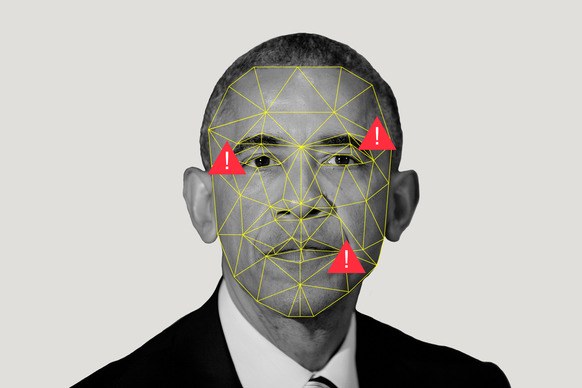
数周来,计算机科学专家Siwei Lyu一直在痛苦地观看着他的团队制作的Deepfake视频。 这些使用机器学习算法制作的假电影向名人展示了他们做不到的事情。 他们似乎对他感到奇怪,不仅仅是因为他知道他们是假的。 他回忆说:“他们看起来错了,但是要精确地确定造成这种印象的位置非常困难。”
但是一旦进入他的大脑,便有了童年的记忆。 像其他许多孩子一样,他和孩子们一起玩“小偷”。 他说:“我总是输掉这样的比赛,因为当我看着他们不眨眼的面孔时,我感到非常不安。”
他意识到这些假冒电影给他带来了类似的不适:他向这些电影明星扮演了窥视者,因为他们没有像真实的人那样睁开或闭上眼睛。
为了找出原因,奥尔巴尼大学的教授Luy和他的团队研究了创建这些视频的
DeepFake软件的每个步骤。
Deepfake程序会在入口处拍摄很多特定人物的图像-您,您的前女友金正恩-这样就可以从不同的角度看到它们,并用不同的面部表情说不同的话。 算法会学习此角色的外观,然后在视频中综合所获得的知识,以展示此人如何做他从未做过的事情。
色情内容 斯蒂芬·科尔伯特(Stephen Colbert)讲约翰·奥利弗(John Oliver)的话。 总统
警告有关假视频的危险。
这些视频在电话屏幕上显示了令人信服的几秒钟,但它们(尚不完美)。 可以看到它们是伪造的迹象,例如,由于其创建过程的缺陷而以一种奇怪的方式不断睁开眼睛。 看着DeepFake的勇气,Lu意识到在程序学习的图像中,闭着眼睛的照片并不多(因为您没有保持眨眼的自拍照?)。 他说:“这变得扭曲了。” 神经网络不了解闪烁。 Luya说,程序也可能会错过其他“人体内固有的生理信号”,即以正常速度呼吸或出现脉搏。 尽管这项研究的重点是使用特定软件制作的商业广告,但通常公认的是,即使是大量照片也可能无法充分描述人的身体感知,因此在这些图像上训练的任何软件都是不完善的。
关于眨眼的启示揭示了很多假视频。 但是,在Lu和团队在网上发布工作草稿几周后,他们收到了一封匿名信,其中包含指向YouTube上发布的下一批假视频的链接,在那儿,明星们以一种更加正常的方式睁开并闭上了眼睛。 假的创造者已经进化。
这是自然的。 正如陆在
接受 The Conversation
采访时指出的那样,“可以通过在数据库中包括闭眼的图像或使用视频进行训练,将闪烁添加到Deepfake视频中。” 知道伪造的迹象是什么,您就可以避免-这“只是”一个技术问题。 这意味着假视频将参与创作者与识别者之间的军备竞赛。 像Luy的作品这样的研究只会使假冒制造商的生活复杂化。 他说:“我们正在努力提高标准。” “我们希望使这一过程复杂化,使其更加耗时。”
因为现在很简单。 下载该程序,谷歌名人照片,并将其输入程序入口。 她消化它们,向它们学习。 尽管她还没有完全独立,但在一点点帮助下,她仍然承受并生出了一些新奇而真实的东西。
“她很模糊,”卢说。 而且他不是图像。 他说:“这是在真假之间。”
这同时使所有人生气,也不会令最近还活着并且正在上网的人感到惊讶。 但这尤其令军事和情报部门感到担忧。 特别是,这就是为什么Lu的研究与其他一些研究一样,都由
DARPA计划 MediFor-Media Forensics [media forensics]资助的。
MediFor项目于2016年启动,当时该机构注意到假冒制造商的活动有所增加。 该项目正在尝试创建一个自动系统,该系统可以研究伪造迹象的三个级别,并对图像或视频进行“真实性评估”。 在第一层上,搜索肮脏的数字轨道-特定型号的相机发出的噪声或压缩伪影。 第二个层次是物理的:照明不在脸上,在这种灯的布置下,反射看起来并不像它看起来的样子。 后者是语义上的:将数据与已确认的真实信息进行比较。 例如,如果声称捕获足球比赛的视频是在2018年10月9日星期二下午2点在中央公园拍摄的,那么天空状况与天气档案是否一致? 收集所有级别,并评估数据的真实性。 DARPA希望到MediFor结束时,将有可能进行大规模检查的系统原型。
但是,时钟在滴答作响(或者仅仅是重复的,由接受过与时间跟踪相关的数据训练的AI发出的声音吗?)“几年后,您将能够碰到事件的制造,” DARPA计划经理Matt Turek说。 “不仅是单张图像或剪辑过的视频,还有试图传达引人注目的信息的几张图像或剪辑。”
在洛斯阿拉莫斯国家实验室,计算机科学家贾斯汀·摩尔对潜在的未来有了更清晰的了解。 假设:我们告知算法,我们需要一个有关Moore抢劫药房的视频; 我们将其引入该机构安全系统的录像中; 送他入狱。 换句话说,他担心,如果不能(或不能)与制造假冒产品同时发展出用于验证证据的标准,就会很容易替代人。 而且,如果法院不能依靠视觉数据,可能会发现真实的证据将被忽略。
我们得出一个合理的结论,即一次见面不会比听一百遍更好。 他说:“我们可能不相信任何摄影证据,但我不想生活在这样的世界中。”
这样的世界并不是那么不可思议。 摩尔认为,问题远不止于取代个人。 摩尔说:“算法可以
创建不属于真实人的图像,它们可以奇怪地改变图像,将一
匹马变成斑马 。” 他们可以
删除部分图像,并
删除视频中的前景对象。
也许我们将无法更快地处理假货。 但是也许会成功-这次机会为摩尔团队提供了研究数字方法研究证据的动力。 结合网络系统,信息系统,理论生物学和生物物理学知识的洛斯阿拉莫斯计划比DARPA机构年轻约一年。 在图像包含的信息看起来不那么多的情况下,一种方法侧重于“可压缩性”。 “基本上,我们基于所有AI图像生成器都只能创建有限的一组东西的想法,” Moore说。 “因此,即使图像对我或您来说看起来相当复杂,您也可以在其中找到重复的结构。” 回收像素时,剩余的很少。
他们还使用稀疏编码算法与比赛进行比赛。 假设我们有两个集合:一堆真实图像和一堆人工创建的AI图片。 该算法对它们进行了研究,创建了摩尔所谓的“视觉元素词典”,并指出人造图片具有某些共同点,而真实图像具有某些共同点。 如果穆尔的朋友转发了奥巴马的图像,并且摩尔认为该图像是使用AI制作的,那么他将能够在程序中运行该图像,并找出将更接近哪个词典。
世界上功能最强大的超级计算机之一洛斯·阿拉莫斯(Los Alamos)将资源上传到该程序,不仅因为有人可以通过假抢劫来代替摩尔。 实验室的任务是“在科学卓越的帮助下解决国家安全问题”。 他们的主要任务是核安全,保证炸弹在不应该炸弹时不爆炸,在不应该炸弹时(请不要)爆炸,并提供不扩散援助。 所有这些都需要机器学习的一般知识,因为正如摩尔所说,这有助于“从小数据集中得出大结论”。
但除此之外,像Los Alamos这样的企业应该能够相信自己的眼睛-或知道何时不需要信任。 因为,如果您看到一个国家如何动员或测试核武器的卫星图像怎么办? 如果有人伪造传感器读数怎么办?
这是一个可怕的未来,理想情况下应避免摩尔和卢的工作。 但是,在一个万物流失的世界中,看到并不意味着要相信,但似乎绝对的测量值可能是假的。 一切数字化都令人怀疑。
但是也许“怀疑”是错误的词。 许多人会以表面价值来伪造商品(还记得休斯顿鲨鱼的
照片吗?),尤其是当内容符合他们的信念时。 摩尔说:“人们会相信他们倾向于相信的东西。”
对于普通民众来说,观看新闻的可能性要比在国家安全领域高。 为了防止错误信息在我们的简单信息中传播,DARPA提供了社交媒体协作,以帮助用户确定金正恩在跳舞杏仁饼的视频的可信度很低。 Turek指出,社交网络可以像反驳视频一样迅速地传播反驳视频的故事。
但是他们会这样做吗? 暴露是一个
麻烦的过程(尽管没有谣传那样
低效 )。 人们需要真正展示事实,然后才能改变对小说的看法。
但是,即使没有人能改变群众对视频准确性的看法,重要的是,做出政治和法律决定的人(关于谁在运送火箭弹或杀人)也试图使用机器将明显的现实与AI睡眠区分开。