在大型服务中,使用机器学习来解决问题仅意味着完成部分工作。 嵌入ML模型并非易事,而围绕它们构建CI / CD流程则更加困难。 在Yandex的
“数据与科学:应用程序”会议上, YouDo的数据科学负责人Adam Eldarov谈到了如何管理模型的生命周期,如何设置再培训和再培训流程,开发可扩展的微服务等等。
-让我们从介绍开始。 有一位数据科学家,他在Jupyter Notebook中编写了一些代码,进行了特征工程,交叉验证,训练模型模型。 速度在增长。

但在某种程度上,他理解:为了给公司带来商业价值,他必须将解决方案附加到生产中某个神话般的生产中,这给我们带来了很多问题。 在大多数情况下,我们在生产中看到的笔记本电脑无法发送。 随之而来的问题是:如何将此代码在笔记本电脑内部运送到特定服务。 在大多数情况下,您需要编写具有API的服务。 或者他们通过PubSub通过队列进行通信。

当我们提出建议时,我们经常需要训练模型并重新训练它们。 此过程必须受到监视。 在这种情况下,必须始终对代码本身和模型进行测试,以使我们的模型在某一时刻不会发疯,也不会总是开始预测零。 还需要通过AB测试对真实用户进行检查-我们做得更好或至少没有做得更好。
我们如何处理代码? 我们有GitLab。 我们所有的代码都分为许多小的库,用于解决特定的领域问题。 同时,它是一个单独的GitLab项目,Git版本控制和GitFlow分支模型。 我们使用诸如pre-commit hook之类的东西,以便您不能提交不满足我们的统计测试检查的代码。 还有测试本身,单元测试。 我们对它们使用基于属性的测试方法。

通常,编写测试时,是指您具有测试函数以及您自己动手创建的参数,一些示例以及测试函数返回的值。 这很不方便。 代码膨胀,原则上许多人都懒得编写它。 结果,我们在测试中发现了一堆代码。 基于属性的测试意味着您所有的参数都有一定的分布。 让我们进行定相,并从这些分布中多次采样所有参数,使用这些参数调用被测函数,并检查此函数的结果是否有某些属性。 结果,我们的代码更少了,同时,还有更多的测试。
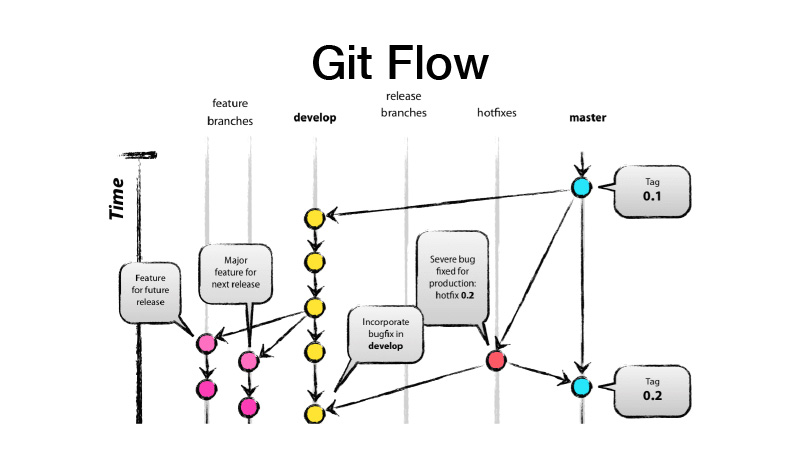
什么是GitFlow? 这是一个分支模型,这意味着您有两个主要分支-开发分支和主分支,生产就绪代码位于此分支,所有开发都在开发分支中进行,所有新功能都来自功能早午餐。 也就是说,每个功能都是一个新的功能分支,而功能分支应该是短暂的,并且永远是有效的-也可以通过功能切换来覆盖。 然后,我们发布一个版本,将开发人员所做的更改扔到master上,并在其上放上我们库或服务的version标签。
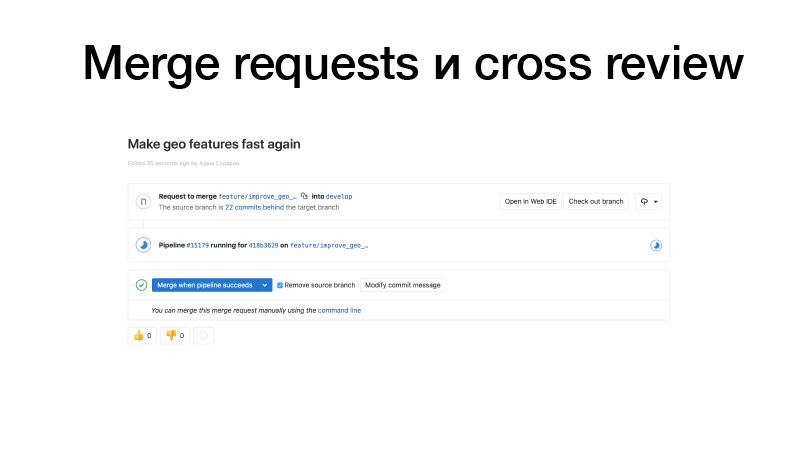
我们正在开发中,看到了一些功能,将其推送到GitLab,创建了从功能早午餐到未婚人士的合并请求。 触发工作,运行测试,如果一切正常,我们可以将其冻结。 但是拿着它的不是我们,而是团队中的某个人。 它修改了代码,从而增加了总线系数。 此代码段已经为两个人所熟知。 结果,如果有人被公交车撞到,则有人已经知道他在做什么。

库的持续集成通常看起来像测试任何更改。 如果我们发布它,它也将发布到我们包的私有PyPI服务器上。
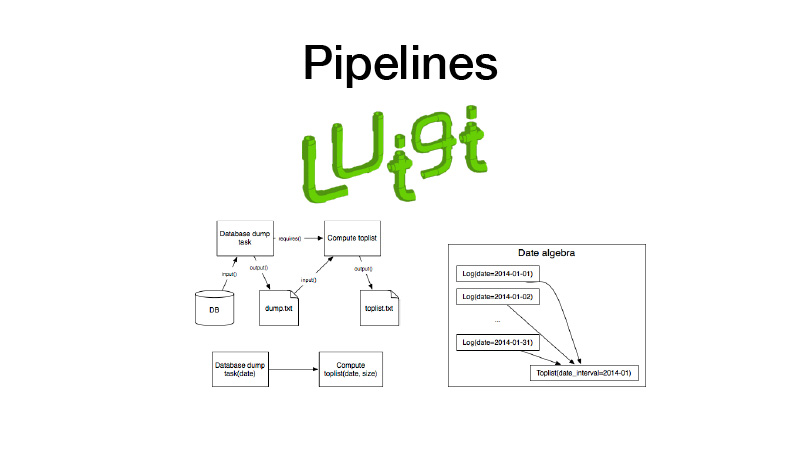
此外,我们可以将其收集在管道中。 为此,我们使用Luigi库。 它可以与诸如task这样的实体一起使用,该实体具有输出,在其中保存在执行任务期间创建的工件。 有一个任务参数可参数化它执行的业务逻辑,识别任务及其输出。 同时,任务始终具有其他任务提出的要求。 当我们运行某种任务时,将通过检查其输出来检查其所有依赖项。 如果输出存在,则我们的依赖项不会启动。 如果工件从某些存储中丢失,它将启动。 这形成了管道,有向循环图。
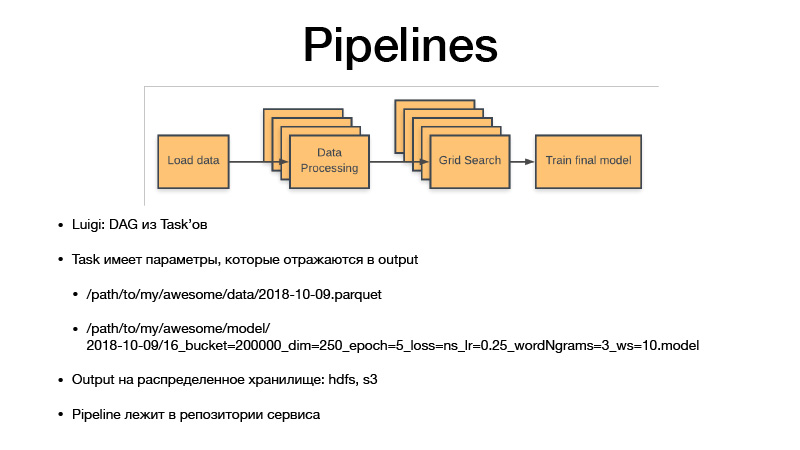
所有参数都标识业务逻辑。 通过这样做,他们可以识别出工件。 它始终是具有某种粒度,敏感度的日期,或者是一周,一天,一小时,三个小时的日期。 如果我们训练某种模型,那么Luigi taska总是具有此任务的超参数,它们会泄漏到我们产生的工件中,超参数会反映在工件的名称中。 因此,我们实质上是对所有中间数据集和最终工件进行版本控制,并且它们永远不会被覆盖,只会升级到存储,而存储是HDFS和S3私有的,可以看到某些酱菜,模型或其他东西的最终工件。 。 并且所有管道代码都位于与其关联的存储库中的服务项目中。

它需要以某种方式修复。 HashiCorp堆栈可以解救,我们使用Terraform以代码形式声明基础结构,使用Vault管理机密,数据库中包含所有密码和外观。 Consul是由键值存储分发的发现服务,可用于配置。 Consul还会对节点和服务进行健康检查,并检查其可用性。
还有-游牧 它是一个编排系统,可以消除您的服务和某种批处理作业。
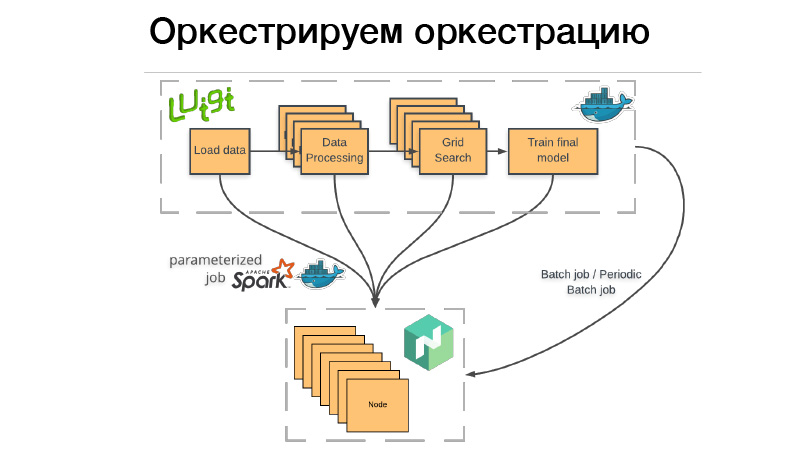
我们如何使用它? 有一个Luigi管道,我们将其包装在Docker容器中,将蝙蝠或定期批处理作业放到Nomad中。 批处理作业-这已经完成了,如果一切成功-一切正常,我们可以手动重新启动。 但是,如果出现问题,Nomad会重试它,直到尝试失败,或者没有成功结束。
定期批处理作业-完全相同,仅按计划进行。
有问题。 当我们将容器部署到任何编排系统时,我们需要指出该容器,CPU或内存需要多少内存。 如果我们有一个运行三个小时的管道,那么其中的两个小时将消耗10 GB的RAM,即1个小时-70 GB。 如果超出了给他的限制,则Docker守护程序就会出现并杀死Dockers和(nrzb。)[02:26:13]我们不想一直持续占用内存,因此我们需要指定所有70 GB(峰值内存负载)。 但这是问题所在,三个小时中的所有70 GB都将被分配,并且其他任何作业都无法访问。
因此,我们走了另一条路。 我们整个Luigi管道都不会启动任何业务逻辑,而只是在Nomad(所谓的参数化工作)中启动一组骰子。 实际上,这是服务器(NRZB。)[02:26:39]功能的类似物,AVS Lambda知道。 制作库时,我们通过CI以参数化作业的形式(即带有某些参数的容器)部署所有代码。 假设Lite JBM分类器具有一个参数,该参数指向用于训练的输入数据的路径,模型的超参数以及通往输出工件的路径。 所有这些都在Nomad中注册,然后从Luigi管道中,我们可以通过API提取所有这些Nomad Jobs,而Luigi确保不要多次运行同一任务。
假设我们有相同的文本处理。 有10个条件模型,我们不想每次都重新启动文本处理。 它只会启动一次,并且每次重复使用都会有一个最终结果。 同时,所有这些工作都是分布式的,我们可以在大型集群上进行巨大的网格搜索,而只剩下时间来抛铁。
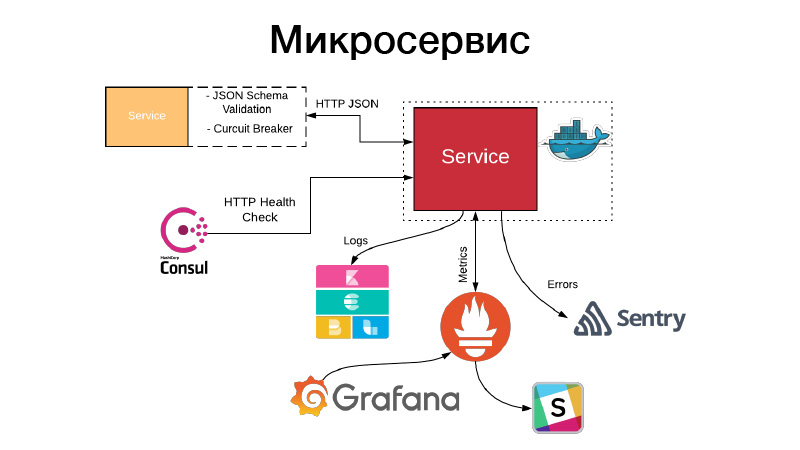
我们有一个工件,我们需要以某种服务形式来安排它。 服务公开HTTP API或通过队列进行通信。 在此示例中,这是最简单的示例HTTP API。 同时,与服务的通信,或者我们的服务通过HTTP JSON API与其他服务的通信,将验证JSON方案。 服务本身总是在文档中为其API和该对象的方案描述一个JSON对象。 但是并非始终需要JSON对象的所有字段,因此,验证了消费者驱动的合同,验证了此方案,通过模式断路器进行通信以防止我们的分布式系统由于级联故障而失败。
同时,该服务必须设置HTTP运行状况检查,以便Consul可以检查该服务的可用性。 同时,Nomad可以做到这一点,以便连续提供三个hello检查的服务,它可以重新启动该服务以提供帮助。 该服务以JSON格式写入其所有日志。 我们使用JSON日志记录驱动程序和Elastics堆栈,在每个点FileBit都简单地获取所有JSON日志,将它们扔到日志缓存中,然后从那里到达Elastic,我们可以分析KBan。 同时,我们不使用日志来收集指标和构建仪表板,这效率很低,为此我们使用Prometheus加密系统,我们有一个为每个仪表板服务创建模板的过程,并且我们可以分析服务产生的技术指标。
此外,如果出现问题,警报会进入,但是在大多数情况下,这还不够。 哨兵为我们提供了帮助,这是事件分析的关键。 实际上,我们由Sentry处理程序捕获所有错误级别日志,并将它们推送到Sentry中。 然后进行详细的追溯,其中包含有关服务所处的环境,哪个版本,哪些函数由哪些参数调用以及该范围内的哪些变量具有哪些值的所有信息。 所有配置都是可见的,它对快速了解发生的情况并修复错误有很大帮助。
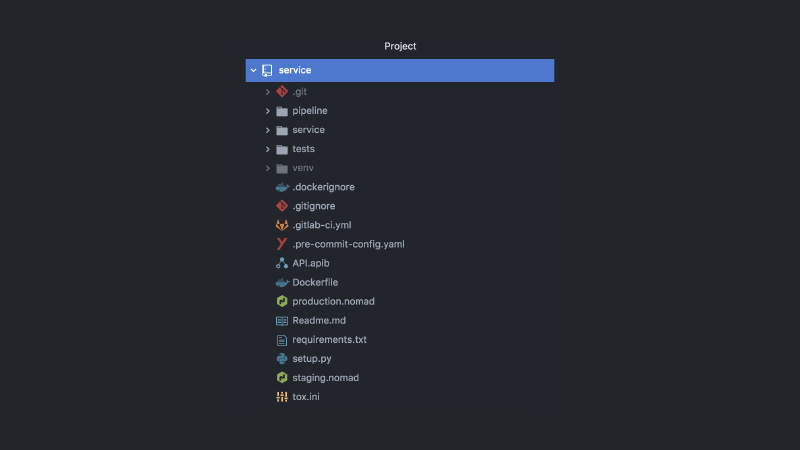
结果,该服务看起来像这样。 单独的GitLab项目,管道代码,测试代码,服务代码本身,一堆不同的配置,Nomad,CI配置,API文档,提交挂钩等等。
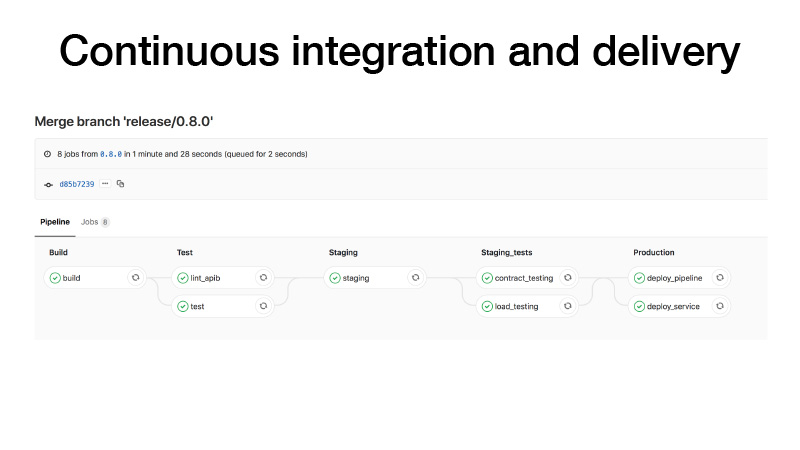
发布时,我们将按以下步骤进行CI:建立一个容器,运行测试,在一个阶段上放置一个集群,为我们的服务运行一个测试合同,进行压力测试以确保我们的预测不会太慢并保持我们认为的负载。 。 如果一切正常,我们将把该服务部署到生产环境中。 有两种方法:我们可以部署管道,如果定期批处理作业,它可以在后台某个地方工作并产生伪像,或者我们可以用笔触发某种管道,可以训练一些模型,之后我们就知道一切都很好并部署服务。

在这种情况下还会发生什么? 我说过,在功能早午餐的发展中,存在着诸如功能切换这样的范例。 以一种很好的方式,您需要使用一些切换来覆盖要素,只是在出现问题时减少战斗中的要素。 然后,我们可以收集发布系列中的所有功能,即使这些功能尚未完成,我们也可以部署它们。 仅功能切换将被关闭。 由于我们都是数据科学家,因此我们也想进行AV测试。 假设我们用CatBoost取代了LightGBM。 我们想检查一下,但是同时,参考一些用户ID来管理AV测试。 功能切换绑定到userID,从而通过了AV测试。 我们需要在此处检查这些指标。
所有服务均已部署到Nomad。 我们有两个Nomad生产集群-一个用于批处理工作,另一个用于服务。
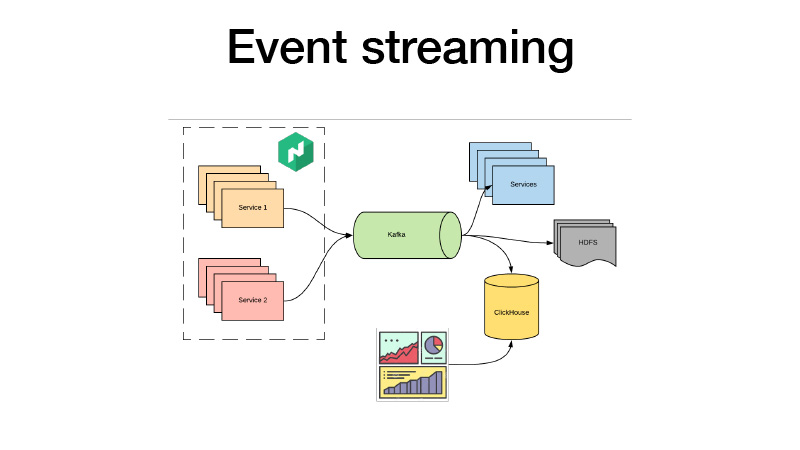
他们将所有商业活动推向卡夫卡。 从那里我们可以接他们。 从本质上讲,它是一个羔羊架构。 我们可以为HDFS订阅某些服务,进行一些实时分析,与此同时,我们都可以进入ClickHouse,并构建仪表板来分析我们服务的所有业务事件。 我们可以分析AV测试。
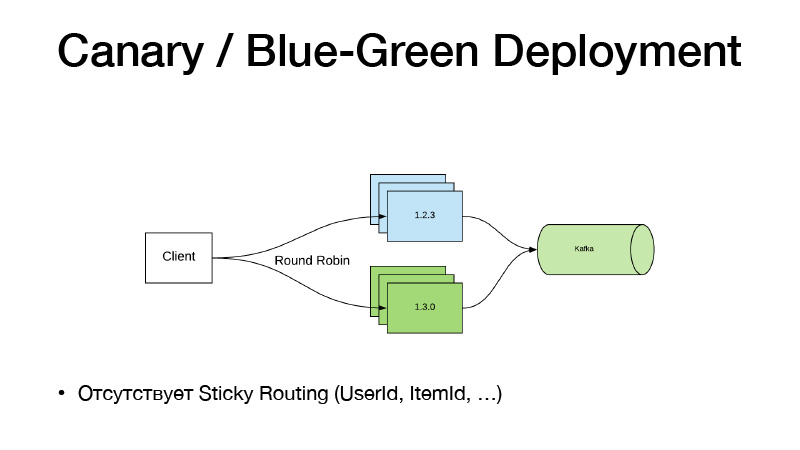
如果我们不更改代码,请不要使用功能切换。 我们刚刚开始在某些管道上使用笔,他教给我们一种新的模型。 我们有一条新的道路。 我们只需要在配置中将Nomad路径更改为模型,发布新的服务即可,在这里Canary Deployment范例对我们有所帮助,可从包装盒中的Nomad中获得。
我们在三个实例中提供了该服务的当前版本。 我们说我们想要三个金丝雀-在不削减旧版本的情况下又部署了三个新版本的副本。 结果,流量开始分为两部分。 部分流量属于新版本的服务。 所有服务将其所有业务活动推送到Kafka。 结果,我们可以实时分析指标。
如果一切正常,那么我们可以说一切正常。 部署后,Nomad将经历,轻轻关闭所有旧版本并扩展新版本。
这种模型的缺点在于,如果我们需要通过某个实体User Item绑定版本路由。 这样的方案不起作用,因为通过轮询来平衡流量。 因此,我们采用以下方式将服务分为两部分。
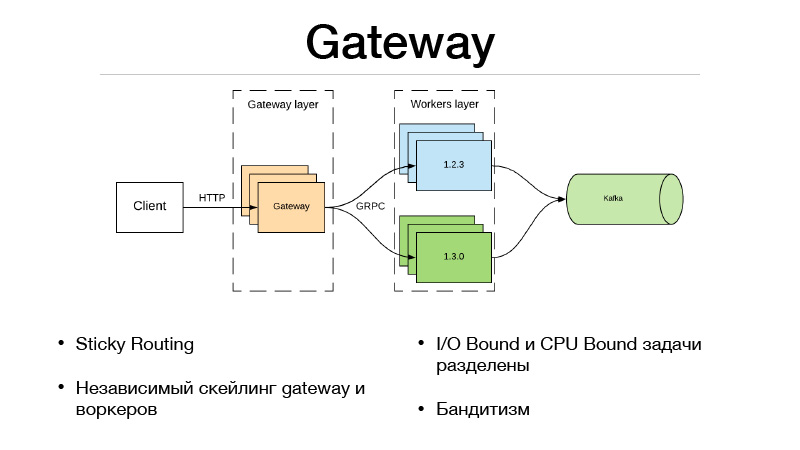
这是网关层和工作层。 客户端通过HTTP与网关层进行通信,所有版本选择和流量平衡的逻辑都在网关中。 同时,完成谓词所需的所有I / O绑定任务也位于网关中。 假设我们在请求的谓词中获得了一个userID,我们需要丰富一些信息。 我们必须提取其他微服务并获取所有信息,功能或基础。 结果,所有这一切都在网关中发生。 他与仅处于模型中的工人进行沟通,并且做一件事-预测。 输入和输出。
但是,由于我们将服务分为两部分,因此由于远程网络调用而出现了开销。 如何调平? Google的JRPC框架,Google的RPC(运行在HTTP2之上)得以解决。 您可以使用多路复用和压缩。 JPRC使用原型。 这是具有快速序列化和反序列化的强类型二进制协议。
因此,我们还能够独立扩展Gateway和worker。 假设我们无法保持一定数量的开放HTTP连接。 好的,扩展网关。 我们的预测太慢了,我们没有时间来承担工作量-好的,我们扩大了员工规模。 这种方法非常适合多臂匪。 在网关中,由于实现了流量平衡的整个逻辑,因此它可以转到外部微服务,并从它们获取每个版本的所有统计信息,以及制定如何平衡流量的决策。 假设使用汤普森采样。
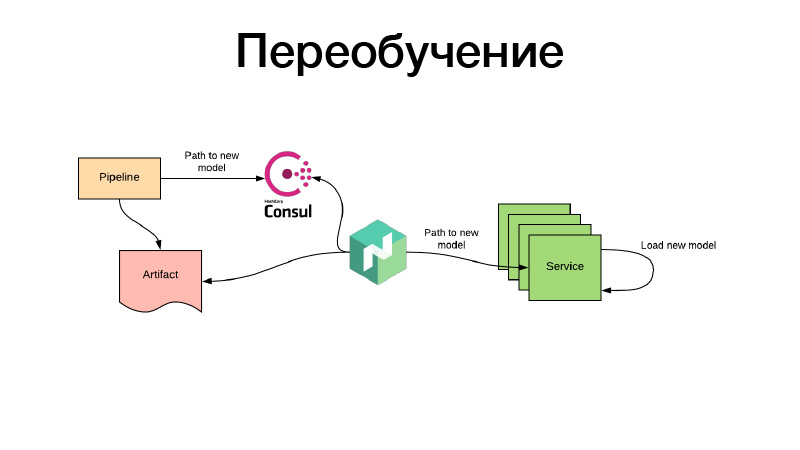
好的,模型已经过某种方式的训练,我们在Nomad配置中注册了它们。 但是,如果有一种推荐模型已经在培训过程中过时了,而我们又需要不断对其进行再培训,该怎么办? 一切都以相同的方式完成:通过定期的批处理作业,会产生一些工件-例如,每三个小时。 同时,在工作结束时,管道为Consul中的新模型设置了路径。 这是键值存储,用于配置。 Nomad可以配置配置。 假设有一个基于键值存储Consul值的环境变量。 他监视更改,并在出现新路径后立即决定可以采用两条路径。 他通过一个新的链接下载工件本身,使用卷将服务容器放入Docker并重新引导-并进行所有这些操作,以确保没有停机时间,也就是缓慢地,单独地。 或者他呈现新配置并向他报告服务。 或者服务本身可以检测到它-并且它内部可以独立地实时更新其modelka。 就这样,谢谢。