尽管现代数据中心具有可靠性,但关键设施仍需要另一个关键级别的冗余,因为整个IT基础架构可能会由于人为或自然灾害而发生故障。 为了确保容灾能力,有必要建立备份数据中心。 在削减的范围内,我们讲述了由于它们的组合(DCI-数据中心互连)而产生的问题。
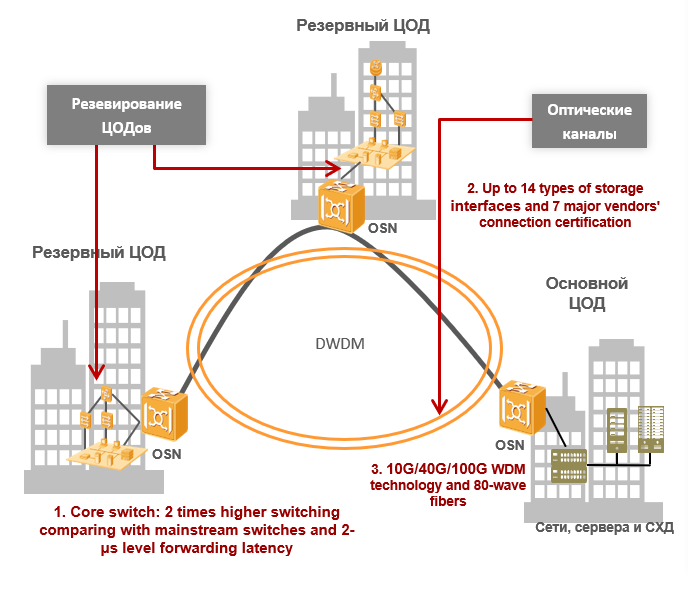
人类处理的数据量已增长到令人难以置信的价值,而且IT基础架构在业务流程中的作用是如此之大,以至于即使是短期故障也可能使公司完全瘫痪。 数字技术正在无处不在,金融,电信或大型互联网零售等都特别依赖数字技术。 对于大型云提供商,银行或大型电信运营商而言,数据中心的可靠性是不够的:小型停机所造成的损失可以用天文数字来计算,为了避免这种情况,需要一个抗灾基础设施。 您只能通过增加冗余来创建它-您必须构建备份数据中心。
将高可用性与灾难恢复分开
可以合并安装在租用场所中的公司数据中心或设备。 地理分布解决方案的容错能力是通过软件体系结构实现的,所有者可以节省自己的设施:他们不需要构建数据中心,例如Tier III或Tier II级别。 您可以放弃柴油发电机,使用开放式服务器,在极端温度条件下玩,并做一些有趣的技巧。 租用区域的自由度较少,提供商在这里确定游戏规则,但是统一的原则是相同的。 在讨论抗灾IT服务之前,值得回顾一下三个神奇的缩写:RTO,RPO和RCO。 这些关键绩效指标确定了IT基础架构抵御破坏的能力。
RTO(恢复时间目标)-事件发生后恢复IT系统的允许时间;
RPO(恢复点目标)-灾难恢复期间可接受的数据丢失。 通常将其度量为数据丢失的最长时间;
RCO(恢复容量目标)是备份系统可以承担的IT负载的一部分。 后一个指标可以百分比,交易和其他“鹦鹉”来衡量。
在此处区分高可用性(HA)和灾难恢复(DR)解决方案非常重要。 它们之间的差异可以通过以RPO和RTO为坐标轴的图表的形式来可视化:
理想情况下,我们不会丢失数据,也不会浪费时间从故障中恢复,并且备份站点将确保服务的全部功能,即使主要的服务已被破坏。 只有通过数据中心的同步运行,才能实现零RTO和RPO:实际上,它是具有实时数据复制和其他乐趣的地理分布的故障安全群集。 在异步模式下,不再保证数据完整性:由于复制是定期进行的,因此某些信息可能会丢失。 在这种情况下,切换到备份站点的时间从几分钟到几小时不等。 冷储备,当大多数备用设备关闭且不耗电时。
技术细节
合并两个或多个数据中心时出现的技术困难分为三类:数据传输延迟,通信通道带宽不足以及信息安全问题。 数据中心之间的通信通常由它们自己的或租用的光纤通信线路提供,因此我们将在后面讨论。 对于以同步模式运行的DPC,主要问题是延迟。 为了确保实时数据复制,它们不应超过20毫秒,有时不应超过10毫秒-这取决于应用程序或服务的类型。
否则,例如,光纤通道协议家族将无法工作,而如果没有现代存储系统,这几乎是不可能的。 在那里,速度越高,延迟应该越短。 当然,有一些协议可以让您通过以太网与存储网络一起工作,但在这里很大程度上取决于数据中心中的应用程序和已安装的设备。 以下是常见Oracle和VMware应用程序的延迟要求示例:
Oracle扩展距离群集延迟要求:
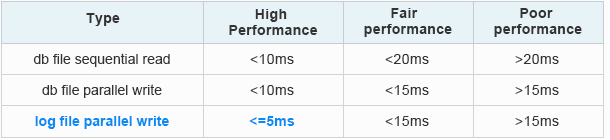 从Oracle官方数据看:如何判断数据库的IO是否缓慢[ID 1275596.1]
从Oracle官方数据看:如何判断数据库的IO是否缓慢[ID 1275596.1]VMware延迟要求:
 VMware vSphere Metro存储集群案例研究(VMware vSphere 5.0)
VMware vSphere Metro存储集群案例研究(VMware vSphere 5.0)
传输数据时,信号延迟可以用两个分量表示:T
total = T
equip。 + T
s T
等于 -由信号通过设备引起的延迟和T
s-由信号通过光纤引起的延迟。 信号通过设备(T
equipment )所引起的延迟取决于
设备的体系结构以及光电信号转换过程中的数据封装方法。 在DWDM设备中,此功能已分配给应答器或复用器模块。 因此,在组织两个数据中心之间的通信时,他们在选择发送应答器(muxponder)的类型时要特别小心,以使发送应答器(muxponder)上的延迟最小。
在同步模式下,信号在光纤中的传播速度(T
s )起着重要作用。 众所周知,标准(例如G.652)光纤中的光传播速度取决于其纤芯的折射率,大约等于真空中光速(〜300,000 km / s)的70%。 我们不会深入研究物理基础知识,但是很容易计算出这种情况下的延迟约为每公里5微秒。 因此,两个数据中心只能在大约100公里的距离内同步运行。
在异步模式下,延迟要求不是那么严格,但是如果对象之间的距离大大增加,光纤中光信号的衰减就会开始受到影响。 信号必须被放大和再生,也就是说,您必须创建自己的传输系统或租用中继通信信道。 两个数据中心之间传递的流量非常大,并且会不断增长。 数据中心之间流量增长的主要驱动力:虚拟化,云服务,新服务器和存储系统的迁移和连接。 在这里您可能会遇到数据传输通道带宽不足的问题。 由于缺乏自己的自由纤维或高昂的租金,将其增加到无穷大是行不通的。 最后一个重点与信息安全有关:必须对在数据中心之间运行的数据进行加密,这也会增加延迟。 还有其他一些方面,例如管理分布式系统的复杂性,但是它们的影响并不大,所有技术障碍主要与通信通道和终端设备的特性有关。
两三是经济困难
组合数据中心的两种模式都有明显的缺点。 同步操作的对象应放置在彼此靠近的位置,这不能保证在发生大规模灾难时至少其中之一能够生存。 是的,可以可靠地保护此选项免受人为错误,火灾,机舱因飞机坠毁而造成的毁坏或其他地方紧急情况的影响,但这远非两个数据中心都能承受例如灾难性地震的事实。 在异步模式下,对象之间可以相距数千公里,但确保可接受的RTO和RPO值将失败。 理想的解决方案是具有三个数据中心的电路,其中两个数据中心同步工作,而第三个数据中心则尽可能远离它们,并起异步备用的作用。
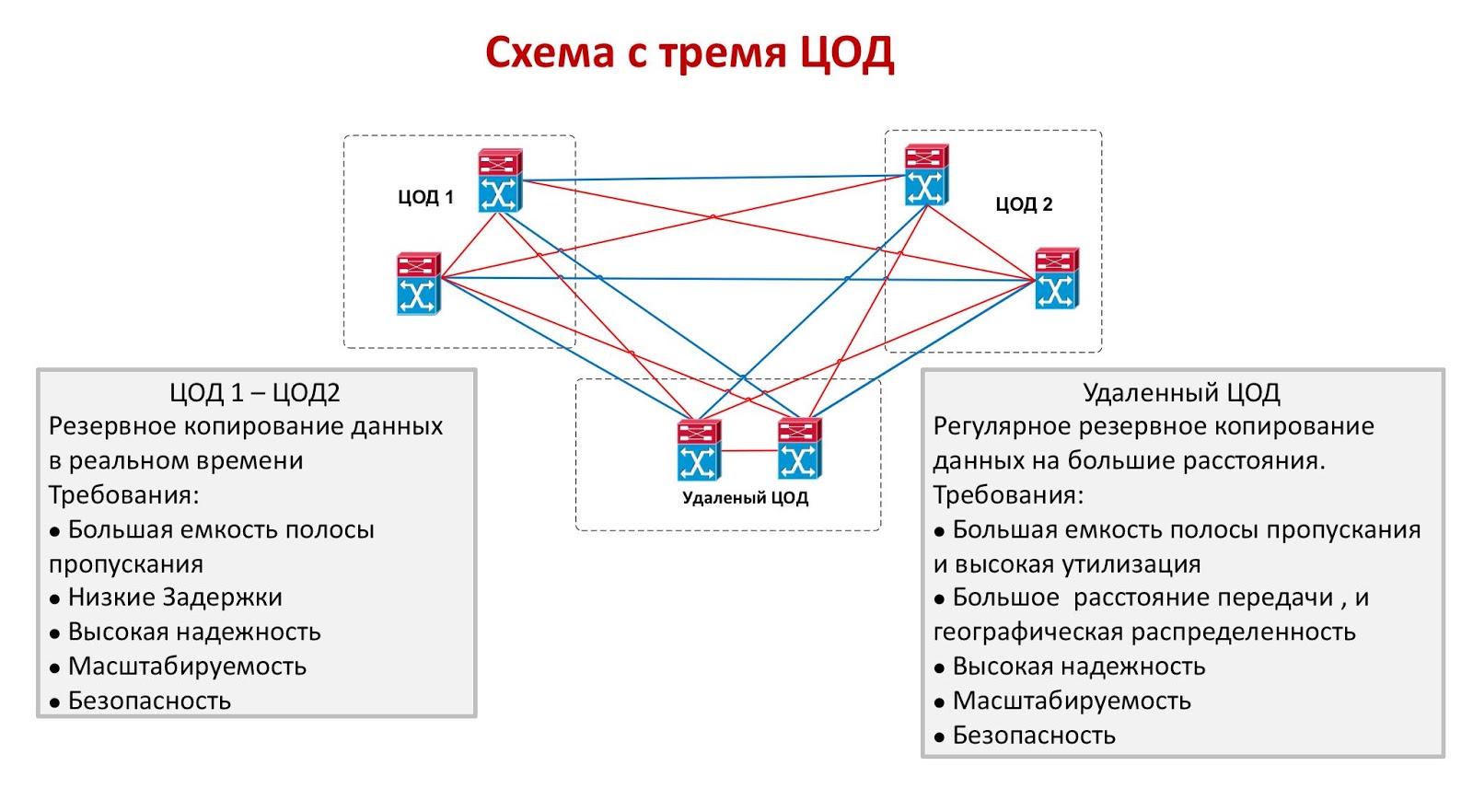
三个数据中心的唯一问题是其极高的成本。 即使组织一个备份站点也不是一件容易的事,而且很少有人负担得起保留两个空闲数据中心的费用。 如果交易成本很高,有时会在金融部门使用类似的方法:大型交易所可以启动包含三个小型数据中心的计划,但是在银行部门,他们更喜欢使用两者的同步组合。 其他行业通常组合两个以同步或异步模式运行的数据中心。
DWDM-DCI的最佳解决方案
如果客户需要将两个数据中心结合在一起,他将不可避免地遇到上述问题。 为了解决这些问题,我们使用DWDM频谱多路复用技术,该技术允许使用不同的波长(λ,即λ)将许多载波信号多路复用到一根光纤中。 此外,根据ITU-T G.694.1频率网格,在一个光学对中,最多可以有80(96)个波长。 每个波长的数据传输速率分别为100 Gbit / s,200 Gbit / s或400 Gbit / s,一个光对的容量可以达到80λ* 400 Gbit / s = 32 Tbit / s。 已经有现成的设计,每个波长可提供1 Tbit / s:在不久的将来它们将提供更大的带宽。 今天,它可以完全解决信道带宽问题:客户将不再使用额外的光纤,而将更有效地使用可用的光纤-流量利用率将达到惊人的价值。
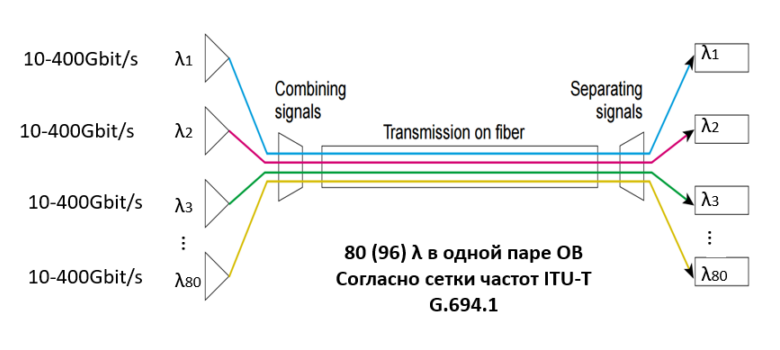
频谱多路复用可以解决带宽问题,对于在同步模式下运行的数据中心来说,这已经足够了,因为它们之间的数据传输距离由于距离小而延迟很小,并且更多地取决于DWDM系统中使用的转发器(或多路复用器)的类型。 值得注意的是,频谱压缩DWDM技术的主要特征之一是:由于该技术在7级OSI模型的第一个物理级工作,因此完全透明地传输业务。 如果我可以这样说,DWDM系统对其客户端连接是“透明的”,就像它们将通过直接跳线连接一样。 如果我们谈论异步模式,那么主要的延迟量取决于数据中心之间的距离(我们记得在OB中每公里有5微秒的延迟),但是对延迟没有严格的要求。 因此,传输范围取决于DWDM系统的功能,并受到三个因素的限制:信号衰减,信噪比和偏振模光色散。
在计算DWDM线路的光学部分时,要考虑所有这些因素,并根据计算结果来选择发送应答器(或多路复用器)的类型,所需的放大器数量和类型以及光路的其他组件。 随着DWDM系统的发展以及在支持40 Gbit / s和100 Gbit / s以及更高速度的相干接收的应答器中出现的应答器,光的偏振模色散作为限制因素已不再被考虑在内。 计算光线路和选择放大器类型的问题是一个单独的大主题,要求读者了解物理光学的基础知识,因此本文中将不对其进行详细讨论。
WDM技术可以解决信息安全问题。 当然,不必在光学级别执行加密,但是这种方法具有许多不可否认的优点。 更高级别的加密通常需要用于不同业务流的自主设备,并且会造成严重的延迟。 随着此类设备数量的增加,延迟也会增加,并且网络管理的复杂性也会增加。 OTN光加密(G.709-描述DWDM系统中帧格式的ITU-T建议)不依赖于服务类型,不需要单独的设备并且速度非常快-加密和未加密数据流之间的差异通常不超过10毫秒。

如果不使用DWDM频谱复用技术,几乎不可能合并大型数据中心并创建防灾分布式集群。 通过网络传输的信息量呈指数增长,迟早将耗尽现有光纤通信线路的可能性。 铺设或租用其他设备比购买设备要花费客户更多的钱,实际上,如今,密封是唯一经济上可行的选择。 在短距离时,DWDM技术可以更有效地使用现有光纤,从而提高了通向天堂的流量的利用率,在长距离时,它们还可以最大程度地减少数据传输的延迟。 今天,它可能是市场上可用的最佳技术,值得对其进行仔细研究。