哈ha
在一个需要存储和处理相当大的动态列表的项目中,测试人员开始抱怨内存不足。 下面介绍了通过仅添加一行代码来解决“小问题”的简单方法。 图片中的结果:
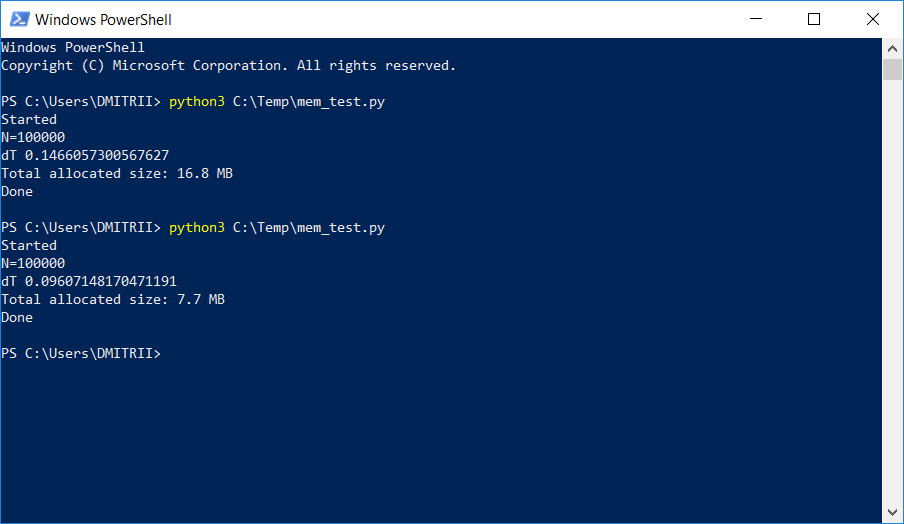
运作方式,继续削减。
考虑一个简单的“培训”示例-创建一个DataItem类,其中包含有关某
个人的个人数据,例如姓名,年龄和地址。
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
“孩子们”的问题是这样的对象在内存中占了多少?
让我们尝试一下额头上的解决方案:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
我们得到56个字节的响应。 似乎有点满意。
但是,我们检查另一个有更多数据的对象:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
答案仍然是56。在这一点上,我们了解到这里并不存在某些事情,并非所有事情都像乍看起来那样简单。
直觉并不会使我们失败,而且一切真的不是那么简单。 Python是一种具有动态类型的非常灵活的语言,在其工作中,它存储了许多其他数据。 它们自己占了很多。 举个例子,sys.getsizeof(“”)将返回33-是的,每个空行多达33个字节! sys.getsizeof(1)将返回24到24个字节的整数(我要求C程序员远离屏幕并且不进一步阅读,以免对美观失去信心)。 对于更复杂的元素,例如字典,sys.getsizeof(dict())将返回272个字节-这是一个
空字典。 我不再赘述,希望原理很明确,
RAM制造商也需要出售他们的芯片 。
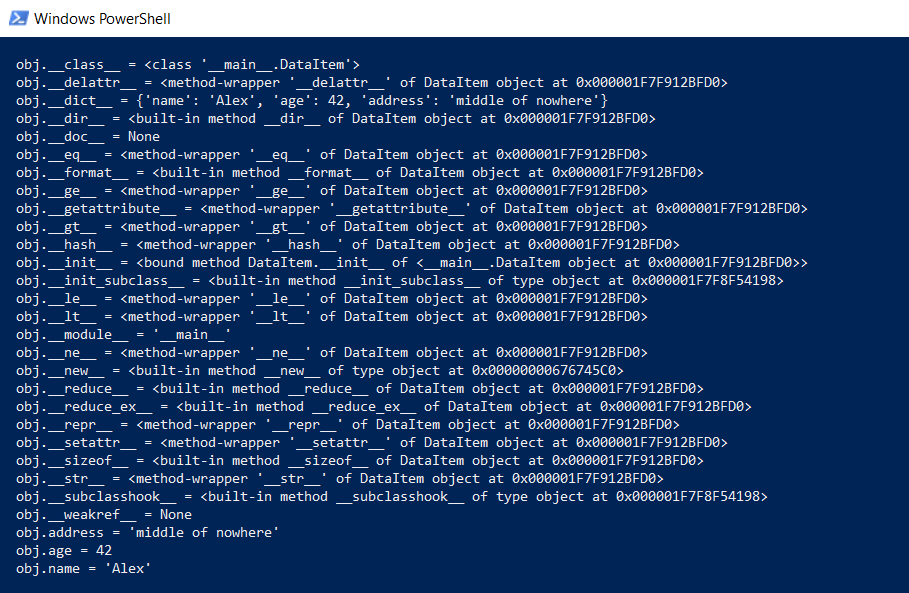
回到我们的DataItem类和“子级”问题。 这样的课程需要花费多长时间? 首先,我们在较低的级别显示该类的全部内容:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
此函数将显示“隐藏在幕后”的内容,以便所有Python函数(键入,继承和其他功能)都可以起作用。
结果令人印象深刻:
这需要多少钱? 在github上有一个计算实际数据量的函数,递归调用所有对象的getsizeof。
def get_size(obj, seen=None):
我们尝试一下:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
我们分别得到460和484字节,这更像是事实。
具有此功能,可以进行许多实验。 例如,我想知道如果将DataItem结构放在列表中会占用多少数据。 get_size([d1])函数返回532个字节-显然,这是“相同的” 460 +一些开销。 但是get_size([d1,d2])将返回863字节-分别小于460 + 484。 更有趣的是get_size([d1,d2,d1])的结果-我们得到871个字节,即多了一点,即 Python很聪明,不会第二次为同一对象分配内存。
现在我们来看问题的第二部分-是否可以减少内存消耗? 是的,你可以。 Python是解释器,我们可以随时扩展我们的类,例如,添加一个新字段:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
很好,但是如果我们
不需要此功能,则可以使用__slots__指令强制解释器列出类的对象:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
您可以在文档(
RTFM )中阅读更多内容,该文档说:“ __ slots__允许我们显式声明数据成员(如属性),并拒绝创建__dict__和__weakref__。使用__dict__
可以节省
大量空间。”
检查:是的,非常重要,get_size(d1)返回... 64个字节而不是460个字节,即 少7倍。 另外,创建对象的速度提高了约20%(请参阅本文的第一个屏幕截图)。
las,在实际使用中,如此大的内存增长不会归因于其他开销。 让我们通过简单地添加元素来为100,000创建一个数组,然后查看内存消耗:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
我们有16.8 MB(无__slots__)和6.9 MB。 当然,这不是7倍,但考虑到代码更改是最小的,即使如此,它也是如此。
现在谈谈缺点。 激活__slots__禁止创建所有元素,包括__dict__,这意味着,例如,将结构转换为json的代码将不起作用:
def toJSON(self): return json.dumps(self.__dict__)
但它很容易修复,只需以编程方式生成您的字典,即可对循环中的所有元素进行排序:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
动态添加新变量到类中也是不可能的,但是在我的情况下,这不是必需的。
以及今天的最后一次测试。 有趣的是,整个程序需要占用多少内存。 在程序末尾添加一个无限循环,以使其不会关闭,并在Windows任务管理器中查看内存消耗。
没有__slots__:
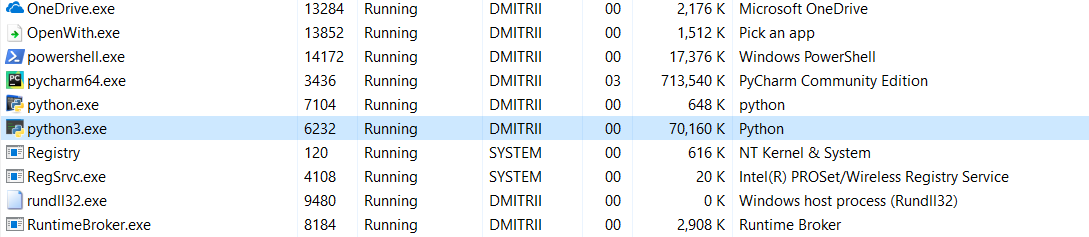
16.8MB奇迹般地(编辑-下面的奇迹解释)变成了70MB(我希望C程序员还没有回到屏幕上吗?)。
启用__slots__:

6.9MB变成了27MB ...好吧,毕竟我们节省了内存,对于添加一行代码的结果来说,27MB而不是70MB并不算太坏。
编辑 :在注释中(感谢robert_ayrapetyan进行测试),他们建议tracemalloc调试库占用大量额外的内存。 显然,它向
每个创建的对象添加了其他元素。 如果禁用它,则总的内存消耗将少得多,屏幕快照显示2个选项:
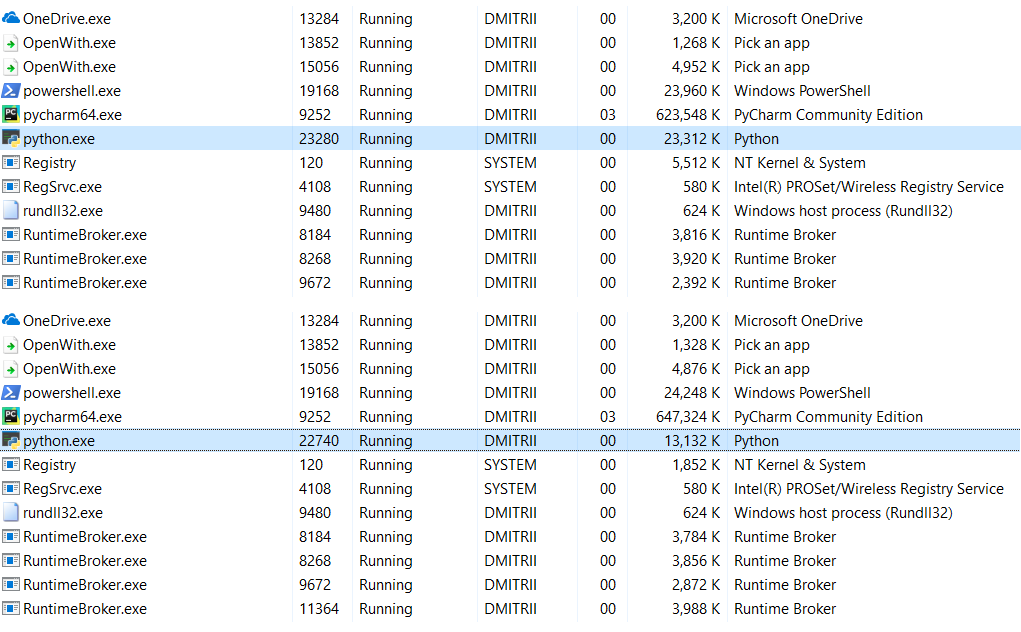
如果需要节省更多内存该怎么办? 使用
numpy库可以实现这一点,它允许您创建C样式的结构,但是在我的情况下,它需要对代码进行更深的细化,第一个方法被证明是足够的。
奇怪的是,从未在Habré上详细检查过__slots__的用法,我希望本文能弥补这一空白。
而不是结论。
这篇文章看起来像是Python的反广告,但根本不是。 Python非常可靠(您必须
非常努力地删除Python程序),这种语言易于阅读且易于编写代码。 在许多情况下,这些优点胜过缺点,但是,如果您需要最大的性能和效率,则可以使用以C ++编写的numpy之类的库,该库可以快速高效地处理数据。
谢谢大家的关注,以及好的代码:)