
在AI大会上,
高级研究员 Vladimir Ivanov vivanov879将讨论强化学习的使用
Nvidia的深度学习工程师 。 专家在测试部门从事机器学习:“我分析了我们在视频游戏和硬件测试期间收集的数据。 为此,我使用机器学习和计算机视觉。 工作的主要部分是图像分析,培训之前的数据清洗,数据标记和获得解决方案的可视化。”
在今天的文章中,弗拉基米尔(Vladimir)解释了为什么在无人驾驶汽车中使用强化学习,并使用视频游戏示例讨论了如何训练特工在变化的环境中行动。
在过去的几年中,人类积累了大量的数据。 某些数据集是手动共享和布局的。 例如,CIFAR数据集(每个图片都在其中签名)属于该类。
在某些数据集中,您不仅需要为整个图片分配一个类,还需要为图像中的每个像素分配一个类。 例如,在CityScapes中。

将这些任务组合在一起的是,学习型神经网络只需要记住数据中的模式即可。 因此,如果有足够的数据量,并且在CIFAR的情况下为8000万张图片,则神经网络正在学习泛化。 结果,她很好地应对了以前从未见过的图像分类。
但是,在与老师一起使用的教学技术的框架内工作(该老师负责标记图片),不可能解决我们不想预测标记而要做出决定的问题。 例如,在自动驾驶的情况下,任务是安全可靠地到达路线的终点。
在分类问题中,我们与老师一起使用了教学技巧-为每张图片分配了特定的班级。 但是,如果我们没有这样的标记,但是有一个代理和一个环境,他可以在其中执行某些操作呢? 例如,假设它是一个视频游戏,我们可以单击控制箭头。

这类问题应通过强化训练来解决。 在问题的一般性陈述中,我们想学习如何执行正确的操作顺序。 从根本上重要的是,代理必须能够一次又一次地执行操作,从而探索其所处的环境。 除了获得正确答案之外,在特定情况下该怎么做,他还获得了正确完成任务的奖励。 例如,在使用自动出租车的情况下,驾驶员每次旅行都会获得奖金。
让我们回到一个简单的例子-电子游戏。 做一些简单的事情,例如Atari乒乓球比赛。
我们将在左侧控制平板电脑。 我们将与按照右侧规则编程的计算机播放器对战。 由于我们正在处理图像,并且神经网络是从图像中提取信息的最成功方法,因此让我们将图片应用于内核尺寸为3x3的三层神经网络的输入中。 在出口处,她将不得不选择以下两项操作之一:上下移动木板。
我们训练神经网络执行导致胜利的动作。 训练技巧如下。 我们让神经网络打几轮乒乓球。 然后我们开始对玩过的游戏进行排序。 在她赢得比赛的比赛中,我们标记了举起球拍的“上”和放下球拍的“下”的图片。 在输掉比赛中,我们则相反。 我们标记了这些照片,在这些照片中,她放下标牌的板子为“ Up”,而她标出的板子为“ Down”。 因此,我们将问题简化为我们已经知道的方法-与老师一起训练。 我们有一组带有标签的图片。
使用这种培训技术,我们的代理将在几个小时内学会击败按规则编程的计算机播放器。
自动驾驶该怎么办? 事实是,乒乓球是一种非常简单的游戏。 它每秒可以产生数千帧。 现在在我们的网络中只有3层。 因此,学习过程很快。 游戏会产生大量数据,我们会立即对其进行处理。 在自动驾驶的情况下,收集数据的时间更长且更昂贵。 汽车非常昂贵,一辆汽车我们每秒只能收到60帧。 另外,错误的代价增加了。 在视频游戏中,我们有能力在培训的一开始就逐场进行游戏。 但是我们不能破坏汽车。
在这种情况下,让我们在训练的一开始就帮助神经网络。 我们将相机固定在汽车上,将经验丰富的驾驶员放入其中,我们将记录相机中的照片。 对于每张图片,我们订阅汽车的转向角。 我们将训练神经网络复制有经验的驾驶员的行为。 因此,我们再次将任务简化为与老师一起进行的已知教学。
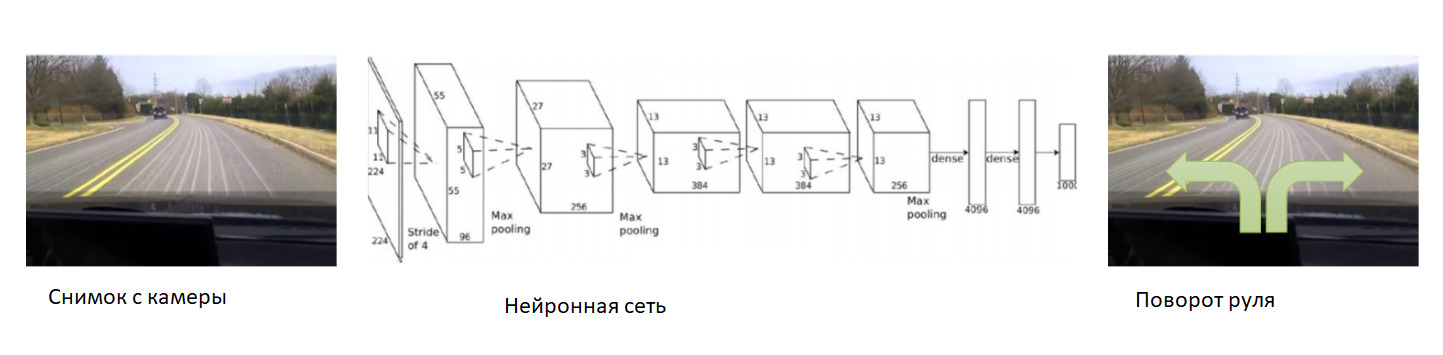
利用足够大且多样化的数据集,其中将包括不同的地形,季节和天气状况,神经网络将学习如何精确控制汽车。
但是,数据存在问题。 它们很长而且收集起来很昂贵。 让我们使用一个模拟器,在其中将实现汽车运动的所有物理特性-例如DeepDrive。 我们可以学习它而不必担心会丢车。

在此模拟器中,我们可以访问汽车和世界的所有指标。 此外,所有人员,汽车,它们的速度和与周围的距离都被标出。

从工程师的角度来看,在这样的模拟器中,您可以安全地尝试新的培训技术。 研究人员应该怎么做? 例如,在学习强化问题时,研究梯度下降的不同选择。 为了检验一个简单的假设,我不想从一门大炮上射麻雀,在一个复杂的虚拟世界中运行一个特工,然后一次等待几天才能获得模拟结果。 在这种情况下,让我们更有效地利用我们的计算能力。 让代理更简单。 以四足蜘蛛模型为例。 在Mujoco模拟器中,它看起来像这样:
我们为他设定了在给定方向(例如,向右)上以最高速度运行的任务。 蜘蛛观察到的参数数量是一个39维向量,它记录了蜘蛛所有肢体的位置和速度。 与乒乓球的神经网络不同,在乒乓球的输出中只有一个神经元,在输出中只有八个神经元(因为该模型中的蜘蛛有8个关节)。
在这种简单的模型中,可以检验有关教学技术的各种假设。 例如,让我们根据神经网络的类型比较学习跑步的速度。 假设它是单层神经网络,三层神经网络,卷积网络和递归网络:
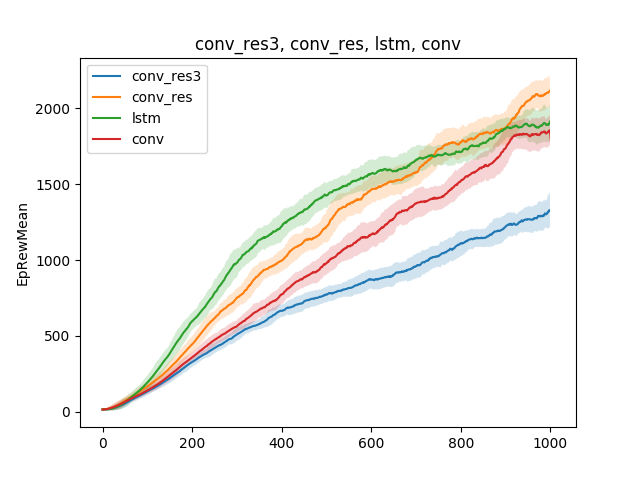
结论如下:由于蜘蛛模型和任务非常简单,因此不同模型的训练结果大致相同。 三层网络太复杂,因此学习情况更糟。
尽管模拟器可以使用简单的蜘蛛模型进行工作,但取决于蜘蛛所承担的任务,训练可以持续数天。 在这种情况下,让我们同时在一个表面上动画化数百个蜘蛛,而不是一个动画,并从我们将从每个人接收的数据中学习。 因此,我们将培训速度提高数百倍。 这是Flex引擎的示例。
就神经网络优化而言唯一发生变化的是数据收集。 当我们只运行一个蜘蛛时,我们将顺序接收数据。 一个接一个。

现在可能发生了,有些蜘蛛刚刚开始比赛,而另一些蜘蛛已经运行了很长时间。
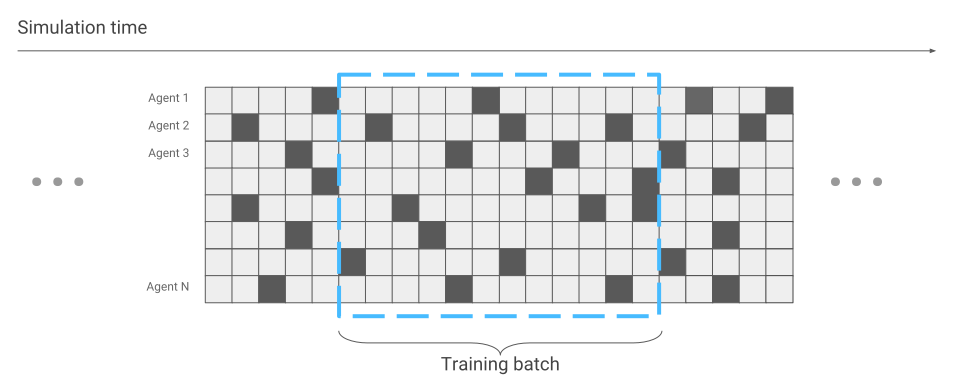
在神经网络优化期间,我们将考虑到这一点。 否则,一切保持不变。 结果,根据同时显示在屏幕上的蜘蛛的数量,我们获得了数百次训练的加速。
由于我们有一个有效的模拟器,让我们尝试解决更复杂的问题。 例如,在崎terrain的地形上奔跑。

由于这种情况下的环境变得更具攻击性,因此在培训期间让我们更改并使任务复杂化。 很难学习,但战斗容易。 例如,每隔几分钟更改一次地形。 另外,让我们将外部代理定向到该代理。 例如,让我们向他扔球并打开和关闭风。 然后,代理甚至学会了在从未遇到过的表面上奔跑。 例如,爬楼梯。

由于我们已经有效地学会了在模拟中进行跑步,因此让我们检查一下竞争学科中的强化训练技术。 例如,在射击游戏中。 VizDoom平台提供了一个可以射击,收集武器并补充健康的世界。 在这个游戏中,我们还将使用神经网络。 直到现在,她将有五个出口:四个用于运动,一个用于射击。
为了使训练有效,让我们逐步进行。 从简单到复杂。 在输入时,神经网络接收到图像,并且在开始做有意识的事情之前,它必须学会了解世界的组成。 在简单的场景中学习,她将学会了解世界上居住着哪些物体以及如何与它们互动。 让我们从破折号开始:
掌握了这种情况后,座席将了解到有敌人,应该将他们开枪,因为您会为他们加分。 然后,我们将在健康持续下降的情况下训练他,您需要补充它。

在这里,他将了解自己的健康状况,需要补充,因为在死亡的情况下,代理商会得到负面奖励。 此外,他还将学习到,如果您朝着这个主题前进,就可以收集它。 在第一种情况下,代理无法移动。
在最后的第三个场景中,让他让他按照游戏规则编程的机器人来射击,以便他可以磨练自己的技能。

在这种情况下的培训期间,正确选择代理商所获得的报酬非常重要。 例如,如果您仅对失败的对手给予奖励,那么信号将非常罕见:如果周围只有很少的玩家,那么我们每隔几分钟就会获得积分。 因此,让我们使用之前的奖励组合。 无论是改善健康状况,选择弹药筒还是击中对手,特工都会因每项有用的行动而获得奖励。
结果,受过精心选择的奖励训练的特工要比其对计算要求更高的对手更强大。 在2016年,这种系统赢得了VizDoom竞赛的冠军,其利润率超过了第二名的一半。 亚军团队也使用了神经网络,训练过程中只有大量的层和来自游戏引擎的其他信息。 例如,有关特工视野中是否有敌人的信息。
我们已经研究了解决问题的方法,在这些问题中做出决定很重要。 但是,使用此方法的许多任务仍未解决。 例如,任务游戏《蒙特祖玛复仇》。
在这里,您需要寻找钥匙才能打开通往相邻房间的门。 我们很少获得钥匙,而且我们开房的频率更低。 不要被异物分散注意力,这一点也很重要。 如果您像以前的任务一样训练系统并为被打败的敌人提供奖励,它只会一次又一次敲打滚动的头骨,并且不会检查地图。 如果您有兴趣,我可以在另一篇文章中讨论解决此类问题。
您可以在11月22日的AI大会上听Vladimir Ivanov的讲话 。 活动的
官方网站上提供了详细的计划和门票。
在
这里阅读对弗拉基米尔的采访。