使用python,sklearn,scipy,XGBoost,pymorphy2,nltk,gensim,MongoDB,Keras和TensorFlow对18年(从1999年9月至2017年12月)的Lenta.ru出版物进行分析。

该研究使用了来自ildarchegg的 “ Analyze this-Lenta.ru ” 帖子中的数据 。 作者以方便的格式提供了3 GB的文章,我认为这是测试某些文本处理方法的绝佳机会。 同时,如果您幸运的话,请学习有关俄罗斯新闻,社会乃至整个社会的新知识。
内容:
MongoDB在python中导入json
不幸的是,带有文本的json有点破损,这对我来说并不重要,但是python拒绝使用该文件。 因此,我首先将其导入到MongoDB中,然后才通过pymongo库中的MongoClient,加载数组并将其分段存储在csv中。
从评论中:1.我不得不使用sudo service mongod start命令启动数据库-还有其他选项,但是它们不起作用; 2. mongoimport-一个单独的应用程序,它不从mongo控制台启动,仅从终端启动。
数据差距在几年中平均分布。 我不打算使用少于一年的期限,希望它不会影响结论的正确性。
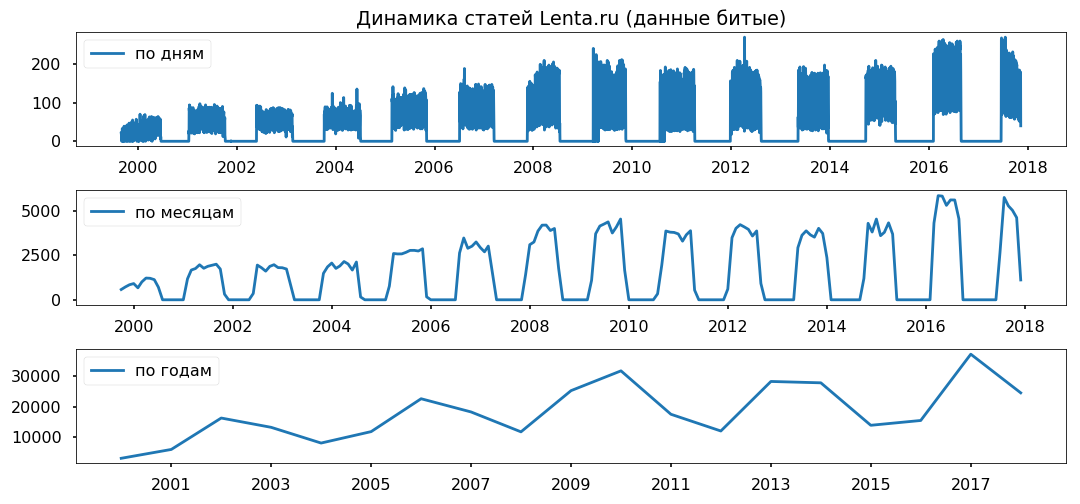
清理和规范化文本
在直接分析数组之前,需要将其转换为标准格式:删除特殊字符,将文本转换为小写(熊猫字符串方法做得很好),删除停用词(nltk.corpus中的stopwords.words(“ russian”)),将单词恢复为正常格式使用lemmatization(pymorphy2.MorphAnalyzer)。
有一些缺陷,例如Dmitry Peskov变成了“ Dmitry”和“ sand”,但是总的来说,我对结果感到满意。
标签云
作为种子,让我们看看最一般形式的出版物。 我们将以标签云的形式显示Lenta记者从1999年到2017年使用的50个最常见的单词。

Ria Novosti(最受欢迎的新闻来源),十亿美元和一百万美元(金融话题),礼物(所有新闻站点通用的语音分发),执法机构和刑事案件(犯罪新闻) ),“总理”和“普京”(政治)-新闻门户的预期样式和主题。
LDA主题建模
我们使用gensim的LDA计算出每年最受欢迎的主题。 LDA(使用Dirichlet潜在放置方法的主题建模)通过在文章中观察到的词频自动显示隐藏的主题(一组在一起并且最经常出现的词)。
国内新闻的基石是俄罗斯,普京和美国。
在几年中,这个话题随着车臣战争(从1999年至2000年),9月11日-2001年的伊拉克(从2002年至2004年)而被淡化。 从2008年到2009年,经济处于第一位:利息,公司,美元,卢布,十亿,百万。 在2011年,他们经常写关于卡扎菲的文章。
从2014年到2017年 乌克兰的岁月开始并在俄罗斯继续。 高峰发生在2015年,然后趋势开始下降,但仍继续保持在较高水平。
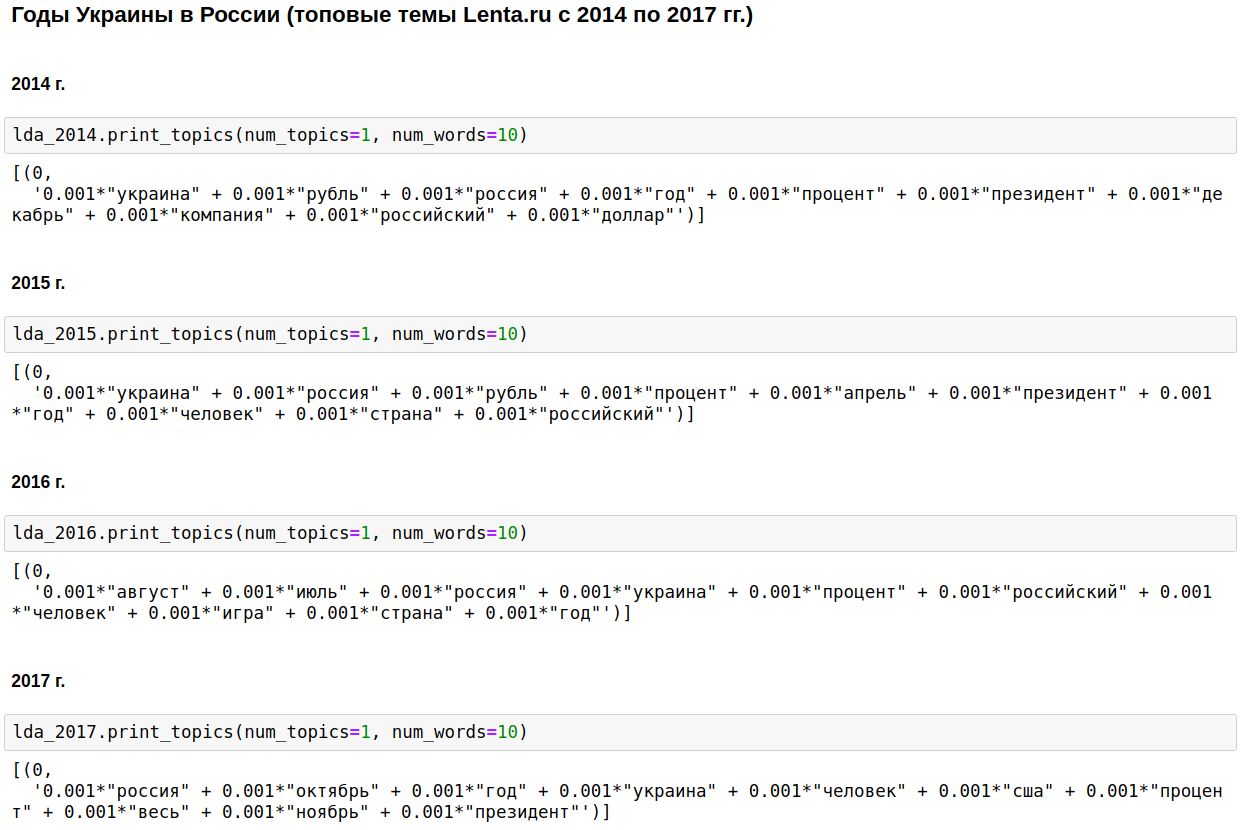
当然,这很有趣,但是没有什么我不会知道或猜不到的。
让我们稍微改变一下方法-始终选择最重要的主题,并查看它们的比例逐年变化,也就是说,我们将研究主题的演变。
解释最多的选项是前5名:
- 犯罪(男性,警察,发生,拘留,警察);
- 政治(俄罗斯,乌克兰,美国总统,负责人);
- 文化(旋转,化脓,instagram,漫无边际-是的,这是我们的文化,尽管具体而言,这个话题非常复杂);
- 体育(比赛,团队,比赛,俱乐部,运动员,冠军);
- 科学(科学家,太空,卫星,行星,细胞)。
接下来,我们阅读每篇文章,并查看其与特定主题的关系,结果,所有材料将分为五个组。
事实证明,该政策是最受欢迎的政策-占所有出版物的80%以下。 但是,政治材料的流行高峰在2014年过去了,现在它们的份额正在下降,并且对犯罪和体育信息议程的贡献正在增加。
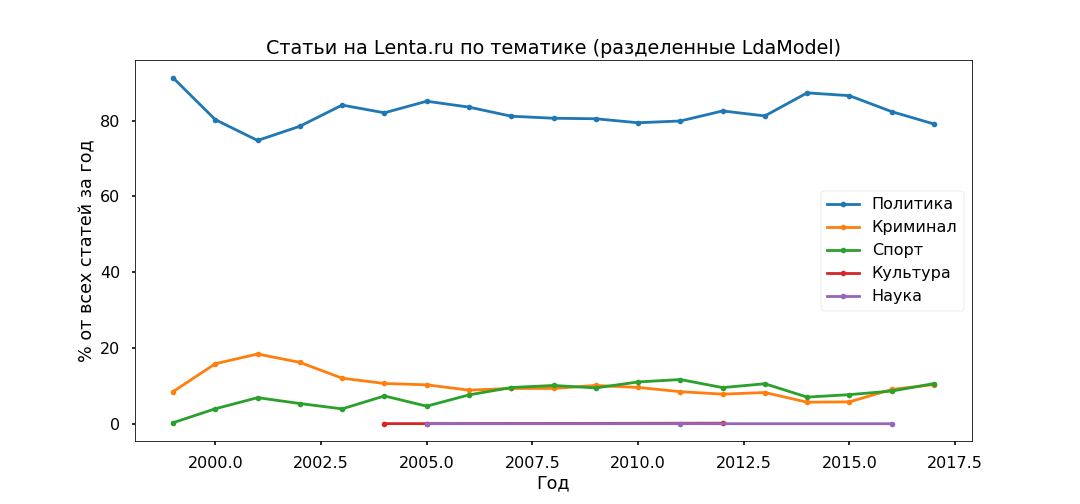
我们将使用编辑指定的小标题来检查主题模型的适当性。 自2013年以来,最基本的子类别已被正确识别。

没有特别的矛盾被注意到:政治在2017年停滞不前,足球和突发事件在增长,乌克兰仍然处于趋势中,2015年达到顶峰。
流行度预测:XGBClassifier,LogisticRegression,嵌入和LSTM
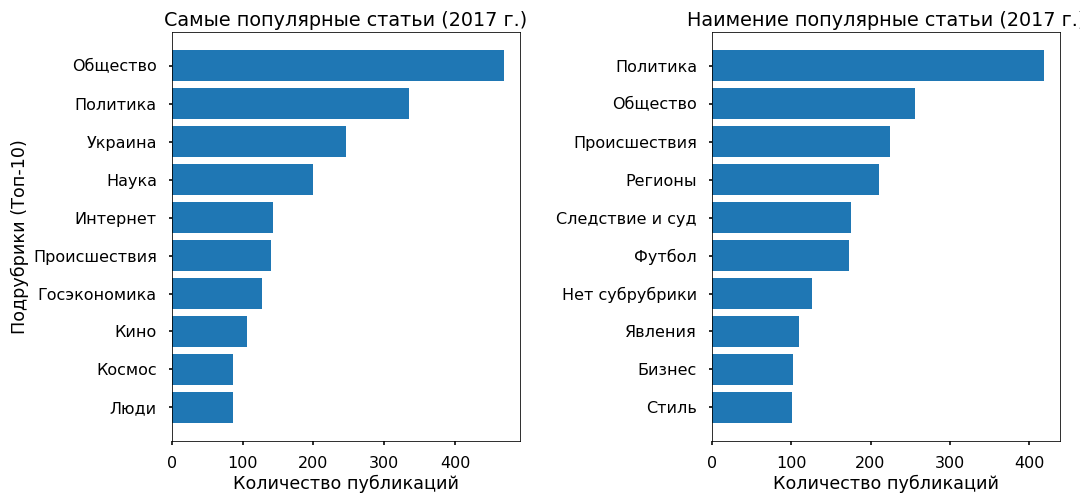
让我们尝试了解是否可以根据文本预测磁带上文章的受欢迎程度,以及该受欢迎程度通常取决于什么。 作为目标变量,我采用了2017年Facebook重新发布的次数。
2017年有3000篇文章在Fb上没有转发-他们被分配为“不受欢迎”类,转发数最多的3000篇文章被标记为“最受欢迎”。
文本(2017年有6000种出版物)被分为unogram和bigrams(令牌词,单词和两个词的短语),并构建了一个矩阵,其中列是标记,行是文章,并且在相交处是相对的文章中单词出现的频率。 sklearn中使用的函数-CountVectorizer和TfidfTransformer。
准备好的数据输入到XGBClassifier(基于来自xgboost库的梯度提升的分类器),在枚举超参数13分钟(cv = 3的GridSearchCV)13分钟后,该数据在测试中的准确性为76%。

然后,我使用了通常的逻辑回归(sklearn.linear_model.LogisticRegression),在17秒后,我的准确度达到了81%。
我再次相信,只要精心准备数据,线性方法最适合于文本分类。
为了向时尚致敬,我对神经网络进行了一些测试。 他使用来自keras的one_hot将单词翻译成数字,将所有文章都放到相同的长度(来自keras的pad_sequences函数),并通过Embedding层应用LSTM(卷积神经网络,使用TensorFlow后端)(以减小尺寸并加快处理时间)。
该网络在2分钟内即可正常工作,在测试中显示出70%的准确性。 完全没有限制,但是在这种情况下,多打扰是没有意义的。
通常,所有方法产生的准确性都相对较低。 经验表明,分类算法可以与多种样式配合使用-换句话说,就是版权材料。 Lenta.ru上有这类材料,但数量很少-不到2%。

主数组是使用中性新闻词汇编写的。 新闻的受欢迎程度不仅取决于文本本身,甚至不取决于主题本身,而取决于新闻的上升趋势。
例如,相当多的热门文章涵盖了乌克兰的活动,最受欢迎的文章几乎与该主题无关。
使用Word2Vec探索对象
最后,我想进行情感分析-了解记者如何与他们在文章中提到的最受欢迎的对象相关联,以及他们的态度是否随着时间而改变。
但是我没有标记的数据,而且搜索语义叙词表不太可能正确进行,因为新闻词汇是相当中性的,会引起情感的困扰。 因此,我决定专注于提到对象的上下文。
我接受了乌克兰(2015年对2017年)和普京(2000年对2017年)的测试。 我选择了其中提到它们的文章,将文本转换为多维向量空间(来自gensim.models的Word2Vec),并使用“主要组件”方法投影到二维上。
渲染完照片后,它们证明是史诗般的,至少不亚于贝叶挂毯的挂毯。 我尽量减少必要的分类,以简化感知,对“ jack狼”感到抱歉。


我注意到了。
普京2000年模式的出现总是出现在俄罗斯的背景下,并亲自谈到。 2017年,俄罗斯联邦总统成为领导人(无论意味着什么)并与俄罗斯保持距离,现在,根据上下文来看,他是克里姆林宫的代表,他通过新闻秘书与世界进行交流。
俄罗斯媒体中的“乌克兰-2015”-战争,战斗,爆炸; 它提到了个性化(基辅说,基辅开始)。 乌克兰-2017年主要出现在官员之间的谈判中,这些人有特定的名字。
...
您可以解释接收到的信息相当长的时间,但是,正如我认为的那样,这是该资源之外的资源。 那些希望的人可以自己看看。 我附上代码和数据。
脚本链接
资料连结