维持庞大的代码库,同时确保大量开发人员的高生产率是一个严峻的挑战。 在过去的5年中,Yandex一直在开发用于持续集成的特殊系统。 在本文中,我们将讨论Yandex代码库的规模,使用基于主干的开发方法将开发转移到单个存储库,连续集成系统必须解决哪些任务才能在这种条件下有效地工作。

许多年前,Yandex在服务开发方面没有特殊的规则:每个部门可以使用任何语言,任何技术,任何部署系统。 正如实践所表明的那样,这种自由并不总是有助于更快地前进。 当时,为了解决相同的问题,通常会有一些专有或开源开发。 随着公司的发展,这种生态系统的运作变得更糟。 同时,我们希望保留一个大型Yandex,而不是拆分成许多独立的公司,因为它具有很多优势:许多人执行相同的任务,其工作结果可以重复使用。 从各种数据结构开始,例如分布式哈希表和无锁队列,最后以我们二十多年来编写的许多不同的专用代码结束。
我们解决的许多任务在开源世界中都无法解决。 没有适用于我们的卷(5000台以上服务器)和我们的任务的MapReduce可以很好地工作,也没有可以处理我们数千万张票证的任务跟踪器。 这在Yandex中很有吸引力-您可以做的很棒。
但是,当我们重新解决现成的解决方案的相同问题时,就会严重降低效率,从而使组件之间的集成变得困难。 只在自己的角落为自己做所有事情,这是既方便又方便,您暂时无法考虑别人。 但是,一旦服务变得足够引人注目,它将具有依赖性。 实际上,似乎各种服务之间的相互依赖程度很小,实际上,公司不同部门之间存在很多联系。 许多服务可以通过Yandex应用程序/浏览器等获得,也可以相互嵌入。 例如, 爱丽丝出现在浏览器中,您可以使用爱丽丝订购出租车。 我们都使用通用组件: YT , YQL和Nirvana 。
旧的开发模型存在重大问题。 由于存在许多存储库,普通开发人员(尤其是初学者)很难发现:
- 组件在哪里?
- 工作原理:没有办法“阅读”
- 现在谁在开发和支持它?
- 如何开始使用它?
结果,出现了相互使用部件的问题。 组件几乎不能使用其他组件,因为它们彼此代表了“黑匣子”。 这对公司产生了负面影响,因为这些组件不仅没有重复使用,而且经常没有得到改善。 复制了许多组件,必须支持的代码量正在显着增长。 我们通常比我们能做的要慢。
单一存储库和基础架构
5年前,我们启动了一个项目,将开发转移到单个存储库,该存储库具有用于组装,测试,部署和监视的通用系统。
我们想要实现的主要目标是消除阻碍集成他人代码的障碍。 该系统应提供对完成工作代码的轻松访问,清晰的连接和使用方案,可收集性:始终收集项目(并通过测试)。
作为该项目的结果,该公司出现了一系列基础架构技术:源代码存储,代码审查系统,构建系统,持续集成系统,部署,监视。
现在,Yandex项目的大多数源代码都存储在单个存储库中,或者正在迁移到该存储库中:
- 超过2000名开发人员从事项目。
- 超过50,000个项目和图书馆。
- 存储库大小超过25 GB。
- 已经有3,000,000多个提交提交到了存储库。
公司的优点:
- 存储库中的任何项目都会获得现成的基础架构:
- 用于查看和导航源代码的系统以及代码查看系统。
- 组装系统和分布式组装。 这是一个单独的大主题,我们肯定会在以下文章中介绍。
- 持续集成系统。
- 部署,与监控系统集成。
- 代码共享,积极的团队互动。
- 所有代码都是通用的,您可以进入另一个项目并在那里进行所需的更改。 这在大型公司中尤其重要,因为您需要其他资源的团队可能没有资源。 使用通用代码,您就有机会自己完成部分工作,并“帮助实现”所需的更改。
- 有机会进行全球重构。 您不需要支持API或库的旧版本,可以更改它们并更改它们在其他项目中的使用位置。
- 代码变得更少“多样化”。 您有一套解决问题的方法,而无需添加另一种大致相同但略有不同的方法。
- 在您旁边的项目中,很可能不会有绝对陌生的语言和库。
还应该理解,这样的开发模型具有需要考虑的缺点:
- 共享存储库需要单独的特定基础结构。
- 您需要的库可能不在存储库中,但它是开源的。 有添加和更新它的成本。 很大程度上取决于语言和库,那里几乎是免费的,而那里却很昂贵。
- 您需要不断致力于代码的“健康”。 这至少包括与不必要的依赖项和无效代码的斗争。
我们对通用存储库的方法强加了每个人都需要遵循的一般规则。 在使用单个存储库的情况下,对使用的语言,库和部署方法施加了限制。 但是在相邻的项目中,所有内容都将与您的项目相同或非常相似,甚至可以在那里进行修复。
通用存储库的模型适用于所有大公司。 整体式存储库是一个庞大且经过深入研究和讨论的主题,因此现在我们不再赘述。 如果您想了解更多信息,那么在本文结尾,您将找到几个有用的链接,这些链接更详细地介绍了此主题。
持续集成系统运行的条件
根据基于Trunk的开发模型进行开发。 大多数用户使用的是HEAD或存储库的最新副本,该副本是从正在进行开发的主分支Trunk中获得的。 将更改提交到存储库是按顺序进行的。 提交后,新代码立即可见,并且所有开发人员都可以使用。 尽管可以将分支用于发布,但不鼓励在单独的分支中进行开发。
项目取决于源代码。 项目和库形成一个复杂的依赖图。 这意味着在一个项目中进行的更改可能会影响存储库的其余部分。
大量的提交进入存储库:
- 每天超过2000次提交。
- 在高峰时段每分钟最多更改10次。
该代码库包含超过500,000个构建目标和测试。
如果没有在这种情况下进行持续整合的特殊系统,将很难迅速前进。
持续整合系统
持续集成系统为每个更改启动程序集和测试:
- 初步检查。 它们允许在提交之前检查代码,并避免破坏主干中的测试。 然后在HEAD上运行装配和测试。 目前,自愿进行预审核检查。 对于关键项目,需要进行预审核检查。
- 提交到存储库后,提交后检查。
构建和测试在数百台服务器的大型群集上并行运行。 构建和测试在不同的平台上运行。 在其他主要平台(用户可配置的子平台)下,在主平台(Linux)下,所有项目都已组装好并运行了所有测试。
在接收并分析了装配结果并运行了测试之后,用户会收到反馈,例如,如果更改破坏了任何测试。

如果有新的装配失败或测试,我们会向测试所有者和更改的作者发送通知。 系统还可以在特殊界面中存储并显示检查结果。 集成系统的Web界面按测试类型显示测试的进度和结果。 带有扫描结果的屏幕现在看起来可能像这样:
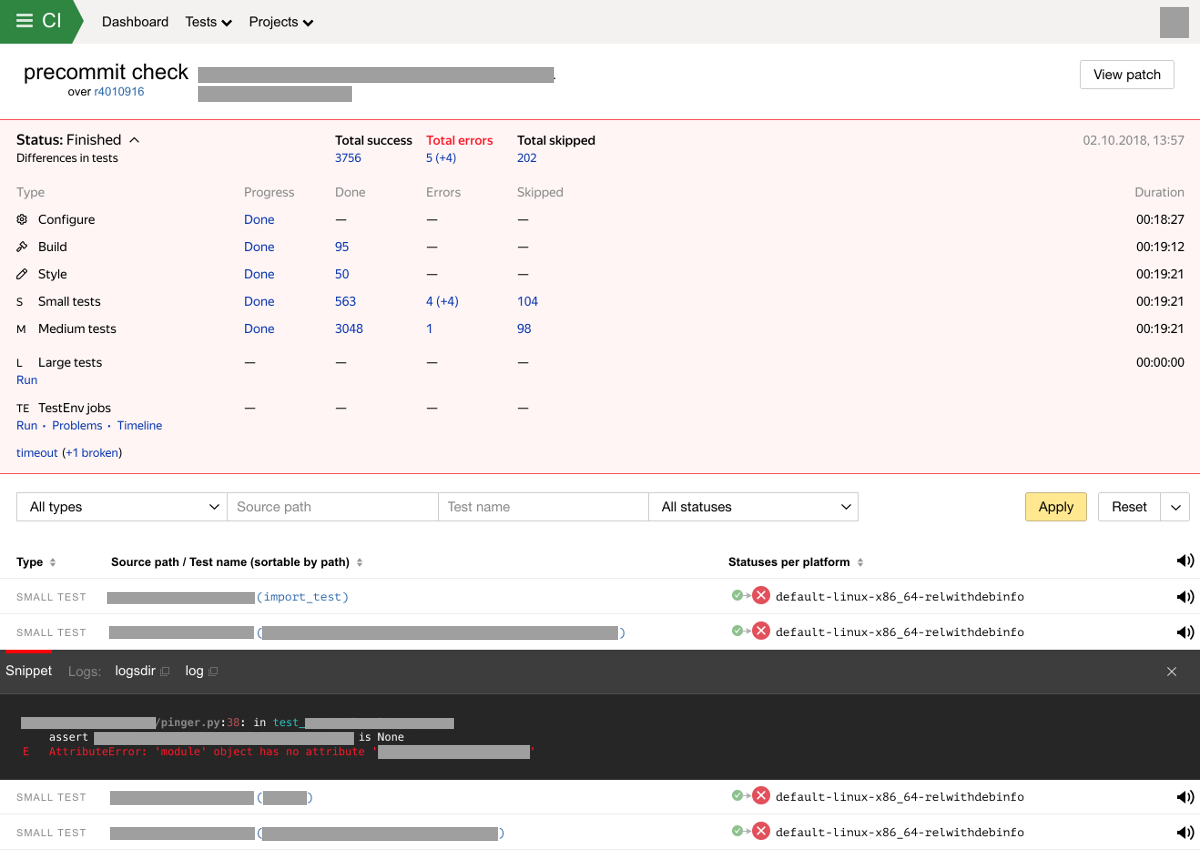
持续集成系统的功能
为解决开发人员和测试人员面临的各种问题,我们开发了持续集成系统。 该系统已经解决了许多问题,但仍有很多地方需要改进。
测试的类型和大小
持续集成系统可以触发几种类型的目标:
- 配置。 由构建系统执行的配置阶段。 该配置包括对装配系统的配置文件的分析,确定项目和装配参数之间的依赖关系并运行测试。
- 建立。 图书馆和项目的组装。
- 风格。 在此阶段,代码样式符合指定的要求。
- 测试。 根据工作时间超时和对计算资源的要求,将测试分为几个阶段。
- 小。 <1分钟
- 中。 <10分钟
- 大。 > 10分钟 另外,对计算资源可能有特殊要求。
- 特大。 这是一种特殊的测试。 此类测试的特征在于以下一组特征:较长的运行时间,大量的资源消耗,大量的输入数据,它们可能需要特殊的访问,最重要的是,它支持以下所述的复杂测试方案。 这样的测试少于其他类型的测试,但是它们非常重要。
测试启动频率和二进制故障检测
在Yandex中分配了大量的资源用于测试-数百个功能强大的服务器。 但是,即使拥有大量资源,我们也无法针对影响它们的每项更改运行所有测试。 但同时,对于我们而言,始终帮助开发人员定位测试失败的地方(尤其是在如此大的存储库中)尤其重要。
我们在做什么 对于所有受影响项目的每次更改,都将运行中小尺寸的装配,样式检查和测试。 其余测试不是针对每个影响提交的,而是以一定的周期运行的(如果有影响测试的提交)。 在某些情况下,用户可以控制启动频率;在其他情况下,启动频率由系统设置。 当检测到测试失败时,将开始搜索破坏测试的提交的过程。 测试运行的频率越低,检测到故障后我们寻找中断提交的时间就越长。

在开始审核前检查时,我们还仅运行装配和灯光测试。 然后,用户可以通过从受系统更改影响的测试列表中进行选择,来手动启动大量测试。
闪烁测试检测
闪烁测试是指在相同代码上运行(通过/失败)结果的测试可能取决于多种因素。 刷新测试的原因可能有所不同:测试代码休眠,使用多线程时出错,基础结构问题(任何系统不可用)等。 闪烁测试提出了一个严重的问题:
- 它们导致了这样一个事实,即持续集成系统会针对测试失败发送虚假警报。
- 污染测试结果。 决定验证结果是否成功变得越来越困难。
- 延迟产品发布。
- 很难检测。 测试可能很少闪烁。
分析测试结果时,开发人员可以忽略闪烁的测试。 有时不正确。
完全消除闪烁测试是不可能的,在连续集成系统中应考虑到这一点。
当前,对于每个测试,我们对所有测试运行两次以检测闪烁测试。 我们还考虑了用户的投诉(通知的接收者)。 如果我们检测到闪烁,则将测试标记为特殊标志(静音),并通知测试所有者。 此后,只有测试所有者将收到测试失败的通知。 接下来,我们将继续在正常模式下运行测试,同时分析其发布的历史记录。 如果测试未在特定时间段内闪烁,则自动化程序可能会决定测试已停止闪烁,您可以清除该标志。
我们当前的算法非常简单,并且计划在此进行很多改进。 首先,我们要使用更多有用的信号。
自动更新测试输入
在测试最复杂的Yandex系统时,除其他测试方法外,经常使用黑盒策略测试 + 数据驱动测试 。 为了确保良好的覆盖范围,此类测试需要大量输入数据。 可以从生产集群中选择数据。 但是,数据很快就会过时,这是一个问题。 世界不会停滞不前,我们的系统正在不断发展。 随着时间的过去,过时的测试数据将无法提供良好的测试覆盖范围,然后由于程序开始使用过时的测试数据中不可用的新数据,从而完全导致测试崩溃。
为了不使数据过时,持续集成系统可以自动更新数据。 如何运作?
- 测试数据存储在特殊的资源存储中。
- 测试包含描述所需输入的元数据。
- 所需的测试输入和资源之间的对应关系存储在连续集成系统中。
- 开发人员定期将新数据传递到资源存储。
- 持续集成系统在资源存储库中搜索测试数据的新版本,并切换输入数据。
重要的是更新数据,以免发生错误测试。 您不能只是从某个提交开始就开始使用新数据,因为 如果测试失败,则不清楚应归咎于谁-提交或新数据。 它还将使差异测试(如下所述)不起作用。

因此,我们这样做是为了使提交间隔很小,对提交数据的旧版本和新版本都会启动测试。

差异测试
差异测试我们称为特殊类型的数据驱动测试 ,它与普遍接受的方法不同,因为该测试没有参考结果,但是同时我们需要找到在哪个提交中测试改变了其行为。
数据驱动测试的标准方法如下。 该测试具有在首次运行时获得的参考结果。 参考结果可以存储在测试旁边的存储库中。 随后的测试运行应产生相同的结果。

如果结果与参考不同,则开发人员必须确定此预期的更改或错误。 如果希望进行更改,则开发人员应在将更改提交到存储库的同时更新参考结果。
在具有大量提交流的大型存储库中使用此方法存在一些困难:
- 可能有很多测试,而测试可能非常困难。 开发人员无法在工作环境中运行所有受影响的测试。
- 进行更改后,如果未同时将参考结果与代码更改同时更新,则测试可能会中断。 然后,另一个开发人员可以更改同一组件,并且测试结果将再次更改。 我们将一个错误强加给另一个错误。 处理此类问题非常困难,需要开发人员花费一些时间。
我们在做什么 差异测试包括2个部分:
- 检查组件。
- 我们开始测试并将结果保存在资源存储中。
- 请勿将结果与参考值进行比较。
- 我们可以捕获一些错误,例如,程序未启动/未结束,崩溃,程序不响应。 还可以执行结果验证:答案中是否存在任何字段,等等。
- 差异组件。
- 比较在不同发射上获得的结果并建立差异。 在最简单的情况下,此函数需要2个参数并返回diff。
- diff的外观取决于测试,但是对于看diff的人来说应该是可以理解的。 通常,diff是一个html文件。
检查和差异组件的启动由一个连续集成系统控制。

如果连续集成系统检测到diff,则首先对导致更改的提交执行二进制搜索。 收到开发人员的通知后,就可以研究diff并决定下一步该怎么做:按预期识别diff(为此您需要执行特殊操作)或修复/“回滚”您的更改。
待续
在下一篇文章中,我们将讨论持续集成系统的工作方式。
参考文献
整体式存储库,基于Trunk的开发
数据驱动测试