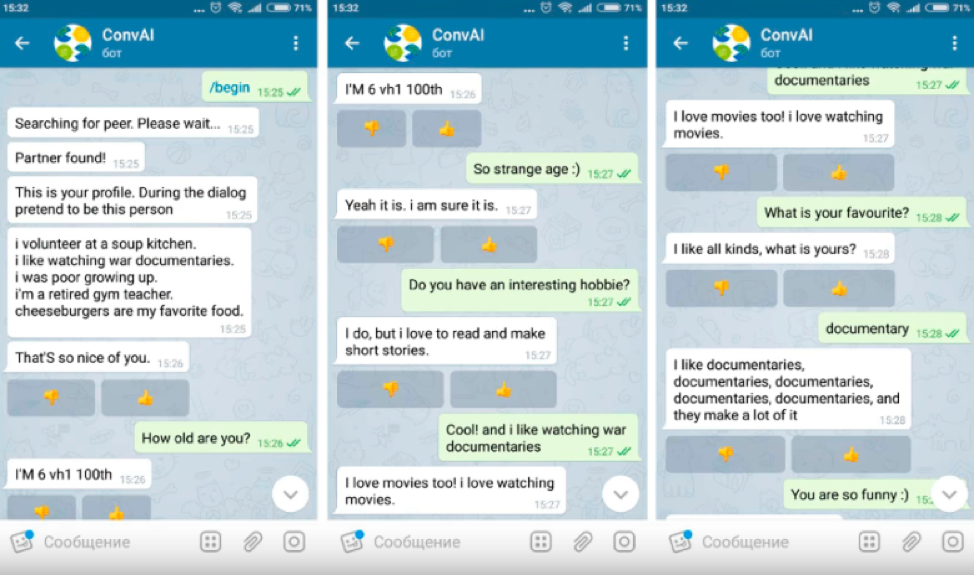
与机器人对话后,用户会收到一个对话ID,该对话ID与对话的评估一起作为回答插入到Toloka中。
为了排除不诚实的骗子,有必要检查用户与漫游器的对话情况。 为此,我们创建了一个单独的任务,表演者可以在该框架中阅读对话框并评估用户的行为,即上一个任务的射击者。
在黑客马拉松期间,团队上传了他们的聊天机器人。 白天,托船员对它们进行了测试,对质量进行了计数,并将分数报告给团队,然后开发人员编辑了他们系统的行为。
在四天内,黑客马拉松系统有了显着改善。 在第一天,漫游器有不适当且重复的答案;在第四天,答案变得更加充分和详细。 机器人不仅学会了回答问题,还学会了问自己的问题。
黑客马拉松比赛第一天的对话示例:

第四天:

统计数据:评估持续了4天,大约200名渔民参与其中,进行了1800次对话。 他们在第一个任务上花费了180美元,在第二个任务上花费了15美元。 事实证明,有效对话的百分比高于与志愿者合作时的百分比。
无人机创建者的一项重要任务是教他从他从传感器接收的数据中提取有关周围物体的信息。 在旅途中,汽车会记录其周围的一切。 将此数据倒入完成主要分析的云中,然后进行包含标记的后处理。 标记的数据发送到机器学习算法,结果返回到机器,然后重复该循环,从而提高了对象识别的质量。
城市中有很多各种各样的物品,所有这些物品都需要标记出来。 这项任务需要一定的技能,并且要花费大量时间,并且训练神经网络需要成千上万张图片。 可以从开放的数据集中获取它们,但它们是在国外收集的,因此图像与俄罗斯现实不符。 您可以低至4美元的价格购买带标签的图像,但在Tolok中,标记的价格便宜约10倍。
由于在Tolok中您可以嵌入任何接口并通过API传输数据,因此开发人员已经插入了自己的可视化编辑器,该编辑器具有层,透明度,选择,放大,划分类。 这几次提高了标记的速度和质量。
此外,API还允许您自动将任务拆分为更简单的任务,并从碎片中收集结果。 例如,在标记图片之前,您可以标记图片上的对象。 这将使您了解在哪些类别上标记图像。
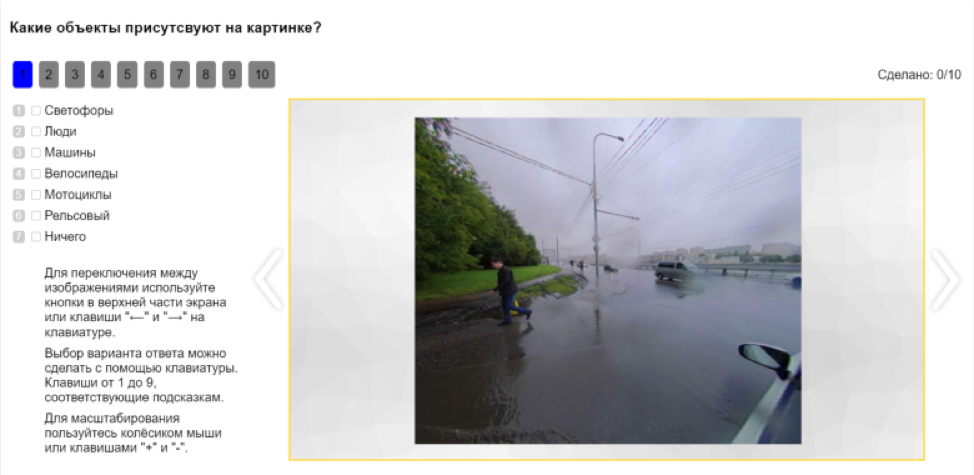
之后,可以对图像中的对象进行分类。 例如,为拍摄者提供一些有人的图片选择,并请他们澄清是行人,骑自行车的人,摩托车的人还是其他人。

托勒完成标记后,需要对其进行检查。 为此,将创建提供给其他执行者的测试任务。

不仅语言使用者,而且神经网络都参与标记。 他们中的一些人已经学会了应付这项任务,这一点并不比人们差。 但是他们的工作质量也需要评估。 因此,在任务中,除了带有标记的图片之外,还带有神经网络标记。
因此,Toloka直接集成到神经网络的学习过程中,并成为所有机器学习管道的一部分。
Ozon使用Toloka创建参考样本。 这有几个目的。
•对新搜索引擎的质量评估。
•确定最有效的排名模型。
•使用机器学习提高搜索算法的质量。
第一个测试样本是手动制作的-我们接受了100个请求并自己标记了它们。 即使是这么小的样本,也有助于发现搜索问题并确定评估标准。 该公司希望创建自己的工具来评估搜索质量,聘请评估人员并对其进行培训,但这会花费太多时间,因此我们决定选择现成的众包平台。
在为上班族准备任务时,最困难的阶段是培训-甚至公司的员工也无法完成第一个测试任务。 收到了团队的反馈意见之后,我们开发了一种新的测试方法:我们将培训人员从简单到复杂和已编译的任务都进行了培训,并考虑了执行者对公司的重要素质。
为了消除错误,Ozon进行了测试。 该任务包括三个部分:训练,控制(正确答案的阈值为60%)和主要任务(正确答案的阈值为80%)。 为了提高样本的质量,向五名表演者提供了一项任务。
测试运行统计:40分钟内完成350个任务。 预算是$ 12。 第一阶段有147位表演者参加,其中77位经过了训练,12位获得了技能并完成了主要任务。
主要发行的场景变得更加复杂:不仅有新的代币发行人,而且还有在测试阶段获得必要技能的人也参与其中。 第一个遵循标准链,第二个立即接受主要任务。 在主发布中,添加了其他技能-主样本中正确答案的百分比和多数意见。 任务仍然提供给五位表演者。
主要发布统计数据:一个月内有40,000个工作岗位。 预算总额为1150美元。 有1117位货主参加了该项目,其中18位获得了技能,6位进入了最大的主池并进行了评估。
现在,Ozon的Tolok工作是这样的:
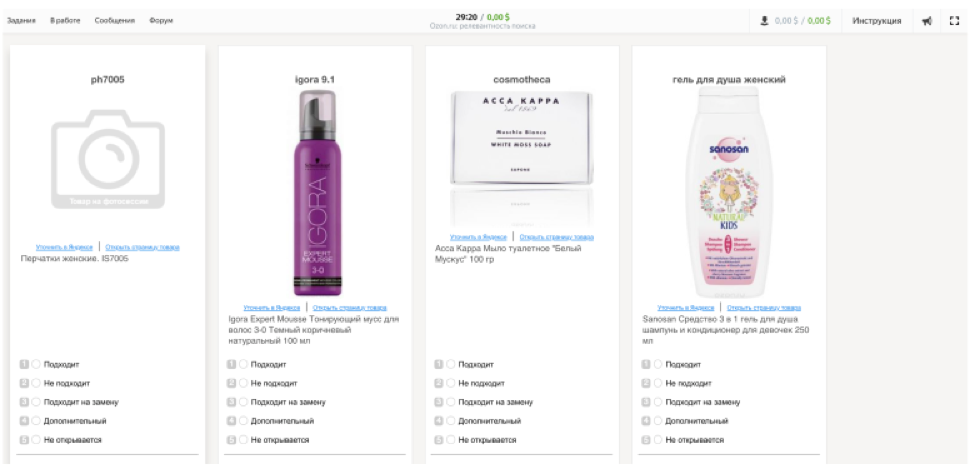
承包商会看到搜索查询和搜索结果中的9个产品。 他的任务是选择评级之一-“适合”,“不适合”,“适合替换”,“其他”,“不公开”。 最终评级有助于确定站点上的技术问题。 为了尽可能准确地模拟用户的行为,开发人员通过iframe重新创建了在线商店的界面。
在Toloka上启动任务的同时,使用规则执行了搜索查询的标记。 重点在于流行查询,以便主要改善其发布。
通过规则进行标记,可以快速地通过少量查询获取数据,并在热门查询中显示出良好的结果。 但是也有弊端:规则无法估计模棱两可的请求,存在许多有争议的情况。 另外,从长远来看,这种方法非常昂贵。
在人们的帮助下进行标记可以解决这些缺点。 在Tolok中,您可以收集大量表演者的意见,评估的等级更高,这使您可以更深入地进行引渡工作。 初始设置后,平台将稳定运行并处理大量数据。
体力劳动和人工智能机制并不相互反对。 人工智能发展得越多,其培训就需要更多的体力劳动。 另一方面,训练有素的神经网络越多,可以使更多的例行任务自动化,从而从中拯救一个人。
几乎所有任务,甚至是繁琐的任务,都可以分为许多小任务,并基于众包构建。
Tolok解决的大多数任务是朝着对人员收集的数据进行训练模型和流程自动化的第一步。
在有关该主题的下一个出版物中,我们将讨论如何使用众包来培训Yande.Buses中的Alice,适度的评论并执行规则。