本教程将向您展示如何使用OpenCV,Python和ImageMagick创建动画GIF。 然后结合这些方法,用OpenCV创建一个模因生成器!
我们所有人都需要时常大笑。 也许找到lulza的最好方法是使用模因。 我的一些最爱:
- 青蛙青蛙(Kermit the Frog):“但这不关我的事”
- 脾气暴躁的猫
- 史诗失败
- 好家伙格雷格
但是对我个人而言,这些模因无法与“与之达成协议”模因(“与之达成协议”或“自己理解”)相提并论,本文开头给出了一个例子。通常在以下情况下使用:
- 作为对不同意您已完成/说过的事情的人的回答或反对(“与之达成协议”)
- 戴上眼镜就像您要离开一样,让一个人独自面对问题(“自己了解”)
几年前,我在作者的博客上读了一篇有趣的文章,我不记得如何使用计算机视觉生成此类模因。 上周我在任何地方都找不到此指南,因此,作为博客,计算机视觉专家和模因专家,我决定自己编写一个教程! (顺便说一句,如果您不小心知道了原始出处,请告诉我,以便感谢作者
。UPD:刚刚从Kirk Kaiser的博客
MakeArtWithPython中找到了原始文章)。
在OpenCV上开发模因生成器将教会我们许多宝贵的实践技能,包括:
- 使用深度学习技术的人脸检测
- 使用dlib库检测面部标志并提取眼睛区域
- 如何根据收到的信息计算眼睛之间的旋转角度
- 最后,如何使用OpenCV生成动画GIF(在ImageMagick的帮助下)
该指南应该既有趣又有趣-同时教会您在现实世界中有用的宝贵的计算机视觉编程技能。
使用OpenCV创建GIF
在指南的第一部分,我们将讨论该项目的必要条件和依赖关系,包括开发环境的正确配置。
然后考虑我们的OpenCV GIF生成器的项目/目录结构。
一旦了解了项目结构,我们将考虑:1)我们的配置文件; 2)Python脚本,负责使用OpenCV创建GIF。
最后,我们将根据流行的模因“ Deal With It”评估该计划的结果。
先决条件和依赖项
 图 1.我们将使用OpenCV,dlib和ImageMagick创建GIF
图 1.我们将使用OpenCV,dlib和ImageMagick创建GIFOpencv和dlib
需要OpenCV来确定帧中的面孔和基本的图像处理。
如果系统上未安装
OpenCV,请遵循我的一份
OpenCV安装指南 。
我们使用Dlib来检测面部标志,这使我们能够在脸上找到两只眼睛并戴上太阳镜。 您可以
使用此指令安装dlib 。
影像魔术师
如果您不熟悉
ImageMagick ,那就白费了。 它是具有许多图像处理功能的跨平台命令行工具。
您是否要使用一个命令将PNG / JPG转换为PDF? 没问题
您需要从几张图像中制作多页PDF? 轻松一点
需要绘制多边形,直线和其他形状吗? 这是可能的。
如何使用一个命令对所有图片进行批处理颜色分级或调整其大小? 为此,您无需在Python中为OpenCV编写几行。
ImageMagick还可以从任何图像生成GIF。
要在Ubuntu(或Raspbian)上安装ImageMagick,只需使用apt:
使用OpenCVShell创建GIF
$ sudo apt-get install imagemagick
在macOS上,您可以使用HomeBrew:
$ brew install imagemagick
不实用
在大多数文章,课程和书籍中,我都使用方便的
imutils图像处理
包 。 它使用pip安装在系统或虚拟环境中:
$ pip install imutils
项目结构
 图 2.项目结构包括两个目录,一个配置文件和一个Python脚本
图 2.项目结构包括两个目录,一个配置文件和一个Python脚本我们的项目中有两个目录:
images/ :我们要为其制作动画GIF的输入图像的示例。 我发现了一些图像,但可以随意添加自己的图像。assets/ :此文件夹包含我们的脸部检测器,脸部界标检测器以及所有图像和相关蒙版。 有了这些资产,我们将把点和文本放在第一个文件夹中的原始图像上。
由于大量的可配置参数,我决定创建一个JSON配置文件,该文件:1)将有助于参数的编辑; 2)将需要更少的命令行参数。 该项目所需的所有配置参数都包含在
config.json 。
考虑
config.json和
create_gif.py的内容。
注意事项 每。: 注册后将发布有关计算机视觉,机器学习和OpenCV的项目代码和17页的手册(镜像: 源代码 , manual )。使用OpenCV生成GIF
因此,让我们继续并开始创建我们的OpenCV GIF生成器!
JSON配置文件内容
让我们从JSON配置文件开始,然后继续使用Python脚本。
打开一个新的
config.json文件,并插入以下键/值对:
使用OpenCVPython创建GIF
{ "face_detector_prototxt": "assets/deploy.prototxt", "face_detector_weights": "assets/res10_300x300_ssd_iter_140000.caffemodel", "landmark_predictor": "assets/shape_predictor_68_face_landmarks.dat",
这些是
深度学习中的
OpenCV人脸检测器模型文件。
最后一行是dlib人脸预测器的路径。
现在,我们有了一些图像文件的路径:
"sunglasses": "assets/sunglasses.png", "sunglasses_mask": "assets/sunglasses_mask.png", "deal_with_it": "assets/deal_with_it.png", "deal_with_it_mask": "assets/deal_with_it_mask.png",
这些是我们的太阳镜,文本和与之匹配的蒙版的路径,如下所示。
首先,花式太阳镜和口罩:
图 3.您不喜欢带像素的眼镜吗? 刚忍受图 4.您不明白为什么需要戴太阳眼镜的口罩? 只需忍受它-或阅读本文的其余部分以获取答案。现在我们的文字是“ DEAL WITH IT”和掩码:
图 5.您讨厌Helvetica Neue Condensed吗? 处理它图 6:使用此遮罩可以在文本周围绘制边框。 哦,也许您不想,想要边界吗? 好吧,忍受它需要使用遮罩才能将相应的图像覆盖在照片上:我们将在以后处理。
现在为模因生成器设置一些参数:
"min_confidence": 0.5, "steps": 20, "delay": 5, "final_delay": 250, "loop": 0, "temp_dir": "temp" }
以下是每个参数的定义:
min_confidence :所需的最小面部检测概率。steps :最终动画中的帧数。 每个“步骤”都将太阳镜从上边界向下移动到目标(即,眼睛)。delay :帧之间的延迟,以百分之一秒为单位。final_delay :最后一帧的延迟,以百分之一秒为单位(在此情况下很有用,因为我们希望文本显示的时间比其余帧的显示时间长)。loop :零值表示GIF永远重复,否则为动画的重复次数指定一个正整数。temp_dir :创建最终GIF之前将在其中存储每个帧的临时目录。
模因,GIF和OpenCV
我们创建了JSON配置文件,现在让我们继续进行实际代码。
打开一个新文件,将其命名为
create_gif.py并粘贴以下代码:
在这里,我们导入必要的包。 特别是,我们将使用imutils,dlib和OpenCV。 要安装这些依赖项,请参阅上面的“先决条件和依赖项”部分。
现在该脚本具有必需的包,因此
overlay_image定义
overlay_image函数:
def overlay_image(bg, fg, fgMask, coords):
overlay_image函数在
coords坐标
(坐标
(x,y) )处在背景图像(
bg )的顶部强加一个前景(
fg ),从而在前景蒙版
fgMask实现了alpha透明性。
要熟悉OpenCV的基础知识(例如使用遮罩),请务必阅读
本指南 。
要完成混合过程,请执行Alpha混合:
def alpha_blend(fg, bg, alpha):
该alpha混合实现也可以
在LearnOpenCV博客上找到 。
本质上,我们将前景,背景和Alpha通道转换为
[0,1]范围内的浮点数。 然后我们执行Alpha混合,添加前景和背景以获得返回到调用函数的结果。
我们还将创建一个辅助函数,该函数允许使用ImageMagick和
convert命令从一组图像路径生成GIF:
def create_gif(inputPath, outputPath, delay, finalDelay, loop):
create_gif函数获取一组图像并将其收集到GIF动画中,并在帧和循环之间具有指定的延迟。 ImageMagick处理所有这一切-我们仅将
convert命令包装在一个动态处理各种参数的函数中。
要查看可用的
convert参数,
请参阅文档 。 在这里,您将看到这个团队有多少功能!
特别是在此功能中,我们:
- 采取
imagePaths 。 - 选择最后一张图像的路径,它将有一个单独的延迟。
- 重新分配
imagePaths以排除最后一个路径。 - 我们将命令与命令行参数组合在一起,然后指示操作系统进行
convert以创建GIF动画。
为脚本分配自己的命令行参数:
我们有三个在运行时处理的命令行参数:
--config :JSON配置文件的路径。 我们在上一节中回顾了配置文件。--image :创建动画所依据的输入图像的路径(即检测面部,戴墨镜,然后输入文本)。--output :生成的GIF的路径。
在命令行/终端上运行脚本时,每个参数都是必需的。
下载配置文件以及眼镜和相应的掩码:
在这里,我们加载配置文件(将来可能会作为Python词典提供)。 然后装入墨镜和口罩。
如果以前的脚本中仍然有其他内容,请删除临时目录,然后重新创建空的临时目录。 临时文件夹将包含GIF动画中的每个单独的帧。
现在将
OpenCV深度学习人脸检测器加载到内存中:
为此,请调用
cv2.dnn.readNetFromCaffe 。
dnn模块仅在OpenCV 3.3或更高版本中可用。 人脸检测器将检测图像中是否存在人脸:
 图 7.使用OpenCV DNN进行面部检测器操作
图 7.使用OpenCV DNN进行面部检测器操作然后加载
dlib人脸界标预测器 。 它使您可以定位单个结构:眼睛,眉毛,鼻子,嘴巴和下巴线:
 图 8. dlib发现的地标叠加在我的脸上
图 8. dlib发现的地标叠加在我的脸上在此脚本的后面,我们仅提取眼睛区域。
继续前进,让我们找到面孔:
在此块中,我们执行以下操作:
- 下载原始
image 。 - 我们构造一个
blob以发送到神经网络的面部检测器。 本文介绍了OpenCV中的blobFromImage如何工作。 - 执行面部检测程序。
- 我们找到具有最高概率值的人,并将其与最小可接受概率阈值进行比较。 如果不符合条件,则退出脚本。 否则,请继续。
现在,我们将提取人脸并计算界标:
要提取脸部并找到脸部界标,请执行以下操作:
- 我们提取脸部周围的边界框的坐标。
- 在dlib中创建一个
rectangle对象并应用面本地化。 - 我们分别获取
leftEyePts和rightEyePts的(x,y)坐标。
给定眼睛的坐标,您可以计算出放置太阳镜的位置和方式:
首先,我们计算每只眼睛的中心,然后计算质心之间的角度。
框架中的面部水平
对齐时执行相同的操作。
现在,您可以旋转眼镜并调整其大小。 请注意,我们使用
的不是
rotate ,而是
rotate 绑定函数 ,因此OpenCV不会修剪仿射变换后不可见的部分。
应用于眼镜的相同操作也适用于面罩。 但是首先,您需要将其转换为灰色阴影并进行二值化处理,因为遮罩始终是二进制的。 然后,我们以与眼镜相同的方式旋转并调整蒙版的大小。
注意:请注意,在调整遮罩大小时,我们对最近的相邻点使用插值,因为遮罩应该只有两个值(0和255)。 其他插值方法更美观,但不适用于蒙版。 在这里,您可以获得有关最近邻点插值的更多信息。剩下的三个代码块为GIF动画创建框架:
眼镜从图像顶部掉落。 在每帧上,它们都靠近脸部显示,直到遮住眼睛为止。 使用JSON配置文件中的
"steps"变量,我们为每个框架生成y坐标。 为此,我们无需花费太多精力即可使用NumPy的
linspace函数。
从左到右稍微偏移的线条可能看起来有些奇怪,但是需要确保眼镜能覆盖整个眼睛,而不仅仅是移动到眼睛中心的位置。 我凭经验确定百分比以计算沿每个轴的偏移量。 下一行确保没有负值。
使用
overlay_image函数,
overlay_image生成最终的
output帧。
现在,使用另一个蒙版应用文本“ DEAL WITH IT”:
在最后一步,我们强加了文本,实际上是另一幅图像。
我决定使用图像,因为OpenCV字体的渲染功能非常有限。 另外,我想在文本周围添加阴影和边框,这也是OpenCV不知道的方法。
在此代码的其余部分中,我们将同时加载图像和蒙版,然后执行alpha混合以生成最终结果。
剩下的只是将每个帧保存到磁盘,并随后创建GIF动画:
我们将结果写入磁盘。 生成所有帧后,我们调用
create_gif函数来创建GIF动画文件。 请记住,这是一个将参数传递给ImageMagick
convert命令行工具的外壳。
最后,删除临时输出目录和单个图像文件。
结果
现在最有趣的部分:让我们看看我们的模因生成器创建了什么!
确保
下载源代码,示例图像和深度学习模型。 然后打开一个终端并运行以下命令:
$ python create_gif.py --config config.json --image images/adrian.jpg \ --output adrian_out.gif [INFO] loading models... [INFO] computing object detections... [INFO] creating GIF... [INFO] cleaning up...
 图9.使用此Python脚本由OpenCV和ImageMagick生成的GIF动画
图9.使用此Python脚本由OpenCV和ImageMagick生成的GIF动画在这里,您可以看到使用OpenCV和ImageMagick创建的GIF。 在其上执行以下操作:
- 正确检测我的脸。
- 眼睛的定位及其中心的计算。
- 眼镜正确落在脸上。
我博客的读者知道我是侏罗纪公园的一个大书呆子,经常在我的书,课程和学习指南中提到它。
不喜欢
侏罗纪公园吗?
好的,这是我的答案:
$ python create_gif.py --config config.json --image images/adrian_jp.jpg \ --output adrian_jp_out.gif [INFO] loading models... [INFO] computing object detections... [INFO] creating GIF... [INFO] cleaning up...
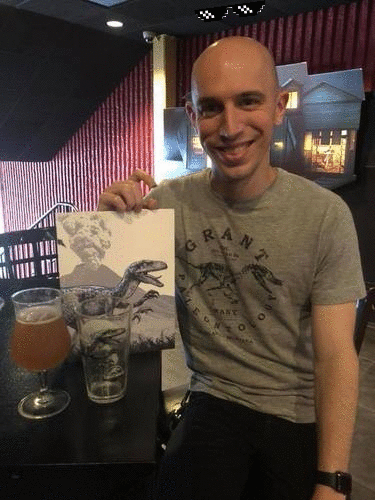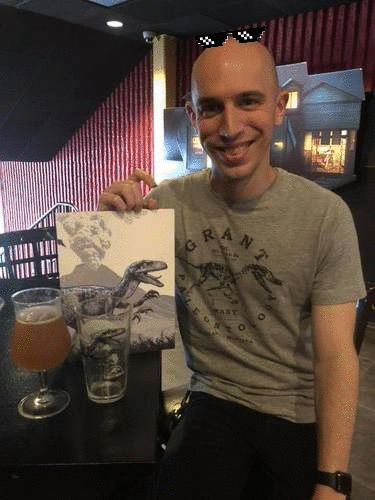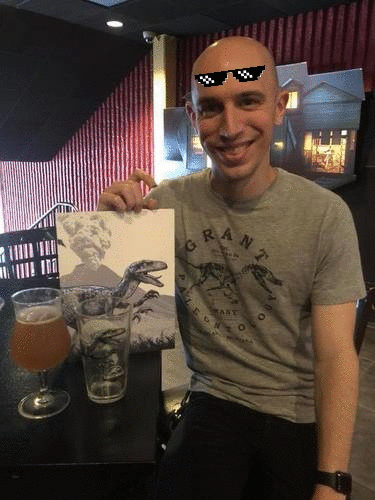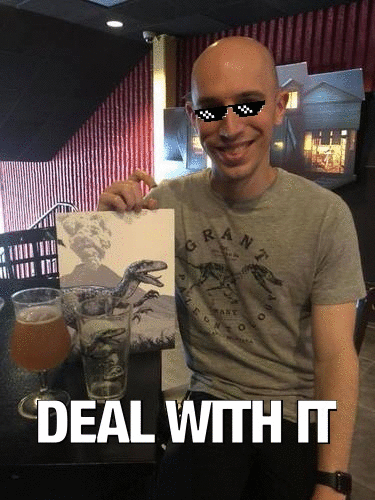 图 10. OpenCV GIF动画基于最近侏罗纪世界2放映中的照片
图 10. OpenCV GIF动画基于最近侏罗纪世界2放映中的照片在这里,我身着主题T恤参加了展览《侏罗纪世界:2》,上面放着一杯光,还有一本收藏书。
有趣的故事:
五六年前,我和我的妻子参观了佛罗里达迪斯尼世界的Epcot中心主题公园。
我们决定出差,以摆脱康涅狄格州严酷的冬季和急需的阳光。
不幸的是,在佛罗里达州一直下着雨,温度几乎不超过10°C。
在加拿大花园附近,特丽莎(Trisha)拍了一张我的照片:她说我看上去像个吸血鬼,皮肤苍白,深色衣服和兜帽,背后是郁郁葱葱的花园:
$ python create_gif.py --config config.json --image images/vampire.jpg \ --output vampire_out.gif [INFO] loading models... [INFO] computing object detections... [INFO] creating GIF... [INFO] cleaning up...
 图 11.使用OpenCV和Python,您可以制作此模因或其他动画GIF
图 11.使用OpenCV和Python,您可以制作此模因或其他动画GIF当天晚上,Trisha在社交网络上发布了一张照片-我不得不忍受。
参加了PyImageConf 2018的那些人(
阅读评论 )知道我总是很喜欢开玩笑。 这是一个例子:
问题:为什么公鸡过马路? $ python create_gif.py --config config.json --image images/rooster.jpg \ --output rooster_out.gif [INFO] loading models... [INFO] computing object detections... [INFO] creating GIF... [INFO] cleaning up...
 图 12.即使对比度低也可以识别出脸部,OpenCV会正确处理照片并放下 墨镜答案:我不会说答案-对此表示赞同。最后,我们以良好的模因总结了本指南。大约六年前,我和父亲收养了一只小猎犬吉玛。在这里,您可以看到Gemma在我的肩膀上:
图 12.即使对比度低也可以识别出脸部,OpenCV会正确处理照片并放下 墨镜答案:我不会说答案-对此表示赞同。最后,我们以良好的模因总结了本指南。大约六年前,我和父亲收养了一只小猎犬吉玛。在这里,您可以看到Gemma在我的肩膀上: $ python create_gif.py --config config.json --image images/pupper.jpg \ --output pupper_out.gif [INFO] loading models... [INFO] computing object detections... [INFO] creating GIF... [INFO] cleaning up...
 图 13. Gemma很好吃。你不这样认为吗 然后“顺其自然!”不同意她是可爱的吗?处理它。
图 13. Gemma很好吃。你不这样认为吗 然后“顺其自然!”不同意她是可爱的吗?处理它。有AttributeError错误吗?
不用担心!如果看到此错误: $ python create_gif.py --config config.json --image images/adrian.jpg \ --output adrian_out.gif ... Traceback (most recent call last): File "create_gif.py", line 142, in <module> (lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"] AttributeError: module 'imutils.face_utils' has no attribute 'FACIAL_LANDMARKS_IDXS'
...那么您只需要更新imutils软件包: $ pip install --upgrade imutils Collecting imutils ... Successfully installed imutils-0.5.1
怎么了默认情况下,它imutils.face_utils使用内置于dlib中的68点地标检测器(如本文所述)。有一个更快的5点检测器,现在也可以与imutils一起使用。我最近更新了imutils以支持两个检测器(因此您可能会看到错误)。总结
在今天的教程中,您学习了如何使用OpenCV创建GIF。为了使课程有趣,我们使用OpenCV生成了GIF动画“ Deal With It”,这是一个流行的模因(也是我的最爱),在几乎每个社交网站上都以一种或另一种形式出现。在此过程中,我们使用计算机视觉和深度学习解决了一些实际问题:- 身份识别
- 预测脸上的地标
- 识别面部区域(在这种情况下为眼睛)
- 计算眼睛之间的角度以对齐脸部
- 使用Alpha混合创建透明混合
最后,我们拍摄了一组生成的图像,并使用OpenCV和ImageMagick创建了动画GIF。希望您喜欢今天的教程!如果您喜欢它,请发表评论,让我知道。好吧,如果您不喜欢它,没关系,就忍受它。 ;)