使用新的TL-GAN进行受控的图像合成和编辑 我的TL-GAN模型中的受控合成示例(透明潜在空间GAN,具有透明隐藏空间的生成竞争网络)项目页面
我的TL-GAN模型中的受控合成示例(透明潜在空间GAN,具有透明隐藏空间的生成竞争网络)项目页面上提供了所有代码和在线演示。
我们按照说明训练计算机拍照
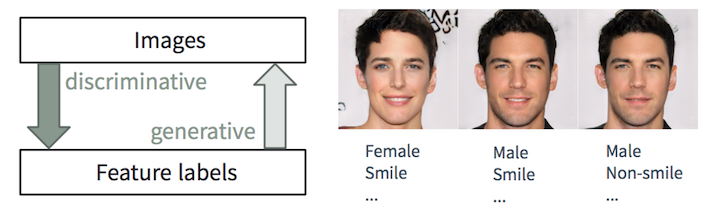 判别和生成任务
判别和生成任务一个人
描述图片很容易,我们从很小的时候就开始学习。 在机器学习中,这是
判别分类/回归的任务,即 根据输入图像预测特征。 ML / AI方法(尤其是深度学习模型)的最新进展开始在这些任务中脱颖而出,有时达到或超过人类的能力,如对对象的视觉识别(例如,根据ImageNet分类从AlexNet到ResNet)和检测/分割等任务所示对象(例如,从COCO数据集中的RCNN到YOLO)等。
然而,从描述中
创建逼真的图像的逆任务要复杂得多,并且需要多年的图形设计培训。 在机器学习中,这是一个
生成任务,比区分性任务要复杂得多,因为生成模型应基于较小的初始数据生成更多信息(例如,在特定级别的细节和变化下的完整图像)。
尽管创建此类应用程序很复杂,但
生成模型 (带有某些控件)在许多情况下仍然非常有用:
- 内容创建 :想象一家广告公司自动创建与插入这些图像的网页的内容和样式相匹配的有吸引力的图像。 设计师通过命令算法生成20种与“休息”,“夏季”和“热情”标志相关的鞋子图案来寻求灵感。 新游戏允许您通过简单的描述生成逼真的头像。
- 基于内容的智能编辑 :只需单击几下,摄影师即可更改面部表情,皱纹和发型。 好莱坞工作室的一位艺术家将在阴天傍晚拍摄的照片转换为好像在一个明亮的早晨拍摄的照片,并在屏幕的左侧显示阳光。
- 数据增强 :无人机开发人员可以为特定事故场景合成逼真的视频,以增加训练数据集。 银行可以合成在现有数据集中表现不佳的某些类型的欺诈数据,以改进反欺诈系统。
在本文中,我们将讨论我们最近的工作,即
透明潜在空间GAN(TL-GAN) ,它扩展了大多数现代模型的功能,并提供了一个新的接口。 我们目前正在处理一个文档,其中将包含更多技术细节。
生成模型概述
深度学习社区正在迅速改善生成模型。 下图显示了三种有希望的类型:
自回归模型 ,
变分 自 编码器(VAE)和
生成对抗网络(GAN) 。 如果您对这些细节感兴趣,请阅读优秀的OpenAI博客
文章 。
 生成网络的比较。 滑铁卢大学STAT946F17课程图片
生成网络的比较。 滑铁卢大学STAT946F17课程图片目前,
最优质的图像是由GAN网络生成的(照片逼真且多样化,并具有令人信服的高分辨率)。 看看Nvidia令人惊叹的pg-GAN(
渐进式GAN )网络。 因此,在本文中,我们将重点介绍GAN模型。
 Nvidia生成的合成pg-GAN 。 没有图像与现实有关。
Nvidia生成的合成pg-GAN 。 没有图像与现实有关。GAN模型问题管理
 随机和受控图像生成GAN的原始版本
随机和受控图像生成GAN的原始版本和基于它的许多流行模型(例如
DC-GAN和
pg-GAN )都是
没有老师的教学模型。 训练后,生成神经网络将随机噪声作为输入,并创建与训练数据集几乎无法区分的真实感图像。 但是,我们无法额外控制生成的图像的特征。 在大多数应用程序中(例如,在第一部分中描述的场景中),用户希望创建具有
任意属性 (例如,年龄,头发颜色,面部表情等)的模式。理想情况下,应平稳地配置每个功能。
已经为这种受控合成创建了许多GAN变体。 它们可以有条件地分为两种类型:样式传递网络和条件生成器。
样式转移网络
经过训练的
CycleGAN和
pix2pix样式传输
网络可以将图像从一个区域(域)传输到另一区域(例如,从马到斑马,从草图到彩色图像)。 结果,我们无法在两个离散状态之间平滑地更改特定符号(例如,在脸上添加一些胡须)。 另外,一个网络被设计用于一种类型的传输,因此将需要十个不同的神经网络来配置十个功能。
条件发生器
条件生成器-
条件GAN ,
AC-GAN和Stack-GAN-在训练过程中,同时研究对象的图像和标签,这使您可以使用属性设置来生成图像。 当您想在生成过程中添加新功能时,您需要重新训练整个GAN模型,这需要大量的计算资源和时间(例如,在具有理想超参数集的同一个K80 GPU上,从几天到几周)。 此外,要完成训练,有必要依靠一个包含所有用户定义的对象标签的数据集,而不要使用来自多个数据集的不同标签。
我们具有透明隐藏空间的生成竞争网络(
透明潜在空间GAN ,TL-GAN)采用了不同的方法进行受控发电-并解决了这些问题。 它提供了
使用单个网络无缝配置一个或多个功能的能力。 此外,您可以在不到一小时的时间内有效地添加新的自定义功能。
TL-GAN:一种有效的受控合成和编辑新方法
使这个神秘的透明隐藏空间
取自Nvidia的pvGAN模型,该模型生成高分辨率的人脸逼真图像,如上一节所示。 生成的1024×1024px图像的所有功能都完全由隐藏空间中的512维噪声矢量确定(作为图像内容的低维表示)。 因此,
如果我们了解构成隐藏空间的内容(即使其透明),那么我们就可以完全控制生成过程 。
 TL-GAN的动机:了解管理生成过程的隐蔽空间
TL-GAN的动机:了解管理生成过程的隐蔽空间通过对预训练的pg-GAN网络进行实验,我发现隐藏空间实际上具有两个良好的属性:
- 它被很好地填充,也就是说,空间中的大多数点都会生成合理的图像。
- 这是非常连续的,也就是说,隐藏空间中两点之间的插值通常会导致相应图像的平滑过渡。
直觉说,在隐藏空间中,有一些方向可以预测我们需要的属性(例如,男人/女人)。 如果是这样,那么这些方向的单位矢量将成为控制生成过程的轴(更男性化或更女性化的脸部)。
方法:特征轴扩展
为了在隐藏空间中找到这些属性轴,
我们在隐藏向量之间构造了一个连接 ž 和标签标签 ÿ 成对使用教师培训
( Z , y ) 。 现在的问题是如何获取这些对,因为现有数据集仅包含图像
X 和相应的对象标签
ÿ 。
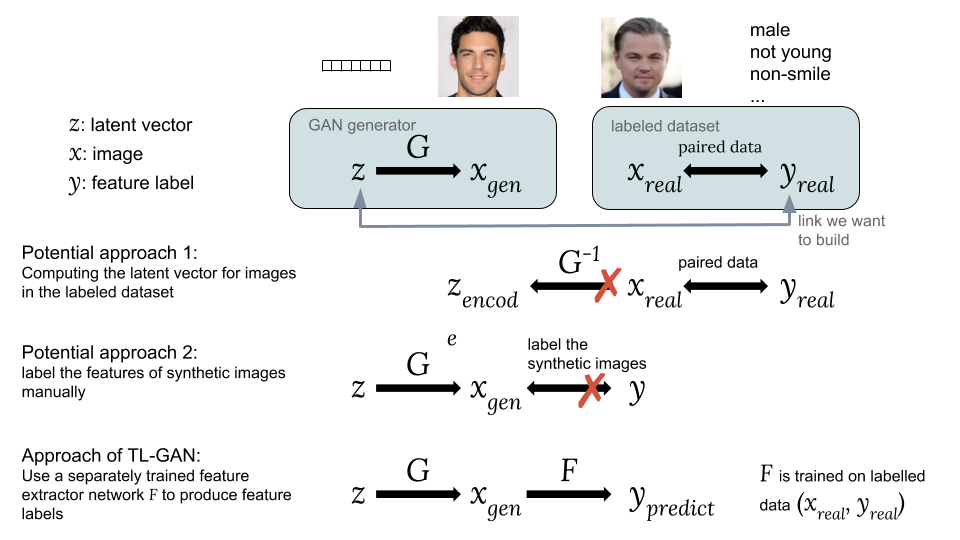 将隐藏向量z与标签y关联的方法可能的方法:一种选择是计算相应的隐藏向量 ž 图片 X - [R ë 一个升 从具有我们感兴趣的标签的现有数据集中 ÿ ř Ë 一个升 。 但是,GAN无法提供一种简便的方法来计算 z e n c o d e = G - 1 x r e a l ,因此很难实现这个想法。
将隐藏向量z与标签y关联的方法可能的方法:一种选择是计算相应的隐藏向量 ž 图片 X - [R ë 一个升 从具有我们感兴趣的标签的现有数据集中 ÿ ř Ë 一个升 。 但是,GAN无法提供一种简便的方法来计算 z e n c o d e = G - 1 x r e a l ,因此很难实现这个想法。
第二个选项是生成合成图像 X 克ë Ñ 使用来自随机隐藏向量的GAN ž 怎么 x g e n = G ( z ) 。 问题在于合成图像没有被标记,因此很难使用一组可访问的标记数据。TL-GAN模型的主要创新是使用该模型
训练了一个单独的提取器 (用于离散标签的分类
器或用于连续标签的回归器)
Y = f ( x ) 使用一组现有的标记数据(
X - [R ë 一个升 ,
ÿ ř Ë 一个升 ),然后在一群训练有素的GAN发电机中启动
g ^ 带有特征提取网络
˚F 。 这使您可以预测特征标签。
ÿ p - [R È d 合成图像
X 克ë Ñ 使用训练有素的特征提取网络(提取器)。 因此,通过合成图像,在
ž 和
ÿ 怎么
x g e n = G ( z ) 和
y p r e d = F (x g e n) 。
现在我们有了配对的隐藏矢量和特征。 您可以训练回归模型
y = A ( z ) 打开特征的所有轴以控制图像生成过程。
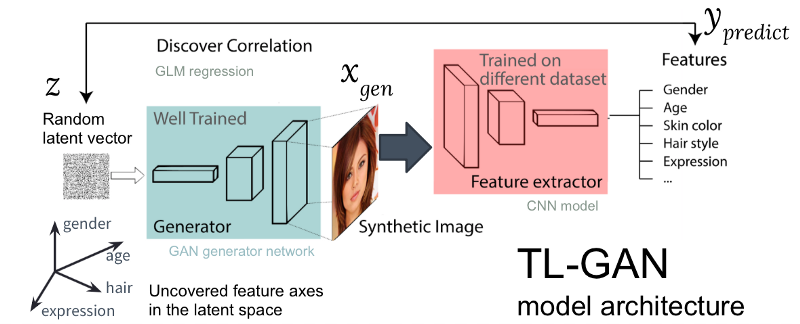 图:我们的TL-GAN模型的架构
图:我们的TL-GAN模型的架构上图显示了TL-GAN模型的体系结构,其中包含五个步骤:
- 分布研究 。 我们选择训练有素的GAN模型和生成网络。 我选择了训练有素的pg-GAN(来自Nvidia),该产品可提供最优质的人脸识别。
- 分类 。 我们选择一个预先训练的模型来提取属性(提取器可以是卷积神经网络或其他计算机视觉模型),也可以使用一组标记数据来训练我们自己的提取器。 我使用CelebA套件训练了一个简单的卷积神经网络(带有40个标签的30,000张面孔)。
- 代 。 我们创建了几个随机的隐藏矢量,通过训练有素的GAN生成器创建合成图像,然后使用训练有素的特征提取器在每个图像上生成特征。
- 相关性 。 我们使用广义线性模型(GLM)来实现隐藏矢量和特征之间的回归。 回归线的斜率成为特征的轴 。
- 研究 。 我们从一个隐藏的矢量开始,沿着符号的一个或几个轴移动它,并研究它如何影响图片的生成。
我极大地优化了该过程:在经过预训练的GAN模型上,在具有一个GPU的计算机上识别特征轴
仅需一个小时 。 这可以通过多种工程技巧来实现,包括传递训练,减小图片大小,初步缓存合成图像等。
结果
让我们看看这个简单的想法是如何工作的。
沿对象的轴移动隐藏的矢量
首先,我检查了检测到的特征轴是否可以用于控制生成图像的相应特征。 为此,创建一个随机向量
ž 0 在GAN的隐藏空间中生成合成图像
x 0 通过生成网络
x 0 = G (z 0 ) 。 然后我们沿着特征的一个轴移动隐藏的向量
ü (例如,对应于面部性别的隐藏空间中的单位矢量)
λ 到新的位置
X 1 = X 0 + λ Ü 并生成新图像
x 1 = G (z 1 ) 。 理想情况下,新图像的相应特征应沿预期方向更改。
沿属性的几个轴(性别,年龄等)移动向量的结果如下所示。 它出奇的好! 您可以在男人/女人,年轻人/老人等之间
顺畅地变换图像。
 沿缠结的特征轴移动隐藏矢量的第一个结果
沿缠结的特征轴移动隐藏矢量的第一个结果分解相关特征轴
在上面的示例中,原始方法的缺点显而易见,即属性的混淆轴。 例如,当需要减少面部毛发时,生成的脸部将变得更加女性化,这不是预期的结果。 问题在于性别和胡须是内在
关联的 。 一个特征的改变导致另一个特征的改变。 其他功能也发生了类似的情况,例如头发和卷发。 如下图所示,隐藏空间中“胡须”属性的原始轴不垂直于“地板”轴。
为了解决这个问题,我使用了简单线性代数的技术。 特别是,他将胡须的轴投影到与地板的轴正交的新方向,这有效地消除了它们之间的相关性,因此有可能在生成的面上解开这两个信号。
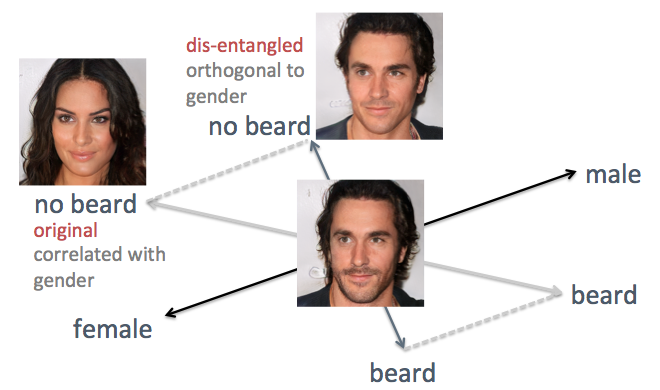 用线性代数技术分解相关特征轴
用线性代数技术分解相关特征轴我将此方法应用于同一个人。 这次,选择性别和年龄轴作为支持轴,并投影所有其他轴,使它们与性别和年龄正交。 通过沿新生成的特征轴移动隐藏矢量来生成人脸(如下图所示)。 不出所料,现在的发型和胡须等标志不会影响地板。
 沿不纠结的特征轴移动隐藏矢量的改进结果
沿不纠结的特征轴移动隐藏矢量的改进结果灵活的交互式编辑
为了查看我们的TL-GAN模型如何灵活地控制图像生成过程,我创建了一个交互式图形界面,其对象值沿不同轴的平滑变化,如下所示。
使用TL-GAN进行交互式编辑同样,如果您沿标志轴更改图像,该模型将出奇地好!
总结
该项目演示了一种无需老师就可以管理生成模型的新方法,例如GAN(生成对抗网络)。 使用预训练的GAN发生器(Nvidia的pg-GAN),我通过显示重要特征的轴来使其隐藏空间透明。 当矢量在隐藏空间中沿着这样的轴移动时,相应的图像将沿着此特征进行变换,从而提供受控的合成和编辑。
此方法具有明显的优点:
- 效率:无需为生成器添加新的功能调谐器,就不需要重新训练GAN模型,因此为40个功能添加调谐器所需的时间不到一个小时。
- 灵活性:您可以使用在任何数据集上受过训练的任何特征提取器,为经过良好训练的GAN添加更多特征。
关于道德的几句话
这项工作使您可以详细控制图像的生成,但是在很大程度上仍取决于数据集的特征。 对好莱坞明星照片进行培训意味着该模型将很好地生成大多数白人和有魅力的人的照片。 这将导致以下事实:用户将能够创建仅代表人类一小部分的面孔。 如果您将此服务部署为实际应用程序,建议考虑到用户的多样性,扩展原始数据集。
尽管该工具可以在创作过程中提供很大帮助,但您需要记住有关将其用于不恰当目的的可能性。 如果我们创建任何类型的逼真的面孔,那么我们在多大程度上可以信任我们在屏幕上看到的人? 今天,重要的是要讨论这类问题。 正如我们在
Deepfake技术的最新示例中看到的
那样 ,人工智能正在快速发展,因此对于人类来说,开始讨论如何最佳部署此类应用程序至关重要。
在线演示和代码
这项工作的所有代码和在线演示都可以在
GitHub页面上
找到 。
如果要在浏览器中使用模型
您无需下载代码,模型或数据。 只需按照
本自述文件
部分中的说明进行操作即可。 您可以在浏览器中更改面孔,如视频所示。
如果您想尝试代码
只需转到GitHub存储库的自述页面。 使用Tensorflow和Keras在Anaconda Python 3.6上编译的代码。
如果你想贡献
欢迎光临 随时在GitHub上提交池请求或报告问题。
关于我
我最近从布朗大学获得了计算和认知神经生物学博士学位,并获得了计算机科学的硕士学位,并专门研究了机器学习。 过去,我研究了大脑中的神经元如何共同处理信息以实现高级功能,例如视觉感知。 我喜欢算法方法来分析,模拟和实现智能,以及喜欢使用AI解决实际的复杂问题。 我正在积极寻找技术行业的ML / AI研究人员。
致谢
作为
InSight AI奖学金计划的一个项目,这项工作在三周内完成。 我感谢程序主管
Emmanuel Amaisen和
Matt Rubashkin的总体领导,尤其是Emmanuel的建议和文章的编辑。 我还要感谢所有Insight员工的出色学习环境以及我从中学到很多的其他Insight AI计划参与者。
特别感谢鲁宾·夏(Rubin Xia)提供的许多提示和启发,这些想法和启发使我决定了该项目的开发方向,并为本文的结构设计和编辑提供了巨大帮助。