
如您所知,HTTP 1.1是基于文本的数据传输协议。 HTTP消息使用ISO-8859-1进行编码(可以有条件地将其视为ASCII的扩展版本,其中包含变音符号,变音符号和西欧语言中使用的其他字符)。 同时,可以在邮件正文中使用其他编码,该编码应在“ Content-Type”标头中指出。 但是,如果我们需要不在消息正文中而是在标头本身中指定非ASCII字符,该怎么办? 可能最常见的情况是将文件名放在“ Content-Disposition”标头中。 这似乎是一个相当普通的任务,但是其实现并不是那么明显。
TL; DR:使用
RFC 6266中描述的“内容处置”编码,在其他情况下,将文本转换为拉丁语(音译)。
编码简介
本文提到并使用US-ASCII编码(通常简称为ASCII),ISO-8859-1和UTF-8。 这是对这些编码的简短介绍。 本部分适用于很少或完全不使用编码并设法忘记编码的开发人员。 如果您不属于他们,请随时跳过本节。
ASCII是一种简单的编码,包含128个字符,包括整个英文字母,数字,标点符号和服务字符。
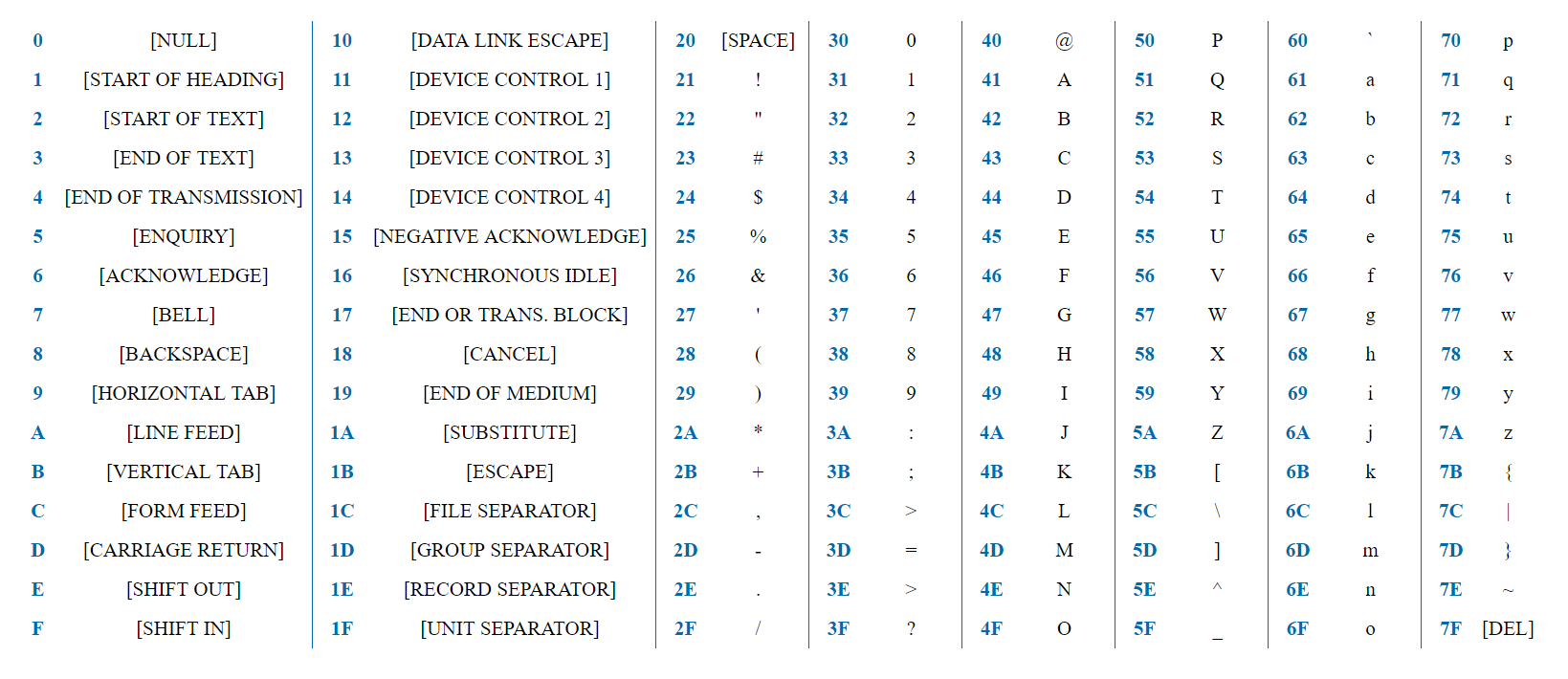
7位足以表示任何ASCII字符。 单词“ test”将以十六进制表示形式表示为0x74 0x65 0x73 0x74。 所有字符的第一位始终为0,因为这些字符以128编码,并且该字节提供2 ^ 8 = 256个选项。
ISO-8859-1是用于西欧语言的编码。 包含法国变音符号,德国变音符号等。
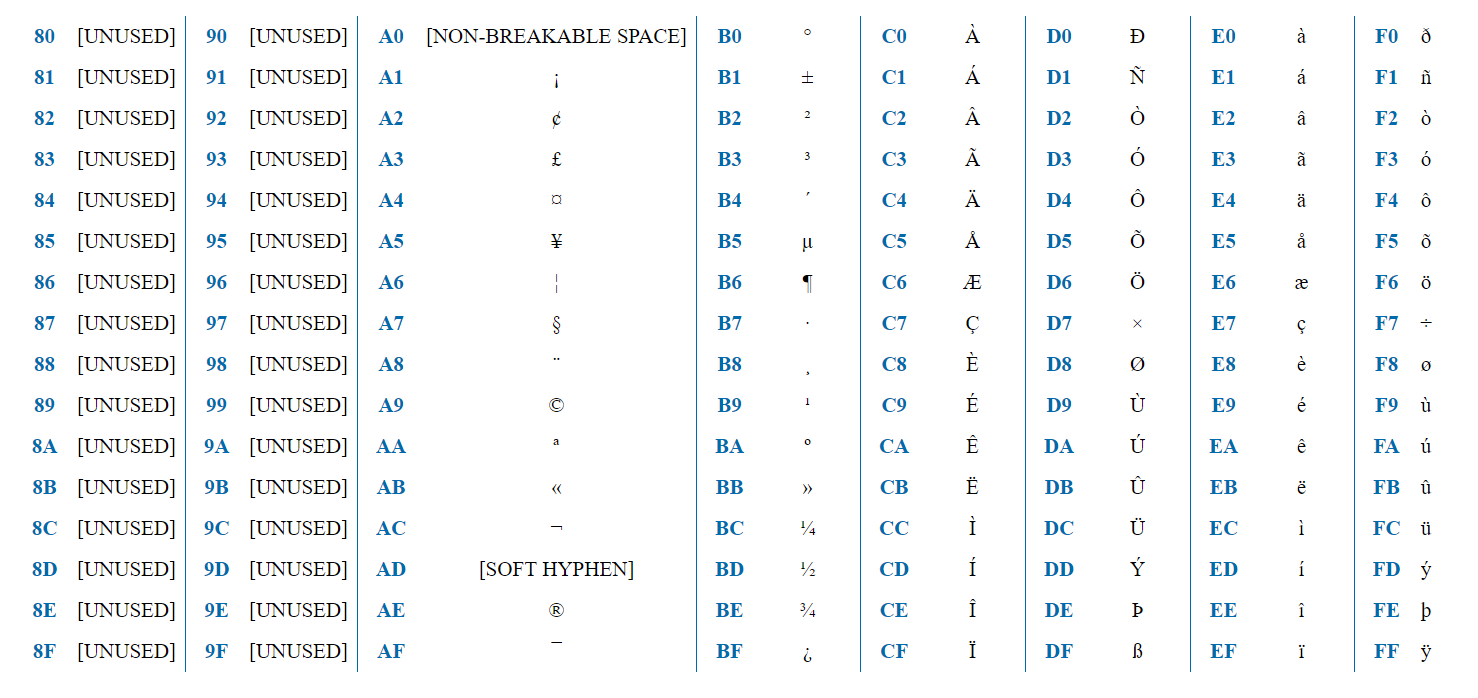
该编码包含256个字符,因此可以用一个字节表示。 前半部分(128个字符)与ASCII完全相同。 因此,如果第一位= 0,则这是常规ASCII字符。 如果为1,则这是ISO-8859-1特有的字符。
UTF-8和ASCII是最著名的编码之一。 能够编码1.112.064个字符。
每个字符的大小从1到4个字节
不等 (
以前最多允许6个字节)。

使用此编码的程序通过前几位确定字符中包含多少字节。 如果八位位组从0开始,则该字符由一个字节表示。 110-两个字节,1110-三个字节,11110-4个字节。
与ISO-8859-1一样,前128个字符完全符合ASCII。 因此,无论使用US-ASCII,ISO-8859-1还是UTF-8进行编码,仅使用ASCII字符的文本在二进制表示形式中都将完全相同。
在邮件正文中使用UTF-8
在转到标题之前,让我们快速看一下如何在邮件正文中使用UTF-8。 为此,请使用标题
“ Content-Type” 。

如果未指定“ Content-Type”,则浏览器应像处理ISO-8859-1一样处理消息。
浏览器不应尝试猜测编码,而且,请忽略“ Content-Type”。 但是在未传输“ Content-Type”的情况下真正出现的情况取决于浏览器的实现。 例如,Firefox将按照规范进行操作,并按照ISO-8859-1中的编码方式读取消息。 相比之下,谷歌浏览器将使用操作系统的编码,对于许多俄罗斯用户而言,该编码等于Windows-1251。 无论如何,如果该消息使用的是UTF-8,则不会正确显示。

我们将UTF-8消息放在标头值中
使用消息正文,一切都非常简单。 消息的正文始终跟随标题,因此没有技术问题。 但是头条新闻呢? 该规范
明确指出消息中标头的顺序无关紧要。 即 无法在一个标头到另一个标头中指定编码。
如果仅将UTF-8值写入标头值,会发生什么情况? 我们已经看到,对消息正文的这种欺骗将导致仅在ISO-8859-1中读取该值。 假设标题会发生同样的事情是合乎逻辑的。 但是事实并非如此。 实际上,在很多(如果不是大多数)情况下,此解决方案将起作用。 其中包括旧版iPhone,IE11,Firefox,Google Chrome。 撰写本文时,触手可及的唯一不希望使用该标题的浏览器是Edge。

此行为未记录在规格中。 也许浏览器开发人员决定使开发人员的工作更轻松,并自动检测消息标头是用UTF-8编码的。 通常,这并不是一件困难的任务。 我们看一下第一位:如果为0,则为ASCII,如果为1-则可能为UTF-8。
在这种情况下是否与ISO-8859-1交叉? 实际上,几乎没有。 以UTF-8为例,一个2个八位字节的字符(俄语字母由两个八位字节表示)。 显示的二进制文件中的符号将如下所示:
110xxxxx 10xxxxxx 。 在十六进制表示中:
[0xC0-0x6F] [0x80-0xBF] 。 在ISO-8859-1中,这些字符几乎无法编码承载语义负载的内容。 因此,浏览器错误地解密消息的风险非常小。
但是,当您尝试使用此方法时,可能会遇到技术问题:您的Web服务器或框架可能根本不允许将UTF-8字符写入标头值。 例如,Apache Tomcat放置0x3F(问号)而不是所有UTF-8字符。 当然,可以绕开此限制,但是如果应用程序本身在握手并且不允许执行某些操作,那么也许您不需要这样做。
但是,无论您的框架或服务器是否允许您将UTF-8消息写入标头,我都不建议这样做。 这不是文档化的解决方案,该解决方案可能会在任何给定时间停止在浏览器中运行。
已转换
我认为使用了translit-eto bolee horoshee reshenie。 许多俄罗斯流行的大型资源都不会轻视文件名中的音译。 这是一个有保证的解决方案,不会随新浏览器的发布而中断,并且不需要在每个平台上分别进行测试。 当然,尽管您需要考虑如何转换可能字符的整个范围,但这可能并非完全无关紧要。 例如,如果应用程序是为俄罗斯读者设计的,则文件名中可能会出现Ta和letters字母Ta,文件名必须以某种方式进行处理,而不仅仅是用“?”代替。
RFC 2047
正如我已经提到的,tomkat不允许我在消息头中放入UTF-8。 Servlet的Java文档中是否反映了此行为功能? 是的,反映:
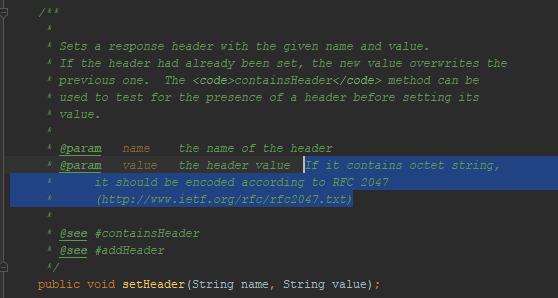
提及
RFC 2047 。 我试图使用这种格式对消息进行编码-浏览器无法理解我。 此编码方法在HTTP中不起作用。 虽然他以前工作过。 例如,从Firefox
删除对这种编码的支持的
票证 。
RFC 6266
在票证中,该票证是上一部分中的链接,其中
引用了
一些参考资料 ,即使在终止对RFC 2047的支持之后,仍然存在一种以下载文件的名称
RFC 6266的形式传输UTF-8值的方法。 我认为,这是迄今为止最正确的决定。 许多流行的在线资源都在使用它。 我们在
CUBA平台上也使用此特定的RFC来生成“内容处置”。
RFC 6266是描述“ Content-Disposition”标头使用的规范。 在另一个规范
RFC 8187中详细描述了编码方法本身。

“ filename”参数包含采用任何必需编码的ASCII文件名“ filename *”。 使用这两个属性,在所有现代浏览器(包括IE11和旧版本的Safari)中都会忽略“文件名”。 相反,大多数旧的浏览器都忽略“ filename *”。
使用此编码方法时,参数首先指示编码,然后指示编码值。 不需要来自ASCII编码的可见字符。 其余字符仅以十六进制表示,每个八位字节前都有一个“%”。
与其他标头做什么?
RFC 8187中描述的编码不是通用的。 是的,您可以在标头中添加带*前缀的参数,甚至在某些浏览器中也可以使用,但是
规范告诉您不
要这样做 。
在标头中支持UTF-8的每种情况下,当前在相关的RFC中都明确提到了这一点。 除Content-Disposition外,此编码还用于例如
Web链接和
摘要访问身份验证 。
应当指出,这方面的标准正在不断变化。
仅在2010年才
提出在HTTP中使用上述编码。 该编码在“ Content-Disposition”中的使用已
在2011年的标准中得到了
固定 。 尽管这些标准仅
处于“提议的标准”阶段 ,但它们在任何地方都得到支持。 我们不排除在将来我们期望新标准允许在标头中使用不同编码进行更统一工作的可能性。 因此,仅需遵循HTTP标准及其在浏览器方面的支持级别的新闻。