引言
自从文章发表以来,已经有四个月的时间了,这是关于我对底层
树的底层实现的尝试。 尽管我付出了所有努力,但我之前对前缀树的实现才能够达到的上限是每秒8万个单词。 然后,我花费了大量时间和精力,但结果只适合作为计算机科学的实验室工作。
然后许多人告诉我:“不要发明我们已经发明的自行车! 使用交钥匙解决方案。 困难在于我无法使用至少在一般意义上无法理解的东西。
我想我了解了前缀树,这就是我设法实现的目标。
工作原理
我不太会英文,所以在我读过的很多有关前缀树的文章中,有些信息可能没听懂。 因此,我想出了如何安排所有内容的方法,仅了解前缀树的基本原理。 对于那些不知道的人,我将比起在Wikipedia上更清楚地描述它。 所以我向妻子解释了我在做什么。
前缀树是一种逻辑结构,用于存储可以表示为图书馆书本卡片索引的数据。 每个盒子都有一个数字。 每个框对应一个特定的字母。 里面是以下抽屉的编号,您可以找到以下打开的抽屉,依此类推。 如果框内没有任何内容,则表示此框的字母是单词的最后一个字母。 问题在于某些框几乎保持为空,因为它们包含1或2个数字,而剩余空间为空。
为了解决这个问题,出现了多种前缀树,包括:HAT-trie,双数组trie,tripple-array trie。 正是由于我不能完全理解他们的工作原理,使我像一本图书馆证件卡一样简单。
上一次我设法实现一个简单的前缀树的相当经济的内存消耗实现。 继续使用图书馆卡索引这个比喻,我在文件柜中制作了不同尺寸的抽屉,对于整个字母来说,盒子是最大的,对于1个字母来说是最小的。
我设法用C实现了完全相同的PHP方案。
1.根据已建立的表,单词的每个字母都使用2到95之间的数字进行编码。例如,单词“ abv”使用3个数字进行编码:11、12、13。为了获得最佳性能,使用了二维数字数组,
uint8_t abc[256][256] = {};为1个字节
uint8_t abc[256][256] = {}; 要转换程序,它将读取1字节的行,并尝试获取数组中每个字节的值。 例如,数字代码是1 = 49,所以我们看
abc[49][0]; 。 如果存在'\ 0'以外的其他值,则这是我们字母的代码,请记住并转到下一个字节。 在我们的例子中,单词“ abv”由6个字节的序列组成,每个字母两个字节:208、176、208、177、208、178。由于utf-8编码的设计是使单字节字符的第一个字节与多字节的第一个字节不重合,在我们的数组
abc[208][0] = 0; 。
但是,对于字节对,存在一些匹配项:
/* [11] */ abc[208][176] = 11; /* [12] */ abc[208][177] = 12; /* [13] */ abc[208][178] = 13;
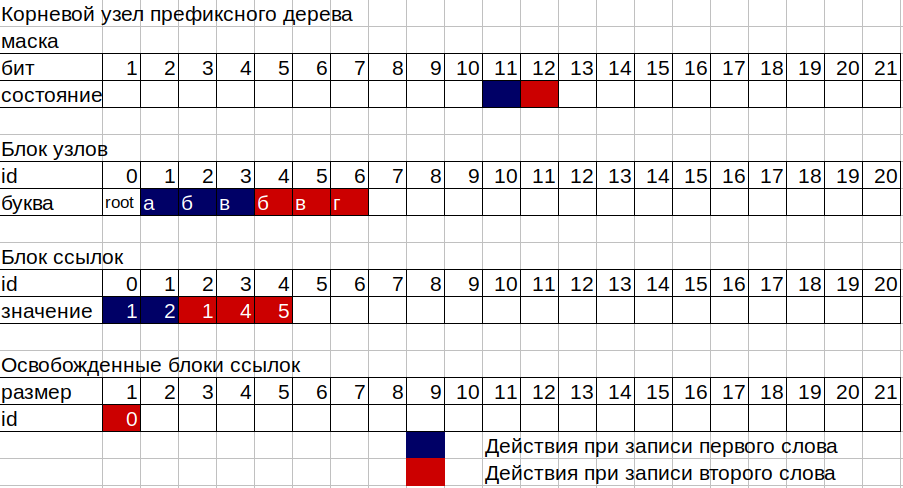
2.现在我们需要在树的框中写下数字11、12和13。 该树由2个单独的非爆炸性内存块组成,第一个是节点块,第二个是链接块,以及两个被占用节点和一个链接块的被占用单元的计数器。 每个树节点由16个字节,12个字节的位掩码和4个字节组成,用于存储链接块的ID。 掩码允许您存储2到96位的数字。 掩码的第一位用于标记该节点上单词的结尾。 如果在该节点中至少写入了一个字母,则每个节点都可以对应于链接块中的id,或者如果该节点在树上是“叶子”,则该节点不对应,也就是说,一个单词简单地以其结尾。 在图书馆里表示,一个空的抽屉。
3.取得第一个(根)节点的掩码。 trie->节点[0] .mask; 我们从第二个(字尾标志的第一个)开始,计算该掩码中的上升位。 如果掩码中的所有位均未升高,即 由于该节点为空,因此我们需要一个大小为1的链接块来存储我们的数字11,从该块的链接引用计数器中获取数字,并将旧值增加1(因为我们需要大小1)。 我们从节点计数器中获取数字,还将旧值增加1。在我们的根节点中写入链接块id,即从链接块计数器获得的数字。 然后在链接块的该ID中,写入新节点的ID,即从节点计数器获得的编号。 现在,除了根节点(id 0)之外,我们还有一个字母为“ a”(id 1)的节点。 要写与字母“ b”相对应的数字12,我们要做的是相同的,但要加上字母“ a”的节点。
4.在最后一个字母“ c”上,我们不需要在链接块中放置任何位置,因为我们将在分支或节点-工作表上拥有最后一个节点。 这样的节点在提升的掩码中只有1位。
5.树的工作中最困难的部分发生在将树写入已写入一些字母的节点上时。 在这种情况下,操作方案如下:
假设我们要在树中添加单词“ bvg”(12、13、14),其中已经写入了单词“ abv”(11、12、13)。 我们将根节点掩码中的位数计算为我们感兴趣的字母的位数。 我们使用带代码12的字母“ b”,这意味着该字母的位是12,在从1到12位的掩码中,已经提高了字母“ a”的位11。 因此,我们有了根节点1的链接块的当前大小。我们写了第二个字母,所以现在我们需要一个大小为2的链接块。这里释放块的注册表开始起作用,节点不再使用链接块中各节的ID和大小树。 我们用于大小为1的根节点的链接块的旧ID刚刚进入大小为1的空闲段的注册表中,因为我们的根节点需要更大的大小。 我们的注册表没有合适的大小为2的部分,我们再次将链接块的计数器中的值用作链接块的新ID,将计数器增加2。在链接块的新地址上,按照位在节点掩码中的排列顺序,写入ID值旧链接块的第一个单词的字母“ a”节点和第二个单词的字母“ b”的刚创建节点的值。
工作速度
鼓声响起……还记得最后的结果吗? 每秒约8万个字。 该树是由所有俄语单词OpenCorpora 3 039 982的词典创建的。 这是现在发生的事情:
yatrie creation time: 4.588216s (666k wps) yatrie search time 1 mln. rounds: 0.565618s (1.76m wps)
更新11/01/2018:在0.0.2版中,可以通过将完整的函数替换为宏函数,以及将节点掩码的结构更改为uint32_t mask [3](以前是uint8_t mask [12])来将速度提高近2倍。
在可能的情况下,还添加了宏LIKELY()UNLIKELY()来预测那些if()块中的预期结果。
更新11/05/2018:扭曲多一点。 即使编译-O3和-Ofast,我也设法使其正常工作。 树中的搜索速度为每100万次重复〜0.2μs或0.2c。 显然,此速度是由于过渡到不同格式的蒙版而获得的。 以前有12个字节的8位,现在是3个int32,这是一个非常快速的函数,用于计算int32中的位。
这有多紧凑?
指定的OpenCorpora词典大约需要84MB,这并不比libdatrie大约80MB差。
→
源代码欢迎光临