在Profi.ru上建立客户端路由/语义搜索并将任意外部语料聚类
TLDR
这是一份简短的执行摘要(或预告片),内容涉及我们在Profi.ru DS部门大约2个月内所做的工作(我在那里待了更长的时间,但入职本人和我的团队是另外一回事首先完成)。
预计目标
- 了解客户的输入/意图并相应地路由客户(尽管我们同时考虑了预输入字符级模型和语言模型,但我们还是选择了输入质量不可知的分类器;简单性规则);
- 查找全新的服务和现有服务的同义词;
- 作为(2)的子目标-学习在任意外部语料库上构建适当的集群;
实现目标
显然,其中一些结果不仅是由我们的团队获得的,而且是由多个团队获得的(即,我们显然没有为域语料库和手动注释进行抓取,尽管我相信抓取也可以由我们的团队解决-您只需要足够的代理人+可能有一些硒经验。
业务目标:
- 客户端路由/意图分类(
5k类)的准确度达到88+% (相比之下,弹性搜索为60% )。 - 搜索与输入质量(打印错误/部分输入)无关;
- 分类器概括,利用语言的形态结构。
- 分类器在各种基准上严重击败了弹性搜索(请参见下文);
- 为了安全起见,至少发现了
1,000新服务+至少15,000同义词(相对于当前状态5,000 + 30,000 )。 我希望这个数字能翻倍甚至三倍。
最后一项是粗略的估计,但比较保守。
还将进行AB测试。 但是我对这些结果充满信心。
“科学”目标:
- 我们将下游分类任务+ KNN与服务同义词数据库彻底地比较了许多现代句子嵌入技术;
- 我们设法使用UNSUPERVISED方法在此基准测试(见下文的详细信息)上击败了弱监督(本质上说,他们的分类器是ngram袋)。
- 我们开发了一种新颖的方法来构建应用的NLP模型(纯香草双LSTM +嵌入包,本质上是快速文本符合RNN)-这考虑了俄语的形态并很好地泛化了内容;
- 我们证明了我们的最终嵌入技术(最佳分类器的瓶颈层)与最新的无监督算法(UMAP + HDBSCAN)相结合可以产生恒星簇;
- 我们在实践中证明了以下方面的可能性,可行性和可用性:
- 与生成较大的静态数据集相比,使用动态增强来训练基于文本的分类器与生成更大的静态数据集相比,可大大减少收敛时间(10倍)(即CNN学会概括显示的错误而大幅减少了增强语句);
总体项目结构
这不包括最终分类器。
最后,我们还是放弃了伪造的RNN和三重损失模型,转而使用了分类器瓶颈。

现在在NLP中什么有效?
鸟瞰:

您也可能知道NLP 现在正在经历Imagenet时刻 。
大型UMAP骇客
在构建集群时,我们偶然发现了一种将UMAP本质上应用于100m +点(甚至10亿个)大小的数据集的方法。 本质上是使用FAISS构建KNN图,然后使用您的GPU将主UMAP循环重写为PyTorch。 我们并不需要它,而放弃了这个概念(毕竟我们只有10-15m的积分),但是请遵循此主题以获取详细信息。
什么最有效
- 对于监督分类,快速文本符合RNN(bi-LSTM)+精心选择的n-gram集;
- 实现-用于n-gram + PyTorch嵌入包层的普通python;
- 对于群集-此模型+ UMAP + HDBSCAN的瓶颈层;
最佳分类基准
手动注释的开发集
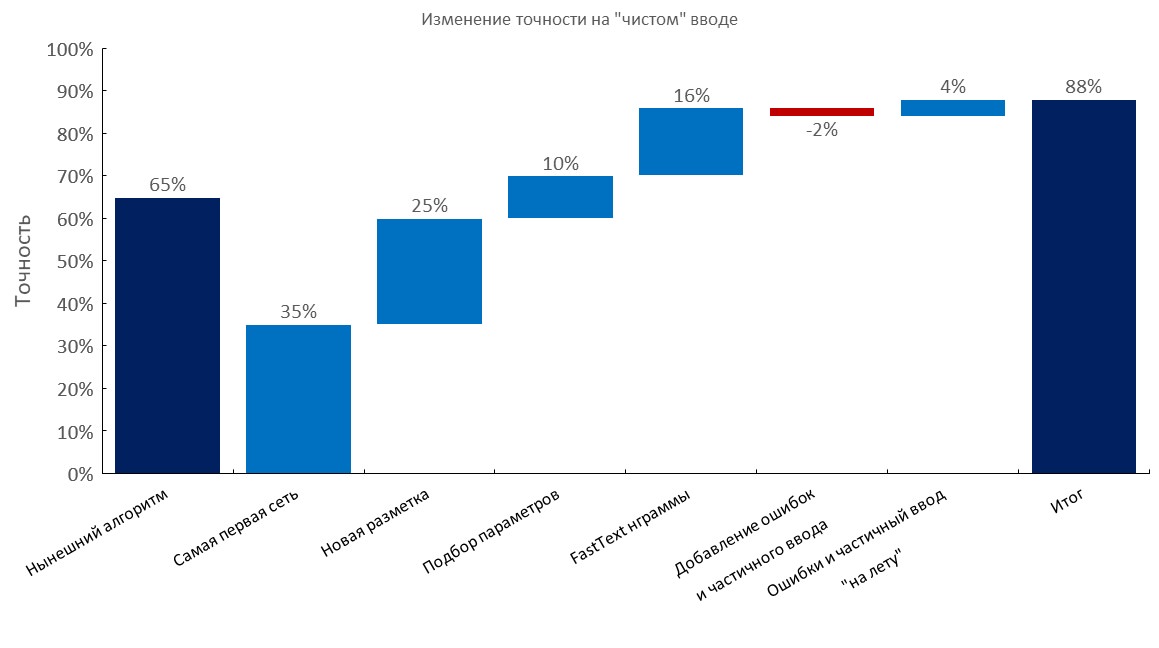
从左到右:
(Top1精度)
- 当前算法(弹性搜索);
- 第一RNN;
- 新注释;
- 调音
- 快速文本嵌入袋层;
- 添加错别字和部分输入;
- 动态生成错误和部分输入( 训练时间减少了10倍 );
- 最终成绩;
手动注释的开发集+每个查询1-3个错误

从左到右:
(Top1精度)
- 当前算法(弹性搜索);
- 快速文本嵌入袋层;
- 添加错别字和部分输入;
- 动态产生错误和部分输入;
- 最终成绩;
手动注释的开发集+部分输入
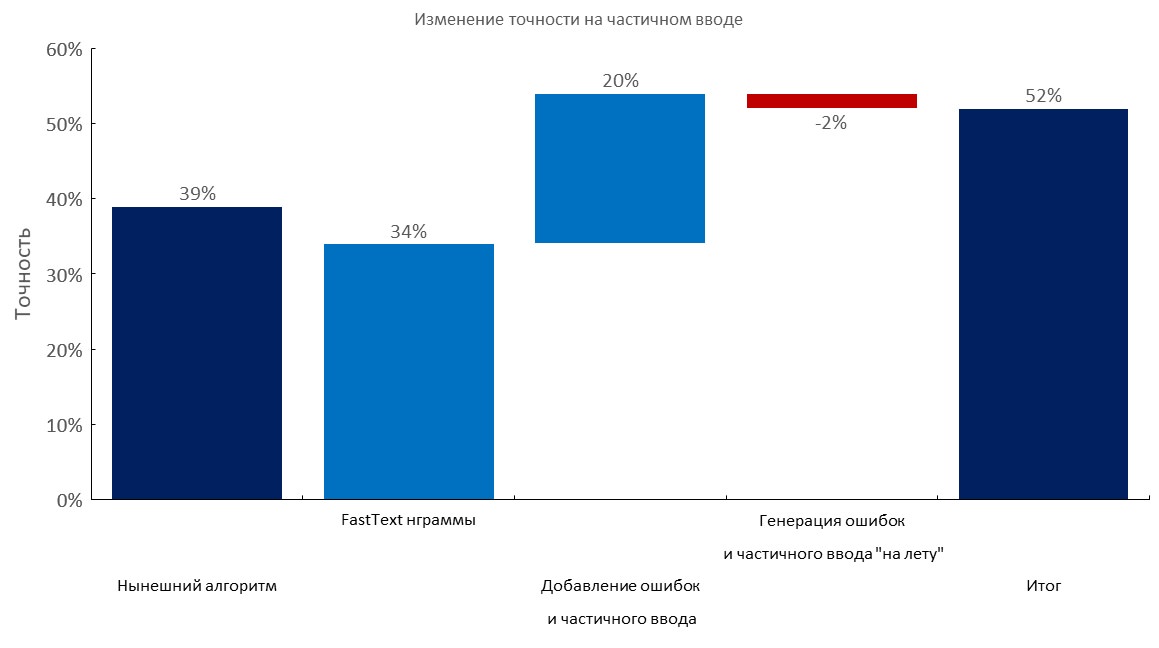
从左到右:
(Top1精度)
- 当前算法(弹性搜索);
- 快速文本嵌入袋层;
- 添加错别字和部分输入;
- 动态产生错误和部分输入;
- 最终成绩;
大型语料库/ n-gram选择
- 我们收集了俄语最大的语料库:
- 我们使用1TB爬网收集了
100m单词词典; - 还可以使用此技巧更快(过夜)下载此类文件;
- 我们为分类器选择了一个最佳的
1m n-gram集合,以进行最佳概括(从在俄罗斯维基百科上训练的快速文本中的500k最受欢迎的n-grams +我们领域数据中的500k最受欢迎的n-grams);
对100M词汇量的1M n-gram进行压力测试:

文字扩充
简而言之:
- 拿一本有错误的大词典(例如10-100m个独特的单词);
- 产生错误(删除字母,使用计算的概率交换字母,插入随机字母,可能使用键盘布局等);
- 检查字典中是否有新词;
我们粗暴地对此类服务强加了很多查询(以尝试对数据集进行反向工程),并且它们内部有一个很小的字典(该服务也由具有n-gram特征的树分类器提供支持)。 看到它们只覆盖了我们在某些语料库上所用词的30%至50%,真是很有趣。
如果您可以使用大量领域的词汇表,则我们的方法要优越得多 。
最佳无监督/半监督结果
KNN用作比较不同嵌入方法的基准。
(向量大小)测试的模型列表:
- (512)在200 GB的常见爬网数据上训练的大型伪句子检测器;
- (300)伪造的句子检测器,经过训练可以从服务中分辨出维基百科的随机句子;
- (300)从此处获得的快速文本,在araneum语料库上进行了预训练;
- (200)对我们的域数据进行了快速文本训练;
- (300)对200GB的“通用抓取”数据进行了快速文本训练;
- (300)具有三重态损失的暹罗网络,通过来自维基百科的服务/同义词/随机句子进行训练;
- (200)嵌入袋RNN的嵌入层的第一次迭代,将句子编码为整个袋的嵌入;
- (200)相同,但是首先将句子拆分为单词,然后嵌入每个单词,然后取平均值;
- (300)与上述相同,但最终型号为;
- (300)与上述相同,但最终型号为;
- (250)最终模型的瓶颈层(250个神经元);
- 监督不足的弹性搜索基准;
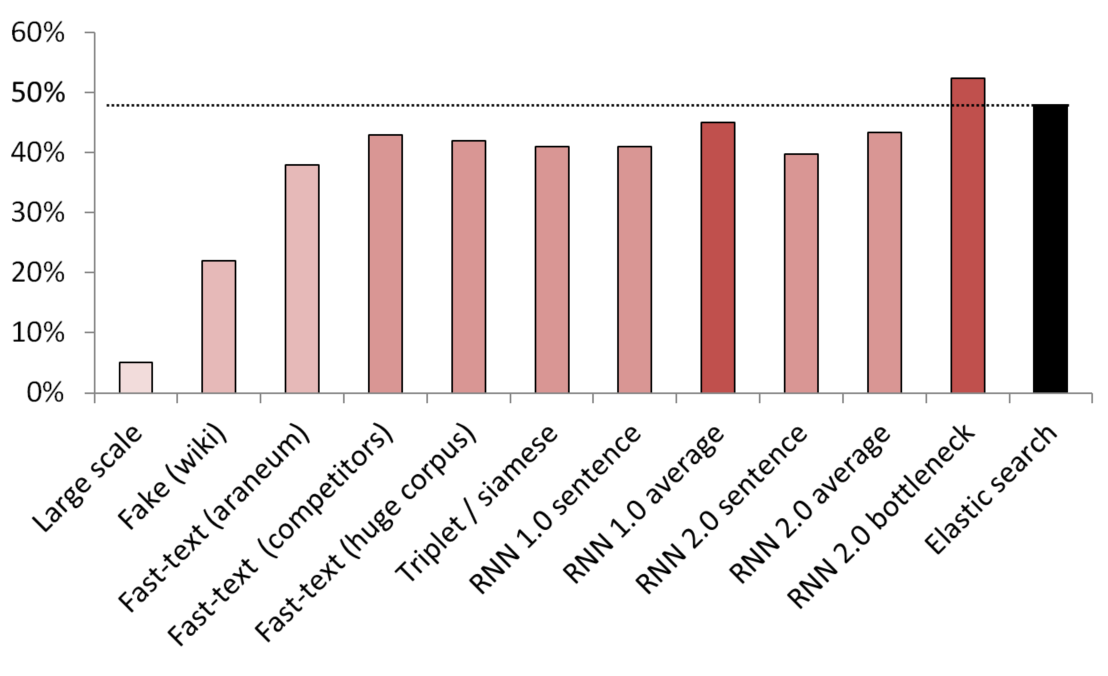
为避免泄漏,对所有随机句子进行了随机抽样。 它们的文字长度与所比较的服务/同义词的长度相同。 还采取措施以确保模型不只是通过分开词汇来学习(嵌入被冻结,Wikipedia采样不足以确保每个Wikipedia句子中至少有一个领域词)。
集群可视化
3D

2D

集群探索“界面”
绿色-新单词/同义词。
灰色背景-可能是新词。
灰色文字-现有同义词。

消融测试,什么可行,我们尝试了什么以及我们没有做什么
- 见上图;
- 快速文本嵌入的纯平均值/ tf-idf平均值-一个非常强大的基线 ;
- 快速文本> Word2Vec(俄语);
- 假句检测类的句子嵌入技术,与其他方法相比显得苍白;
- BPE(哨兵)在我们的领域没有任何进步;
- 尽管有Google的论文,Char级别的模型还是难以一概而论。
- 我们尝试了多头转换器(具有分类器和语言建模头),但是在手头可用的注释上,其执行效果与基于普通LSTM的普通模型大致相同。 当我们迁移到嵌入不良方法时,由于变压器的LM头和嵌入袋层的实用性较低和不切实际,我们放弃了这一研究领域。
- BERT-似乎是过大的杀伤力,也有人声称变压器实际上需要训练数周。
- ELMO –我认为在研究/生产和教育环境中使用像AllenNLP这样的库似乎会适得其反;
部署
完成使用:
- 带有简单Web服务的Docker容器;
- 仅用于推理的CPU就足够了;
- 在CPU上每次查询〜2.5
2.5 ms ,实际上没有必要进行批处理; 1GB RAM内存占用;- 除了
PyTorch , numpy和pandas (以及Web服务器ofc)之外,几乎没有依赖项。 - 模仿这样的快速文本n-gram生成;
- 将包层+索引嵌入到字典中;