当我们谈论主动优化时,我们遇到的第一件事是不知道需要优化什么。 “这样做,我不知道是什么。”
- 没有经典算法。
- 问题尚未出现(未知),人们只能猜测可能在哪里。
- 我们需要找到系统中的一些潜在弱点。
- 尝试在这些地方优化查询性能。
主动优化的主要目标
主动优化的主要任务与被动优化的任务不同,如下:
最后一刻是最根本的。 在无功优化的情况下,我们没有整体减少资源消耗的任务,而只有使功能的响应时间处于可接受范围内的任务。
如果您使用作战服务器,则对性能事件的含义有一个很好的了解。 您需要退出所有内容并快速解决问题。 RNKO Payment Center LLC与许多代理商合作,对于他们来说,尽可能少地出现问题非常重要。 HighLoad ++ Siberia的Alexander Makarov讲述了为显着减少性能事件而采取的措施。 主动优化可以解救。 以及为什么以及如何在战斗服务器上生产它,请阅读下文。
 关于演讲者:
关于演讲者: RNKO Payment Center LLC,Oracle数据库的首席管理员Alexander Makarov(
AL_IG_Makarov )。 尽管有这个职位,行政管理却很少,主要任务与综合体的维护及其开发有关,特别是与解决性能问题有关。
战斗数据库的优化是否积极主动?
首先,我们将处理此报告称为“主动性能优化”的术语。 有时,您可能会遇到这样的观点:主动优化是在甚至启动应用程序之前就进行问题区域分析的时候。 例如,我们发现某些查询不能最佳地工作,因为索引不足或查询使用的算法无效,因此这项工作是在测试服务器上完成的。
尽管如此,我们在RNCO的
战斗服务器上还是做了这个项目。 我很多次听到:“如何? 您是在战斗服务器上完成的-这意味着它不是主动的性能优化!” 在这里,我们需要回顾一下ITIL中培养的方法。 从ITIL的角度来看,我们有:
- 绩效事件已经发生;
- 我们为防止性能事故发生而采取的措施。
从这个意义上讲,我们的行动是积极主动的。 尽管我们正在战斗服务器上解决问题,但问题本身尚未出现:事件没有发生,我们没有奔跑,也没有尝试在短时间内解决此问题。
因此,在此报告中,主动性
在ITIL的意义上被理解为
主动性 ,我们在性能事件发生之前就解决了问题。
参考点
RNKO“付款中心”为2个大型系统提供服务:
这些系统上的负载的性质是混合的(DSS + OLTP):有些东西可以很快运行,有报告,中等负载。
我们面临这样一个事实,即不经常发生,而是以一定的频率发生性能事件。 那些使用战斗服务器的人可以想象它是什么。 这意味着您需要退出所有内容并快速解决问题,因为此时客户端无法接收该服务,某些东西根本无法工作,或者工作非常缓慢。
由于很多代理商和客户都与我们的组织息息相关,因此这对我们非常重要。 如果我们不能快速解决性能事件,那么我们的客户将遭受一种或另一种痛苦。 例如,他们将无法补充卡或进行转帐。 因此,我们想知道如何解决这些偶发的性能事件。 当您需要放下所有东西并解决问题时以这种方式工作-这并不完全正确。 我们使用冲刺并制定冲刺工作计划。 绩效事件的出现也偏离了工作计划。
必须为此做些事情!
优化方法
我们思考并了解了主动优化技术。 但是在谈论前摄性优化之前,我必须先谈谈经典的反应式优化。
反应性优化
场景很简单,有一架战斗服务器发生了一些事情:他们启动了报告,客户收到了陈述,这时数据库上正在进行活动,突然有人决定更新某种庞大的目录。 系统开始减速。 此刻,客户来了,说:“我不能做到这一点或那件事”-我们需要找到他不能做到这一点的原因。
经典动作算法:- 重现该问题。
- 找到问题点。
- 优化问题所在。
在被动方法的框架内,主要任务不是寻找根本原因并加以消除,而是使系统正常工作。 根本原因的消除可以在以后解决。 最主要的是快速恢复服务器,以便客户端可以接收服务。
反应式优化的主要目标
在反应式优化中,可以区分两个主要目标:
1.
减少响应时间 。
例如,必须在某个预定时间内执行一项操作,例如接收报告,声明,交易。 必须确保接收服务的时间返回到客户端可接受的范围。 也许该服务的工作速度比平常慢一些,但是对于客户而言,这是可以接受的。 然后,我们认为性能事件已被消除,我们开始着手研究根本原因。
2.
批处理期间每单位时间处理的对象数增加 。
在进行交易的批处理时,有必要减少批处理中一个对象的处理时间。
反应性方法的优点:●
各种工具和技术是被动方法的主要优点。
我们可以使用监视工具来直接了解问题所在:CPU,线程,内存不足或磁盘系统滑移,或者日志处理缓慢。 有许多工具和技术可用于研究Oracle数据库中的当前性能问题。
●
所需的响应时间是另一个优点。
在进行此类工作的过程中,我们将情况带到可接受的响应时间,也就是说,我们不会尝试将其降低到最小值,但是我们会达到一定的值,并且在执行此操作后便会完成,因为我们认为已经达到可接受的极限。
被动方法的缺点:- 性能事件仍然存在 -这是被动方法的最大缺点,因为我们无法始终找到根本原因。 尽管我们取得了令人满意的表现,但她仍可以呆在某个地方,躺在更深的地方。
如果尚未发生绩效事故,该如何处理? 让我们尝试制定如何进行主动优化以防止这种情况的发生。
主动优化
我们遇到的第一件事是,尚不清楚需要优化什么。 “这样做,我不知道是什么。”
- 没有经典算法。
- 问题尚未出现(未知),人们只能猜测可能在哪里。
- 我们需要找到系统中的一些潜在弱点。
- 尝试在这些地方优化查询性能。
主动优化的主要目标
主动优化的主要任务与被动优化的任务不同,如下:
最后一刻是最根本的。 在无功优化的情况下,我们没有整体减少资源消耗的任务,而只有使功能的响应时间处于可接受范围内的任务。
如何在数据库中查找瓶颈?
当我们开始考虑这个问题时,许多子任务立即出现。 有必要进行:
- CPU测试
- 对读取/记录进行负载测试;
- 通过活动会话数进行压力测试;
- 在...等上进行负载测试
如果我们尝试在测试综合系统上模拟这些问题,则可能会遇到这样的事实,即测试服务器上出现的问题与战斗系统无关。 造成这种情况的原因很多,首先是测试服务器通常较弱。 可以将测试服务器制作为实战服务器的精确副本,这是很好的做法,但这不能保证以相同的方式重现负载,因为您需要准确地重现用户活动以及影响最终负载的更多不同因素。 如果您尝试模拟这种情况,那么总的来说,没有人可以保证战斗服务器上会发生完全相同的事情。
如果在一种情况下问题是由于新注册表到达而引起的,则在另一种情况下可能是由于用户启动了执行大型排序的大型报表而引起的,因此临时表空间被填满,并且结果,系统开始变慢。 即,原因可以不同,并且并非总是能够预测它们。 因此,
我们几乎从一开始
就放弃了在测试服务器上搜索瓶颈的尝试 。 我们仅依靠战斗服务器及其上发生的一切。
在这种情况下该怎么办? 首先,让我们尝试了解最有可能缺少的资源。
减少数据库资源消耗
基于我们拥有的工业园区,
在磁盘读取和CPU中观察到最常见的资源不足 。 因此,首先,我们将精确地寻找这些方面的弱点。
第二个重要问题:如何寻找东西?
这个问题很重要。 我们将Oracle Enterprise Edition与Diagnostic Pack选项一起使用,并且为自己找到了这样的工具
-AWR报告 (在其他Oracle版本中,您可以使用
STATSPACK报告 )。 在PostgreSQL中有一个类似的pgstatspack,有Andrey Zubkov的
pg_profile 。 据我了解,最后一种产品只是在去年才出现并开始开发。 对于MySQL,我找不到类似的工具,但我不是MySQL专家。
该方法本身不依赖于任何特定种类的数据库。 如果可以从某些报告中获取有关系统负载的信息,那么使用我现在将要讨论的技术,您可以
在任何基础上进行主动优化工作。
优化前五项业务
我们在RNCO付款中心开发并使用的主动优化技术包括四个阶段。
第1阶段。我们在尽可能长的时间内收到AWR报告。需要最大可能的时间长度来平均一周中不同日期的负载,有时有时会非常不同。 例如,过去一周的注册中心于星期二到达苏格兰皇家银行零售银行,开始进行处理,整天的工作量比平均水平高出大约2-3倍。 在其他日子,负载较小。
如果已知系统具有某些特定信息-某些天负载更大,某些天-更少,那么您需要分别接收这些时间段的报告,并分别使用它们以优化特定的时间间隔。 如果您需要优化服务器的整体状况,则可以获得当月的大报告,并查看服务器实际消耗的资源。
有时会遇到非常意外的情况。 例如,对于CFT银行,检查报告服务器队列的请求可能位于前10位。 此外,此请求是正式的,不执行任何业务逻辑,而仅检查是否存在执行报告。
阶段2。我们查看以下部分:- 按经过时间排序的SQL-按运行时排序的SQL查询;
- SQL按CPU时间排序-用于CPU使用情况;
- 由Gets排序的SQL-通过逻辑读取;
- SQL按读取顺序排序-用于物理读取。
根据需要研究SQL的其余部分。
第3阶段。我们确定父操作和依赖于父操作的请求。AWR报告有单独的部分,其中根据Oracle版本的不同,在每个部分中显示15个或更多的顶级查询。 但是Oracle在AWR报告中的这些查询显示出一团糟。
例如,有一个父操作,其中有3个顶级查询。 Oracle在AWR报告中将显示父操作和所有这三个查询。 因此,您需要对此列表进行分析,并查看特定请求所指的是什么,并将其分组。
第4阶段。我们优化了前5个操作。进行此类分组后,输出是一个操作列表,您可以从中选择最困难的操作。 我们仅限于5个操作(不是请求,即操作)。 如果系统更复杂,那么您可以承担更多。
常见查询设计错误
在应用这项技术的过程中,我们整理了一些典型的设计错误清单。 有些错误是如此简单,以至似乎不可能。
●
索引不足→全面扫描例如,在非常偶然的情况下,没有关于战斗计划的索引。 我们有一个具体的示例,其中长时间没有索引就可以快速进行查询。 但是进行了全面扫描,并且随着表的大小逐渐增加,查询开始工作的速度变慢了,从一个季度到另一个季度,查询花费了更长的时间。 最后,我们注意了他,结果发现索引不存在。
●
大选择→全面扫描第二个常见错误是大数据样本-全扫描的经典案例。 所有人都知道,只有在真正合理的情况下才应使用全面扫描。 有时,在某些情况下,如果发现完全扫描,则可以不进行完全扫描,例如,将过滤条件从pl / sql代码转移到查询中。
●
无效索引→长INDEX RANGE SCAN也许这甚至是最常见的错误,出于某种原因他们很少说-所谓的无效索引(长索引扫描,长INDEX RANGE SCAN)。 例如,我们有一个注册表表。 在请求中,我们尝试查找该代理的所有注册表,并最终添加某种过滤条件,例如,在一定时期内,使用特定数量或使用特定客户。 在这种情况下,出于普遍使用的原因,索引通常仅建立在“ agent”字段上。 结果如下图所示:例如,在工作的第一年中,座席在此表中有100个条目,第二年已经有1000个条目,第二年可能有10,000个条目。 一段时间后,这些记录变为100,000。显然,该请求开始缓慢运行,因为在该请求中,您不仅需要添加代理标识符本身,而且还需要添加一些其他过滤器(在这种情况下,按日期)。 否则,事实证明,随着该代理的注册处数量的增加,样本量会逐年增加。 必须在索引级别解决此问题。 如果数据太多,那么我们应该已经考虑了分区的方向。
●
不必要的分发代码分支这也是一个奇怪的情况,但是尽管如此,它还是发生了。 我们查看最上面的查询,然后在那里看到一些奇怪的查询。 我们来到开发人员那里说:“我们找到了一些要求,让我们找出来,看看可以做什么。” 开发人员认为,然后过了一会儿说:“此代码分支不应在您的系统上。 您不使用此功能。” 然后,开发人员建议您打开一些特殊设置,以解决代码的这一部分。
个案研究
现在,我想考虑一下我们实际实践中的两个例子。 当我们处理最重要的查询时,我们当然首先要考虑这样一个事实,即应该有一些繁琐,繁琐的复杂操作。 实际上,并非总是如此。 有时在某些情况下,非常简单的查询属于最重要的操作。
例子1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
在此示例中,查询仅包含两个表,而这些表不是很重的表-只有几百万个记录。 看起来会更容易吗? 但是,请求达到了顶峰。
让我们尝试找出他的问题所在。
下面是来自企业管理器云控制的图片-有关此请求的统计数据(Oracle有这样的工具)。 可以看出,此请求有固定的负载(上图)。 侧面的数字1表示平均不超过一个会话正在运行。 绿色图显示该
请求仅使用CPU ,这很有趣。

让我们尝试找出这里发生了什么?

上表是根据要求提供统计信息的表格。 近70万次发射-这不会让任何人感到惊讶。 但是,从12月15日的“首次加载时间”到12月22日的“最后一次加载时间”(参见上图)的时间间隔为一周。 如果计算每秒的启动次数,那么
查询平均每秒执行一次 。
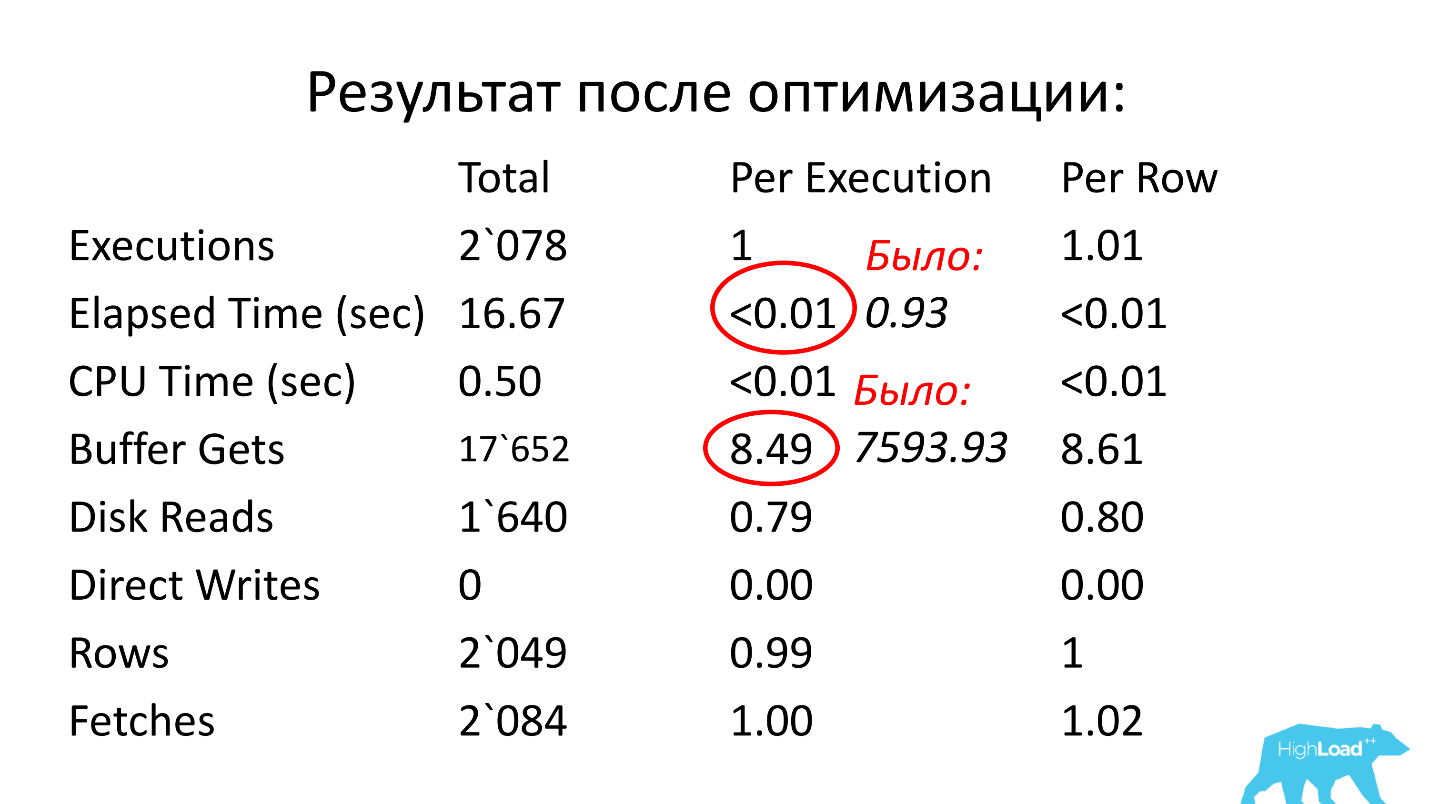
我们进一步看。 查询执行时间为0.93秒,即 不到一秒钟,那太好了。 我们可以高兴-请求并不繁重。 尽管如此,他还是名列前茅,这意味着他消耗了大量资源。 它在哪里消耗大量资源?
该表有一行用于逻辑读数。 我们看到,一次启动需要近8000个块(通常1个块为8 KB)。 事实证明,每秒处理一次的请求从内存加载大约64 MB的数据。 这里有些问题,我们需要了解。
让我们看一下计划:进行全面扫描。 好吧,让我们继续前进。
Plan hash value: 634977963
在rnko_dep_reestr_in_oper表中,只有500万行,其平均行长为150个字节。 但是事实证明,连接的字段没有足够的索引-子查询通过ean_rnko字段连接到请求,而该字段没有索引!
而且,即使他出现,实际上情况也不会很好。 该长索引扫描(长INDEX RANGE SCAN)将发生。 ean_rnko是代理的内部标识符。 代理注册表会累积,并且每年该请求选择的数据量将增加,而请求的速度将减慢。
解决方案:为ean_rnko和date_reg字段创建索引,要求开发人员在此请求中按日期限制扫描深度。 然后,您可以至少在某种程度上保证查询性能将保持在大致相同的边界上,因为样本大小将被限制为固定的时间间隔,并且不需要读取整个表。 这是很重要的一点,看看发生了什么。
经过优化后,运行时间变得小于百分之一秒(0.93),平均块数比以前减少了8.5-1000倍。
例子2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
我从说起故事开始,通常是在查询顶部出现一些复杂的情况。 上面是一个对一个表(!)进行“复杂”查询的示例,它也进入了顶部查询:) ID_PROCESSING字段上有一个索引!
此查询中有3个IS NULL条件,并且众所周知,此类条件未编制索引(在这种情况下,您不能使用索引)。 另外,只有两个相等类型的条件(通过ID_PROCESSING和STATUS)。
可能,查看此查询的开发人员首先会建议在ID_PROCESSING和STATUS上建立索引。 但是,鉴于将要选择的数据量(会有很多),该解决方案将不起作用。
但是,该请求消耗大量资源,这意味着需要做一些事情才能使其更快地工作。 让我们尝试找出原因。

上面的统计数据是1天,从中可以看出请求每5分钟启动一次。 主要资源消耗是CPU和磁盘读取。 在具有查询启动次数统计信息的图表下方,可以看到一切都井井有条-启动次数几乎不会随时间变化-情况相当稳定。

如果进一步看,您会发现查询时间有时会相差很大-多次,这已经很重要了。
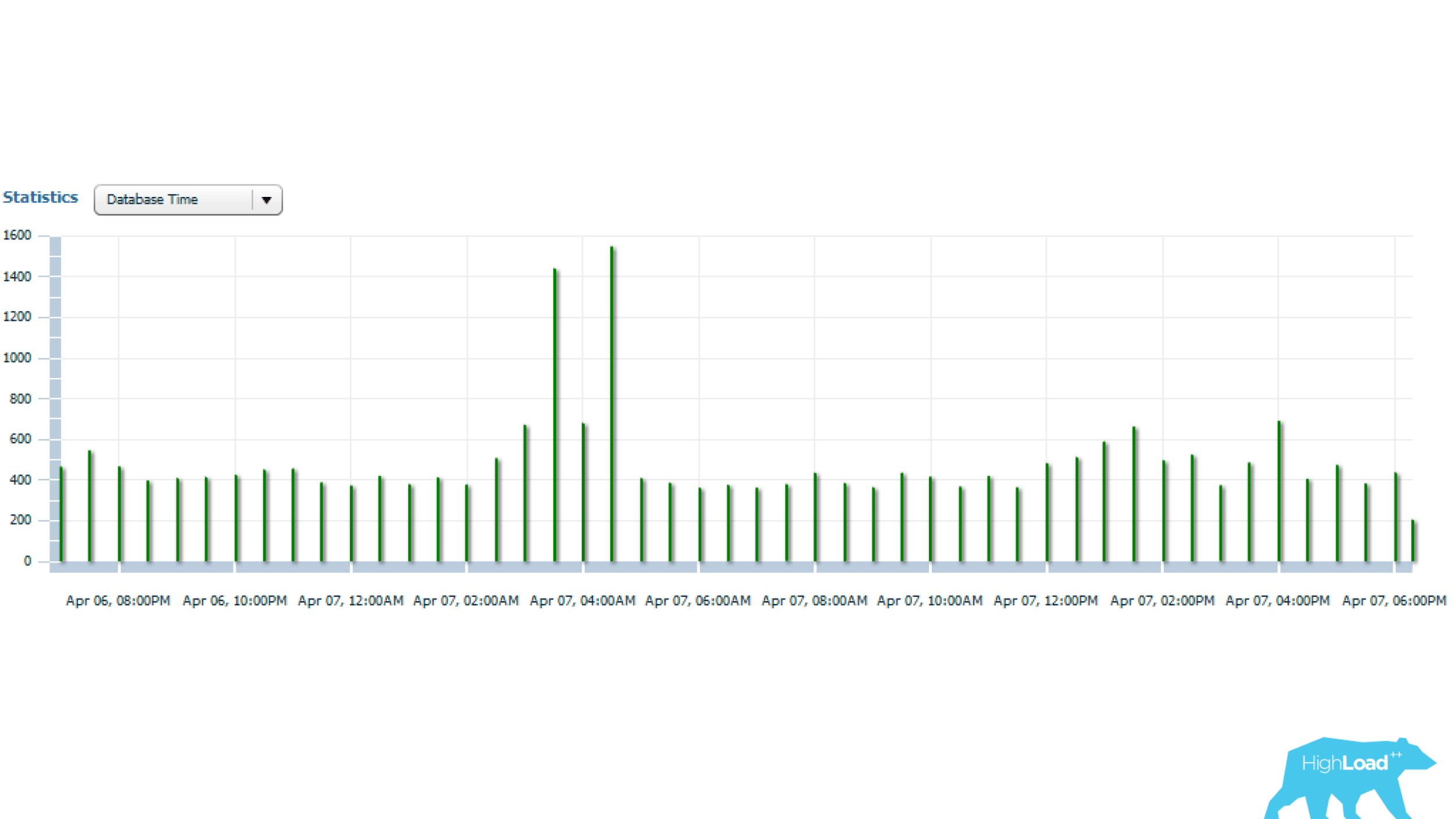
接下来让我们弄清楚。
Oracle Enterprise Manager具有SQL监视实用程序。 使用此实用程序,您可以根据请求实时查看资源消耗情况。

以上报告有问题。 首先,我们应该对“实际行数”列中的“索引范围扫描”(底部线)显示1700万行这一事实感兴趣。 大概值得考虑。
如果我们进一步看一下实施计划,结果发现,在计划的下一个项目之后,在这1,700万行中,仅剩下1705条,问题是,为什么选择1,700万? 最终样品中剩余约0.01%,即
显然效率低下,做了不必要的工作 。 此外,这项工作每5分钟完成一次。 这是问题所在! 因此,此请求命中了最前面的查询。
让我们尝试解决这个非同寻常的问题。 首先乞求自己的索引效率很低,因此您需要提出一些棘手的问题并克服IS NULL条件。
新指数
我们与开发人员进行了协商,认为并做出了以下决定:我们创建了一个功能索引,其中包含一个ID_PROCESSING列,该列在请求中具有相等条件,并且我们将所有其他字段作为该函数的参数包括在内:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
此函数的类型是确定性的,也就是说,对于同一组参数,它始终给出相同的答案。 我们确保该函数始终返回一个值-在这种情况下为“ U”。 当所有这些条件都满足时,将发出“ U”,如果不满足,则发出NULL。 这样的功能索引使得可以有效地过滤数据。
应用该索引得出以下结果:
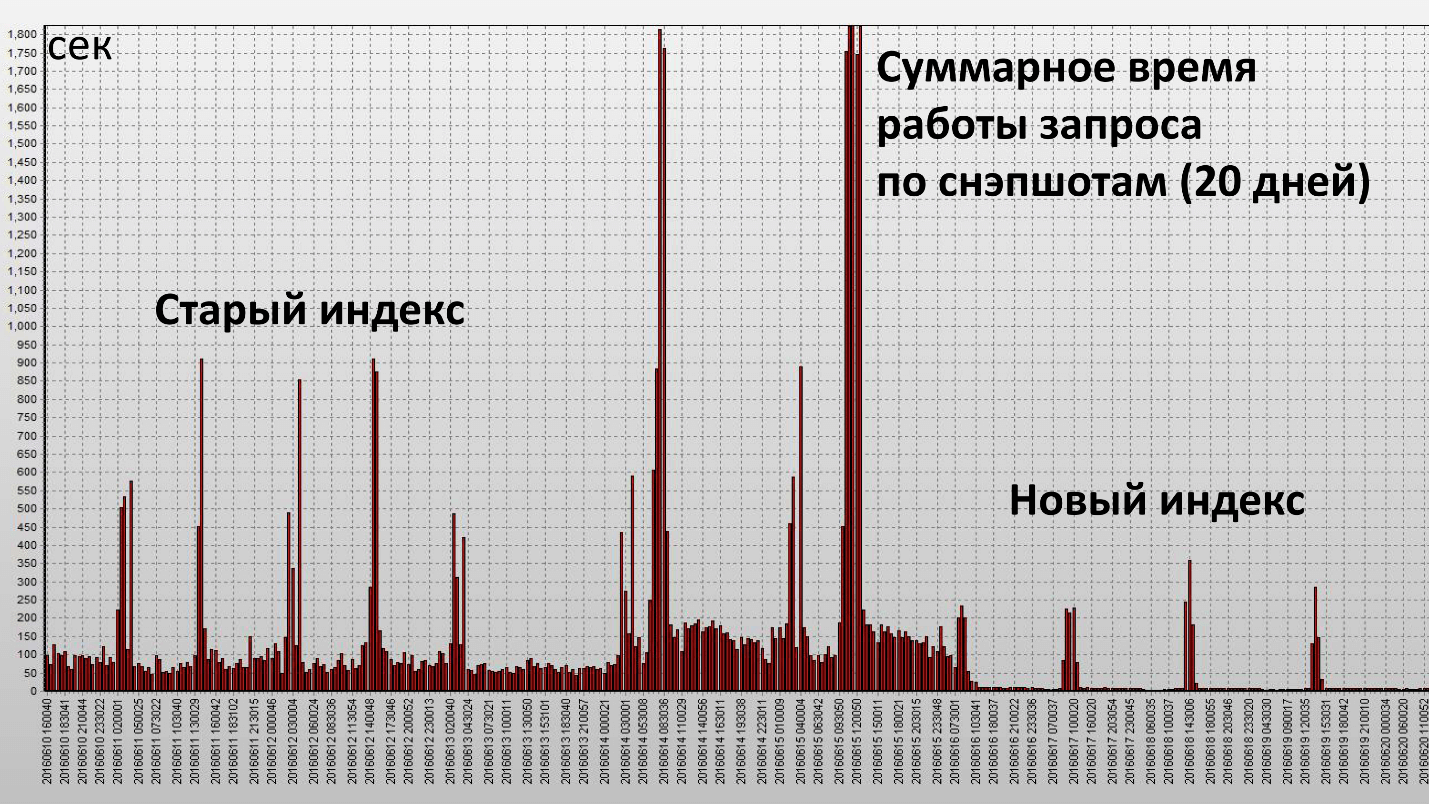
在这里,一栏是一个快照,它们每半小时在数据库中完成一次。 我们已经实现了我们的目标,该指数确实非常有效。 让我们看看定量特征:
平均请求统计
|
| 之前
| 之后
|
经过时间,秒
| 143.21
| 60.7
|
CPU时间,秒
| 33.23
| 45.38
|
缓冲区获取块
| 6`288`237.67
| 1`589`836
|
磁盘读取块
| 266`600.33
| 2`680
|
运行时间减少了2.5倍,资源消耗(缓冲区获取)减少了大约4。从磁盘读取的数据块数量大大减少。
主动优化结果
我们已经收到:
- 减轻数据库的负担;
- 提高数据库的稳定性;
- 大大减少了软件性能事件的数量。
表演事件减少了10倍 。 这是一个主观的金额,在苏格兰皇家银行-零售银行综合大楼每月发生1-2次事件之前,但现在我们几乎已经将其遗忘了。
这就提出了一个问题-软件性能事件如何处理? 我们没有直接与他们打交道吗?
返回上一个时间表。 如果您还记得,曾经进行过全面扫描,则需要在内存中存储大量块。 由于请求是定期执行的,因此所有这些块都存储在Oracle缓存中。 事实证明,如果这时数据库中出现高负载,例如有人开始主动使用内存,则将需要缓存来存储数据块。 因此,用于我们请求的部分数据将被挤出,这意味着我们将不得不进行物理读取。 如果您进行物理读取,查询运行时间将立即大大增加。
逻辑读取正在使用内存,它会很快发生,并且对磁盘的任何访问速度都很慢(如果您查看时间,以毫秒为单位)。 如果您很幸运,并且操作系统的高速缓存或阵列高速缓存中有此数据,那么它仍将是数十微秒。 从Oracle的缓存中读取数据要快得多。
当我们摆脱了全盘扫描时,在缓存(Buffer Cache)中存储如此大量块的需求就消失了。 当这些资源不足时,请求或多或少是稳定的。 旧索引不再有如此大的峰值。
主动优化摘要:- 初始查询优化应在测试服务器上进行,以查看查询及其业务逻辑的工作方式,以免做多余的事情。 这些作品仍然存在。
- 但是定期(每隔几个月一次)从服务器中删除满负荷报告,搜索数据库中的热门查询和操作并对其进行优化是有意义的。
有许多工具可用于获取Oracle数据库中的统计信息:- AWR报告(DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- 企业管理器云控制12c(SQL详细信息);
- SQL详细信息活动报告(DBMS_PERF.report_sql);
- SQL监视(EMCC中的选项卡);
- SQL监视报告(DBMS_SQLTUNE.report_sql_monitor *)。
其中一些工具可在控制台中使用,也就是说,它们不与企业管理器绑定。
奖励: RNCO“付款中心”和CFT
的专家为在新西伯利亚举行的会议做好了充分的准备,做了一些有用的报道,还组织了一个真正的出口电台。 两天来,专家,演讲者和组织者设法访问了CFT电台。 您可以通过添加条目来回到西伯利亚的夏天,这是各部分的链接:
Kubernetes:优缺点 ;
数据科学与机器学习 ;
DevOps 。
在11月8日和9日已经在莫斯科举行的HighLoad ++上,将会有更多有趣的事情。 该计划包括合作伙伴的高负荷项目,大师班,会议和活动的所有方面的报告,他们将分享专家的建议并发现令人惊讶的地方。 请务必写出最有趣的文章,并在时事通讯中进行通知,以取得联系!