为什么某些API比其他API更方便使用? 作为我们的前端提供程序,我们可以使用质量可接受的API做什么? 今天,我将向Habr的读者介绍技术选择和组织措施,这些技术将帮助前端和后端提供商找到一种通用语言并建立有效的工作。

今年秋天,Yandex.Market年满18岁。 一直以来,市场的会员界面一直在开发中。 简而言之,这是管理面板,商店可以使用该面板上载目录,使用分类,跟踪统计信息,回复评论等。 该项目的细节使得您必须与各种后端进行大量交互。 但是,无法始终从一个特定的后端在一处获取数据。
问题症状
因此,想象一下,存在某种问题。 经理将任务交给设计师-他们绘制布局。 然后,他去了后端-他们制作了一些
笔,并在内部Wiki上写下了参数列表和响应格式。
然后,经理将“我为您带来了API”一词带到了前端,并提供了对所有内容进行快速脚本编写的方法,因为在他看来,几乎所有工作都已经完成。
您查看文档并看到以下内容:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors
没注意到什么奇怪的事吗? 一支笔的骆驼,蛇和烤肉串盒。 我不是在谈论fesh参数。 什么是肉? 这样的词甚至不存在。 打开扰流板之前,请尝试猜测。
扰流板Fesh是按商店ID过滤的。 您可以传递多个用逗号分隔的标识符。 ID前面可能带有减号,这意味着该存储应从结果中排除。
同时,当然,从JavaSctipt,我无法通过点分表示法访问此类对象的属性。 更不用说一个事实,如果您在一处拥有50个以上的参数,那么很显然,您一生中就会转向其他地方。
对于不方便的API,有很多选项。 一个经典示例-API搜索并返回结果:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null
如果找到货物,我们得到一个数组。 如果找到一种产品,那么我们将获得该产品的对象。 如果什么也没找到,那么充其量我们就是空的。 在最坏的情况下,后端的响应为404甚至400(错误请求)。
情况比较容易。 例如,您需要在一个后端获取存储列表,而在另一个后端获取存储设置。 在某些笔中,数据不足,在某些数据中,数据太多。 在客户端上过滤所有这些或发出多个ajax请求是一个坏主意。
那么该问题的解决方案是什么? 作为我们的前端提供程序,我们可以使用质量可接受的API做什么?
前端后端
我们在合作伙伴界面中使用React / Redux客户端。 客户端下面是Node.js,它执行许多辅助操作,例如,将其扔到Editors的InitialState页面。 如果您具有服务器端渲染,则与哪个客户端框架(最可能是由节点渲染)无关紧要。 但是,如果您走得更远,不直接在后端与客户端联系,而是在节点上使代理API最大限度地满足客户需求,该怎么办?
此技术称为BFF(后端后端)。 该术语由 SoundCloud于2015年首次引入 ,其构想可如下所示:
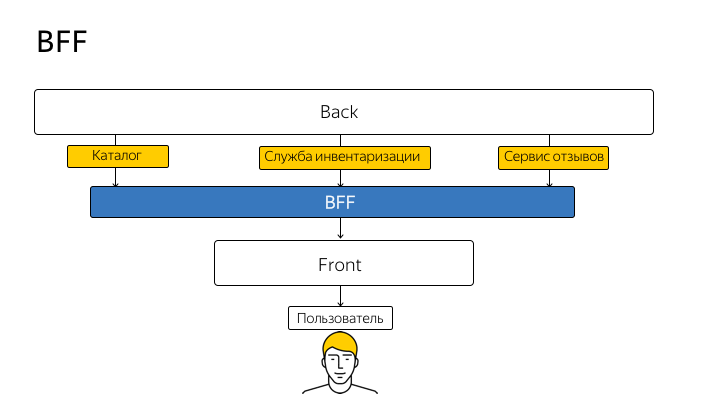
因此,您将不再直接从客户端代码转到API。 您在节点上以及从客户端复制的真实API的每个句柄,每种方法都专门移至该节点。 并且该节点已经将该请求代理到了真正的API,并向您返回了响应。
这不仅适用于原始的get-request,而且通常适用于所有请求,包括multipart / form-data。 例如,商店通过站点上的表单上载带有目录的.xls文件。 因此,在此实现中,该目录不是直接加载到API中,而是直接加载到您的Nod句柄中,该代理将流到真正的后端。
还记得后端返回null,数组或对象的结果示例吗? 现在,我们可以将其恢复到正常状态,如下所示:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response }
这段代码看起来很糟糕。 因为他太可怕了。 但是我们仍然需要这样做。 我们可以选择:在服务器或客户端上执行此操作。 我选择一台服务器。
我们还可以以方便我们的方式映射所有这些烤肉串和蛇形情况,并在必要时立即记下默认值。
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, }
我们还能获得什么其他优势?
- 过滤 。 客户只收到他所需要的东西,没有更多,也没有更少。
- 汇总 无需浪费客户端网络和电池来进行多个ajax请求。 由于打开连接是一项昂贵的操作,因此速度明显提高。
- 快取 您重复的汇总呼叫不会再拉任何人,而只会返回304 Not Modified。
- 数据隐藏 。 例如,您可能有后端之间需要的令牌,不应将其传递给客户端。 客户可能甚至无权知道这些令牌的存在,更不用说其内容了。
- 微服务 。 如果您背面有一个整体,那么BFF是微服务的第一步。
现在,关于缺点。
- 难度越来越大。 任何抽象都是需要编码,部署和支持的另一层。 该机制的另一个活动部分可能会失败。
- 句柄重复 。 例如,多个端点可以执行相同类型的聚合。
- BFF是边界层 ,应支持常规路由,用户权限限制,查询日志记录等。
要消除这些缺点,只需遵守简单的规则即可。 首先是将前端和业务逻辑分开。 您的BFF不应更改核心API的业务逻辑。 其次,您的图层仅应在绝对必要时转换数据。 我们不是在谈论一个自包含的综合API,而只是在讨论一种填补空白,纠正后端缺陷的代理。
GraphQL
GraphQL解决了类似的问题。 使用GraphQL,您可以拥有一支可以处理复杂查询并以客户端请求的形式生成数据的智能笔,而不是许多“愚蠢”的端点。
同时,GraphQL可以在REST之上运行,即数据源不是数据库,而是其余API。 由于GraphQL具有声明性,因此所有这些都是React和Editors的朋友,因此您的客户变得更加轻松。
实际上,我将GraphQL视为具有其协议和严格查询语言的BFF的实现。
这是一个很好的解决方案,但是它有几个缺点,特别是在类型化,权限区分方面,总的来说这是一个相对较新的方法。 因此,我们还没有切换到它,但是在将来,对我来说,这似乎是创建API的最佳方法。
永远最好的朋友
没有组织的更改,任何技术解决方案都无法正常工作。 您仍然需要文档,保证响应格式不会突然改变,等等。
应该理解,我们都在同一条船上。 对于抽象的客户,无论是经理还是经理,总的来说,这没有什么区别-您那里有GraphQL或BFF。 对他而言,更重要的是要解决问题并且产品上不会出现错误。 对于他来说,由于产品的错误是由谁的错引起的,差异不大-通过正面或背面的错。 因此,您需要与支持者进行协商。
另外,我在报告开头提到的背面缺陷并非总是由于某人的恶意行为而出现。 fesh参数可能也具有某些含义。

注意提交的日期。 事实证明,最近的一次庆祝是十七岁生日。
在左侧看到一些奇怪的标识符? 这是SVN,仅是因为2001年没有gita。 不是将github作为服务,而是将gith作为版本控制系统。 他只在2005年出现。
该文件
因此,我们所需要的不是与后端争吵,而是要达成共识。 只有找到一个单一的真理来源,才能做到这一点。 该来源应为文档。
这里最重要的是在开始使用功能之前先编写文档。 与婚前协议一样,最好就岸上的一切达成协议。
如何运作? 相对而言,三个要去:管理器,前端和后端。 Fronteder精通主题领域,因此他的参与至关重要。 他们收集并开始考虑API:以什么方式,应该返回什么答案,直到字段的名称和格式。
招摇
API文档的一个很好的选择是Swagger格式,现在称为OpenAPI。 最好以YAML格式使用Swagger,因为与JSON不同,它可以被人类更好地读取,但是对于机器而言没有任何区别。
结果,所有协议都以Swagger格式固定并发布在一个公共存储库中。 销售后端的文档必须在向导中。
主服务器受到保护,不会提交,代码仅通过请求池进入,您无法将其压入。 前线团队的代表有义务对请求池进行审查,如果不升级,则代码不会交给主数据库。 这样可以保护您避免API意外更改,恕不另行通知。
Swagger写到了,你们聚在一起,所以您实际上签署了合同。 从这一刻起,您作为前端就可以开始工作,而不必等待真正的API的创建。 毕竟,如果我们不能并行工作并且客户端开发人员必须等待服务器开发人员,那么客户端和服务器之间的分离点是什么? 如果我们有一个“合同”,那么我们就可以放心地解决这个问题。
Faker.js
法克(Faker )非常适合这些目的。 这是一个用于生成大量假数据的库。 它可以生成不同类型的数据:日期,名称,地址等,所有这些都已本地化,并且支持俄语。
同时,伪造者是招摇的朋友,您可以冷静地举起Mock服务器,该服务器基于Swagger方案,将以必要的方式为您生成伪造的答案。
验证方式
可以将Swagger转换为json方案,并借助ajv之类的工具,您可以在运行时,在BFF中直接验证后端响应,并在有差异的情况下报告测试人员,backender本身。
假设测试人员在网站上发现某种错误,例如,单击按钮时什么都没有发生。 测试员做什么? 他在前端放了一张票:“这是您的按钮,没有被按下,请修理。”
如果您和后面之间有一个验证器,那么测试人员将知道该按钮实际上已被按下,只是后端发送了错误的答案。 错误的-这是前线不期望的响应,也就是说,它与“合同”不符。 在这里,已经有必要修理后背或更改合同。
结论
- 我们积极参与API的设计。 我们设计API,以便在17年后可以方便使用。
- 我们需要Swagger文档。 没有文档-后端操作尚未完成。
- 有文档-我们将其发布在git中,并且API的任何更改均应由前团队代表进行更新。
- 我们提出了伪造的服务器,并开始在前端工作,而无需等待真正的API。
- 我们将节点放在前端之下,并验证所有答案。 另外,我们还具有聚合,规范化和缓存数据的能力。
另请参阅
→ 如何在大型项目中构建类似REST的API
→ 前端后端
→ 使用GraphQL作为BFF模式实现