通过对
Guess.js预测
模型的改进进行试验,我开始密切关注深度学习:递归神经网络(RNN),尤其是LSTM,因为它们在Guess.js工作的领域具有
“不合理的有效性” 。 同时,我开始研究卷积神经网络(CNN),它也经常用于时间序列。 CNN通常用于分类,识别和检测图像。
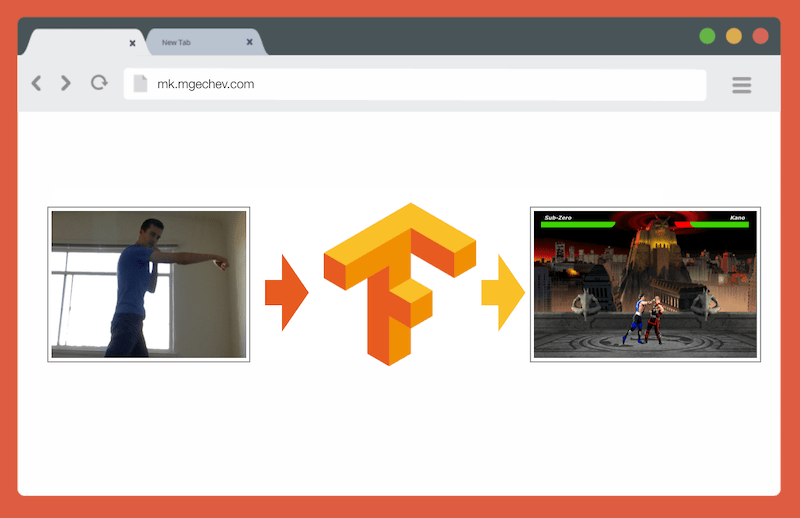 使用TensorFlow.js管理MK.js
使用TensorFlow.js管理MK.js本文和MK.js的源代码在我的GitHub上 。 我还没有发布训练数据集,但是您可以按照以下说明构建自己的模型并训练模型!
在玩了CNN之后,我还记得几年前浏览器开发人员发布
getUserMedia API时进行的一项
实验 。 在其中,用户的相机充当了播放Mortal Kombat 3的小型JavaScript克隆的控制器。您可以在
GitHub存储库中找到该游戏。 作为实验的一部分,我实现了一种基本的定位算法,该算法将图像分为以下几类:
该算法非常简单,我可以用几句话来解释它:
该算法拍摄背景。 一旦用户出现在框架中,该算法就会计算出与用户之间的背景和当前框架之间的差异。 因此,它确定了用户图形的位置。 下一步是以黑底白字显示用户的身体。 之后,建立垂直和水平直方图,将每个像素的值相加。 基于此计算,算法将确定身体的当前位置。
视频显示了程序的工作方式。
GitHub源代码。
尽管微型MK克隆成功运行,但该算法还远非完美。 需要带有背景的框架。 为了正确操作,在程序执行期间,背景必须为相同的颜色。 这样的限制意味着光线,阴影和其他事物的变化会干扰并给出不准确的结果。 最后,该算法无法识别该动作。 他只将新框架分类为预定义集合中身体的位置。
现在,由于Web API(即WebGL)的进步,我决定通过应用TensorFlow.js返回此任务。
引言
在本文中,我将分享我使用TensorFlow.js和MobileNet创建用于对身体位置进行分类的算法的经验。 请考虑以下主题:
- 收集训练数据以进行图像分类
- 使用imgaug进行数据增强
- 使用MobileNet转移学习
- 二元分类和N元分类
- 在Node.js中训练TensorFlow.js图像分类模型并在浏览器中使用它
- 关于使用LSTM对动作进行分类的几句话
在本文中,与通过一系列帧识别动作相反,我们将减少基于一个帧确定身体位置的问题。 我们将与老师一起开发深度学习模型,该模型基于用户网络摄像头中的图像来确定人的动作:踢腿,踢腿或不做任何动作。
到本文结尾,我们将能够构建一个播放
MK.js的模型:

为了更好地理解本文,读者应该熟悉编程和JavaScript的基本概念。 对深度学习的基本理解也是有用的,但不是必需的。
资料收集
深度学习模型的准确性高度依赖于数据质量。 与生产中一样,我们需要努力收集广泛的数据集。
我们的模型应该能够识别出拳和踢脚。 这意味着我们必须收集三个类别的图像:
在此实验中,两名志愿者(
@lili_vs和
@gsamokovarov )帮助我收集了照片。 我们在MacBook Pro上录制了5个QuickTime视频,每个视频包含2-4个脚和2-4个脚。
然后,我们使用ffmpeg从视频中提取单个帧并将其另存为
jpg图像:
ffmpeg -i video.mov $filename%03d.jpg要执行上述命令,首先需要在计算机上
安装 ffmpeg 。
如果要训练模型,则必须提供输入数据和相应的输出数据,但是在此阶段,我们只有一堆包含三个人的不同姿势的图像。 要构建数据,您需要将框架分为三类:拳,踢和其他。 对于每个类别,将创建一个单独的目录,所有对应的图像都将移动到该目录中。
因此,在每个目录中应该有大约200张与以下图像相似的图像:

请注意,“其他”目录中将有更多的图像,因为相对较少的帧中包含有拳打脚踢的照片,而其余的帧中则是人们走动,转身或控制视频。 如果我们在一类的图像上有太多的图像,则冒着教导偏向该特定类的模型的风险。 在这种情况下,当对具有冲击力的图像进行分类时,神经网络仍可以确定类别“其他”。 为了减少这种偏见,您可以从“其他”目录中删除一些照片,并在每个类别上使用相同数量的图像训练模型。
为方便起见,我们在目录编号中分配的编号从
1到
190 ,因此第一个图像为
1.jpg ,第二个图像为
1.jpg ,依此
2.jpg 。
如果仅在同一环境下由同一个人拍摄600张照片中的模型,我们将无法获得很高的准确性。 为了充分利用我们的数据,最好使用数据增强来生成一些额外的样本。
数据扩充
数据增强是一种通过从现有集中合成新点来增加数据点数量的技术。 通常,增强用于增加训练集的大小和多样性。 我们将原始图像转移到创建新图像的转换管道中。 您不能太过激进地进行转换:应该从打孔器中生成其他手动打孔器。
可接受的转换包括旋转,颜色反转,模糊等。有出色的开源工具可用于数据增强。 在用JavaScript撰写本文时,没有太多选择,因此我使用了在Python中实现的库
-imgaug 。 它具有一组可以概率应用的增强器。
这是此实验的数据扩充逻辑:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
该脚本使用具有三个
for循环的
main方法-每个图像类别一个。 在每次迭代中,在每个循环中,我们都调用
draw_single_sequential_images方法:第一个参数是文件名,第二个是路径,第三个是保存结果的目录。
之后,我们从磁盘读取映像,并对其进行一系列转换。 我已经在上面的代码片段中记录了大多数转换,因此我们将不再重复。
对于每个图像,还将创建其他16张图片。 这是它们的外观示例:

请注意,在上述脚本中,我们将图像缩放到
100x56像素。 我们这样做是为了减少数据量,从而减少我们的模型在训练和评估期间执行的计算数量。
模型制作
现在建立分类模型!
由于我们正在处理图像,因此我们使用卷积神经网络(CNN)。 已知该网络体系结构适用于图像识别,对象检测和分类。
学习转移
下图显示了流行的CNN VGG-16,用于对图像进行分类。
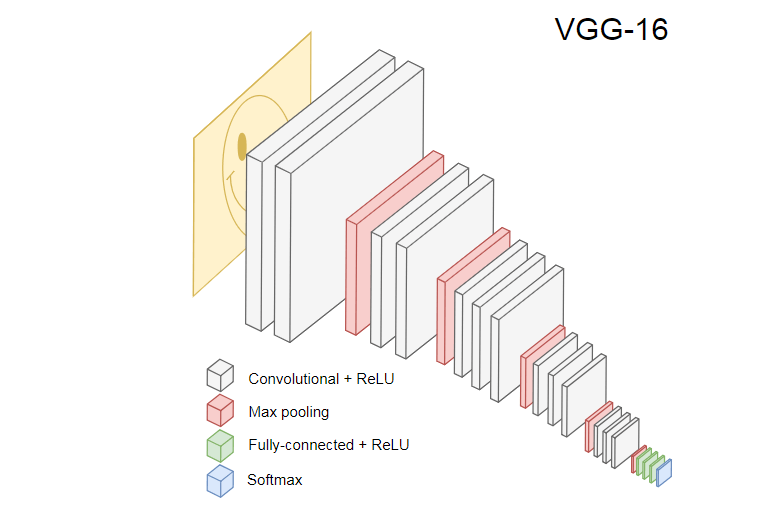
VGG-16神经网络可识别1000种图像类别。 它有16层(不计算池和输出层)。 这样的多层网络在实践中很难训练。 这将需要大量的数据集和许多小时的培训。
被训练的CNN的隐藏层从边缘开始识别训练集中的图像的各种元素,然后移动到更复杂的元素,例如形状,单个对象等。 VGG-16风格的经过训练的CNN(用于识别大量图像)必须具有隐藏层,这些隐藏层已从训练集中学习了很多功能。 这些功能对于大多数图像来说是通用的,因此可以在不同的任务中重复使用。
学习转移使您可以重用现有且经过培训的网络。 我们可以从现有网络的任何层获取输出,并将其作为输入传递到新的神经网络。 因此,通过教导新创建的神经网络,随着时间的推移,可以教导人们识别更高级别的新功能,并从原始模型从未见过的类中正确分类图像。
为了我们的目的,请从
@ tensorflow-models / mobilenet软件包中获取MobileNet神经网络。 MobileNet的功能与VGG-16一样强大,但体积却小得多,从而可以加快直接分发速度,即网络传播(正向传播)的速度,并减少浏览器中的下载时间。 MobileNet接受
ILSVRC-2012-CLS图像分类
数据集的培训。
在开发具有学习转移的模型时,我们有两种选择:
- 源模型的哪一层用作目标模型的输入的输出。
- 我们将训练目标模型中的多少层(如果有)。
第一点非常重要。 根据所选层的不同,我们将以较低或较高的抽象水平获得要素,作为对神经网络的输入。
我们不会训练MobileNet的任何层。 我们从
global_average_pooling2d_1输出,并将其作为输入传递到我们的微型模型。 为什么选择此特定图层? 根据经验。 我做了一些测试,这一层工作得很好。
型号定义
最初的任务是将图像分为三类:手,脚和其他运动。 首先,让我们解决较小的问题:我们将确定框架中是否有手触。 这是一个典型的二进制分类问题。 为此,我们可以定义以下模型:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
这样的代码定义了一个简单的模型,一个具有
1024单元的层和
ReLU激活,以及一个通过
sigmoid激活
sigmoid输出单元。 后者给出一个从
0到
1 ,具体取决于该帧中手部打击的可能性。
为什么我选择
1024单元作为第二级且训练速度为
1e-6 ? 好吧,我尝试了几种不同的选择,并且发现这种选择效果最好。 Spear方法似乎并不是最好的方法,但是在很大程度上,这就是深度学习中超参数设置的工作方式-基于对模型的理解,我们使用直觉来更新正交参数并凭经验验证模型的工作方式。
compile方法将各层编译在一起,为训练和评估准备模型。 在这里,我们宣布我们要使用
adam优化算法。 我们还声明我们将根据交叉熵计算损失(损失),并表明我们要评估模型的准确性。 然后TensorFlow.js使用以下公式计算准确性:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)如果您从原始MobileNet模型转移培训,则必须首先下载它。 由于在浏览器中在超过3,000张图像上训练模型是不切实际的,因此我们将使用Node.js并从文件中加载神经网络。
在此处下载MobileNet。 目录包含文件
model.json ,其中包含模型的体系结构-层,激活等。 其余文件包含模型参数。 您可以使用以下代码从文件中加载模型:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
请注意,在
loadModel方法中
loadModel我们返回一个函数,该函数接受一维张量作为输入并返回
mn.infer(input, Layer) 。
infer方法采用张量和层作为参数。 该层确定我们要从哪个隐藏层输出。 如果打开
model.json并
global_average_pooling2d_1 ,则会在其中一层上找到这样的名称。
现在,您需要创建用于训练模型的数据集。 为此,我们必须将所有图像传递给MobileNet中的
infer方法,并为其分配标签:
1表示带有笔划的图像,
0表示没有笔划的图像:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
在上面的代码中,我们首先读取带有或不带有匹配项的目录中的文件。 然后我们确定包含输出标签的一维张量。 如果我们有
n带有笔触的图像和
m其他图像,则张量将包含
n元素的值为1,
m元素的值为0。
在
xs我们为单个图像添加了调用
infer方法的结果。 请注意,对于每个图像,我们都调用
readInput方法。 这是它的实现:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput首先调用
readImage函数,然后将其调用委托给
imageToInput 。
readImage函数从磁盘读取图像,然后使用
jpeg-js包从缓冲区解码jpg。 在
imageToInput我们将图像转换为三维张量。
结果,对于每个从
0到
TotalImages ys[i] ,如果
xs[i]对应于具有点击的图像,则
ys[i]等于
1 ,否则为
0 。
模型训练
现在该模型已准备好进行训练! 调用
fit方法:
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
上面的代码调用包含三个参数:
xs ,ys和配置对象。 在配置对象中,我们将设置训练模型的数量,数据包大小以及TensorFlow.js在处理每个数据包后将生成的回调的次数。
数据包大小决定了
xs和
ys以便在一个时代中训练模型。 对于每个时代,TensorFlow.js将从
ys选择
xs的子集和相应的元素,执行直接分配,以
sigmoid激活方式接收层的输出,然后基于损失,使用
adam算法执行优化。
启动训练脚本后,您将看到类似于以下结果:
成本:0.84212,精度:1.00000
eta = 0.3> ---------- acc = 1.00损失= 0.84成本:0.79740,准确性:1.00000
eta = 0.2 => --------- acc = 1.00损失= 0.80成本:0.81533,准确性:1.00000
eta = 0.2 ==> -------- acc = 1.00损失= 0.82成本:0.64303,准确性:0.50000
eta = 0.2 ===> ------- acc = 0.50损失= 0.64成本:0.51377,准确性:0.00000
eta = 0.2 ====> ------ acc = 0.00损失= 0.51成本:0.46473,准确性:0.50000
eta = 0.1 =====> ----- acc = 0.50损失= 0.46成本:0.50872,准确性:0.00000
eta = 0.1 ======> acc = 0.00损失= 0.51成本:0.62556,准确性:1.00000
eta = 0.1 =======> --- acc = 1.00损失= 0.63成本:0.65133,准确性:0.50000
eta = 0.1 =======>-acc = 0.50损失= 0.65成本:0.63824,准确性:0.50000
eta = 0.0 ===========>
293ms 14675us /步-acc = 0.60损耗= 0.65
时代3/50
费用:0.44661,准确性:1.000000
eta = 0.3> ---------- acc = 1.00损失= 0.45成本:0.78060,准确性:1.00000
eta = 0.3 => --------- acc = 1.00损失= 0.78成本:0.79208,准确性:1.00000
eta = 0.3 ==> -------- acc = 1.00损失= 0.79成本:0.49072,准确性:0.50000
eta = 0.2 ===> ------- acc = 0.50损失= 0.49成本:0.62232,准确性:1.00000
eta = 0.2 ====> ------ acc = 1.00损失= 0.62成本:0.82899,准确性:1.00000
eta = 0.2 =====> ----- acc = 1.00损失= 0.83成本:0.67629,准确性:0.50000
eta = 0.1 ======> ---- acc = 0.50损失= 0.68成本:0.62621,准确性:0.50000
eta = 0.1 =======> --- acc = 0.50损失= 0.63成本:0.46077,准确性:1.00000
eta = 0.1 =======>-acc = 1.00损失= 0.46成本:0.62076,准确性:1.000000
eta = 0.0 ===========>
304ms 15221us / step-acc = 0.85损耗= 0.63
请注意,随着时间的流逝,精度如何提高,而损耗却如何降低。
在我的数据集上,训练后的模型显示出92%的准确性。 请记住,由于训练数据集很少,因此准确性可能不是很高。
在浏览器中运行模型
在上一节中,我们训练了二进制分类模型。 现在,在浏览器中运行它并连接到
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
上面的代码中有几个声明:
video HTML5 videoLayer MobileNet,mobilenetInfer — , MobileNet . MobileNetcanvas HTML5 canvas ,scale — canvas ,
之后,我们从用户的摄像头获取视频流,并将其设置为element的源video。下一步是实现一个接受canvas并转换其内容的灰度滤镜: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
下一步,我们将模型与MK.js连接: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
在上面的代码中,我们首先加载上面训练的模型,然后下载MobileNet。我们将MobileNet传递给该方法,mobilenetInfer以获得从隐藏网络层计算输出的方法。之后,我们startInterval以两个网络作为参数调用该方法。 const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
最有趣的部分始于方法startInterval!首先,我们运行一个间隔,每个人都100ms调用一个匿名函数。在其中,canvas具有当前帧的视频首先在其顶部呈现。然后,我们将帧尺寸减小到,100x56并对其应用灰度滤镜。下一步是将帧传输到MobileNet,从所需的隐藏层获取输出,并将其作为输入传输到predict我们的模型方法中。这将返回具有一个元素的张量。使用,dataSync我们从张量获得值并将其分配给一个常量punching。最后,我们检查:如果触击的可能性超过0.4,则我们调用onPunchglobal object method Detect。 MK.js为全局对象提供了三种方法:onKick,onPunch而且onStand我们可以将其用于控制的人物之一。做完了!
结果就是这里!
具有N分类的脚踢和手臂识别
在下一部分中,我们将创建一个更智能的模型:识别出拳,脚踢和其他图像的神经网络。这次,让我们从准备训练集开始: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
和以前一样,我们首先阅读带有手,脚和其他图像的打孔图像的目录。此后,与上次不同,我们以二维张量而不是一维的形式形成预期结果。如果我们有Ñ图片包含有冲头,米图像与踢和ķ其他图像,张量ys将是n的值的元件[1, 0, 0],m与该值的元素[0, 1, 0]和k项具有值[0, 0, 1]。一个n元素向量,其中有n - 1一个具有值的元素和一个具有值的0元素1,我们称为a矢量(one-hot vector)。之后,我们形成输入张量xs堆叠来自MobileNet的每个图像的输出。在这里,您必须更新模型定义: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
与以前的模型仅有的两个区别是:输出层中有三个单位,因为我们有三种不同的图像类别:在这三个单元上触发激活softmax,这会将它们的参数转换为具有三个值的张量。为什么输出层需要三个单位?为三类的三个值中的每一个可以由两个比特表示:00,01,10。创建的张量值的总和softmax为1,也就是说,我们永远不会得到00,因此我们将无法对其中一个类别的图像进行分类。经过多年的训练500,我的准确率达到了约92%!这还不错,但是请不要忘记训练是在一个小的数据集上进行的。下一步是在浏览器中运行模型!由于逻辑与运行用于二进制分类的模型非常相似,因此请看最后一步,其中根据模型的输出选择操作: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
首先,我们将MobileNet的框架缩小为灰色阴影,然后再传递经过训练的模型的结果。模型返回一维张量,我们将其转换为Float32Arrayc dataSync。下一步,我们将Array.from类型化数组转换为JavaScript数组。然后,我们提取帧中存在用手,脚踢或不发球的概率。如果第三个结果的概率超过0.4,我们将返回。否则,如果发生踢的可能性更高0.32,我们会向MK.js发送一个踢命令。如果踢0.32的可能性越来越大,则我们发送踢的动作。一般来说,仅此而已!结果如下所示:
动作识别
如果您收集了大量有关手脚搏动的人的数据,则可以建立一个适用于各个框架的模型。但是够了吗?如果我们想走得更远并区分两种不同的踢法,该怎么办:转身和后卫(后踢)。从下面的框架中可以看出,在某个角度从某个角度的某个时间点,两个笔画看起来是相同的:
 但是如果您查看性能,则动作是完全不同的:
但是如果您查看性能,则动作是完全不同的: 如何训练神经网络来分析框架的序列,而不仅仅是一个框架?为此,我们可以探索另一类神经网络,称为递归神经网络(RNN)。例如,RNN非常适合处理时间序列:
如何训练神经网络来分析框架的序列,而不仅仅是一个框架?为此,我们可以探索另一类神经网络,称为递归神经网络(RNN)。例如,RNN非常适合处理时间序列:- 自然语言处理(NLP),其中每个单词都取决于前一个和后一个
- 根据您的浏览历史预测下一页
- 帧识别
实现这种模型不在本文讨论范围之内,但是让我们看一下示例架构,以了解所有这些如何协同工作。RNN的力量
下图显示了动作识别模型: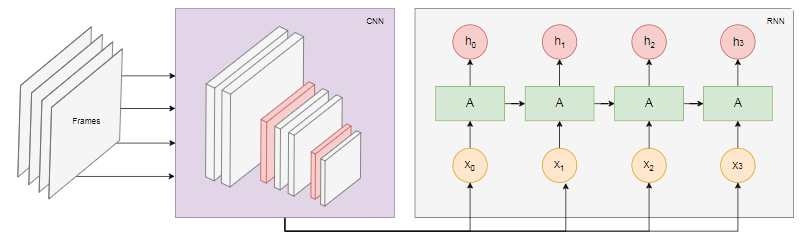 我们
我们n从视频中获取最后一帧并将其传输到CNN。每个帧的CNN输出作为输入RNN传输。循环神经网络将确定各个框架之间的关系,并识别它们对应的动作。结论
在本文中,我们开发了图像分类模型。为此,我们收集了一个数据集:我们提取了视频帧并将其手动分为三类。然后通过使用imgaug添加图像来增强数据。之后,我们解释了什么是学习转移,并使用了@ tensorflow-models / mobilenet软件包中训练有素的MobileNet模型来达到我们的目的。我们从Node.js进程中的文件加载了MobileNet,并训练了一个额外的密集层,该层从隐藏的MobileNet层馈送数据。经过培训,我们的准确率达到了90%以上!为了在浏览器中使用该模型,我们将其与MobileNet一起下载,并开始每100毫秒对用户网络摄像头中的帧进行分类。我们将模型与游戏连接MK.js并使用模型输出来控制字符之一。最后,我们研究了如何通过将模型与递归神经网络结合以识别动作来改进模型。希望您能像我一样喜欢这个小项目!