客户必须先进行验证,然后才能在ePayments中进行汇款。 他向我们提供他的个人数据,并上传文件以验证其身份和地址。 并且我们检查它们是否满足监管机构的要求。 验证的申请流程越来越多,我们处理此类文件流程变得越来越困难。 我们担心此过程将花费大量时间,并且超出客户的所有合理条件。 然后,我们决定创建一个基于深度学习的验证系统。

有关监管机构及其要求的教育计划
要发行电子货币,您需要获得监管机构许可证。 例如,如果您在俄罗斯建立付款系统,则俄罗斯联邦中央银行将成为您的监管者。 ePayments是一种英语付款系统,我们的监管者是金融行为监管局(FCA),该机构向英国财政部报告。 FCA确保我们遵守反洗钱政策(AML),其中包括“了解客户”(KYC)程序集。
根据KYC的说法,我们致力于检查我们的客户是谁,以及他是否与社会危险群体有联系。 因此,我们有两个义务:
- 识别并确认客户身份。
- 将他的数据与各种清单进行核对:恐怖分子,受到制裁的人员,政府成员等。
每年,KYC要求都变得更加严格和详细。 在2017年初,ePayments客户仍可在未经验证的情况下接收付款或进行转账。 现在这是不可能的,直到他们确认自己的身份。
手动验证
几年前,我们独自应对。 俄国人扫描了护照的某些页面以确认其身份,并扫描了租赁协议,用于支付住房和公共服务的收据以确认地址。 还记得游戏论文吗? 在其中,您扮演海关官员的角色,对照政府日益复杂的要求检查文件。 我们的客户部门每天都在工作。

客户可以通过远程验证,而无需访问办公室。 为了加快流程,我们雇用了新员工,但这是一个死胡同。 然后这个想法委托了神经网络的部分工作。 如果她能很好地应对人脸识别,那么她就能应付我们的任务。 从业务角度来看,快速验证系统应该能够:
- 对文档进行分类。 我们会收到身份证和居住地址确认信。 系统应回答输入时收到的信息:俄罗斯联邦公民的护照,租赁协议或其他内容。
- 比较照片和文档中的面孔。 我们要求客户使用身份证发送自拍照,以确保他们自己已在付款系统中注册。
- 提取文字。 从智能手机填充数十个字段不是很方便。 如果应用程序为您完成了所有操作,则容易得多。
- 检查图像文件中的照片蒙太奇。 我们一定不要忘记那些想要欺诈性地进入系统的骗子。
在输出时,系统应指示对客户端的特定信任级别:高,中或低。 着眼于这种等级,我们将迅速核实并不会长时间激怒客户。
文件分类器
该模块的任务是确保用户发送有效的文件并给出他明确上传的答案:哈萨克斯坦公民的护照,租赁协议或用于支付住房和公共服务的收据。
分类器接收输入数据:
- 照片或扫描文件
- 居住国家
- 客户注明的文件类型(身份证或地址证明)
- 提取的文字(更多内容见下文)
在输出结果中,分类器报告他收到的信息(护照,驾驶执照等)以及他对正确答案的信心。

该解决方案现在可以在宽残留网络体系结构上运行。 我们没有马上来找她。 快速验证系统的第一个版本是在VGG启发我们的体系结构的基础上工作的。 她有两个明显的问题:大量参数(大约1.3亿个)和文档位置的不稳定。 参数越多,训练这样的神经网络就越困难-概括性差。 照片中的文档应居中,否则分类器将必须针对位于照片不同部分中的样本进行训练。 结果,我们放弃了VGG,决定改用其他架构。
残留网络(ResNet)比VGG凉爽。 多亏了
跳过连接,您可以创建大量图层并实现高精度。 ResNet仅具有约一百万个参数,她对文档的位置毫不关心。 无论它在图像中的什么位置,此体系结构上的解决方案都可以处理分类。
当我们用文件完成解决方案时,发布了新的体系结构修改,宽残留网络(WRN)。 与ResNet的主要区别是在深度方面有所退步。 WRN的层数较少,但卷积滤波器更多。 现在,这是适用于大多数任务的最佳神经网络体系结构,我们的解决方案也可以在其中进行工作。
一些有用的解决方案
问题编号1.分类器需要训练。 我们不得不下载很多俄罗斯,哈萨克和白俄罗斯的护照和驾驶执照。 但是,当然,您不能获取客户文档。 网络上有样本,但是样本数量太少,无法成功地训练神经网络。
解决方法。 我们的技术部门生成了8000多种每种类型的样本。 我们创建一个文档模板,并乘以许多随机样本。 然后,我们考虑到文档的数学模型和特性(焦距,矩阵分辨率等),相对于相机在文档中生成了一个随机位置。 生成人工照片时,从完成的数据集中选择随机图像作为背景。 之后,将具有透视变形的文档随机放置在图像上。 在这样的样本上,我们的神经网络训练有素,并完美定义了“战斗中”的文档。 结果在文章末尾。
问题编号2。对计算资源和内存的常规限制。 向大图像的输入提交深度神经网络是没有意义的。 而来自现代智能手机的照片就是这样。
解决方法。 在应用于输入之前,将照片压缩为大约300x300像素的大小。 从这种许可的图像中,一个人可以轻松地区分一个身份证明文件。 为了解决这个问题,我们可以使用标准的Wide ResNet体系结构。
问题编号3。有了确认住所地址的文件,一切都变得更加复杂。 租赁协议或银行对帐单只能通过表格上的文字加以区分。 将图像尺寸减小到相同的300x300像素后,所有这些文档看起来都一样-就像A4纸上的文字难以辨认。
解决方法。 为了对任意文档进行分类,我们对神经网络本身的体系结构进行了更改。 另一个神经元输入层出现在其中,并与输出层相连。 此输入层的神经元接收矢量输入,该矢量输入使用“
单词袋”模型描述先前识别的文本。
首先,我们训练了一个神经网络对身份证件进行分类。 当初始化带有附加层的另一个网络来分类任意文档时,我们使用了受过训练的网络的权重。 该解决方案具有很高的准确性,但是文本识别花费了一些时间。 表2列出了不同模块之间的处理速度和分类精度之间的差异。
人脸识别
如何欺骗检查文件的付款系统? 您可以借用他人的护照并进行注册。 为了确保客户正在注册,我们要求您使用身份证进行自拍照。 识别模块应该将文档上的脸与自拍照上的脸进行比较并回答,这是一两个人。
如果您是汽车并且像汽车一样思考如何比较两张脸? 将一张照片变成一组参数,并将它们的值相互比较。 这就是识别面部的神经网络的工作方式。 他们拍摄图像并将其转换为128维(例如)矢量。 当您将另一张面部图像提交给输入并要求它们进行比较时,神经网络会将第二张面部转换为矢量并计算它们之间的距离。
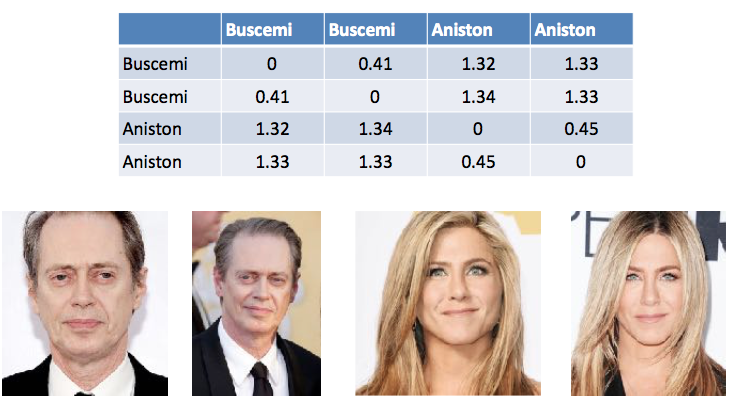 表1.计算面部识别中向量之间差异的示例。 史蒂夫·布塞米(Steve Buscemi)在不同的照片中与他自己的差异为0.44。 詹妮弗·安妮斯顿(Jennifer Aniston)的平均得分为1.33。
表1.计算面部识别中向量之间差异的示例。 史蒂夫·布塞米(Steve Buscemi)在不同的照片中与他自己的差异为0.44。 詹妮弗·安妮斯顿(Jennifer Aniston)的平均得分为1.33。当然,一个人的生活和护照上的样子是有区别的。 我们还选择了向量之间的距离,并在真实人物上进行了测试,以得出结果。 在任何情况下,最终决定权都将由该人员做出,来自系统的评论仅是建议。
文字识别
文档上有文本字段,可帮助分类程序了解其前面的内容。 如果同一护照中的文本自动传输并且不必手动键入,由谁签发,何时签发,将为用户带来方便。 为此,我们制作了以下模块-识别和文本提取。
在某些证件上,例如俄罗斯联邦的新护照上有机器可读区(MRZ)。 有了它的帮助,很容易获得信息-很容易在白色背景上阅读黑色文本,这很容易识别。 此外,MRZ具有众所周知的格式,因此,它更易于获得必要的数据。

如果任务包含带有MRZ的文档,那么对我们来说将变得更加容易。 整个过程位于计算机视觉领域。 如果该区域不存在,那么在识别文本之后,您需要解决一个有趣的问题-理解,我们识别了哪些信息? 例如,“ 1999年5月15日”是出生日期还是签发日期? 在此阶段,您也可能会犯错。 MRZ很好,因为它是唯一解码的。 我们始终知道要查找的信息以及机读区的哪一部分。 对我们来说非常方便。 但是MRZ并不是该网络可以使用的最流行的文件-俄罗斯联邦的护照。
对于文本识别,我们需要一个非常有效的解决方案。 必须从手机相机拍摄的图像中删除文字,而不是由最专业的摄影师拍摄。 我们测试了Google Tesseract和几种付费解决方案。 什么都没发生-它工作不佳,或者价格不合理。 因此,我们开始开发自己的解决方案。 现在我们正在完成他的测试。 该解决方案显示出不错的结果-您可以在下面阅读有关它们的信息。 稍后,当测试样本和“战斗”获得准确的研究结果时,我们将讨论用于检查照片蒙太奇的模块。
结果
该系统目前正在俄罗斯的验证应用程序段中进行测试。 该细分市场是通过随机抽样确定的,结果被保存并根据客户部门运营商针对特定客户的决定进行检查。
| 国别 | 分类器类型 | 准确度 | 工作时间,s |
| 俄罗斯 | 身份证 | 99.96% | 0.41 |
| 俄罗斯 | 自订文件 | 98.62% | 6.89 |
| 哈萨克斯坦 | 身份证 | 99.51% | 0.47 |
| 哈萨克斯坦 | 自订文件 | 97.25% | 7.66 |
| 白俄罗斯 | 身份证 | 98.63% | 0.46 |
| 白俄罗斯 | 自订文件 | 98.63% | 9.66 |
表2.文件分类器的准确性(与操作员的评估相比,文件的正确分类)。机器学习的巨大优势之一是神经网络可以真正学习并且减少错误。 很快,我们将完成对网段的测试,并以“战斗”模式启动验证系统。 俄罗斯,哈萨克斯坦和白俄罗斯的验证付款申请中有30%来自ePayments。 根据我们的估计,此次发布将帮助减少客户部门的工作量20-25%。 将来,该解决方案可以扩展到欧洲国家。
找工作?
我们正在寻找在圣彼得堡的办公室工作的员工。 如果您对具有大量雄心勃勃任务的国际项目感兴趣,我们正在等待您的光临。 我们没有足够的人不惧怕实现这些目标。 您可以在下面在hh.ru上找到职位空缺的链接。