致命的43秒,导致服务每日降级上周在GitHub上发生了一个
事件 ,该
事件使该服务降级了24小时11分钟。 该事件并没有影响整个平台,只影响了几个内部系统,导致显示了过时和不一致的信息。 最终,用户数据并没有丢失,但是仍在手动核对写入数据库的几秒钟。 对于大多数崩溃,GitHub也无法处理webhooks,创建和发布GitHub Pages。
GitHub上的所有人都谨对你们所有人遇到的问题深表歉意。 我们知道您对GitHub的信任,并为创建可支持我们平台高可用性的可持续系统而感到自豪。 我们让您对这一事件感到失望,并对此深表遗憾。 尽管由于GitHub平台的长期退化而导致我们无法解决问题,但我们可以解释发生这种情况的原因,讨论所汲取的经验教训以及可以使该公司将来更好地保护自己免受此类故障影响的措施。
背景知识
大多数GitHub用户服务都在我们自己的
数据中心中工作 。 数据中心拓扑旨在在几个提供计算和数据存储系统工作的区域数据中心前提供可靠且可扩展的边界网络。 尽管项目的物理和逻辑组件中内置了一定程度的冗余,但站点在一段时间内仍可能无法相互交互。
10月21日,世界标准时间下午10:52,由于计划内的维修工作以更换有故障的100G光学设备,导致东海岸(美国东海岸)的网络节点与东海岸的主要数据中心之间的通信中断。 它们之间的连接在43秒后恢复,但是短暂的断开连接导致一系列事件,导致24小时11分钟的服务质量下降。
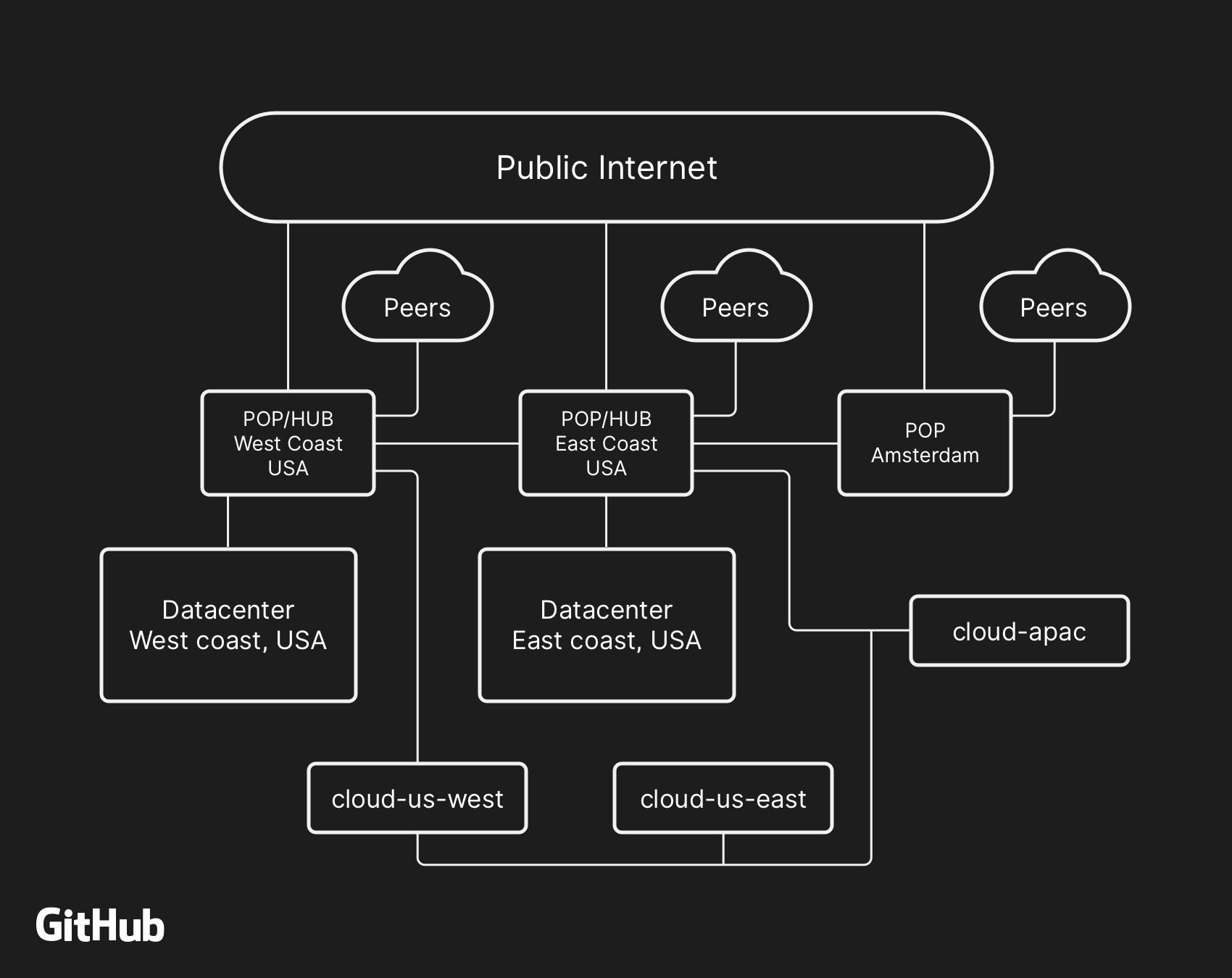 GitHub的高级网络架构,包括两个物理数据中心,3个POP和多个区域的云存储,通过对等连接
GitHub的高级网络架构,包括两个物理数据中心,3个POP和多个区域的云存储,通过对等连接过去,我们讨论了如何使用
MySQL存储GitHub元数据 ,以及
为MySQL提供
高可用性的方法。 GitHub管理着数个MySQL集群,规模从数百GB到近5 TB。 每个集群都有数十个只读副本来存储除Git之外的元数据,因此我们的应用程序在Git对象存储库之外提供池请求,问题,身份验证,后台处理以及其他功能。 使用功能分段,将应用程序不同部分中的不同数据存储在不同的群集中。
为了大规模提高性能,应用程序将写入直接写入每个群集的相应主服务器,但是在大多数情况下,将读取请求委托给副本服务器的子集。 我们使用
Orchestrator来管理MySQL群集拓扑并自动进行故障转移。 在此过程中,Orchestrator考虑了许多变量,并在
Raft上组装以保持一致性。 Orchestrator可能会实现应用程序不支持的拓扑,因此您需要确保Orchestrator的配置符合应用程序级别的期望。
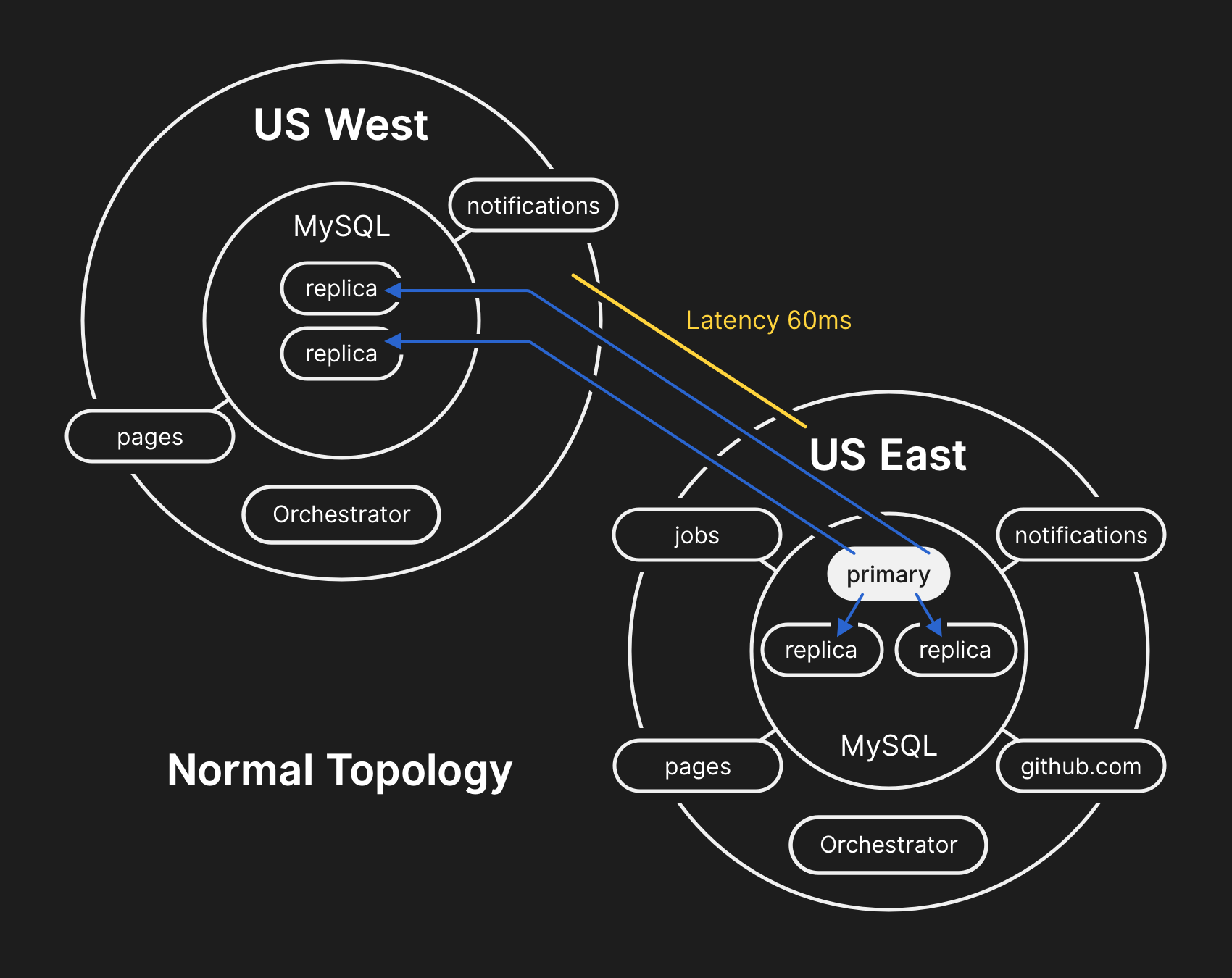 在典型的拓扑中,所有应用程序都以低延迟在本地读取。
在典型的拓扑中,所有应用程序都以低延迟在本地读取。事件纪事
世界标准时间10.21.2018,22:52
在上述网络分离期间,主数据中心的Orchestrator开始根据Raft共识算法取消领导的选择过程。 西海岸数据中心和东海岸的Orchestrator公共云节点设法达成共识-并开始解决群集故障,以将记录转发到西部数据中心。 Orchestrator开始在西方创建数据库集群拓扑。 重新连接后,这些应用程序立即向美国西部的新主服务器发送写流量。
在东部数据中心的数据库服务器上,有短时间的记录没有复制到西部数据中心。 由于两个数据中心中的数据库集群现在都包含不在另一个数据中心中的记录,因此我们无法安全地将主服务器返回到东部数据中心。
世界标准时间10.21.2018,22:54
我们的内部监控系统开始生成警报,指示大量系统故障。 这时,几名工程师做出了回应并致力于对传入通知进行排序。 到23:02,第一个响应小组的工程师确定许多数据库集群的拓扑处于意外状态。 查询Orchestrator API时,显示了数据库复制拓扑,其中仅包含来自西部数据中心的服务器。
世界标准时间10.21.2018,23:07
此时,响应团队决定手动阻止内部部署工具,以防止进行其他更改。 在23:09,小组将网站设置为
黄色 。 该操作会自动为事件分配活动事件的状态,并向事件协调员发送警告。 在23:11,协调员加入了工作,两分钟后决定
将状态更改为red 。
世界标准时间10.21.2018,23:13
当时,很明显该问题影响了多个数据库集群。 数据库工程组的其他开发人员也参与了这项工作。 他们开始检查当前状态,以确定需要采取哪些措施来手动将US East Coast数据库配置为每个群集的主要数据库并重建复制拓扑。 这并不容易,因为此时西方数据库集群已经从应用程序层接收了将近40分钟的记录。 此外,在东部群集中,有几秒钟的记录没有复制到西方,也不允许将新记录复制回东方。
保护用户数据的隐私和完整性是GitHub的首要任务。 因此,我们决定在西方数据中心中记录30分钟以上的数据,以便为保存这种数据而只为我们提供一种解决方案:向前传输(失败)。 但是,东部地区的依赖于向西部MySQL集群写入信息的应用程序由于来回传输大多数数据库调用而当前无法处理额外的延迟。 该决定将导致以下事实:我们的服务将不适用于许多用户。 我们认为,服务质量的长期下降值得确保用户数据的一致性。
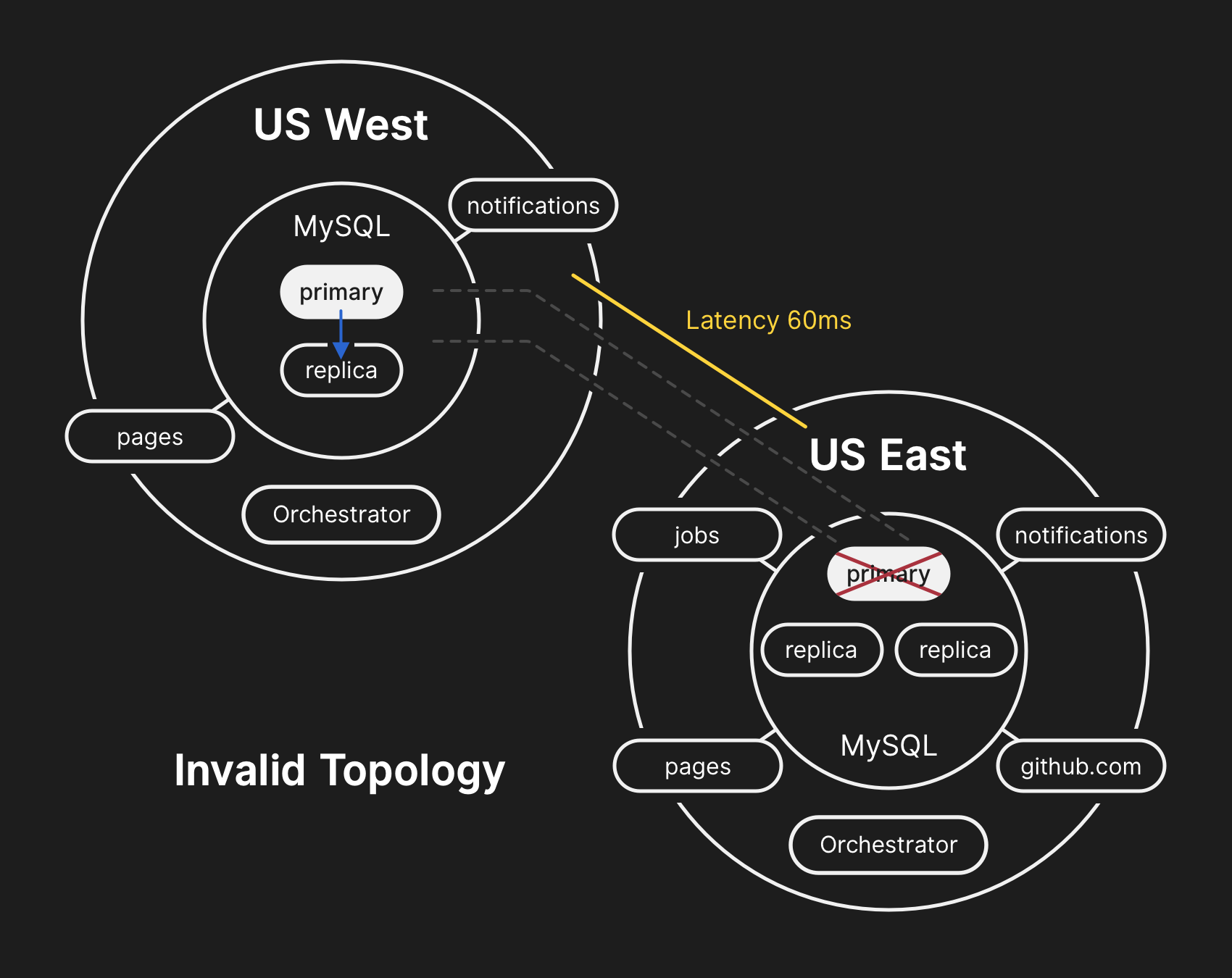 在错误的拓扑中,将违反从西向东的复制,并且应用程序无法从当前副本读取数据,因为它们依赖低延迟来维持事务性能
在错误的拓扑中,将违反从西向东的复制,并且应用程序无法从当前副本读取数据,因为它们依赖低延迟来维持事务性能世界标准时间10.21.2018,23:19
有关数据库集群状态的查询表明,有必要停止执行写入元数据的任务(例如推送请求)的执行。 我们做出了选择,并故意对服务进行了部分降级,中止了Webhooks和GitHub Pages的组装,以免损害已经从用户那里收到的数据。 换句话说,策略是优先考虑:数据完整性而不是站点可用性和快速恢复。
10/22/2018,00:05 UTC
响应团队工程师开始制定解决数据不一致的计划,并启动MySQL故障转移程序。 计划是从备份还原文件,同步两个站点上的副本,返回到稳定的服务拓扑,然后继续处理队列中的作业。 我们更新了状态,以通知用户我们将对内部存储系统执行托管故障转移。
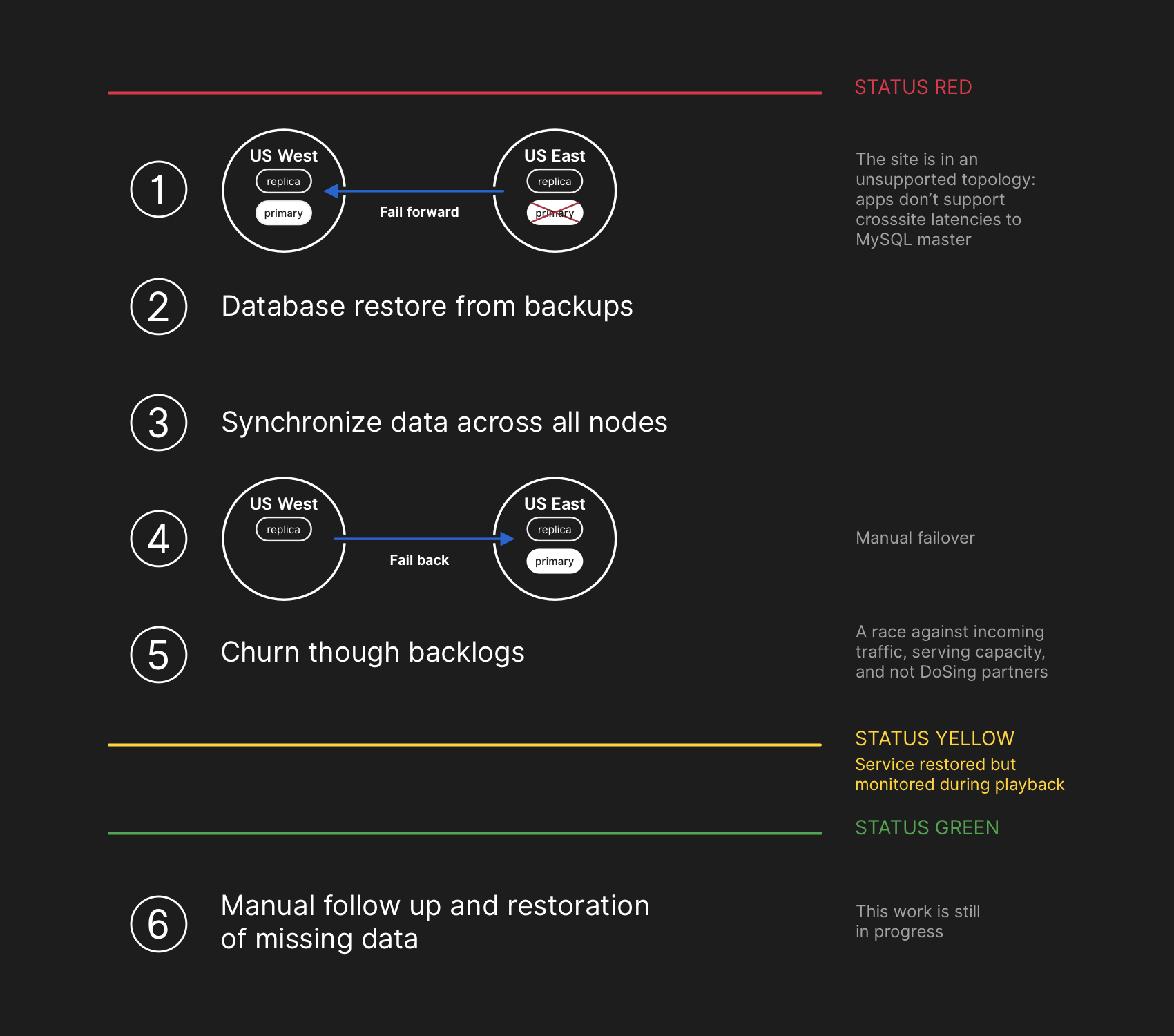 恢复计划包括前进,从备份中还原,同步,回滚并解决延迟,然后返回绿色状态。
恢复计划包括前进,从备份中还原,同步,回滚并解决延迟,然后返回绿色状态。尽管MySQL备份每四个小时进行一次并存储很多年,但它们位于blob对象的远程云存储中。 从备份中恢复几个TB花费了几个小时。 从远程备份服务传输数据花费了很长时间。 大部分时间都花在解压缩,检查校验和,准备大型备份文件并将其上传到刚准备好的MySQL服务器上。 每天都要测试此过程,因此每个人都对恢复需要多长时间有所了解。 但是,在发生此事件之前,我们不必从备份中完全重建整个集群。 其他策略也一直有效,例如推迟的副本。
10/22/2018,00:41 UTC
到这个时候,已经为所有受影响的MySQL群集启动了备份过程,并且工程师跟踪了进度。 同时,几组工程师研究了加速传输和恢复的方法,而不会进一步降低站点的性能或数据损坏的风险。
10/22/2018,06:51 UTC
东部数据中心的几个集群完成了从备份的恢复,并开始复制西海岸的新数据。 这导致在全国范围内执行写操作的页面加载速度减慢,但是如果读取请求落在新还原的副本上,则从这些数据库集群读取页面会返回实际结果。 其他较大的数据库群集继续恢复。
我们的团队已经直接从西海岸确定了一种恢复方法,以克服因从外部存储启动而造成的带宽限制。 几乎100%的人知道恢复将成功完成,并且创建健康的复制拓扑的时间取决于追赶复制需要多少时间。 根据可用的遥测复制对该估计值进行线性插值,并
更新状态页以将两小时的等待时间设置为估计的恢复时间。
10/22/2018,07:46 UTC
GitHub发布了一个内容
丰富的博客文章 。 我们自己使用GitHub Pages,并且所有程序集都在数小时前暂停,因此发布需要更多的工作。 造成延误,我们深表歉意。 我们打算更早地发送此消息,将来我们将在这种限制的情况下提供更新的发布。
10/22/2018,11:12 UTC
所有主要数据库再次转移到东方。 由于记录现在被路由到与我们的应用程序层位于同一物理数据中心的数据库服务器,因此该站点变得更加敏感。 尽管这可以显着提高性能,但是仍然有几十个读取数据库的副本比主副本要晚几个小时。 这些延迟的副本导致用户在与我们的服务进行交互时看到不一致的数据。 我们将读取负载分布在一大批只读副本中,并且对我们服务的每个请求都有几小时的延迟进入只读副本的良好机会。
实际上,滞后副本的追赶时间呈指数下降,而不是线性下降。 当美国和欧洲的用户醒来时,由于数据库集群中记录的负载增加,恢复过程花费了比预期更长的时间。
10/22/2018,13:15 UTC
我们正在GitHub.com上达到峰值负载。 响应小组讨论了后续步骤。 很明显,复制滞后到一致状态是在增加而不是减少。 早些时候,我们开始在东海岸公共云中准备其他MySQL读取副本。 一旦它们变得可用,就可以在多个服务器之间分配读取请求流。 降低只读副本的平均负载可加速复制追赶。
10/22/2018,16:24 UTC
同步副本后,我们返回到原始拓扑,从而消除了延迟和可用性问题。 作为对数据完整性优先于快速纠正情况的有意识决定的一部分,当我们开始处理累积的数据时,我们
保持了网站
的红色状态 。
10/22/2018,16:45 UTC
在恢复阶段,有必要平衡与积压相关的增加的负载,这可能使我们的生态系统合作伙伴过载通知,并尽快恢复到100%的效率。 队列中还有超过500万个挂钩事件和8万个构建网页的请求。
当我们重新启用对数据的处理时,我们用超过内部TTL的webhooks处理了大约200,000个有用任务,并被丢弃。 了解到这一点后,我们停止了处理并开始增加TTL。
为了避免状态更新的可靠性进一步降低,我们保留了降级状态,直到完成处理所有累积的数据量并确保服务已明显恢复到正常的性能水平为止。
世界标准时间10/22/2018,11:03
处理所有不完整的webhook事件和Pages程序集,并确认所有系统的完整性和正确操作。 该站点的状态已
更新为绿色 。
进一步行动
解决数据不匹配
在恢复过程中,我们修复了MySQL二进制日志,其日志主要包含数据中心的条目,这些条目未复制到西方数据库。 此类条目的总数相对较小。 例如,在最繁忙的群集之一中,这几秒钟中只有954条记录。 我们目前正在分析这些日志,并确定哪些条目可以自动调节,哪些需要用户帮助。 有几个团队参与了这项工作,我们的分析已经确定了用户随后重复使用的记录的类别,并且这些记录已成功保存。 如本分析所述,我们的主要目标是维护您存储在GitHub上的数据的完整性和准确性。
沟通交流
为了在事件发生期间向您传达重要信息,我们根据累积数据的处理速度对恢复时间进行了几次公开估算。 回顾过去,我们的估算并未考虑所有变量。 对于由此带来的困惑,我们深表歉意,并将在未来提供更多准确的信息。
技术措施
在分析过程中,确定了许多技术措施。 分析继续进行,可以对列表进行补充。
- 调整Orchestrator的配置,以防止主数据库移出该区域。 Orchestrator根据设置工作,尽管应用程序层不支持这种拓扑更改。 通常,在一个区域内选择一位领导者是安全的,但是由于穿越非洲大陆的交通流量而突然出现的延误现象已成为此事件的主要原因。 这是系统的一种新出现的行为,因为在我们之前没有遇到过如此庞大的网络内部部分。
- 我们已经加快了向新状态报告系统的迁移,它将提供一个更合适的平台,以更精确和清晰的表述方式讨论活动事件。 尽管在整个事件中GitHub的许多部分都可用,但是我们只能为整个站点选择绿色,黄色和红色状态。 我们承认这并不能给出准确的描述:有效的方法和无效的方法。 新系统将显示平台的各个组件,以便您了解每个服务的状态。
- 在此事件发生前几周,我们发起了一项全公司范围的工程计划,以使用主动/主动/主动架构来支持从多个数据中心为GitHub流量提供服务。 该项目的目标是在数据中心级别支持N + 1冗余,以承受一个数据中心的故障而不受外界干扰。 这是一项繁重的工作,需要一些时间,但是我们相信,不同地区的几个连接良好的数据中心将为您提供一个很好的折衷方案。 最近的事件进一步推动了这一倡议。
- 我们将采取更加积极的立场来检查我们的假设。 GitHub迅速发展,在过去十年中积累了相当多的复杂性。 捕获折衷和决策的历史背景并将其传给新一代员工变得越来越困难。
组织措施
该事件极大地影响了我们对站点可靠性的理解。 我们了解到,在像我们这样的复杂服务系统中,加强操作控制或改善响应时间不足以保证可靠性。 为了支持这些工作,我们还将开始在故障情况实际发生之前进行测试的系统实践。 这项工作包括故意进行故障排除和使用混乱的工程工具。
结论
我们知道您在项目和业务中如何依赖GitHub。 我们比任何人都更关心我们的服务可用性和您的数据安全。
分析此事件将继续寻找机会,为您提供更好的服务并证明您的信任。