公司博客上的先前帖子没有一个控制台团队,因此我们决定追赶。
我们公司的度量标准旨在防止共享主机出现大故障。 在每个共享托管服务器上,都有一个在WordPress上的测试站点,该站点会定期访问。
这是测试站点在每个共享主机服务器上的外观
测量站点响应的速度和成功。 公司的任何员工都可以查看常规统计信息,并查看公司的状况。 可以查看整个主机或特定服务器的测试站点成功响应的百分比。 不必成为公司的雇员-在控制面板中,客户还会在其帐户所在的服务器上看到统计信息。
我们称此正常运行时间指标(从测试站点到对测试站点的所有请求的成功响应百分比)。 这不是一个很好的名字,很容易将其与正常运行时间(最后一次重启后的服务器)混淆。
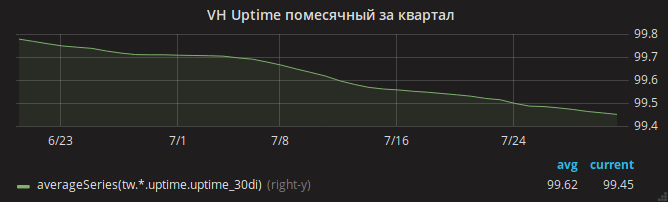
夏天过去了,正常运行时间计划逐渐降低。
管理员立即确定了原因-缺少RAM。 当服务器内存不足并且内核杀死nginx时,很容易在日志中看到OOM情况。
该部门的负责人安德烈(Andrey)用向导的手将一项任务分解为几项,并将其并行化为不同的管理员。 一种方法是分析Apache设置-也许这些设置不是最佳设置,并且流量很大,Apache占用了所有内存? 另一个分析了mysqld的内存消耗-从共享托管使用Gentoo OS时起,突然有任何过时的设置吗? 第三个是对nginx设置的最新更改。
管理员一一返回结果。 每个人都设法减少分配给他的区域中的内存消耗。 例如,在nginx的情况下,检测到包含但未使用的mod_security。 同时,OOM也很常见。
最后,可能会注意到某些服务器上的核心内存消耗(尤其是SUnreclaim)非常大。 在ps输出和htop中都看不到此参数,因此我们没有立即注意到它! 具有地狱SUnreclaim的示例服务器:
root@vh28.timeweb.ru:~
24 GB的RAM被分配给内核,而内核却花了它们,没人知道!
管理员(我们称他为加百列)冲上了战场。 使用KMEMLEAK选项重新组装内核以进行泄漏检测。
重建选项要启用KMEMLEAK,只需指定下面列出的选项,并使用kmemleak = on参数加载内核。
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
KMEMLEAK编写(在/sys/kernel/debug/kmemleak )这些行:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
加布里埃尔没有向我们透露他所有的秘密,也没有告诉他如何从上述几行中找出导致内存泄漏的确切原因。 最有可能的是,他使用了addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361来查找确切的行。 或者只是打开net/socket.c并查看它,直到该文件变得不舒服为止。
问题原来是net/socket.c上的补丁,该net/socket.c已在很多年前添加到我们的存储库中。 其目的是禁止客户端使用bind()系统调用,这是防止客户端启动代理服务器的简单保护。 该修补程序实现了其目的,但没有清除内存。
可能是PHP中出现了新的流行恶意软件,它们试图循环运行代理服务器-导致成千上万个阻塞的bind()调用和丢失的千兆字节RAM。
然后很简单-Gabriel修复了补丁并重建了内核。 在所有运行Linux的服务器上增加了对SUnreclaim值的监视。 工程师警告客户,并重新启动了新内核中的主机。
OOM消失了。
但是网站可用性仍然存在问题
在所有服务器上,测试站点每天停止响应几次。
在这里,作者将开始在身体的不同部位撕头发。 但是Gabriel保持冷静,并开始记录部分托管服务器的流量。
在流量转储中,通常可以看到,突然收到TCP RST数据包后,对测试站点的请求下降。 换句话说,请求到达了服务器,但是连接最终被nginx破坏了。
更有趣! Gabriel启动的strace实用程序显示nginx守护程序未发送此数据包。 怎么会这样,因为只有nginx正在监听端口80?
原因是多个因素的组合:
- 在nginx设置中,
reuseport了reuseport选项(包括SO_REUSEPORT socket SO_REUSEPORT ),该SO_REUSEPORT允许不同的进程在同一地址和端口接受连接 - 在(当时最新的)nginx 1.13.0版本中,存在一个错误,由于该错误 ,当通过
nginx -t启动nginx配置测试并使用SO_REUSEPORT此nginx测试过程实际上开始监听端口80并拦截来自真实客户端的请求。 在配置测试过程结束时,客户端收到Connection reset by peer - 最终,在监视zabbix时,在所有安装了
nginx -t服务器上都配置了nginx配置正确性监视:每分钟在它们上调用nginx -t命令。
只有更新了nginx之后,您才能平静地呼吸。 网站的正常运行时间图已经上升。
整个故事的寓意是什么? 保持乐观,避免使用自组装内核。