GraphQL查询语言是什么? 这项技术提供了哪些优势?开发人员在使用该技术时会面临哪些问题? 如何有效使用GraphQL? 关于这一切的削减。

本文基于
2017年Joker会议的
Vladimir Tsukur (
volodymyrtsukur )的介绍水平报告。
我叫弗拉基米尔(Vladimir),我负责WIX部门之一的开发。 超过一亿的WIX用户创建了各种方向的网站-从名片网站和商店到复杂的Web应用程序,您可以在其中编写代码和任意逻辑。 作为WIX上一个项目的生动示例,我想向您展示成功的网站商店
unicornadoptions.com ,该网站提供了购买驯服独角兽的工具包的机会-这是给孩子的好礼物。

该站点的访问者可以选择他们喜欢驯服独角兽的工具箱(例如粉红色),然后查看该工具箱中的确切内容:玩具,证书,徽章。 此外,购买者有机会将商品添加到购物篮,查看其内容并下订单。 这是商店站点的一个简单示例,我们有成百上千的此类站点。 所有这些都建立在具有一个后端的同一平台上,并且我们为此使用API支持了一组客户端。 关于API,将进一步讨论。
简单的API及其问题
让我们想象一下可以创建哪个通用API(即平台顶部所有商店的一个API)来提供商店功能。 让我们仅专注于获取数据。
对于此类站点上的产品页面,应返回产品名称,价格,图片,描述,其他信息等。 在WIX商店的完整解决方案中,有超过两个这样的数据字段。 在HTTP API上执行此类任务的标准解决方案是描述
/products/:id资源,该资源返回
GET请求中的产品数据。 以下是响应数据的示例:
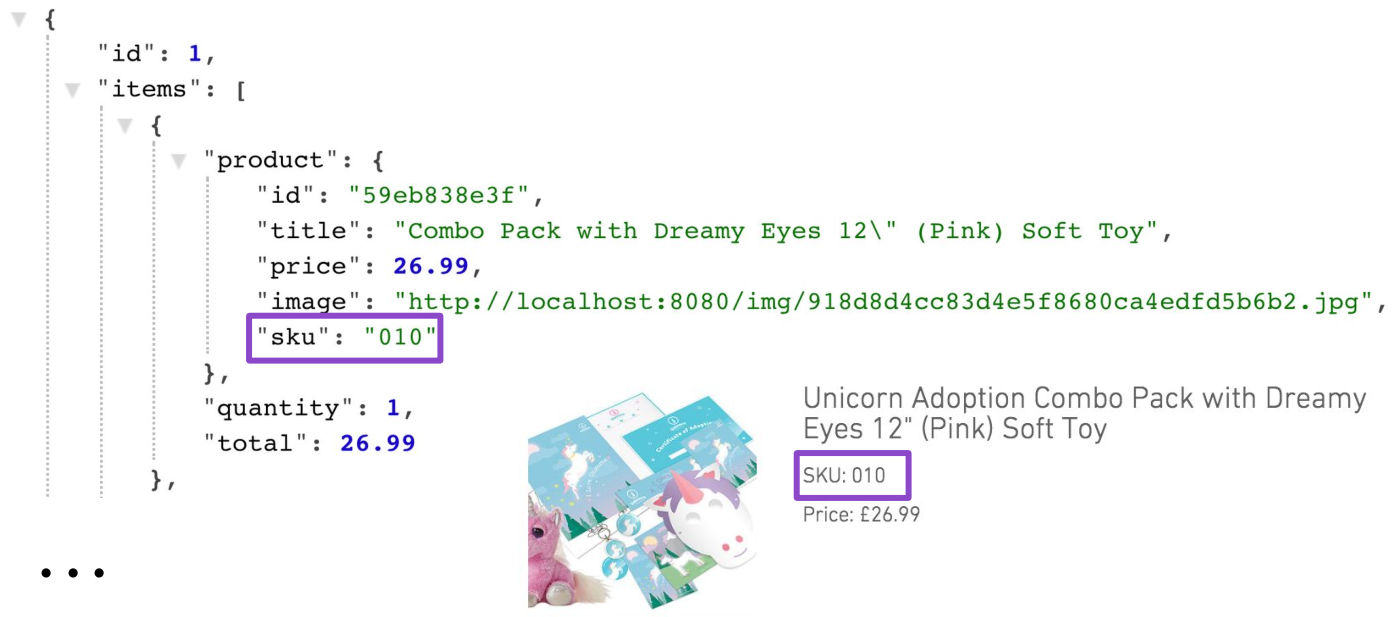
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

现在让我们看一下产品目录页面。 对于此页面,您需要
/ products资源集合。 但是,仅在目录页面上显示产品集合时,并不需要所有产品数据,而仅需要价格,名称和主图像。 例如,描述,附加信息,背景图像等对我们而言并不重要。

为了简单起见,假设我们决定对资源
/products和
/products/:id使用相同的产品数据模型。 在收集此类产品的情况下,可能会有几种。 响应方案可以表示如下:
GET /products [ { title price images description info ... } ]
现在,让我们看一下服务器对产品集合的响应的“有效负载”。 这是客户在两个以上字段中实际使用的内容:
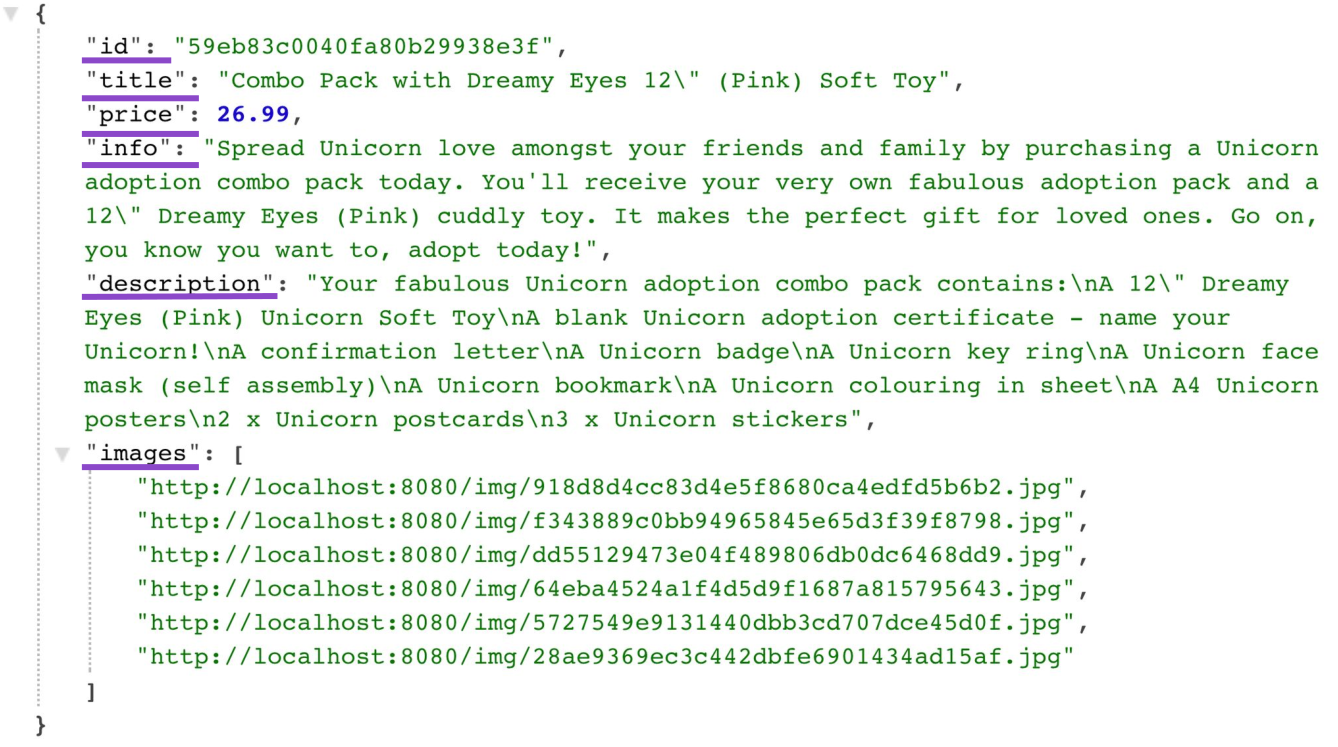
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}显然,如果我想通过返回相同的数据来保持产品模型的简单性,那么我将遇到一个过度获取的问题,在某些情况下,获取的数据比我需要的多。 在这种情况下,这会出现在产品目录页面上,但是通常,以某种方式与产品连接的任何UI屏幕都可能只需要其中一部分(而不是全部)数据。
现在让我们看一下购物车页面。 在购物篮中,除了产品本身之外,还有数量(在此购物篮中),价格以及整个订单的总费用:

如果继续使用HTTP API的简单建模方法,则可以通过resource
/ carts /:id来表示该购物篮,其表示形式是指添加到此购物篮的产品资源:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
现在,例如,为了在前端绘制一个包含三个产品的购物篮,您需要发出四个请求:一个请求本身加载购物篮,三个请求以加载产品数据(名称,价格和SKU编号)。
我们遇到的第二个问题是获取不足。 篮子和产品资源之间的责任区分导致需要提出其他要求。 显然这里存在许多弊端:由于请求数量增加,我们更快地降低了手机的电池电量,而获得完整答案的速度却越来越慢。 而且我们解决方案的可扩展性也引发了疑问。
当然,这种解决方案不适合生产。 解决该问题的一种方法是为篮子增加投影支撑。 除购物篮本身的数据外,此类预测之一还可以返回有关产品的数据。 此外,此预测将非常具体,因为您需要在购物篮页面上输入产品的库存编号(SKU)。 在其他任何地方都不需要SKU。
GET /carts/1?projection=with-products
针对特定UI的这种“适合”资源通常不会结束,并且我们开始生成其他预测:关于购物篮的简要信息,针对移动网络的购物篮投影,然后是针对独角兽的投影。

(通常,在WIX Designer中,您作为用户可以配置要在产品页面上显示的产品数据以及要在购物篮中显示的数据)
在这里,困难仍在等待着我们:我们正在构筑花园并寻找复杂的解决方案。 从API的角度来看,针对这种任务的标准解决方案很少,它们通常在很大程度上取决于框架或HTTP资源描述库。
更为重要的是,现在工作变得越来越困难,因为当客户端的需求发生变化时,后端必须不断“追赶”并满足它们。
作为“蛋糕上的樱桃”,让我们来看另一个重要的问题。 对于简单的HTTP API,服务器开发人员不知道客户端使用的是哪种数据。 使用价格了吗? 说明? 一幅或全部图像?
因此,出现了几个问题。 如何处理已过时/过时的数据? 我如何知道不再使用哪些数据? 从响应中删除数据而不破坏大多数客户端相对安全吗? 通常的HTTP API无法回答这些问题。 尽管我们很乐观并且API看起来很简单,但情况似乎并不那么热。 API问题的范围不是WIX独有的。 许多公司不得不与他们打交道。 现在来看一个潜在的解决方案很有趣。
GraphQL。 开始
2012年,在开发移动应用程序的过程中,Facebook面临类似的问题。 工程师希望实现对服务器的移动应用程序调用的最小数量,而在每个步骤中,他们仅接收必要的数据,而仅接收到它们。 他们努力的结果是在2015 React Conf会议上展示的GraphQL。 GraphQL是查询描述语言,也是这些查询的运行时环境。

考虑使用GraphQL服务器的典型方法。
我们描述方案
GraphQL中的数据模式定义了它们之间的类型和关系,并以强类型的方式定义了它们。 例如,想象一个简单的社交网络模型。
User了解
friends 。 用户生活在城市中,城市通过
citizens字段了解其居民。 这是GraphQL中这种模型的图形:
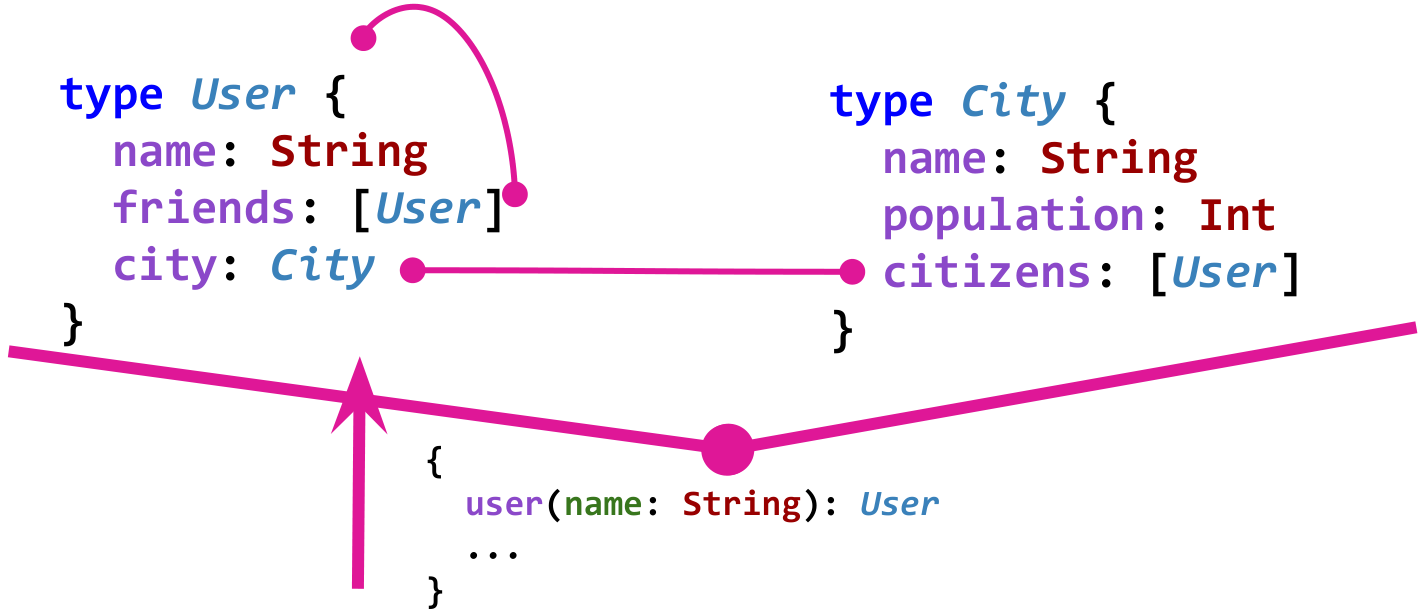
当然,为了使图表有用,还需要所谓的“入口点”。 例如,这样的入口点可能是通过名称获取用户。
索取资料
让我们看看GraphQL查询语言的本质是什么。 让我们将这个问题翻译成这种语言:
“对于一个名叫Vanya Unicorn的用户,我想知道他的朋友的名字,以及Vanya所居住城市的名称和人口” :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } }
这是来自GraphQL服务器的答案:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
请注意,请求表单与响应表单是“辅音”。 感觉这种查询语言是为JSON创建的。 具有强大的打字能力。 所有这些都是在一个HTTP POST请求中完成的-无需多次调用服务器。
让我们看看它在实际中的外观。 让我们打开GraphQL服务器的标准控制台,这称为Graph
i QL(“图形”)。 要请求购物篮,我将满足以下要求:
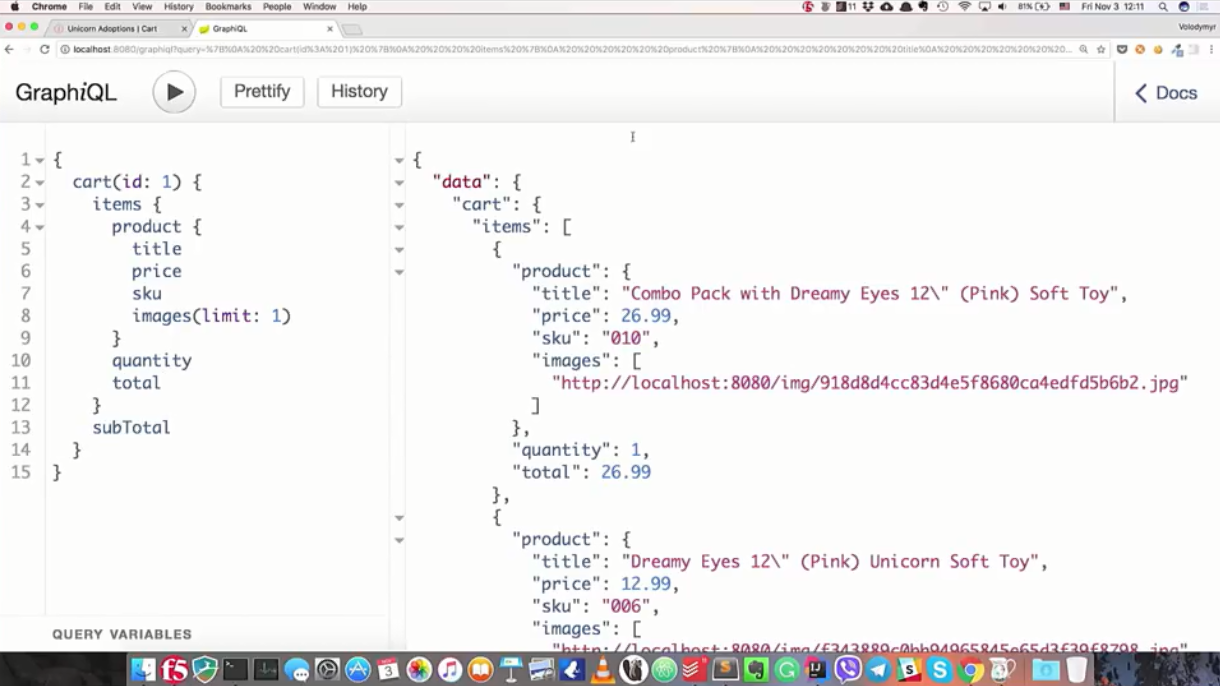
“我想通过标识1获取购物篮,我对该购物篮的所有位置和产品信息感兴趣。 从信息中,名称,价格,库存编号和图像很重要(并且只有第一个)。 我还对这些产品的数量,价格和篮子里的总成本感兴趣 。
” { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
成功完成请求后,我们将得到确切的要求:
主要好处
- 灵活的采样。 客户可以根据自己的具体要求提出要求。
- 有效采样。 响应仅返回请求的数据。
- 发展更快。 客户端上可以进行许多更改,而无需在服务器端进行任何更改。 例如,根据我们的示例,您可以轻松显示移动网络购物篮的其他视图。
- 有用的分析。 由于客户端必须在请求中显式指示字段,因此服务器确切知道真正需要哪些字段。 这是弃用政策的重要信息。
- 适用于任何数据源和传输。 GraphQL允许您在任何数据源和任何传输之上工作,这一点很重要。 在这种情况下,HTTP并不是万能的,GraphQL也可以通过WebSocket运行,稍后我们将讨论这一点。
如今,几乎可以使用任何语言制作GraphQL服务器。 GraphQL服务器的最完整版本是用于Node平台的
GraphQL.js 。 在Java社区中,参考实现是
GraphQL Java 。
创建GraphQL API
让我们看看如何在一个具体的生活示例中创建GraphQL服务器。
考虑一个基于微服务架构的在线商店的简化版本,该架构具有两个组件:
- 提供定制篮子服务的购物车服务。 将数据存储在关系数据库中,并使用SQL访问数据。 非常简单的服务,没有太多的魔法:)
- 产品服务提供对产品目录的访问,实际上是从该目录中填充了购物篮。 提供用于访问产品数据的HTTP API。
两种服务都在经典的Spring Boot之上实现,并且已经包含所有基本逻辑。
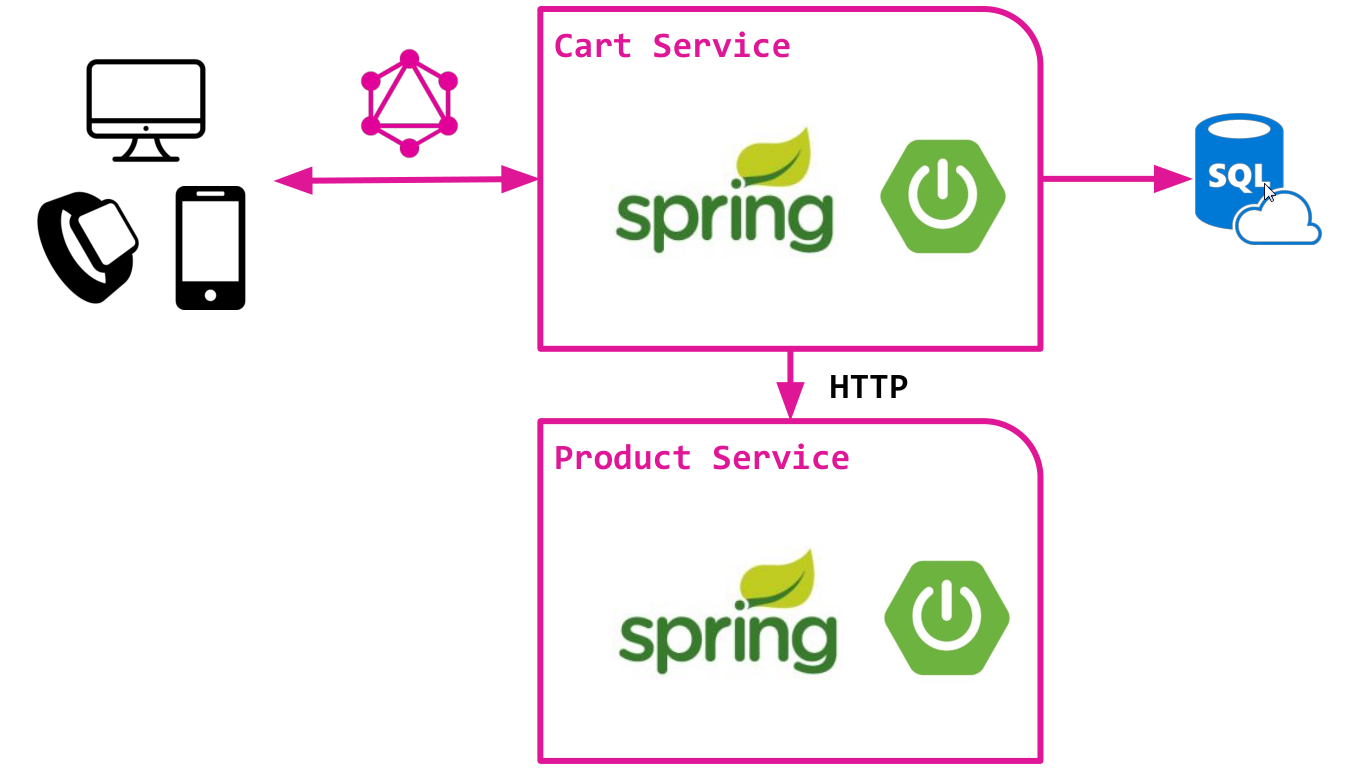
我们打算在Cart服务的顶部创建GraphQL API。 此API旨在提供对购物篮数据和添加到其中的产品的访问。
第一版
我们前面提到的Java生态系统的GraphQL参考实现-GraphQL Java,将为我们提供帮助。
向
pom.xml:添加一些依赖项
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
除了前面提到的
graphql-java我们还将需要一个
graphql-java-tools,库
graphql-java-tools,以及GraphQL的Spring Boot“启动器”,这将大大简化创建GraphQL服务器的第一步:
- graphql-spring-boot-starter提供了一种将GraphQL Java快速连接到Spring Boot的机制。
- graphiql-spring-boot-starter添加了一个交互式Graph i QL Web控制台来运行GraphQL查询。
下一个重要步骤是确定graphQL服务方案,即我们的图形。 该图的节点使用
类型描述,而边使用
字段描述 。 空图定义如下所示:
schema { }
您记得,在这种方案中,存在“入口点”或顶级查询。 它们是通过模式中的
查询字段定义的。 调用我们的
EntryPoints入口
点类型:
schema { query: EntryPoints }
我们在其中定义按标识符进行篮子搜索作为第一个入口点:
type EntryPoints { cart(id: Long!): Cart }
Cart仅是GraphQL术语中的一个
字段 。
id是标量类型
Long的此字段的参数。 感叹号
! 指定类型后,表示该参数是必需的。
是时候识别并输入
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
除标准
id ,购物篮还包括其item元素和所有
subTotal产品的金额。 请注意,
项目定义为列表,如方括号
[] 。 此列表的元素是
CartItem类型。 字段类型名称后面有一个感叹号
! 表示必填字段。 这意味着如果请求,服务器同意为该字段返回一个非空值。
剩下的要看的是
CartItem类型的定义,其中包括指向产品(
productId )的链接,将其添加到购物篮的次数(number)和产品的数量(根据数量(
total )计算):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
这里的一切都很简单-标量类型的所有字段都是必填字段。
这个方案并非偶然。 Cart服务已经使用与GraphQL模式中完全相同的字段名称和类型定义了
CartItem购物篮及其
CartItem元素。 cart模型使用Lombok库自动生成getter / setter,构造函数和其他方法。 JPA用于数据库中的持久性。
Cart类别:
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
CartItem类别:
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
因此,在GraphQL图和代码中都描述了购物篮(
Cart )和购物篮元素(
CartItem ),它们根据字段集及其类型相互“兼容”。 但这还不足以使我们的服务正常工作。
我们需要明确说明入口点“
cart(id: Long!): Cart ”的工作方式。 为此,请使用GraphQLQueryResolver类型的bean为Spring创建一个非常简单的Java配置。 GraphQLQueryResolver仅描述架构中的“入口点”。 我们定义一个名称与入口点(
cart )的字段相同的方法,使其与参数类型兼容,并使用
cartService通过标识符查找相同的cart:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
这些更改足以使我们获得有效的应用程序。 在GraphiQL控制台中重新启动Cart服务后,以下查询将开始成功执行:
{ cart(id: 1) { items { productId quantity total } subTotal } }
注意事项
- 我们使用标量类型
Long和String作为购物篮和产品的唯一标识符。 GraphQL为此具有特殊的类型ID 。 从语义上来说,这对于真实的API是更好的选择。 ID类型的值可以用作缓存的键。
- 在我们应用程序开发的现阶段,内部和外部域模型是完全相同的。 我们正在谈论
Cart和CartItem以及它们在GraphQL解析器中的直接使用。 在战斗应用中,建议将这些模型分开。 对于GraphQL解析器,必须存在与内部主题区域分开的模型。
使API有用
所以我们得到了第一个结果,这真是太好了。 但是现在我们的API太原始了。 例如,到目前为止,尚无方法请求产品的有用数据,例如其名称,价格,商品,图片等。 相反,只有
productId 。 让我们使该API真正有用,并添加对产品概念的全面支持。 这是它的定义在图中的样子:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
将必填字段添加到
CartItem ,并将productId字段
productId为已弃用:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
我们想出了方案。 现在是时候描述
product领域的选择如何工作了。 之前,我们在
Cart和
CartItem依赖于getter方法,从而使GraphQL Java自动绑定值。 但是在这里应该记得,
CartItem类中的
product属性不是:
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
我们可以选择:
- 将产品属性添加到CartItem并“教”它如何接收产品数据;
- 确定如何获取产品而不更改CartItem类。
第二种方法是可取的,因为在这种情况下内部域的描述模型(
CartItem类)将不包含Graph
i QL API的实现细节。
为了实现此目标,GraphQLResolver标记器接口将有所帮助。 通过实现它,您可以确定(或覆盖)如何获取类型
T的字段值
T 这是相应的bean在Spring配置中的样子:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
product方法的名称不是偶然选择的。 GraphQL Java正在按字段名称寻找数据下载器方法,我们只需要为
product字段定义一个加载器! 作为参数传递的
CartItem类型的对象定义了选择产品的上下文。 接下来是技术问题。 使用诸如
RestTemplate类的
http客户端
RestTemplate我们向Product服务发出GET请求,并将结果转换为
Product ,如下所示:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
这些更改应足以实施更有趣的示例,其中包括购物篮与添加到其中的产品之间的真实关系。
重新启动应用程序后,您可以在Graph
i QL控制台中尝试新的查询。
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
这是查询执行的结果:

尽管
productId被标记为
@deprecated ,但指示该字段的查询将继续起作用。 但是Graph
i QL控制台不会为此类字段提供自动完成功能,而是以特殊方式突出显示它们的用法:

现在该展示Graph
i QL控制台的一部分的Document Explorer了,它是基于GraphQL模式构建的,并显示所有已定义类型的信息。 这是
CartItem类型的文档资源管理器的外观:

但是回到例子。 为了实现与第一个演示中相同的功能,返回的图像数量仍然没有足够的限制。 确实,例如,对于一个购物篮,每个产品只需要一个图像:
images(limit: 1)
为此,请更改方案,然后将
图像字段的新参数添加到
产品类型:
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
在应用程序代码中,我们将再次使用它GraphQLResolver,仅这次按类型Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
我再次提请注意以下事实:方法的名称并非偶然:它与字段的名称一致images。上下文对象Product可以访问图像,并且limit是字段本身的参数。如果客户未将任何值指定为limit,则我们的服务将返回该产品的所有图像。如果客户端指定了一个特定值,则该服务将返回的值与返回值完全相同(但不超过产品中的值)。我们编译项目,然后等待服务器重新启动。在控制台中重新启动电路并执行请求,我们看到一个完整的请求确实有效。 { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
同意,这一切都很酷。在短时间内,我们不仅了解了GraphQL,而且还转移了一个简单的微服务系统来支持此类API。对于我们来说,数据来自哪里并不重要:SQL和HTTP API都可以很好地融合在一起。代码优先和GraphQL SPQR方法
您可能已经注意到,在开发过程中存在一些不便之处,即需要不断保持GraphQL模式和代码同步。类型更改始终必须在两个地方进行。在许多情况下,使用代码优先方法更为方便。其实质是GraphQL的架构是从代码自动生成的。在这种情况下,您无需单独维护电路。现在,我将展示它的外观。仅GraphQL Java的基本功能对我们来说还不够,我们还需要GraphQL SPQR库。好消息是GraphQL SPQR是GraphQL Java的附加组件,而不是Java中GraphQL服务器的替代实现。将所需的依赖项添加到pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
这是为篮子实现相同的基于GraphQL SPQR的功能的代码: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
对于产品: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
@GraphQLQuery批注用于标记字段加载器方法。注释@GraphQLContext定义了字段的选择类型。注释@GraphQLArgument清楚地标记了参数参数。所有这些都是一种机制的一部分,可以帮助GraphQL SPQR自动生成模式。现在,如果删除旧的Java配置和方案,并使用GraphQL SPQR中的新芯片重新启动Cart服务,则可以确保所有工作均与以前相同。我们解决N + 1的问题
现在是时候看看b 上 lshih详细介绍了如何“引擎盖下”全要求的执行。我们快速创建了GraphQL API,但是它能有效地工作吗?请考虑以下示例: 获取篮子
获取篮子cart发生在对数据库的一个SQL查询中。数据items并在subtotal那里返回,因为根据急切的获取JPA策略,购物篮元素已随整个集合一起加载: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 当下载产品上的数据时,对产品服务的请求将与该系列产品中的请求完全一样地执行。如果购物篮中有三种不同的产品,那么我们将收到三个对产品服务的HTTP API的请求,如果有十种,那么同一服务将必须回答十个此类请求。
当下载产品上的数据时,对产品服务的请求将与该系列产品中的请求完全一样地执行。如果购物篮中有三种不同的产品,那么我们将收到三个对产品服务的HTTP API的请求,如果有十种,那么同一服务将必须回答十个此类请求。 这是Charles Proxy中Cart服务和Product服务之间的通信:
这是Charles Proxy中Cart服务和Product服务之间的通信: 因此,我们回到经典的N + 1问题。正是他们在报告一开始就竭尽全力摆脱的那个人。毫无疑问,我们取得了进步,因为在最终客户端和我们的系统之间只执行了一个请求。但是在服务器生态系统内,性能显然需要提高。我想通过在一个请求中获得所有合适的产品来解决此问题。幸运的是,产品服务已经通过
因此,我们回到经典的N + 1问题。正是他们在报告一开始就竭尽全力摆脱的那个人。毫无疑问,我们取得了进步,因为在最终客户端和我们的系统之间只执行了一个请求。但是在服务器生态系统内,性能显然需要提高。我想通过在一个请求中获得所有合适的产品来解决此问题。幸运的是,产品服务已经通过ids收集资源中的参数支持此功能: GET /products?ids=:id1,:id2,...,:idn
让我们看看如何修改product字段的示例方法代码。先前版本: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
替换为更有效的一个: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
我们做了三件事:- 用@Batched批注标记引导加载程序方法,以便GraphQL SPQR清楚加载应该批量进行;
- 将返回类型和上下文参数更改为列表,因为使用批处理假定已接受并返回了多个对象;
- 改变了方法的主体,一次实现了所有必要产品的选择。
这些更改足以解决我们的N + 1问题。现在,“ Charles Proxy”应用程序窗口将向Product服务显示一个请求,该请求将立即返回三个产品:
有效现场样本
我们解决了主要问题,但是您可以使选择更快!现在,无论最终客户需要什么,产品服务都会返回所有数据。我们可以改进查询并仅返回请求的字段。例如,如果最终客户未要求提供图片,为什么我们需要将其转移到购物车服务?很棒的一点是,Product服务的HTTP API已经通过相同集合资源的include参数支持此功能: GET /products?ids=...?include=:field1,:field2,...,:fieldN
对于bootloader方法,添加带有注释的Set类型的参数@GraphQLEnvironment。GraphQL SPQR了解这种情况下的代码“请求”了产品所要求的字段名称列表,并自动将其填写在: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
现在我们的样本非常有效,没有N + 1问题,仅使用必要的数据:
“大量”查询
想象一下在经典的社交网络(例如Facebook)中使用用户图的情况。如果此类系统提供了GraphQL API,则不会阻止客户端发送以下性质的请求: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
在5-6层的嵌套级别,完全执行此请求将导致选择世界上所有用户。服务器肯定无法一次坐下来应付这样的任务,并且很可能会“跌倒”。为了保护自己免受此类情况的侵害,必须采取多种措施:- 限制请求深度。换句话说,不应允许客户请求任意嵌套的数据。
- 限制请求的复杂性。通过为每个字段分配权重并计算请求中所有字段的权重之和,您可以在服务器上接受或拒绝此类请求。
例如,考虑以下查询: { cart(id: 1) { items { product { title } quantity } subTotal } }
显然,此类请求的深度为4,因为最长的路径在其中cart -> items -> product -> title。如果我们假设每个字段的权重为1,则考虑到查询中的7个字段,其复杂度也为7。在GraphQL Java中,通过在创建对象时指示其他工具来实现检查的叠加GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
仪表MaxQueryDepthInstrumentation检查请求的深度和不允许运行太“深”的要求(在这种情况下-一个深度大于3)。仪表MaxQueryComplexityInstrumentation请求计数的执行之前,并验证其复杂性。如果此数字超过指定的值(20),则将拒绝此类请求。您可以重新定义每个字段的权重,因为其中某些字段显然比其他字段“更难”。例如,可以通过@GraphQLComplexity,GraphQL SPQR支持的注释将乘积字段分配给复杂性10 : @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
这是深度检查明显超过指定值时的示例: 顺便说一下,检测机制不限于施加限制。它也可以用于其他目的,例如日志记录或跟踪。我们研究了针对GraphQL的“保护”措施。但是,无论API的类型如何,都有许多技巧值得关注:
顺便说一下,检测机制不限于施加限制。它也可以用于其他目的,例如日志记录或跟踪。我们研究了针对GraphQL的“保护”措施。但是,无论API的类型如何,都有许多技巧值得关注:- 节流/速率限制-限制每单位时间的请求数
- 超时-与其他服务,数据库等一起进行操作的时间限制;
- 分页-分页支持。
数据突变
到目前为止,我们一直在考虑纯粹的数据采样。但是GraphQL允许您不仅有机地组织数据的接收,还组织它们的更改。这有一个机制mutation: schema { query: EntryPoints, mutation: Mutations }
例如,可以通过以下突变来组织将产品添加到购物篮中: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
这类似于定义字段,因为变异也具有参数和返回值。使用GraphQL SPQR在服务器代码中实现突变的方法如下: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
当然,大多数有用的工作都是在内部完成的cartService。这个中间层方法的任务是将其与API关联。与数据采样一样,由于有了注释,因此@GraphQL*很容易理解从该方法定义生成的GraphQL模式。在GraphQL控制台中,您现在可以执行更改请求,以将特定产品添加到我们的购物篮中,数量为2: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
由于突变具有返回值,因此可以根据与普通样本相同的规则向其请求字段。一些WIX开发团队正在积极地将GraphQL与Scala和Sangria库一起使用,Sangria库是该语言中GraphQL的主要实现。WIX中使用的一种有用技术是在呈现HTML时支持GraphQL查询。我们这样做是为了直接在页面代码中生成JSON。以下是填充HTML模板的示例: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
这是输出: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
HTML渲染器和GraphQL服务器的这种组合使我们可以最大程度地重用我们的API,而无需创建额外的控制器层。而且,该技术通常在性能方面具有优势,因为在加载页面后,JavaScript应用程序不需要进入后端就可以获取第一个必要的数据-它已经在页面上了。GraphQL的缺点
如今,GraphQL使用了许多公司,包括GitHub,Yelp,Facebook等巨人。而且,如果您决定加入他们的团队,那么您不仅应该知道GraphQL的优点,也应该知道它的缺点,其中有很多:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
还需要记住的是,如果您未能成功开发HTTP API,很可能将无法开发GraphQL API。毕竟,在任何API的开发中最重要的是什么?将内部域模型与外部API模型分开。根据使用情况而不是应用程序的内部设备构建API。仅打开必要的最少信息,而不是全部打开。选择正确的名称。正确描述图形。 HTTP API中有一个资源图,而GraphQL API中有一个字段图。在这两种情况下,都必须定性地绘制该图。HTTP API世界中有多种选择,当您需要复杂的选择时,您不必总是使用GraphQL。例如,存在OData标准,该标准支持部分选择和扩展选择,例如GraphQL,并且可以在HTTP之上工作。有一个与JSON一起使用的标准JSON API,并支持超媒体和复杂的提取功能。另外还有LinkRest,您可以从Andrus Adamchik在Joker 2017上的https://youtu.be/EsldBtrb1Qc“>报告中了解更多信息。对于那些想尝试GraphQL的人,我强烈建议阅读那些精通该技术的工程师的比较文章。从实践和哲学的角度来看REST和GraphQL:最后关于订阅和延迟
GraphQL与标准API相比有一个有趣的优势。在GraphQL中,同步和异步用例都可以放在同一屋檐下。我们考虑过通过您接收数据,通过来query更改服务器的状态mutation,但是还有另外一个好处。例如,组织订阅的能力subscriptions。想象一下,一个客户想要接收有关异步将产品添加到购物篮的通知。通过GraphQL API,可以基于以下方案完成此操作: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
客户可以通过以下请求进行订阅: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
现在,每次将产品添加到购物篮1时,服务器都会在WebSocket上向每个订阅的客户端发送一条消息,其中包含请求的数据。同样,继续执行GraphQL策略,只有客户端在订阅时请求的数据才会出现: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
客户现在可以重新绘制购物篮,而不必重新绘制整个页面。这很方便,因为可以通过GraphQL描述同步API(HTTP)和异步API(WebSocket)。使用异步通信的另一个示例是延迟机制。主要思想是,客户端选择他希望立即(同步)接收的数据,以及他准备稍后接收(异步)的数据。例如,对于这样的请求: query { feedStories { author { name } message comments @defer { author { name } message } } }
服务器将首先返回作者和每个故事的消息: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
之后,接收到注释数据的服务器将通过WebSocket异步将其传送到客户端,并在路径中指出现在已准备好历史注释: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
样本来源
可以在GitHub上找到用于准备此报告的代码。最近,我们宣布了JPoint 2019,它将于2019年4月5日至6日举行。您可以从我们的中心了解有关会议期望的更多信息。直到12月1日,Early Bird门票仍将以最低价出售。