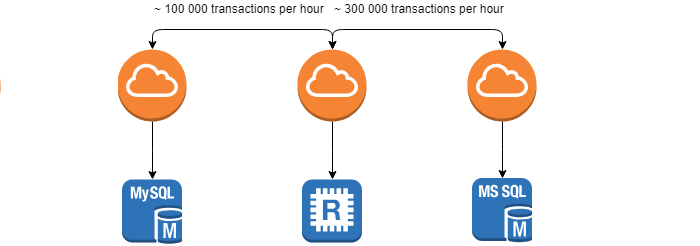
在开发和使用分布式系统时,我们面临着监视系统之间数据完整性和身份的任务-协调任务 。
客户设置的要求是此操作的最短时间,因为发现差异越早,消除其后果就越容易。 由于系统处于不停运转状态(每小时约100,000个事务),并且无法实现0%的差异,因此该任务非常复杂。
主要思想
下图描述了解决方案的主要思想。
我们分别考虑每个元素。
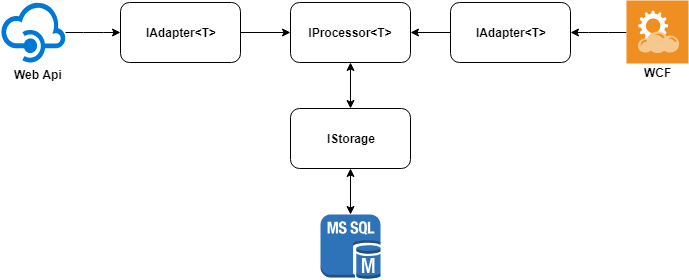
数据适配器
每个系统都针对其自己的主题领域而设计,因此,对象的描述可能会发生很大变化。 我们只需要比较来自这些对象的一组特定字段。
为了简化比较过程,我们通过为每个数据源编写一个适配器将对象变成单一格式。 将对象设为单一格式可以显着减少使用的内存量,因为我们将仅存储要比较的字段。
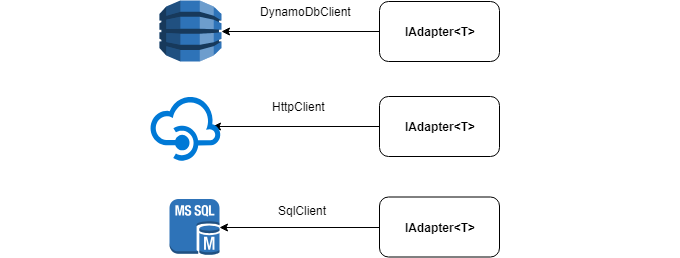
在后台 ,适配器可以具有任何数据源: HttpClient , SqlClient , DynamoDbClient等。
以下是您要实现的IAdapter接口:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
贮藏
数据协调只能在读取完所有数据后才能开始,因为适配器可以随机顺序返回它们。
在这种情况下,RAM的数量可能不足,尤其是如果您同时运行多个对帐,表明时间间隔较长时,尤其如此。
考虑IStorage接口
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
仓库。 基于MS SQL的实现
我们使用MS SQL实施了IStorage ,这使我们能够在Db服务器端完全执行比较。
要存储所请求的值,只需创建下表:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
每个记录包含系统字段( [id] , [adapterId] )和用于比较的字段( [qty] , [price] )。 关于系统字段的几句话:
[id] -条目的唯一标识符,在两个系统中都相同
[adapterId] -通过其接收记录的适配器的标识符
由于对帐流程可以并行启动并具有相交的间隔,因此我们为每个表格创建一个具有唯一名称的表格。 如果对帐成功,则将删除该表,否则将发送报告,其中包含有差异的记录列表。
仓库。 价值比较
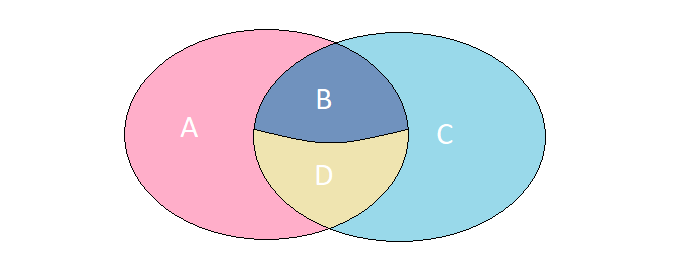
想象一下,我们有2个集合,它们的元素具有完全相同的字段集。 考虑它们相交的4种可能情况:
A. 元素仅存在于左集中。
B. 元素在两组中都存在,但是含义不同。
C. 元素仅出现在正确的集合中。
D. 元素在两组中都存在并且具有相同的含义。
在一个特定的问题中,我们需要找到案例A,B,C中描述的元素。 您可以通过FULL OUTER JOIN在一次对MS SQL的查询中获得所需的结果:
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
该请求的输出可能包含满足初始要求的4种记录类型
| # | 编号 | 适配器ID | 评论 |
|---|
| 1个 | guid1 | adp1 | 该记录仅存在于左集中。 案例A |
| 2 | guid2 | adp2 | 该记录仅存在于正确的集中。 案例C |
| 3 | guid3 | adp1 | 记录在两组中都存在,但是含义不同。 情况B |
| 4 | guid3 | adp2 | 记录在两组中都存在,但是含义不同。 情况B |
仓库。 散列
在比较对象上使用散列,可以显着降低写入和比较操作的成本。 特别是在比较数十个字段时。
事实证明,散列对象的序列化表示形式的最通用方法是。
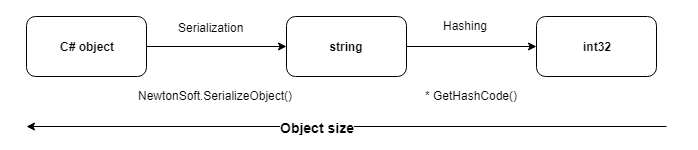
1.对于散列,我们使用标准的GetHashCode()方法,该方法返回int32并被所有基本类型覆盖。
2.在这种情况下,冲突的可能性很小,因为仅比较具有相同标识符的记录。
考虑此优化中使用的表结构:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
这种结构的优点是存储一条记录(24字节)的不变成本,这将不取决于比较字段的数量。
自然,比较过程会发生变化并变得更加简单。
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
中央处理器
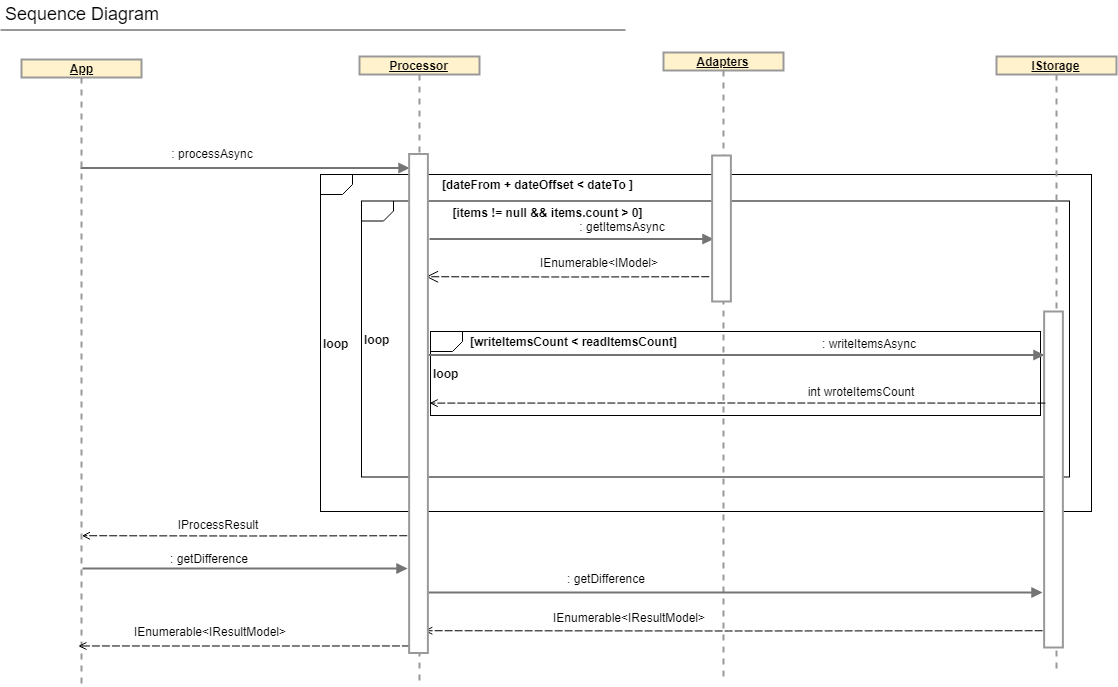
在本节中,我们将讨论一个包含所有对帐业务逻辑的类,即:
1.从适配器并行读取数据
2.数据哈希
3.缓冲数据库中的值记录
4.交付结果
通过查看序列图和IProcessor接口,可以获得对帐过程的更全面的描述。
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
致谢
非常感谢MySale Group的同事的反馈: AntonStrakhov , Nesstory , Barlog_5 ,Kostya Krivtsun和VeterManve-这个想法的作者。