机器学习使您可以为用户提供更加便捷的服务。 开始实施建议并不是那么困难,即使没有完善的基础架构,也可以获得最初的结果,主要是开始。 并且只有这样才能建立一个大规模的系统。 这就是从Booking.com开始的一切。 Viktor Bilyk告诉HighLoad ++ Siberia,它的结果是什么,现在正在使用什么方法,如何将模型引入生产,要监视哪些模型。 报告中没有遗漏任何可能的错误和问题,它将帮助某人克服困难,并提出新的想法。
 关于演讲者:
关于演讲者: Victor Bilyk在Booking.com上将机器学习产品引入商业运营。
首先,让我们看看Booking.com在哪些产品中使用机器学习。
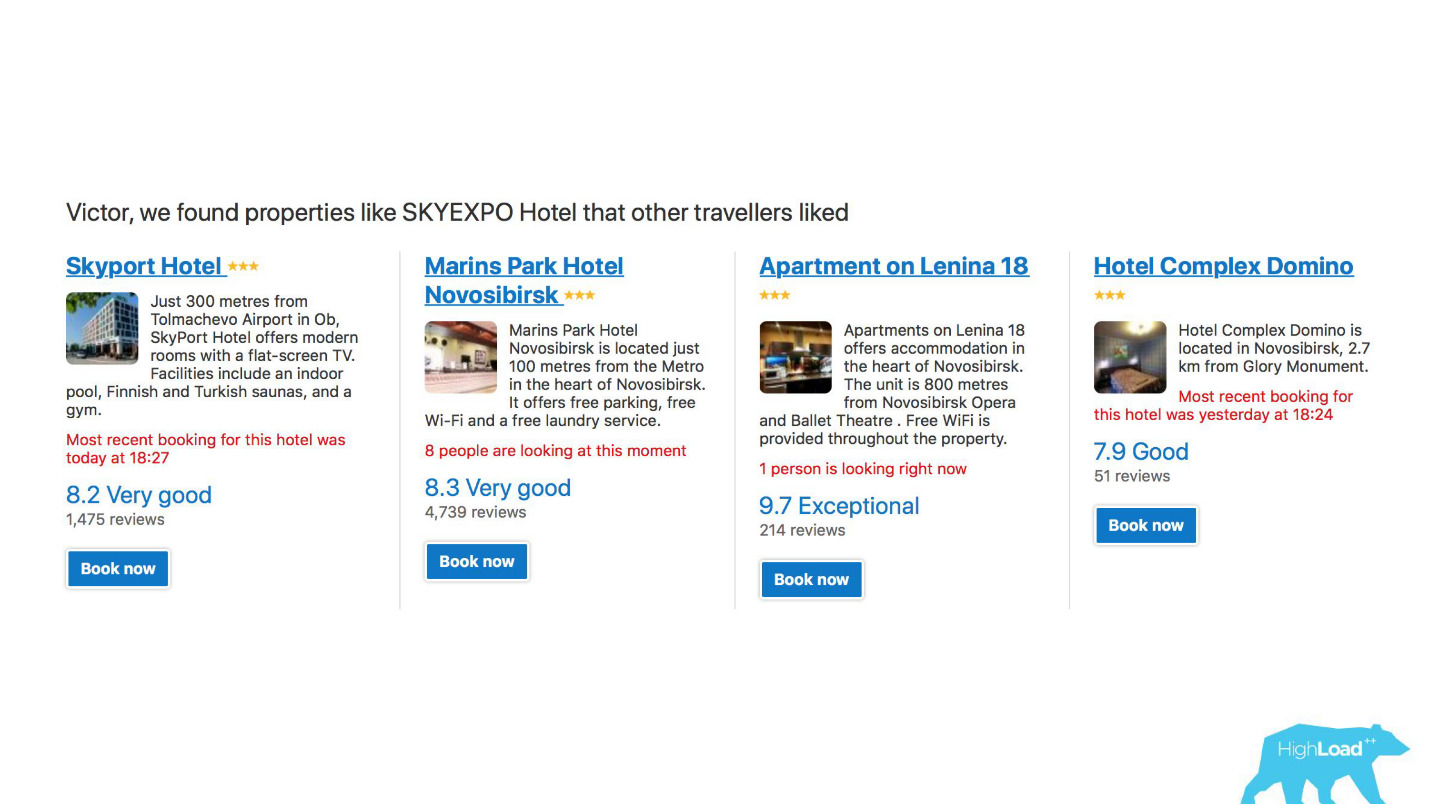
首先,这是针对酒店,目的地,日期以及在销售渠道中不同点和不同上下文的大量推荐系统。 例如,当您根本没有在搜索行中输入任何内容时,我们试图猜测您的去向。

这是我帐户中的屏幕截图,今年我肯定会访问其中两个区域。
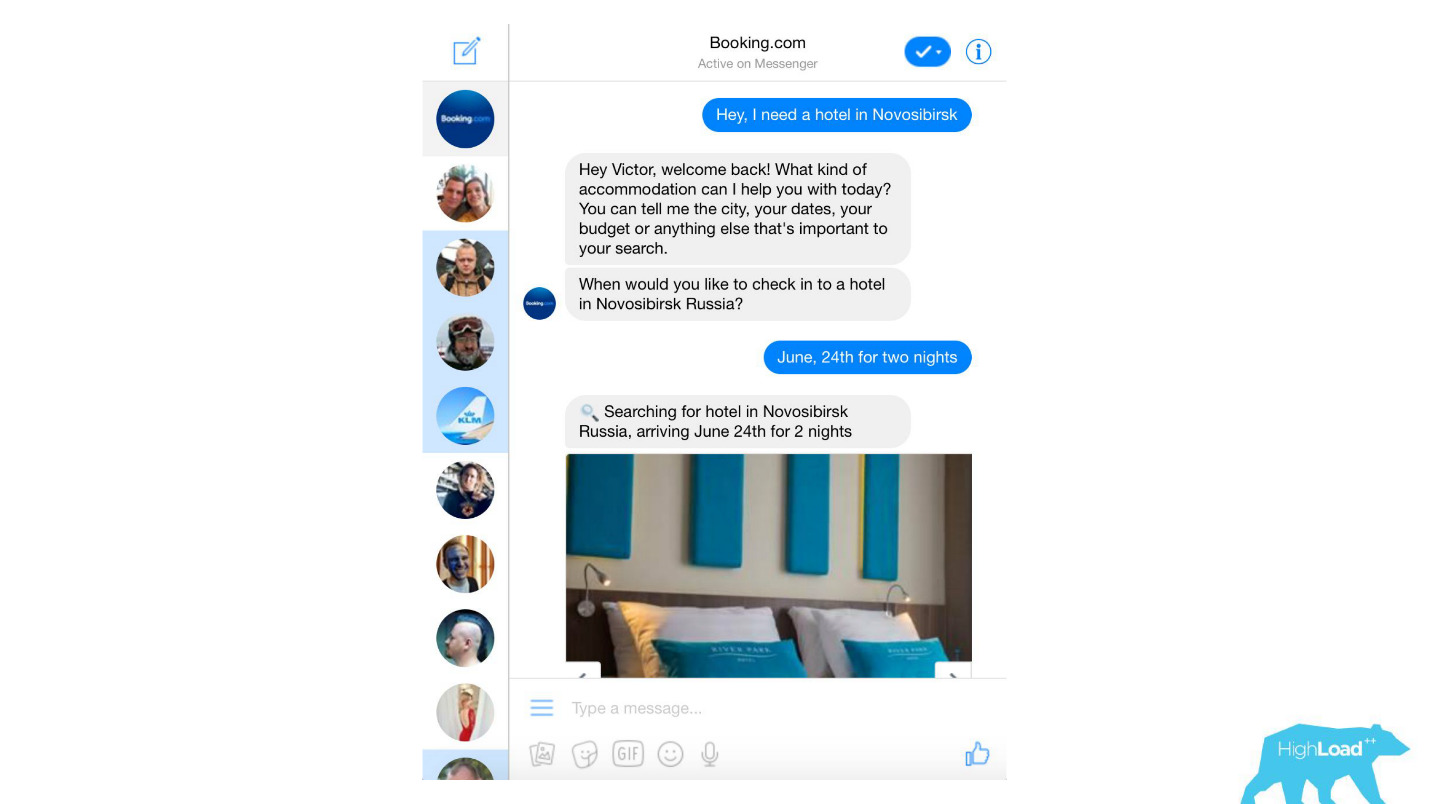
我们处理来自客户的几乎所有文本消息,从垃圾邮件过滤器到复杂的产品(例如Assistant和ChatToBook),这些产品使用模型来确定意图并识别实体。 此外,有些模型不是很引人注目,例如欺诈检测。
我们分析评论。 模型告诉我们为什么人们去柏林。
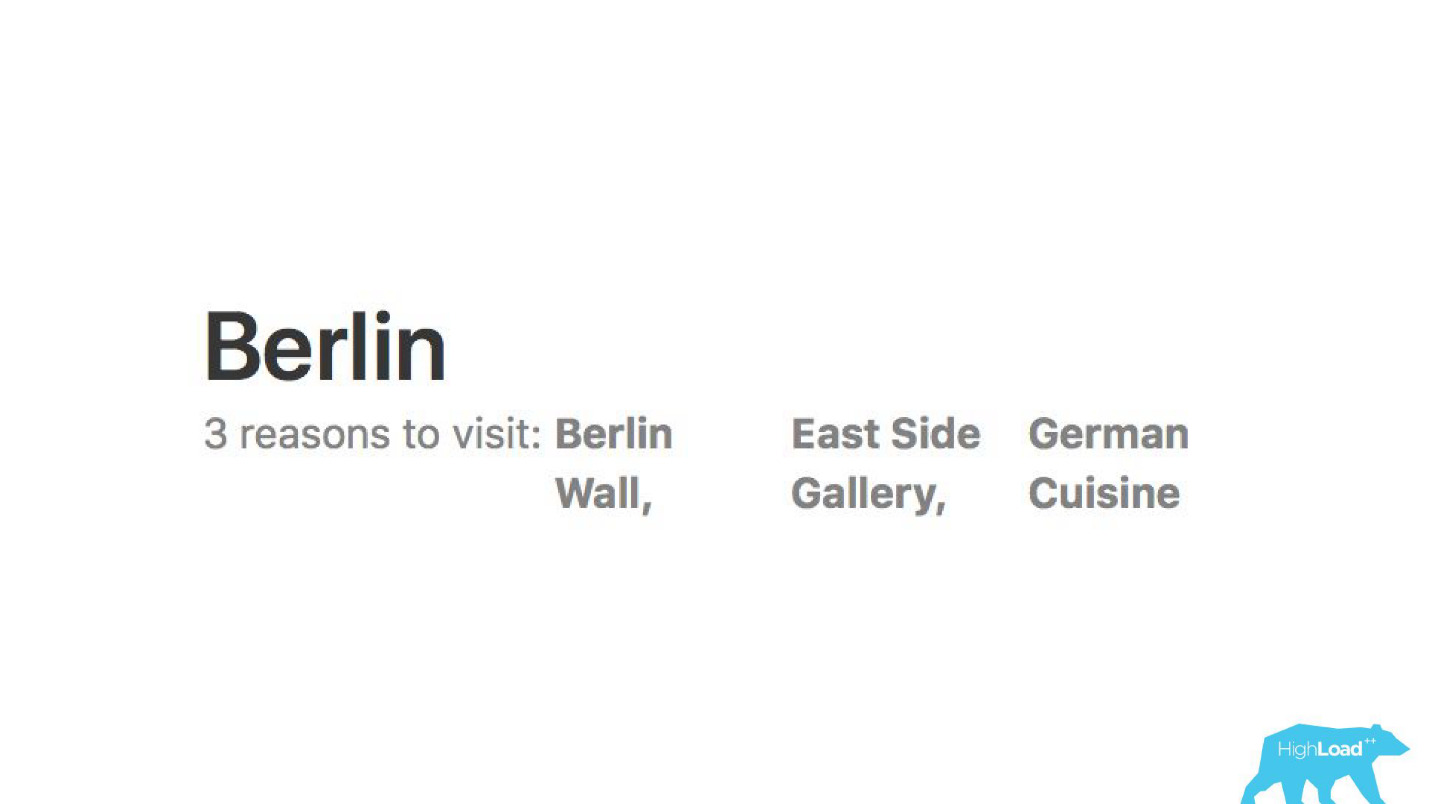
借助机器学习模型,分析了为什么酒店受到赞誉,从而使您不必自己阅读数千条评论。
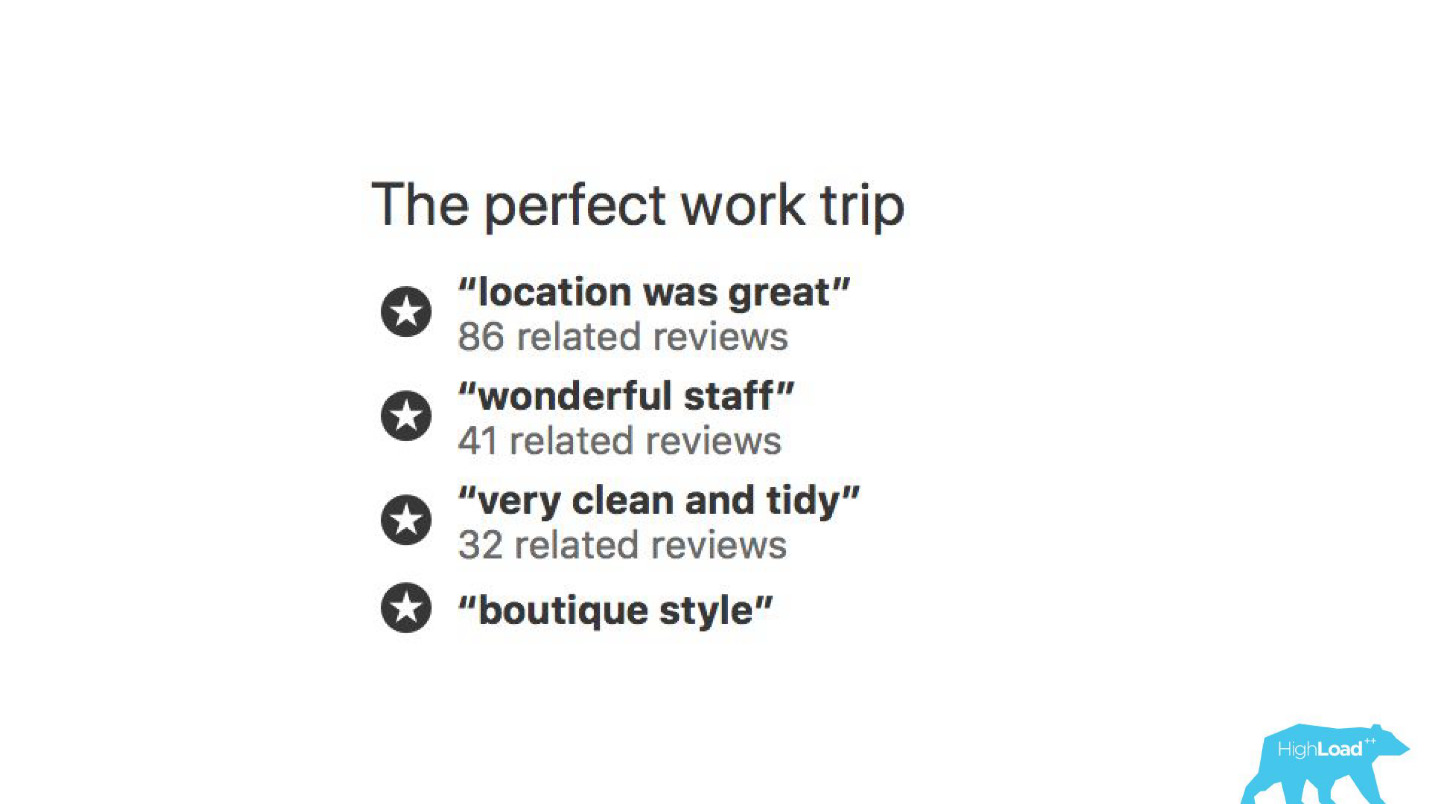
在我们界面的某些地方,几乎每个部分都与某些模型的预测有关。 例如,在这里我们试图预测酒店何时售罄。
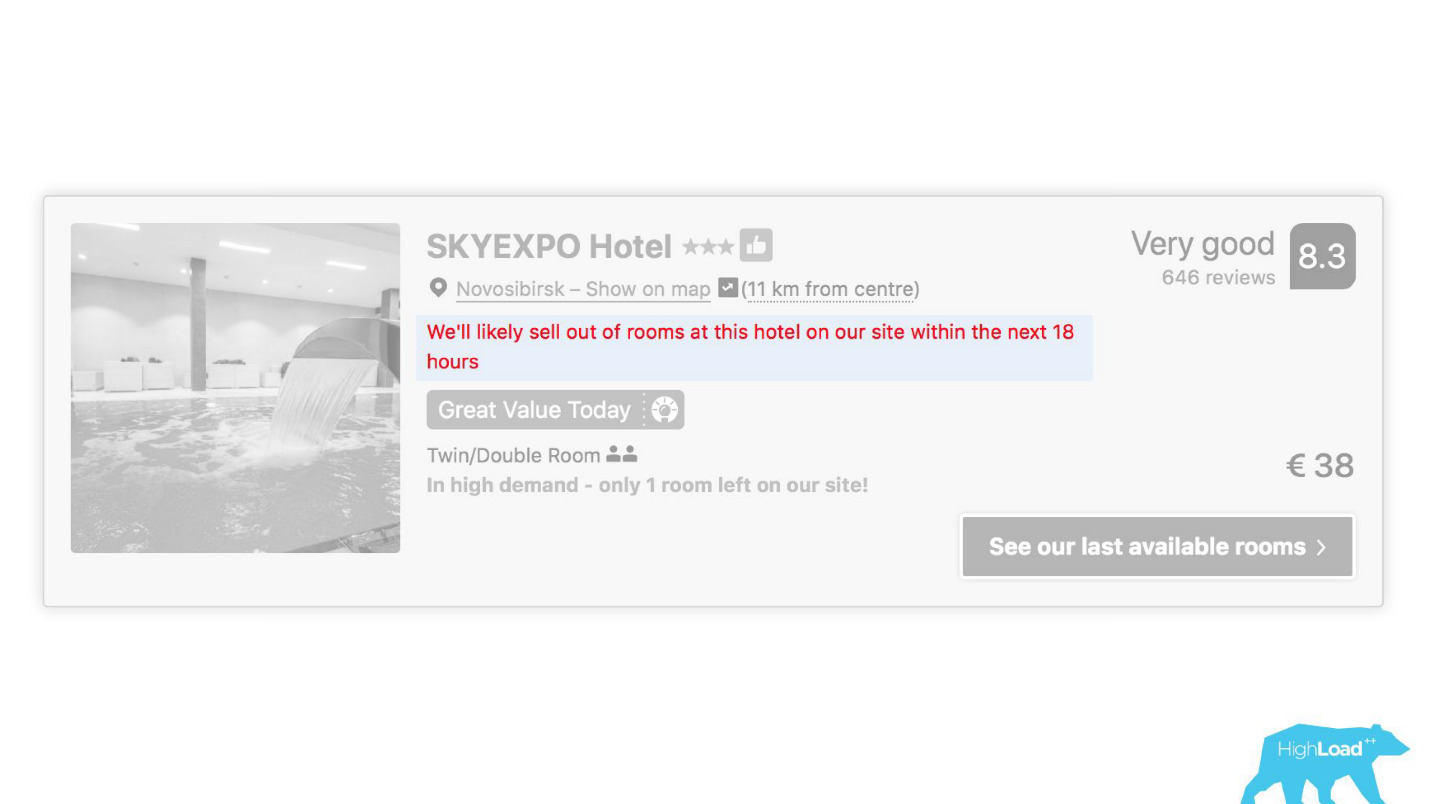
我们经常会发现自己没错-19小时后,最后一间客房已经被预订。
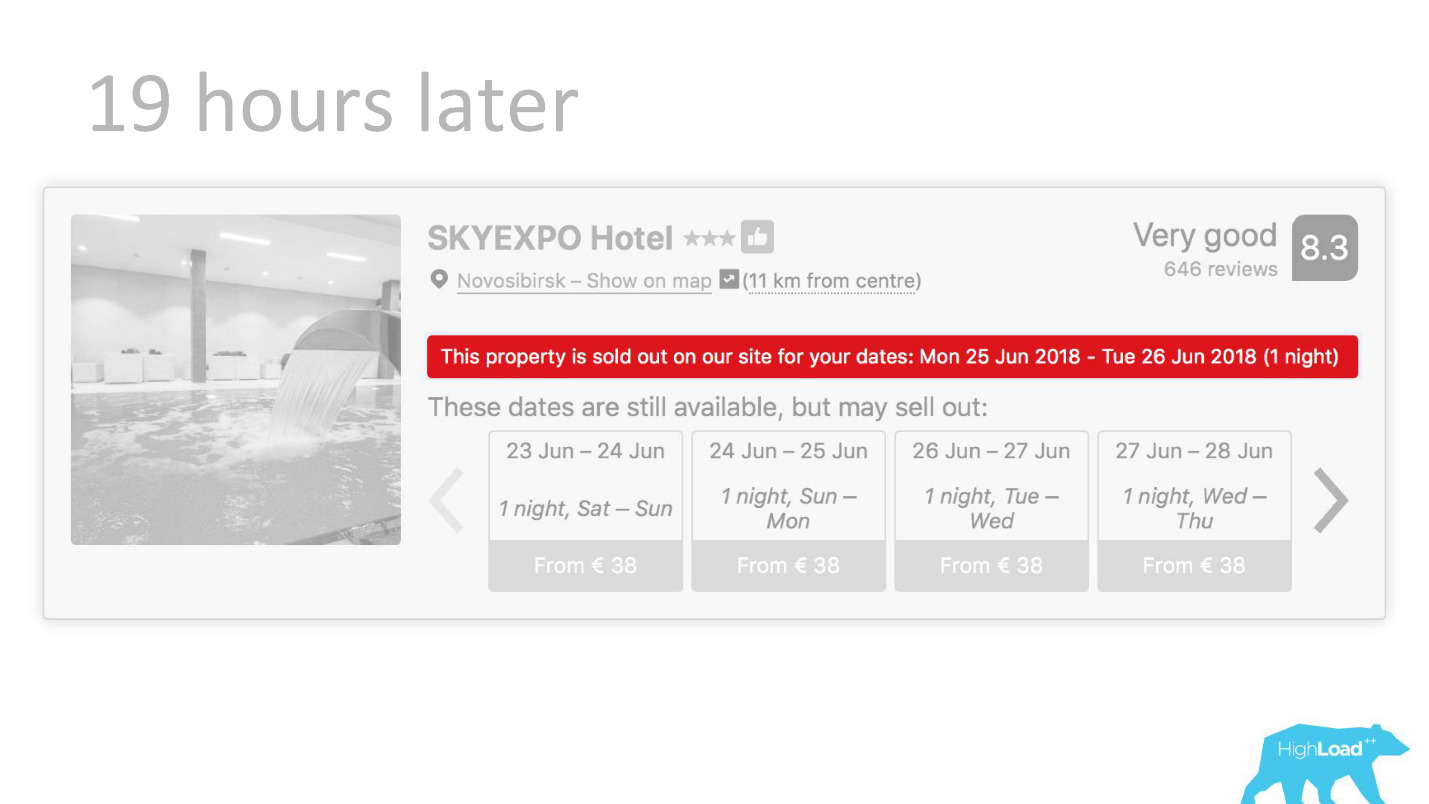
或者,例如-徽章“优惠”。 在这里,我们试图将主观化:什么是如此有利的提议。 如何理解酒店为这些日期设定的价格是好的? 毕竟,除了价格以外,这还取决于许多因素,例如附加服务,甚至还取决于外部原因,例如,如果现在在这座城市举行世界杯或大型技术会议。
开始实施
让我们倒退几年前的2015年。 我谈论的某些产品已经存在。 而且,我今天要谈论的系统还没有。 当时实施是如何进行的? 坦率地说,事情并非如此。 事实是我们遇到了一个巨大的问题,其中一部分是技术问题,一部分是组织问题。
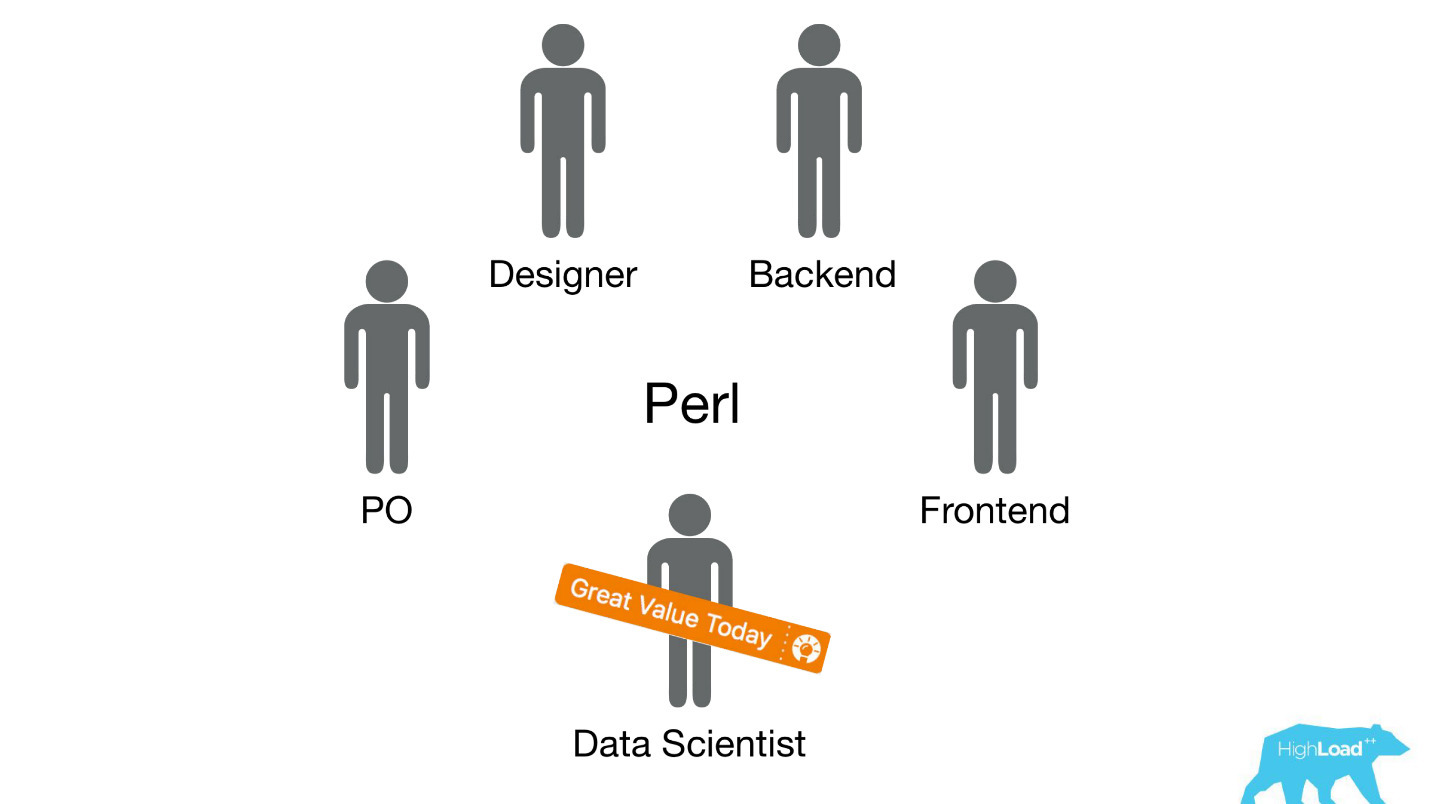
我们已将数据科学家派往现有的跨职能团队,以处理特定用户问题,并期望他们以某种方式改进产品。
通常,这些产品都是在Perl堆栈上构建的。 Perl有一个明显的问题-它不是为密集计算而设计的,我们的后端已经装有其他东西。 此外,团队内部不能优先考虑开发能够解决此问题的严肃系统,因为团队的重点是解决用户问题,而不是使用机器学习解决用户问题。 因此,产品负责人(PO)对此非常反对。
让我们看看它是如何发生的。
只有两种选择-我肯定知道这一点,因为当时我只是在这样一个团队中工作,并帮助数据科学家将他们的第一个模型投入战斗。
第一种选择是
实现预测 。 假设有一个只有两个功能的非常简单的模型:
- 访客所在的国家/地区;
- 他正在寻找酒店的城市。
我们需要预测某些事件的可能性。 我们只是炸毁所有输入向量:例如,100,000个城市,200个国家-MySQL中的总数为2000万行。 这听起来像是一个功能齐全的选项,可以将一些小型排名系统或其他简单模型输出到生产中。

另一种选择是
将预测直接嵌入到后端代码中 。 有很大的限制-数百甚至数千个系数-这就是我们所能承受的。

显然,任何一种方式都不会让您在生产中带出至少某种复杂的模型。 这限制了数据中心及其通过改进产品可以实现的成功。 显然,这个问题必须以某种方式解决。
预测服务
我们所做的第一件事是预测服务。 Habré和HighLoad ++上展示的最简单的架构可能更低。
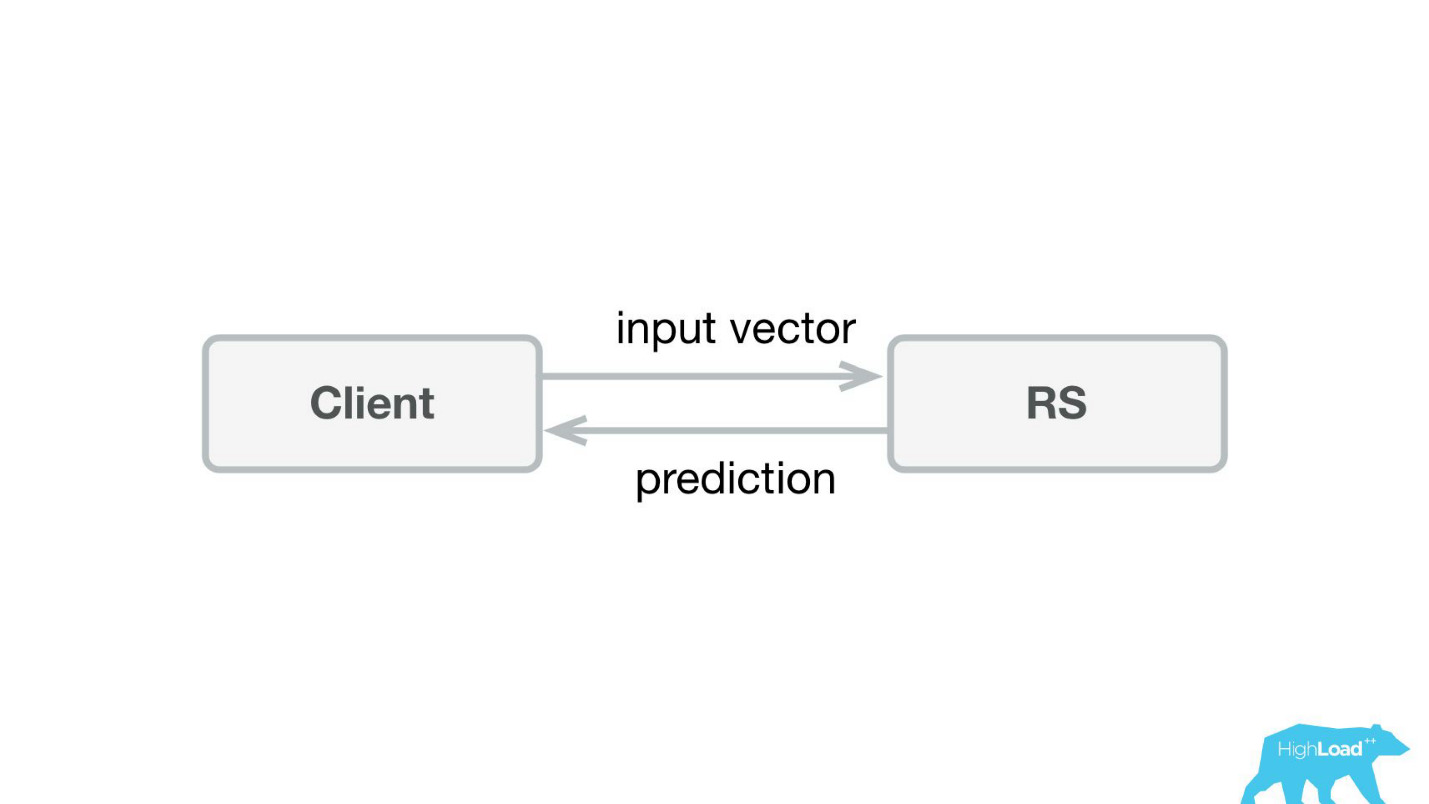
我们在Scala + Akka + Spray中编写了一个小应用程序,该应用程序仅接收传入的矢量并返回了预测。 实际上,我有点儿狡猾-系统有点复杂,因为我们需要以某种方式进行监视和推出。 实际上,一切都看起来像这样:
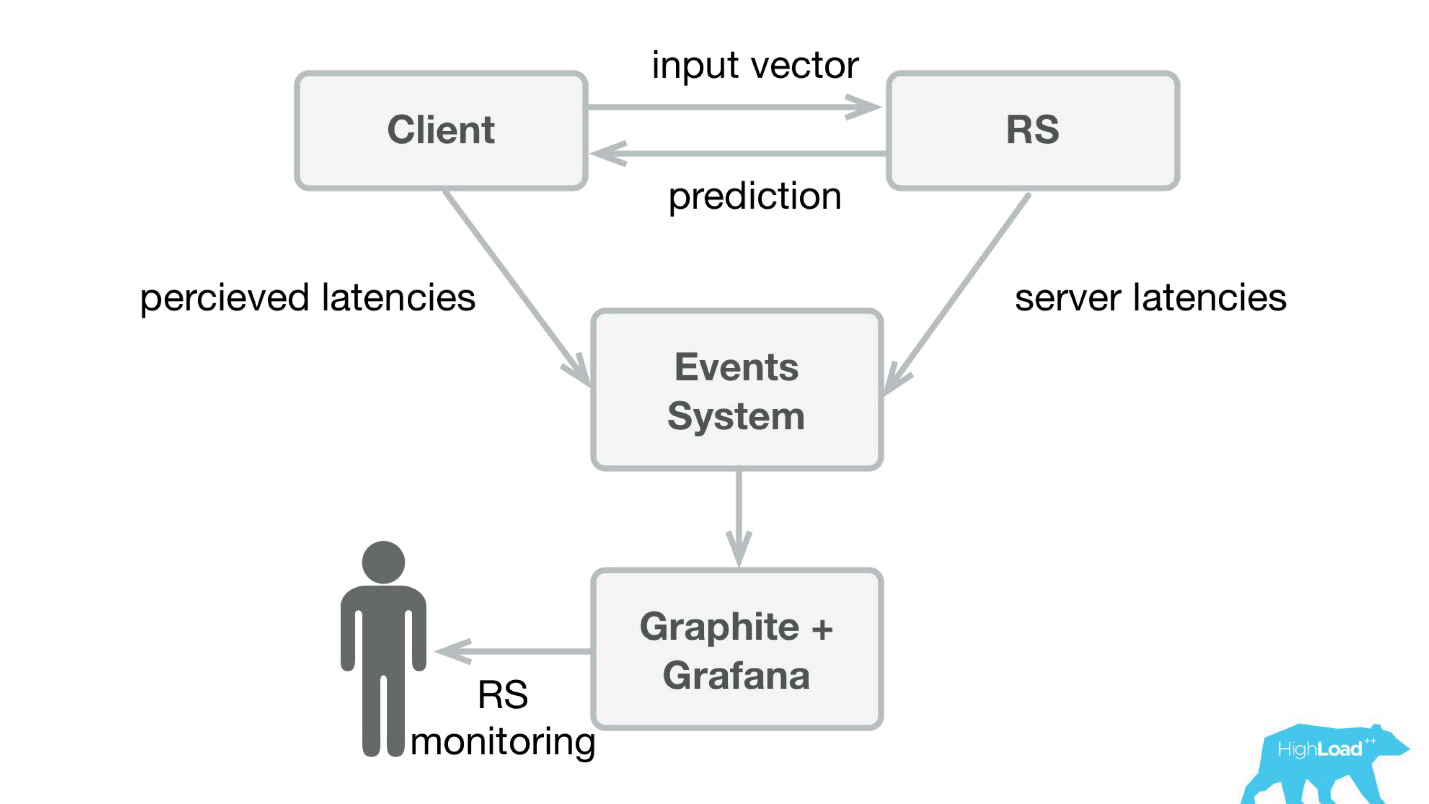
Booking.com有一个事件系统-类似于所有系统的杂志。 在此处编写非常容易,并且此流的重定向非常简单。 首先,我们需要将感知到的延迟和来自服务器端的详细信息发送给Graphite和Grafana的客户端遥测。

我们为Perl创建了简单的客户端库-将整个RPC隐藏在本地调用中,在其中放置了多个模型,然后该服务开始兴起。 出售这样的产品非常简单,因为我们有机会
介绍更复杂的模型并且花费更少的时间 。
数据科学家开始以更少的限制进行工作,在某些情况下,后台的工作减少为单行。
产品预测
但是,让我们简要地回顾一下我们如何在产品中使用这些预测。
有一个模型可以根据已知事实进行预测。 基于此预测,我们将以某种方式更改用户界面。 当然,这不是我们公司使用机器学习的唯一方案,而是相当普遍的。
启动此类功能有什么问题? 事实是,这是一瓶中的两件事:模型和用户界面的更改。 很难将两者的效果分开。
想象一下,作为AB实验的一部分,推出“ Favorable Offer”徽章。 如果不成功-目标指标没有统计上的显着变化-不知道问题是什么:难以理解,小巧,不起眼的徽章或模型不好。
此外,模型可能会降级,并且可能有很多原因。 昨天起作用的东西不一定今天就起作用。 此外,我们一直处于冷启动模式,不断连接新城市和酒店,新城市的人们来找我们。 我们需要以某种方式理解该模型在这些传入空间中仍然可以很好地推广。

关于模型降级的最可能是最近已知的案例是Alex的故事。 由于再培训,她很可能开始理解随机的声音,以求发笑,并在晚上开始轻笑,吓到了主人。
预测监控
为了监控预测,我们对系统进行了一些修改(下图)。 同样,从事件系统中,我们将流重定向到Hadoop并开始保存,除了之前保存的所有内容外,还保存了系统所有的输入向量和所有预测。 然后,使用Oozie,我们将它们汇总到MySQL中,然后从那里向那些对模型的定性特征感兴趣的人展示了一个小型Web应用程序。
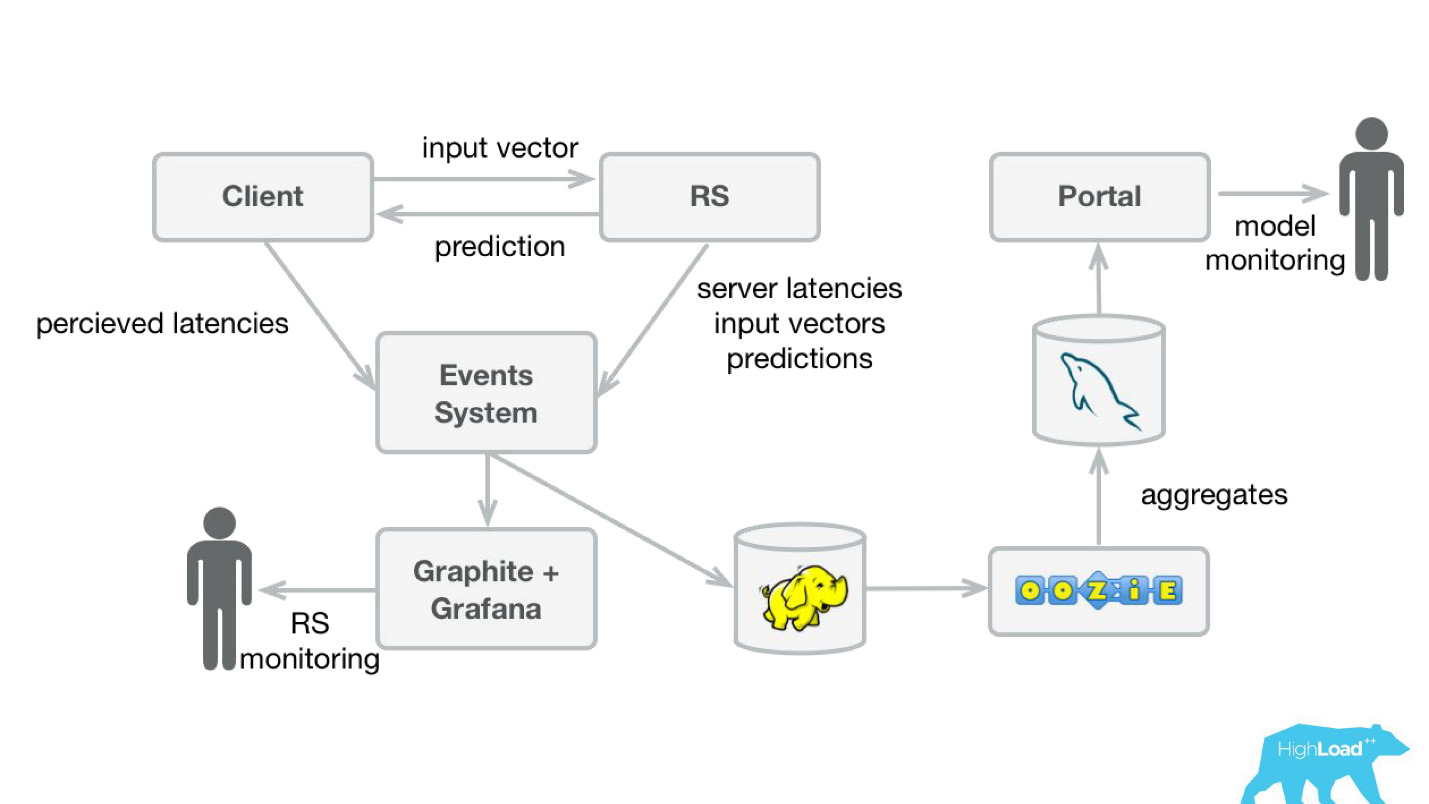
但是,重要的是弄清楚在那里显示什么。 事实是,在我们的案例中,很难计算出模型训练中常用的指标,因为通常我们在标签上会有很大的延迟。
以这个为例。 我们要预测用户是单独度假还是与家人度假。 当人们选择旅馆时,我们需要此预测,但我们只能在一年中找出真相。 刚休假时,用户将收到邀请进行评论,其中除其他事项外,还会有一个问题,即他是独自一人还是与家人在一起。
也就是说,您需要将一年中所做的所有预测存储在某个位置,甚至可以快速找到与传入标签匹配的内容。 听起来这是非常严肃的,甚至是沉重的投资。 因此,在我们解决这个问题之前,我们决定做一些简单的事情。
事实证明,这种“简单”仅仅是模型做出
的预测的
直方图 。
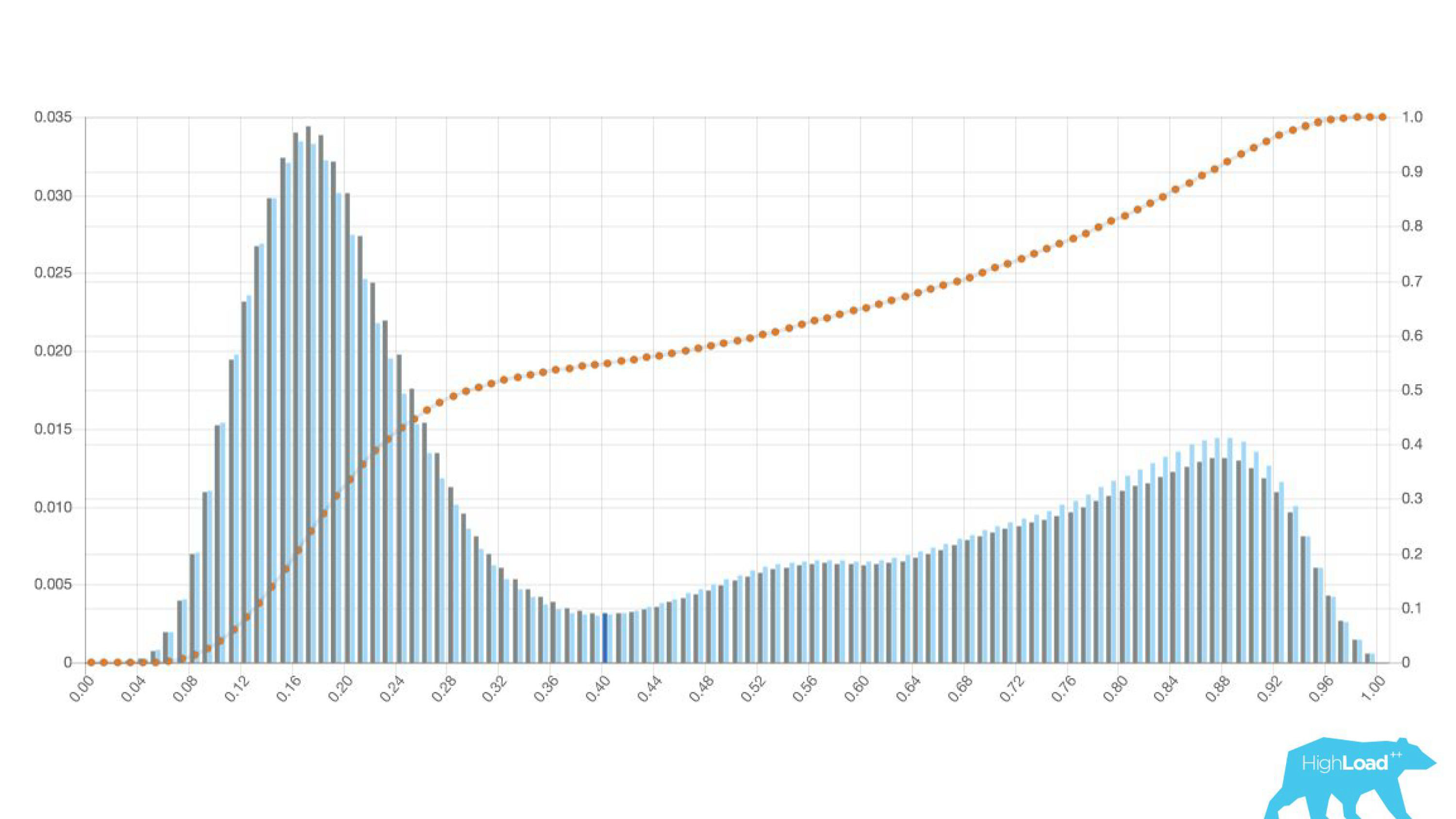
图的上方是逻辑回归,用于预测用户是否更改旅行日期。 可以看出,它将用户很好地分为两类:左边是那些不愿意做的人;另一边是不愿意做的人。 右边的山就是那些人。
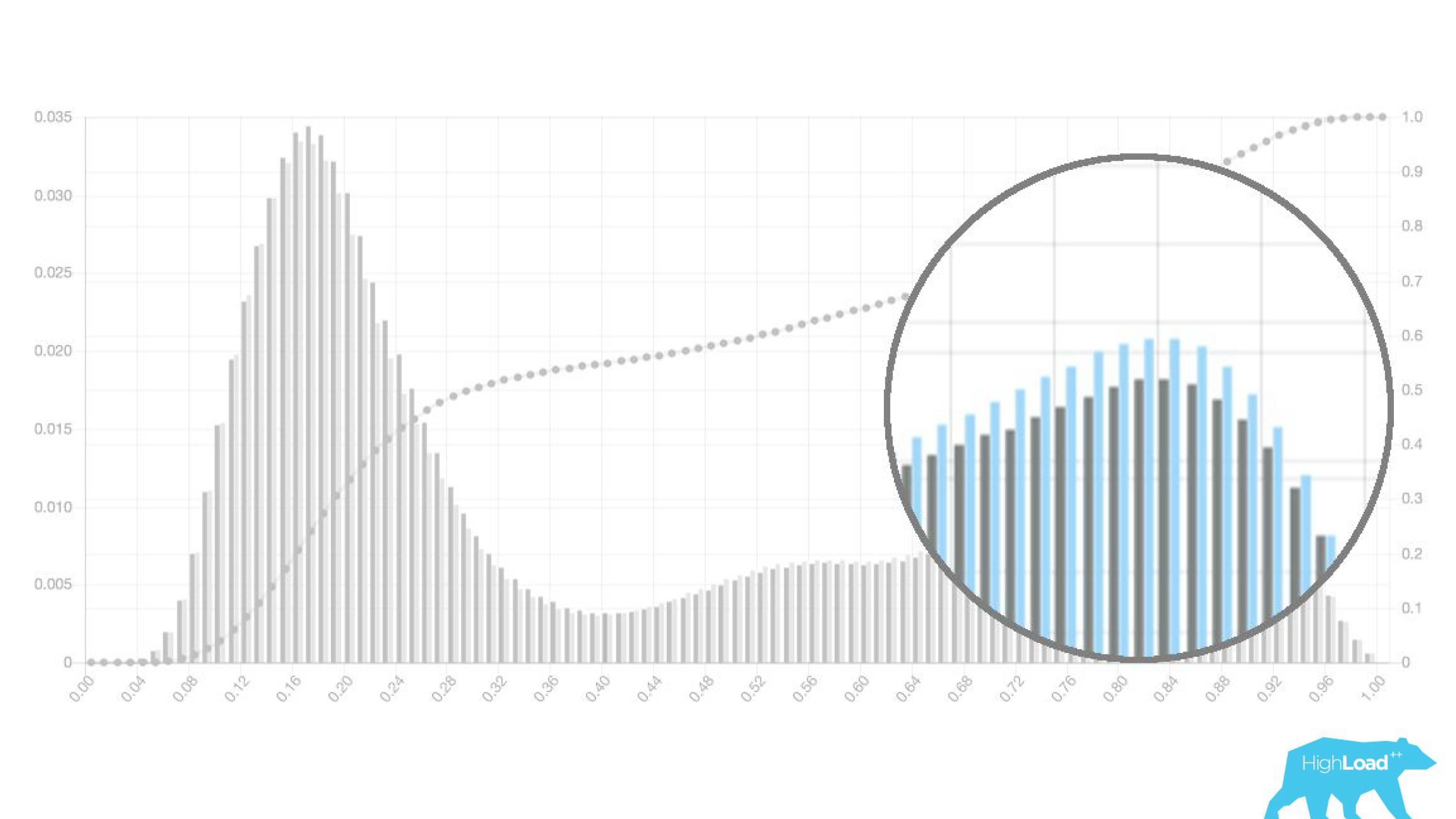
实际上,我们甚至显示了两个图表:一个用于当前期间,另一个用于上一个期间。 可以清楚地看到,本周(这是一个每周图表)该模型预测日期更频繁一些。 很难确定是季节性变化还是随着时间的推移而退化。
这导致数据科学家的工作发生了变化,他们不再与其他人接触,而是开始更快地迭代他们的模型。 他们与后端工程师一道将模型以空运行的方式投入生产。 也就是说,收集了向量,模型做出了预测,但是没有以任何方式使用这些预测。
对于徽章,我们只是不显示任何内容,而是收集统计数据。 这使我们不必浪费时间在失败的项目上。 我们为前端和设计师腾出了时间进行其他实验。
只要数据中心不确定模型是否可以按照他想要的方式工作,他就不会在此过程中让其他人参与。有趣的是,这些图在不同部分中如何变化。
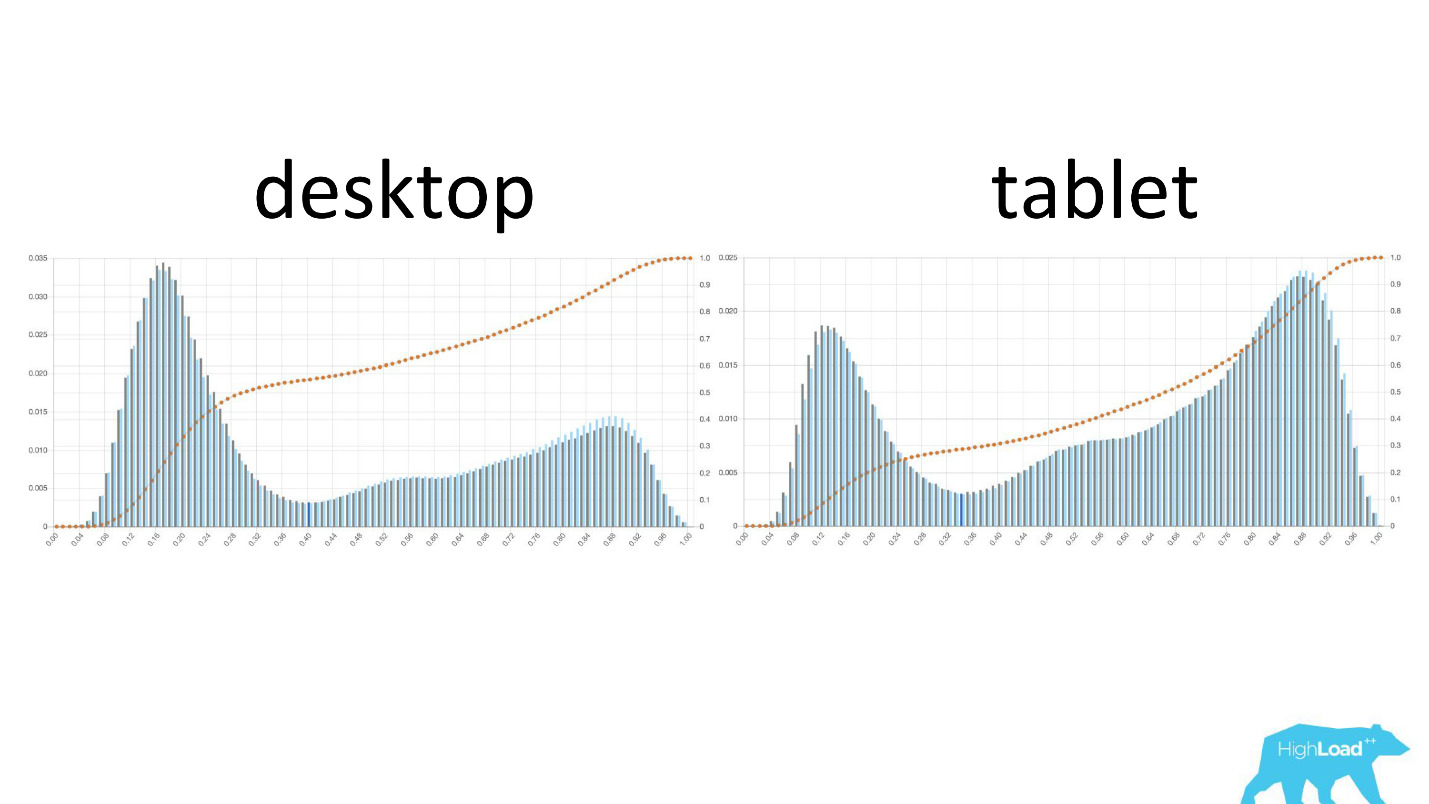
左侧是在台式机上更改日期的概率,右侧是在平板电脑上。 可以清楚地看到,在平板电脑上,该模型预测日期更可能发生变化。 这很可能是由于平板电脑经常用于旅行计划而很少用于预订的事实。
有趣的是,这些图表会随着用户在销售渠道中的移动而发生变化。
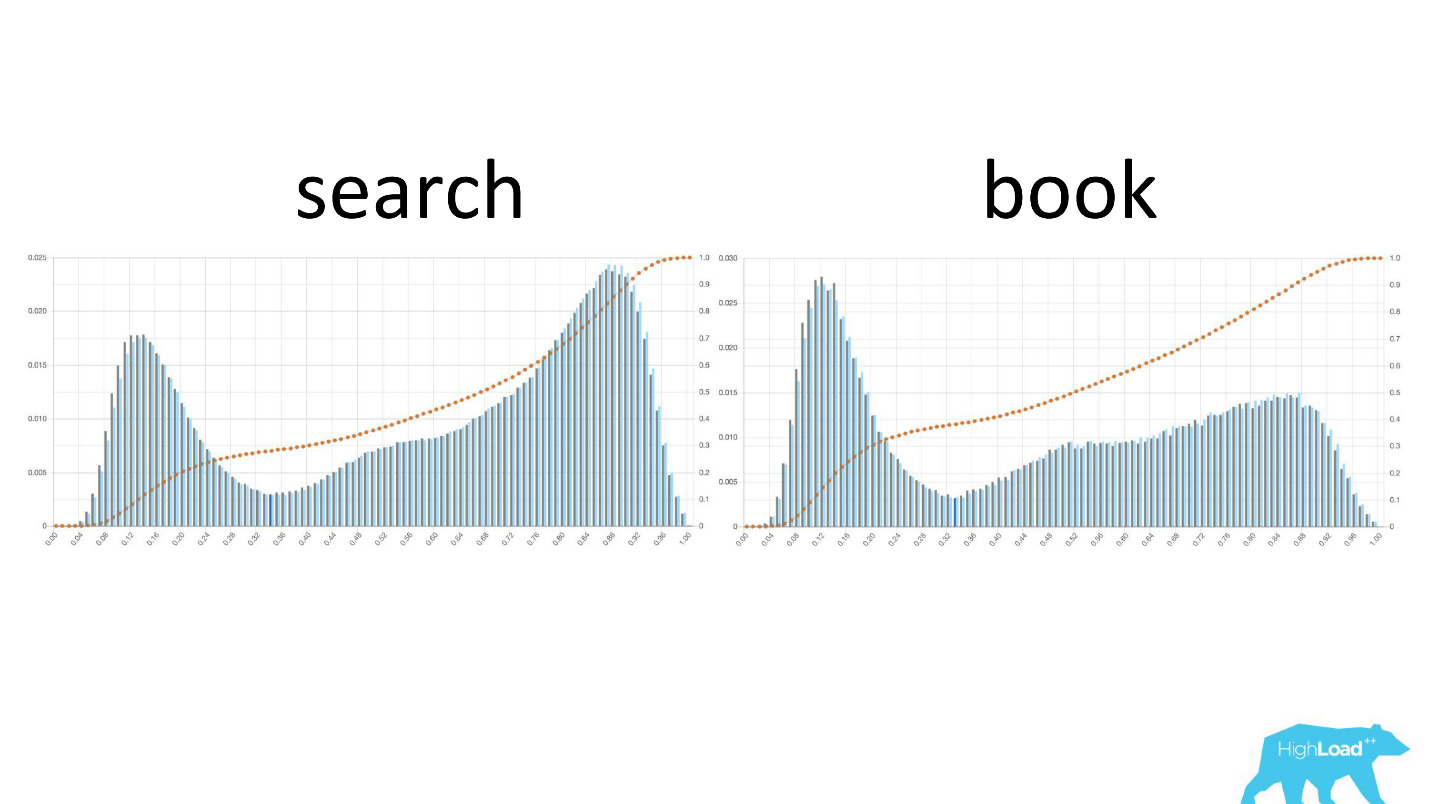
左侧是搜索页面上更改日期的概率,右侧是第一个预订页面。 可以看出,已经确定日期的人数更多的人进入了预订页面。
但是这些都是好的图形。 坏人是什么样的? 以非常不同的方式。 有时只是噪音,有时是巨大的山丘,这意味着该模型无法有效地区分任何两类预测。

有时这些是巨大的山峰。
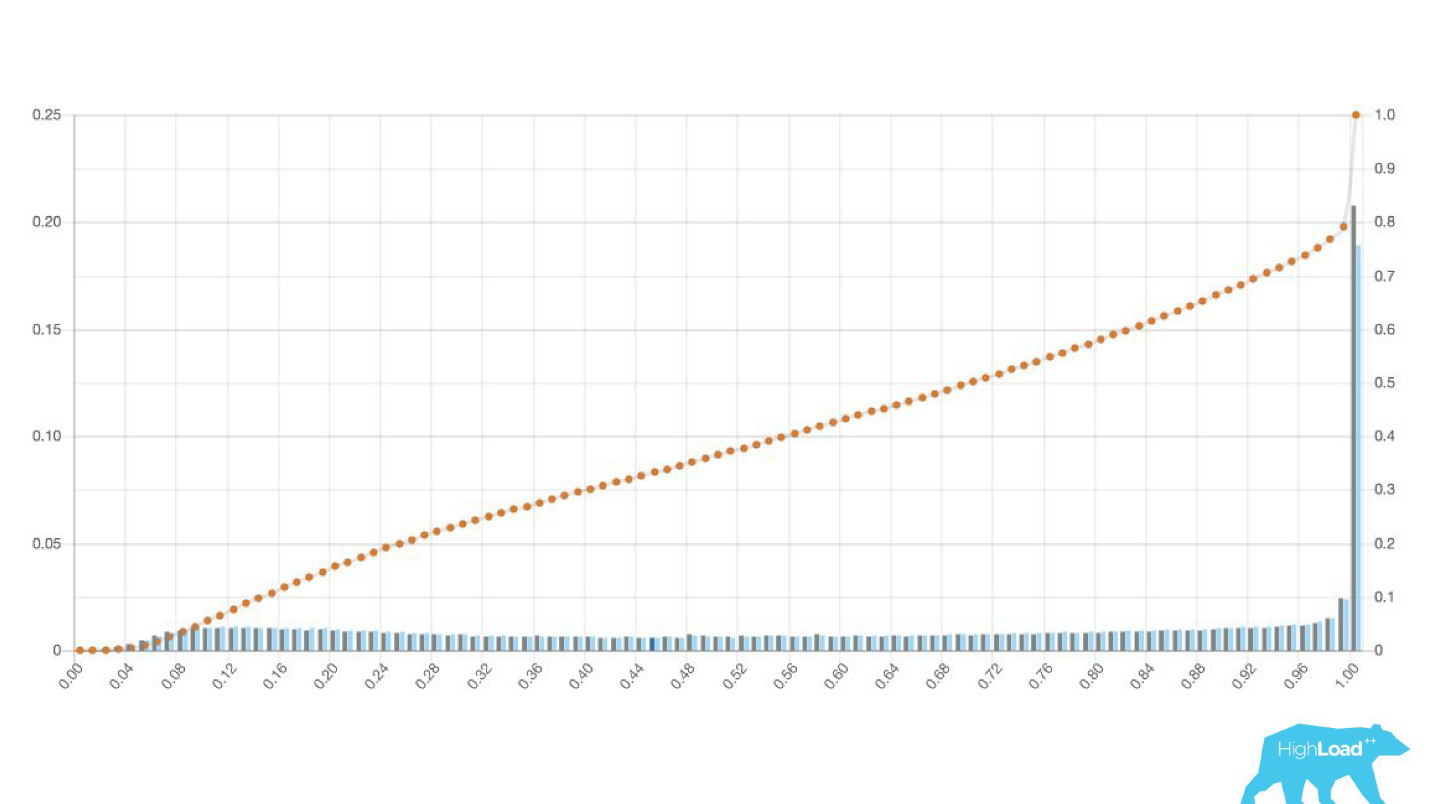
这也是逻辑回归,直到某个时候它显示了两座小山的美丽图画,但是到了一个早晨,它变成了这样。
为了了解内部发生了什么,您需要了解如何计算逻辑回归。
快速参考
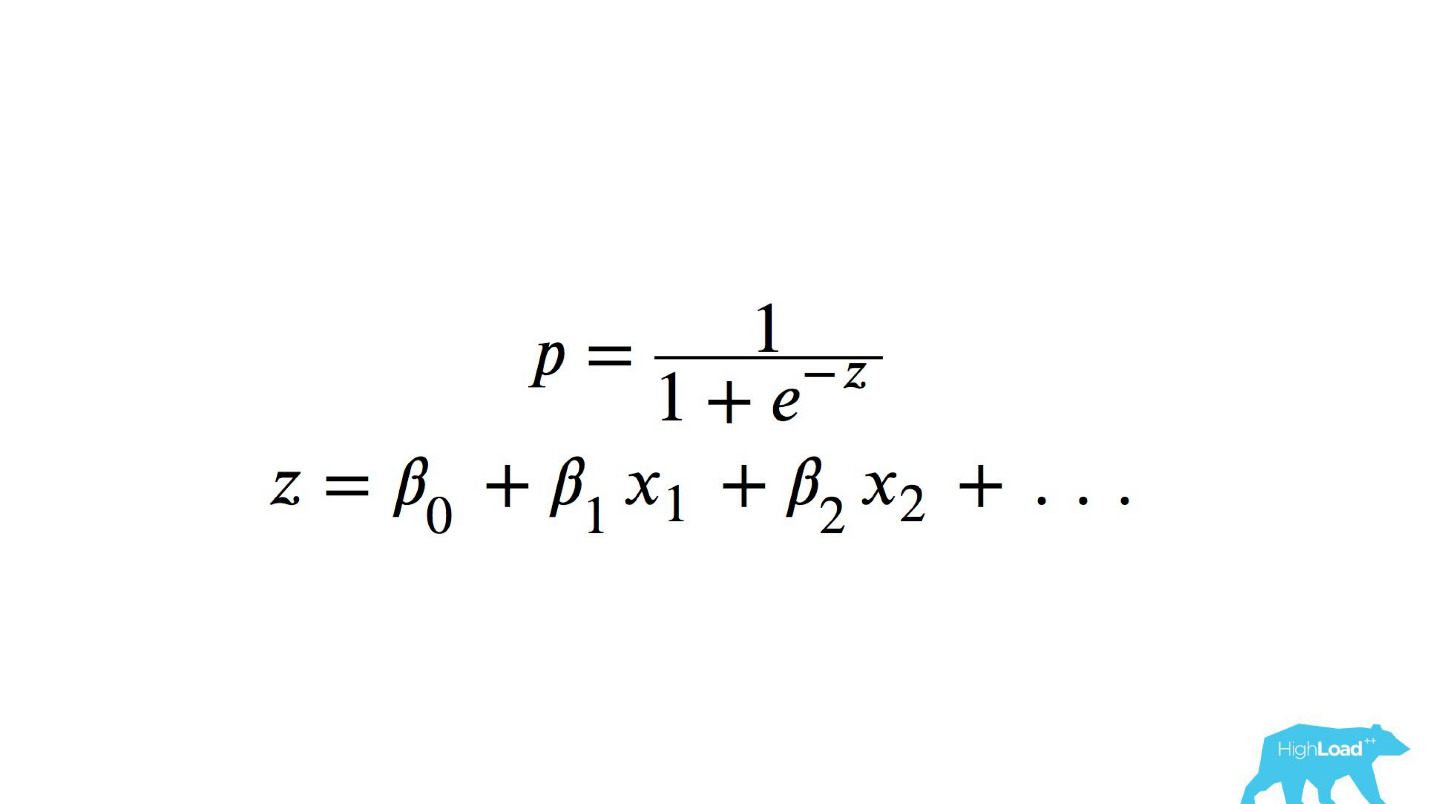
这是标量积的逻辑函数,其中x
n是一些特征。 这些功能之一就是在酒店住一晚的价格(欧元)。
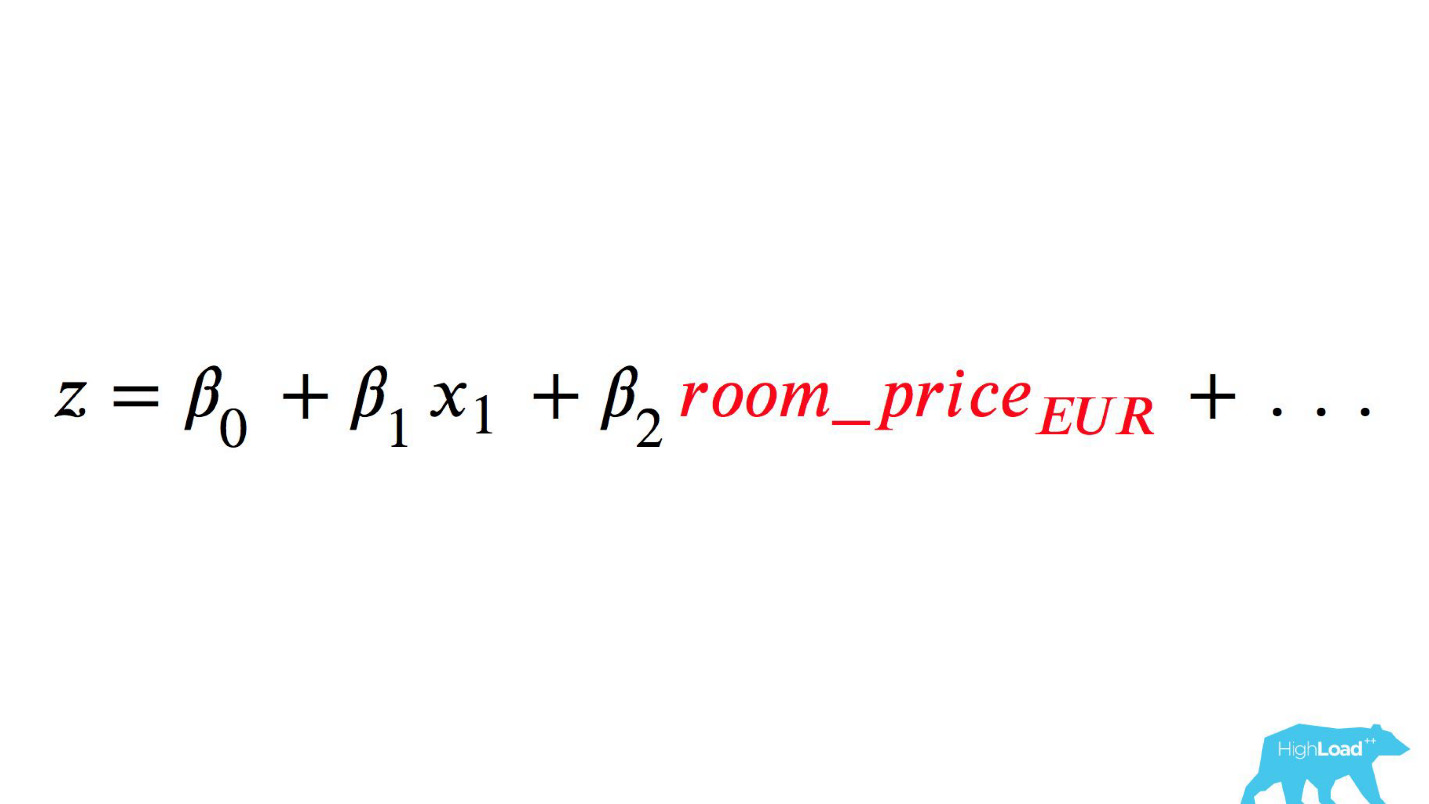
调用此模型将是这样的:
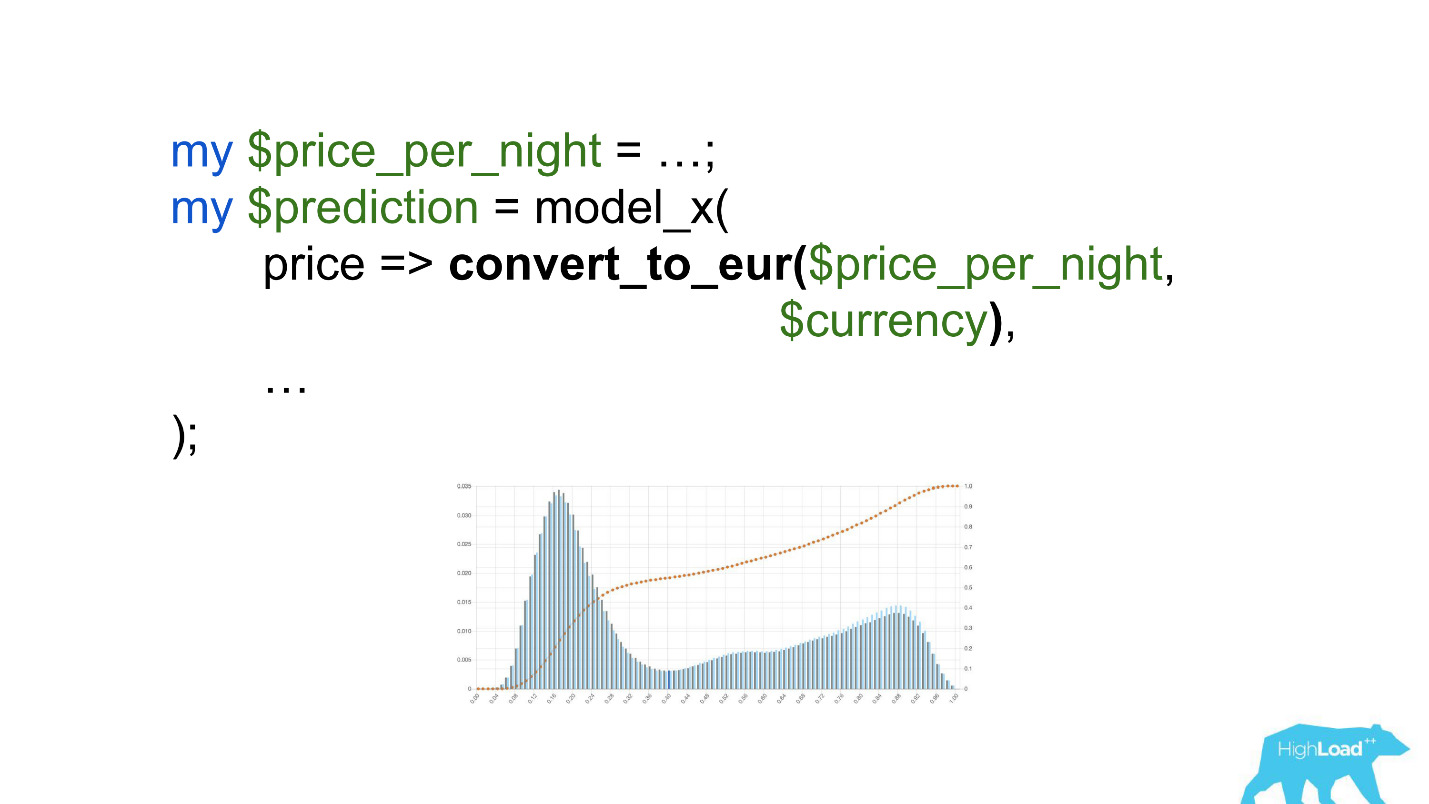
注意选择。 有必要将价格转换为欧元,但开发人员却忘记了。
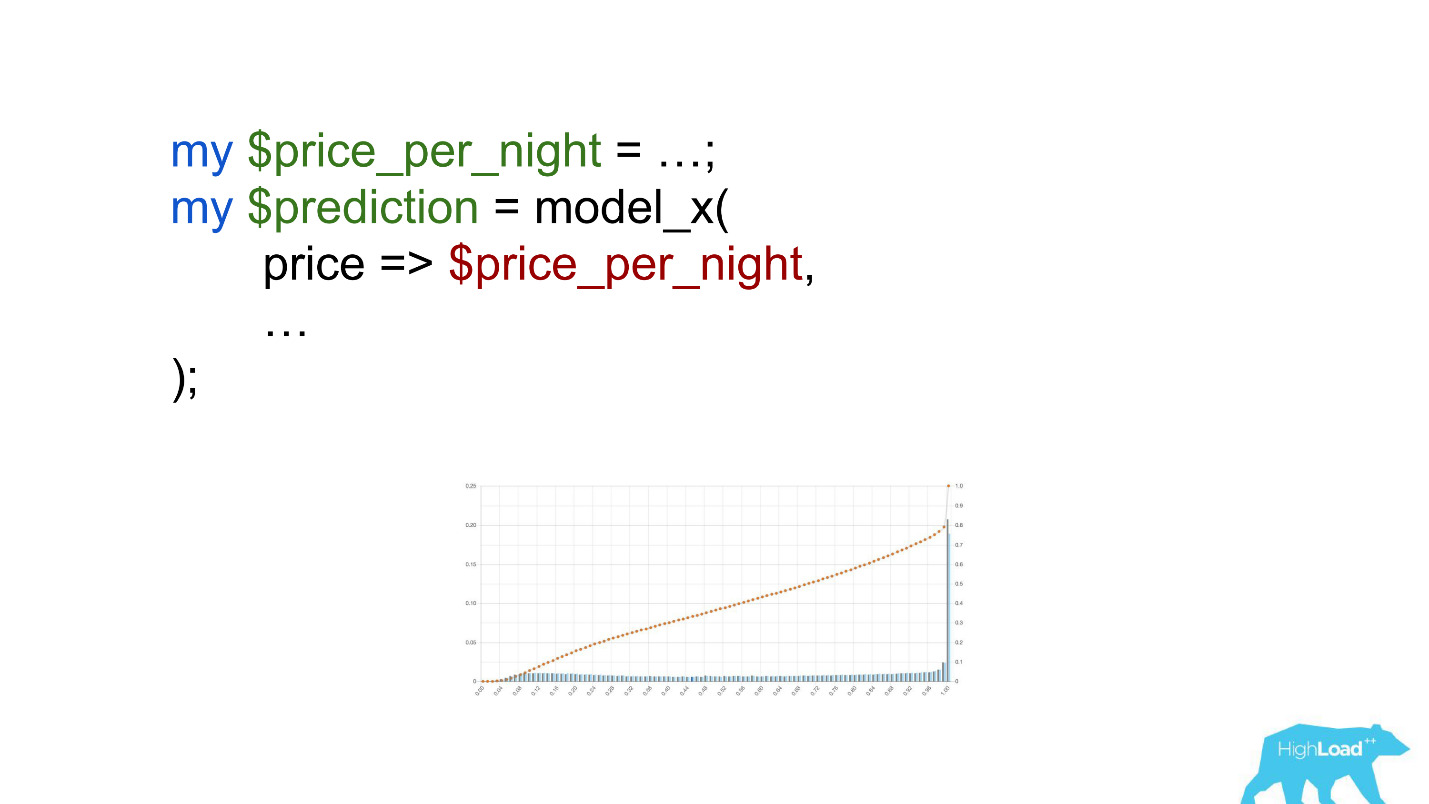
卢比或卢布之类的货币多次提高了标量产品,因此迫使该模型更频繁地产生接近于单位的值,这在图表上可以看到。
阈值
这些直方图的另一个有用功能是可以有意识地,最佳地选择阈值。
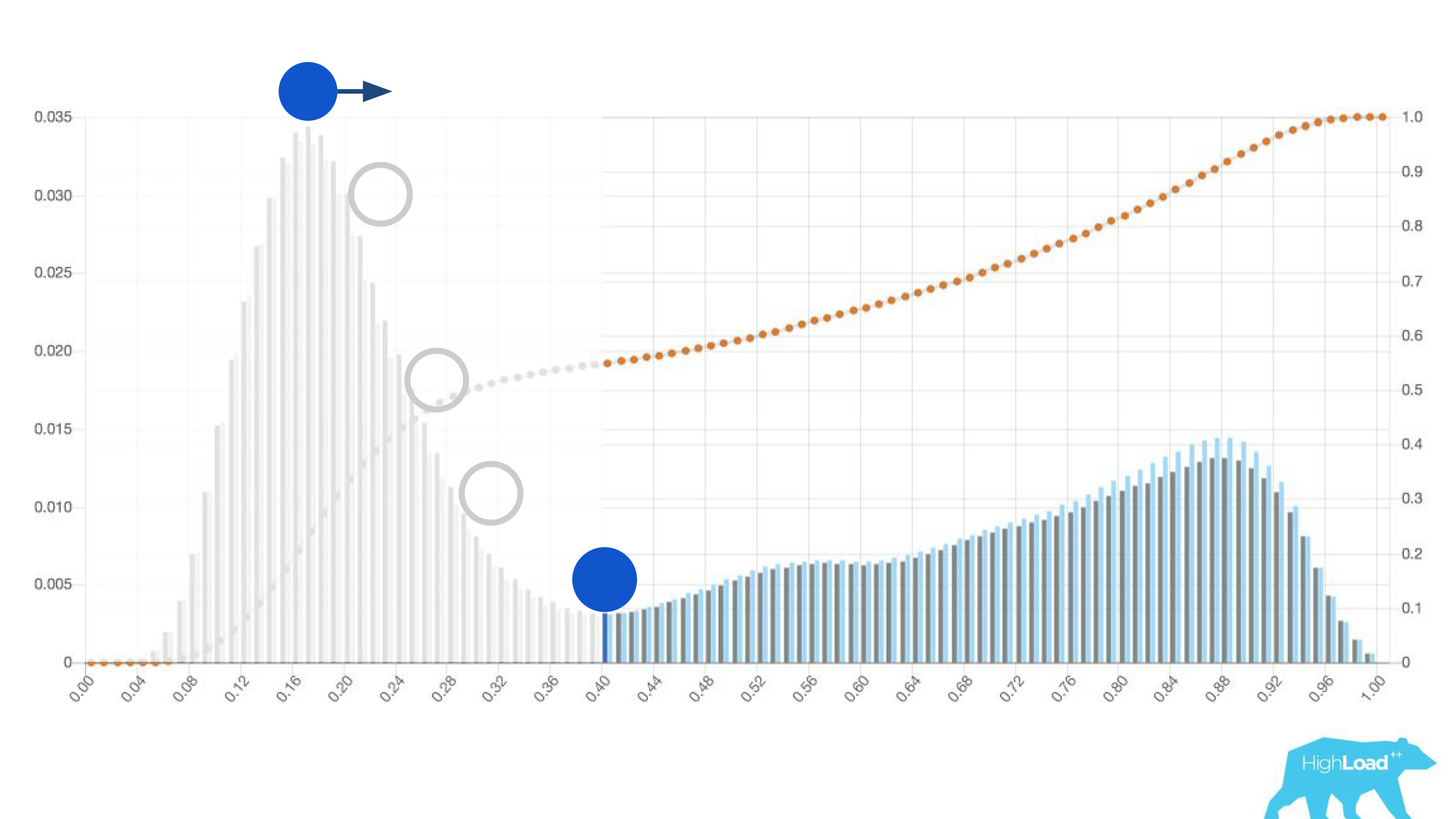
如果将球放置在此直方图中的最高山丘上,将其推入并想象它将停止的位置,这将是进行班级分离的最佳点。 右边的一切都是一类,左边的一切都是另一类。
但是,如果您开始提出这一点,则可以实现非常有趣的效果。 假设我们要运行一个实验,如果模型回答是,则以某种方式更改用户界面。 如果您将此点移到右边,我们的实验对象将会减少。 毕竟,接受此预测的人数就是曲线下的面积。 但是,实际上,预测的准确性要高得多。 同样,如果静态功率不足,则可以增加实验对象,但会降低预测的准确性。
除了预测本身之外,我们还开始监视向量中的输入值。
一种热编码
我们最简单的模型中的大多数功能都是分类的。 这意味着这些不是数字,而是某些类别:用户所在的城市或他正在寻找酒店的城市。 我们使用“一次热编码”,并将每个可能的值转换成二进制向量中的一个单位。 由于起初我们仅使用自己的计算核心,因此很容易识别在输入向量中没有输入类别的位置的情况,也就是说,模型在训练期间没有看到此数据。
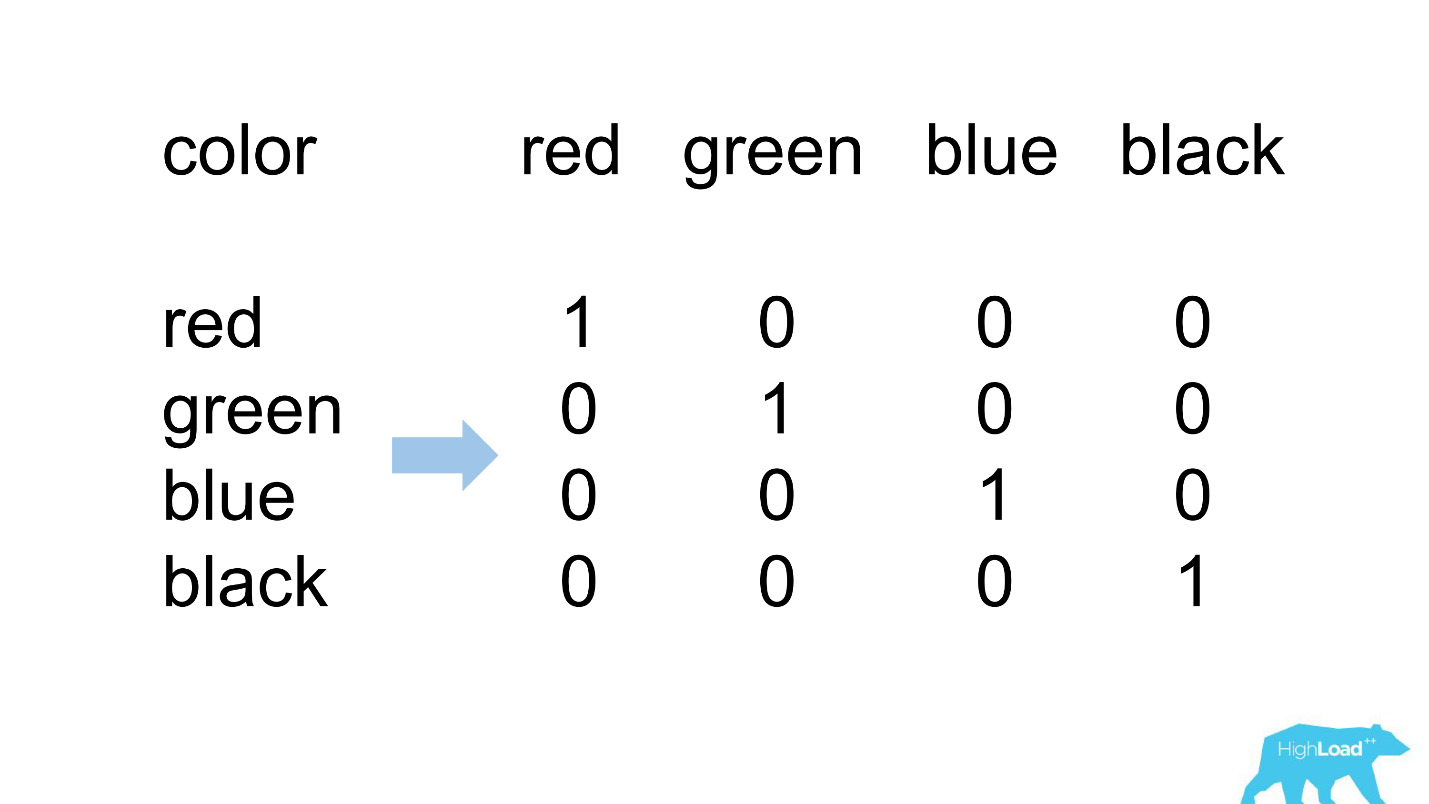
这是通常的样子。

destination_id-用户在其中寻找酒店的城市。 自然地,该模型没有看到约5%的值,因为我们一直在连接新城市。 visitor_cty_id = 23.32%,因为数据科学家有时会有意识地忽略不太常见的城市。
在坏的情况下,它可能看起来像这样:

立即获得3个属性,其中100%是模型从未见过的值。 这种情况最常见的原因是使用了培训中使用的格式以外的其他格式,或者仅仅是普通的拼写错误。
现在,借助仪表板,我们可以快速检测并纠正这种情况。
机器学习展示
让我们谈谈我们已经解决的其他问题。 在制作了客户端库并进行监视之后,该服务开始迅速发展。 从字面上看,我们公司的各个部门的应用程序不堪重负:“让我们也连接这种模式! 让我们更新旧的!” 我们只是缝制了,实际上任何新的发展都已停止。
我们通过
为数据科学家提供自助服务亭来摆脱困境。 现在,您可以转到我们的门户,该门户是我们最初仅用于监视的门户,并且通过单击按钮可以将模型加载到生产环境中。 几分钟后,她将工作并给出预测。
还有一个问题。
Booking.com有大约200个IT团队。 如何让团队在公司的某些完全不同的部分中知道有一种可以帮助他们的模型? 您可能根本不知道这样的团队甚至存在。 如何找出其中的模型以及如何使用它们? 传统上,我们团队中的外部沟通由PO(产品负责人)负责。 这并不意味着我们没有任何其他水平连接,只是PO比其他功能要多。 但是很明显,在这样的规模上,一对一的沟通无法扩展。 您需要对此做些事情。
如何促进沟通?我们突然意识到,我们专门用于监视的门户逐渐开始变成我们公司内机器学习的展示。
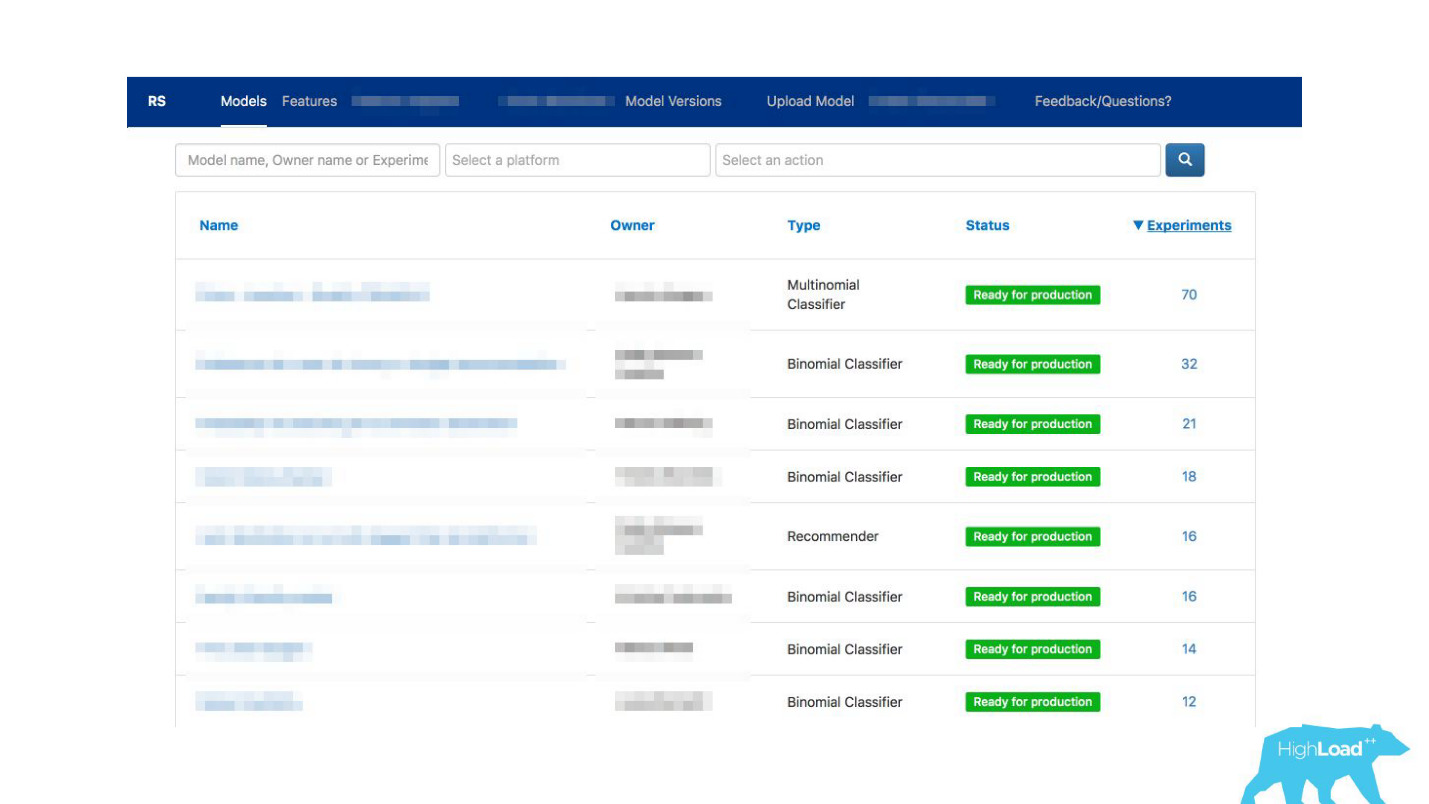
我们使数据科学家能够详细描述他们的模型。 当模型很多时,我们添加了主题和区域标签以方便分组。
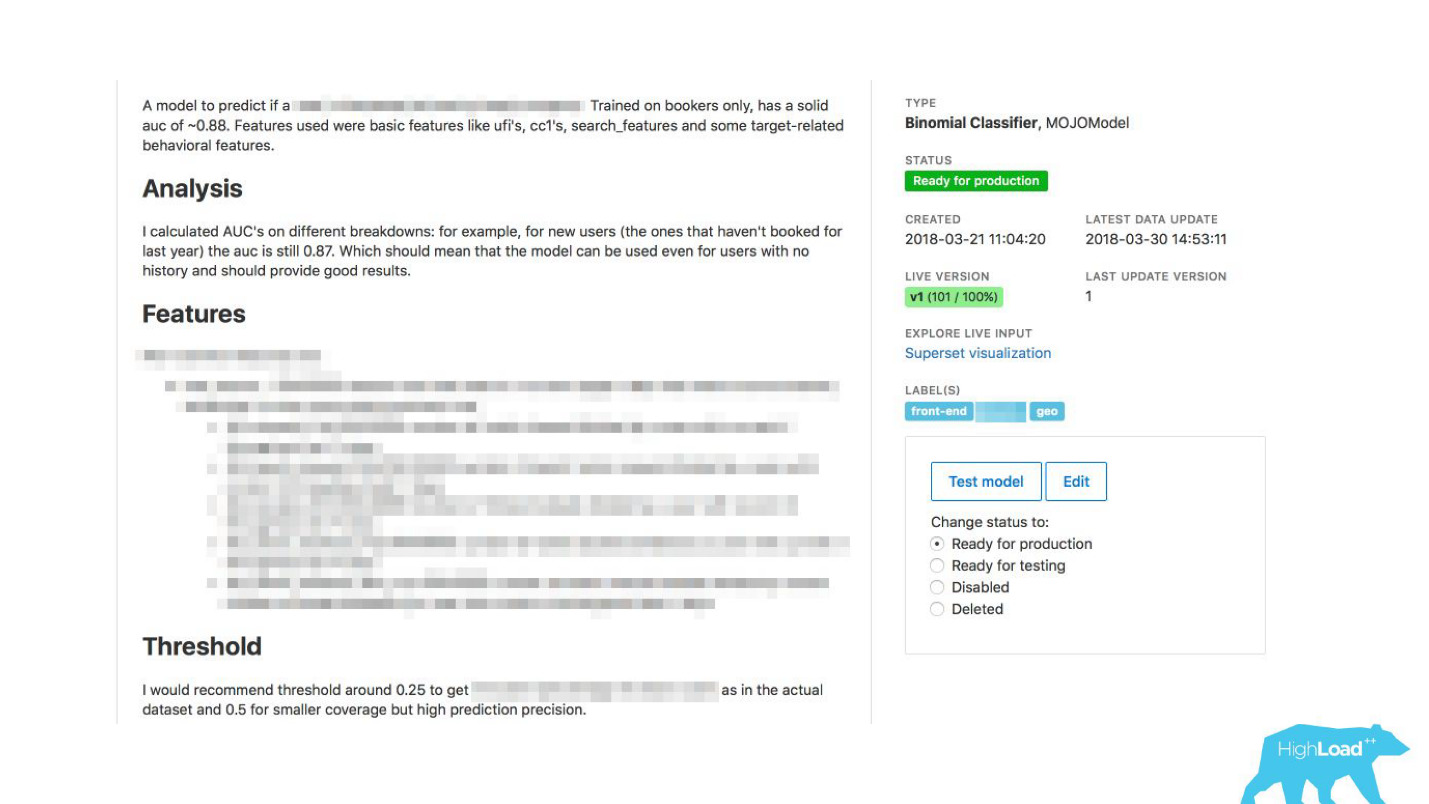
我们已将工具与ExperimentTool链接在一起。 这是我们公司内部提供的产品,可提供A / B实验并存储整个实验历史。

现在,除了对模型的描述之外,您还可以查看其他团队之前对该模型所做的工作以及成功的方法。 它改变了一切。
严重地,这改变了IT的工作方式,因为即使在团队中没有数据科学家的情况下,您也可以使用机器学习。
例如,许多团队在集思广益会议期间使用此功能。 当他们提出一些新产品创意时,他们只需选择适合自己的型号并使用它们。 不需要任何复杂的操作。
它为我们洒了什么? 目前,在高峰期,我们每秒可提供约20万个预测,延迟小于20-30毫秒,包括HTTP往返行程和200多个模型的放置。
在公园里散步似乎很轻松:我们做得很出色,一切正常,每个人都很高兴!
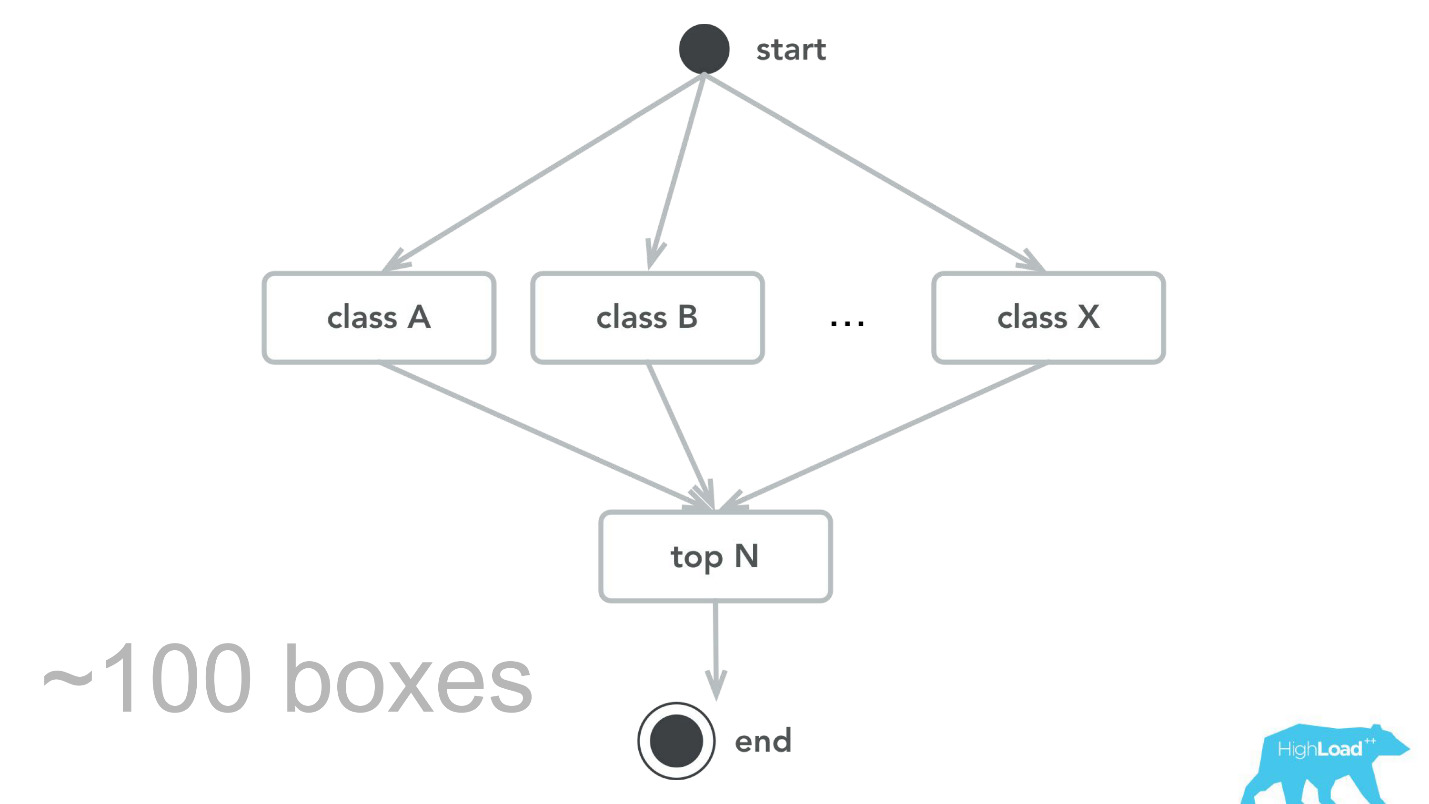
当然,这不会发生。 有错误。 例如,在一开始,我们就植入了一颗小型定时炸弹。 出于某种原因,我们假设我们的大多数模型将是具有沉重输入向量的推荐系统,而之所以选择Scala + Akka堆栈是因为它很容易在其帮助下组织并行计算。 但是实际上,所有这些并行化的开销(收集在一起)实际上要高于可能的收益。 在某个时候,我们的100台计算机仅处理了100,000 RPS,并且发生了一些具有特征性症状的故障:CPU利用率低,但是会超时。
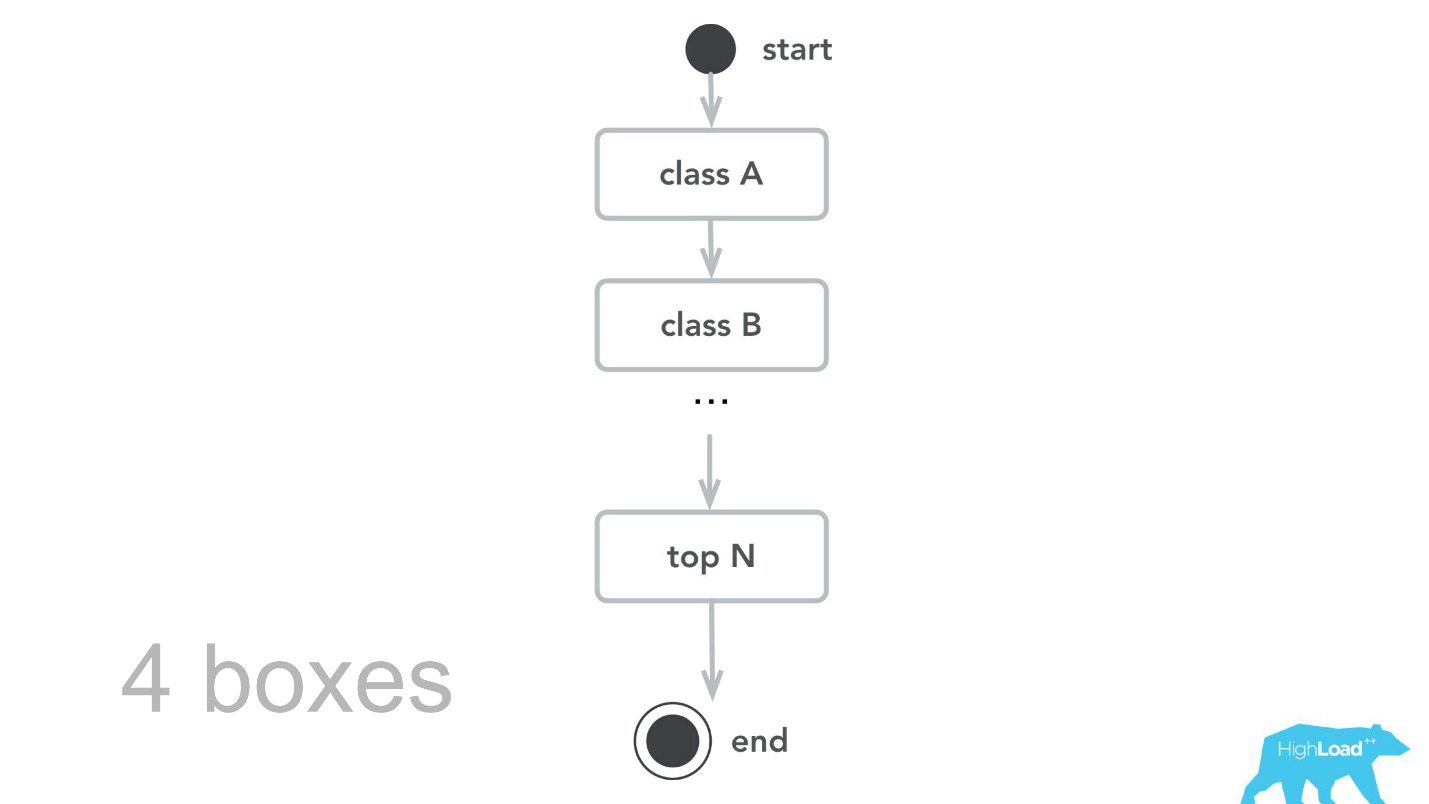
然后,我们回到了计算核心,进行了审查,制定了基准,并且通过容量测试,我们了解到,对于相同的流量,我们仅需要4台计算机。 , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
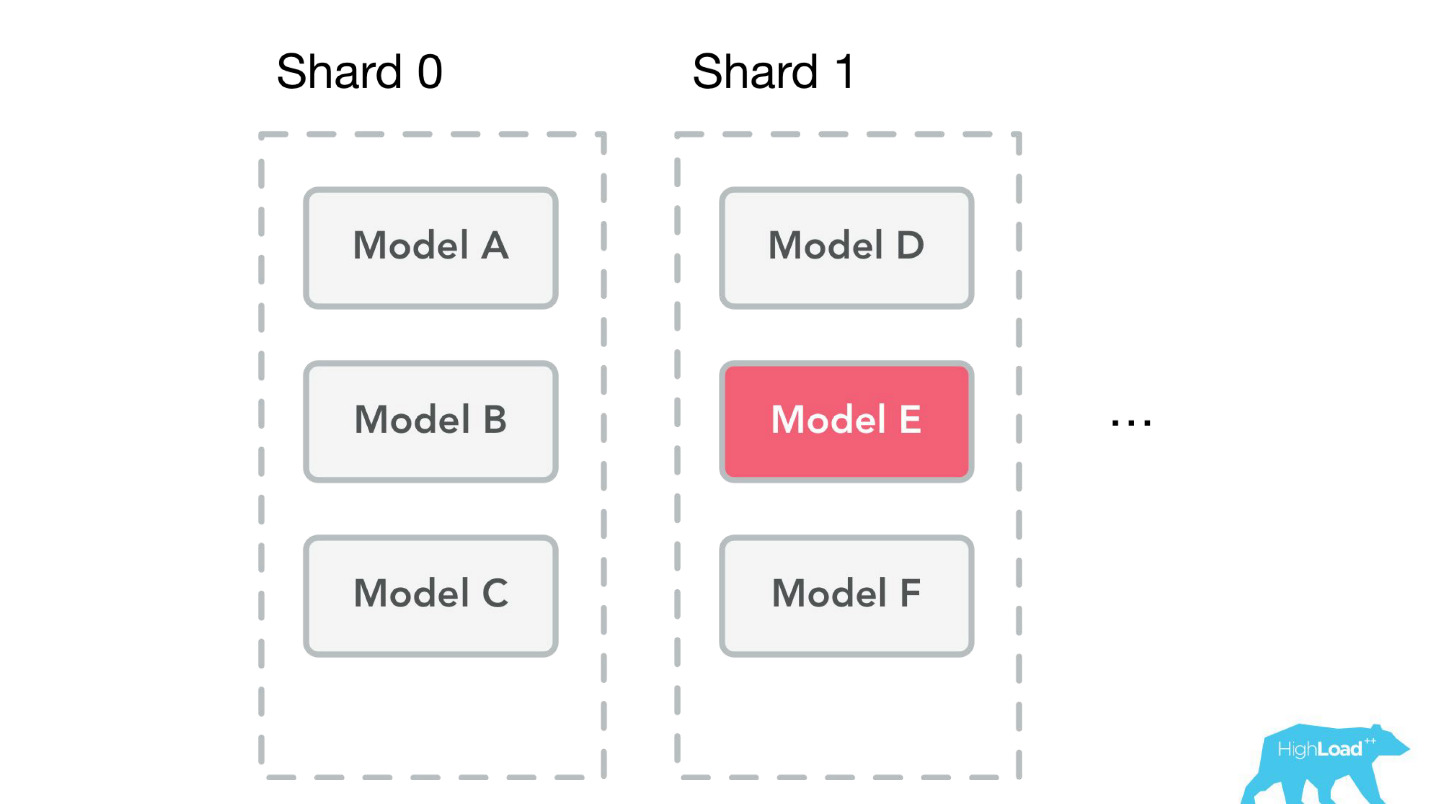
— , . , ID , . , 0.
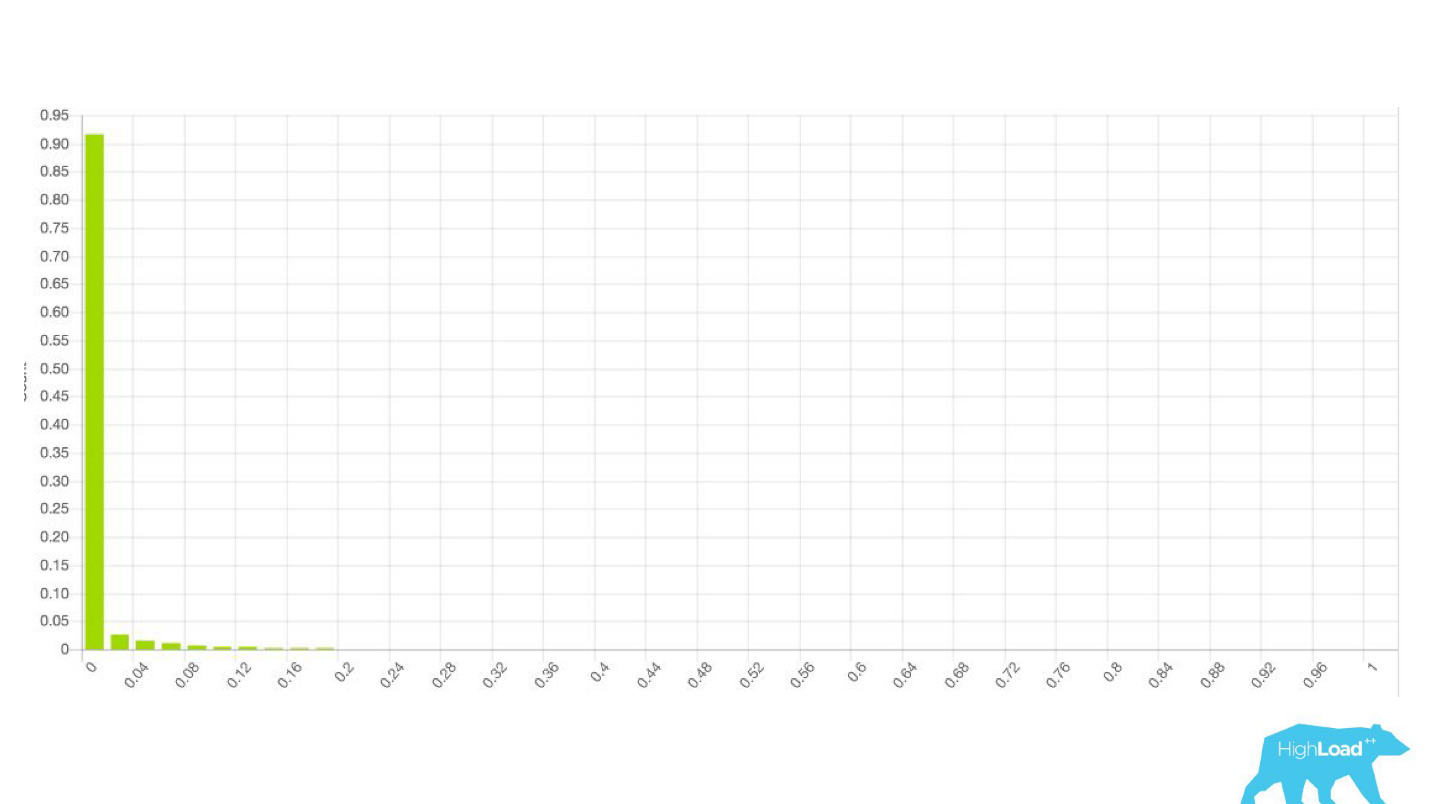
— , — .
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
未来计划
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .