光学字符识别(OCR)是获取数字化格式的印刷文本的过程。 如果您在数字设备上阅读经典小说或要求医生通过医院计算机系统获取旧病历,则可能使用了OCR。
OCR使以前的静态内容可编辑,可搜索和可共享。 但是,许多需要数字化的文档包含咖啡渍,角落卷曲的页面以及许多使某些打印文档无法数字化的皱纹。
长期以来,每个人都知道有数百万本旧书存储在存储中。 由于这些书的破旧和破旧,因此禁止使用它们,因此这些书的数字化非常重要。
本文考虑了清除噪声中的文本,识别图像中的文本并将其转换为文本格式的任务。

为了训练,使用了144张图片。 大小可以不同,但最好在合理范围内。 图片必须为PNG格式。 读取图像后,将使用二值化-将彩色图像转换为黑白的过程,即将每个像素标准化为0到255的范围,其中0为黑色,255为白色。
要训练一个卷积网络,您需要的图像要多得多。 决定将图像分成几部分。 由于训练样本包含不同大小的图像,因此每个图像都被压缩为448x448像素。 结果是144张图像的分辨率为448x448像素。 然后将它们全部切成尺寸不重叠的112x112像素窗口。

因此,在144张初始图像中,获得了训练集中约2304张图像。 但这还不够。 良好的卷积网络训练需要更多的训练。 结果,最好的选择是将图片旋转90度,然后旋转180度和270度。 结果,将大小为[16,112,112,1]的数组提供给网络输入。 其中16是图像数量,112是每个图像的宽度和高度,1是颜色通道。 原来有9216个训练示例。 这足以训练卷积网络。
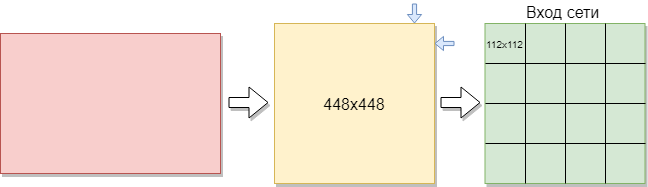
每个图像的尺寸为112x112像素。 如果尺寸太大,则计算复杂度将增加,因此,将违反对响应速度的限制,通过选择方法解决了该问题中尺寸的确定。 如果选择的尺寸太小,网络将无法识别关键标志。 每个图像都有黑白格式,因此分为1个通道。 彩色图像分为3个通道:红色,蓝色,绿色。 由于我们有黑白图像,因此每个图像的大小为112x122x1像素。
首先,有必要在准备好的,经过处理的图像上训练卷积神经网络。 为此,选择了U-Net体系结构。
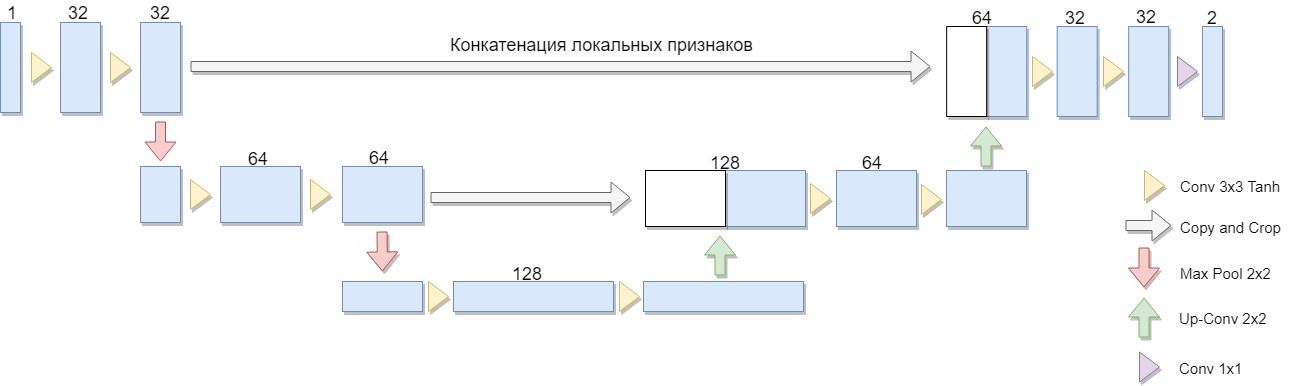
选择了简化的体系结构版本,仅包含两个块(原始版本为四个)。 一个重要的考虑因素是,在这样的体系结构或类似体系结构中明确表达了大量众所周知的二值化算法(例如,我们可以用平均偏差代替标准偏差来修改Niblack算法,在这种情况下,网络的构建特别简单)。
这种体系结构的优势在于,对于训练网络,您可以从少量的源映像中创建足够数量的训练数据。 此外,由于其卷积架构,网络具有相对较少的权重。 但是有一些细微差别。 特别地,严格地说,使用的人工神经网络不能解决二值化问题:对于源图像的每个像素,它会关联一个0到1的数字,该数字表示该像素属于某一类(有意义的填充或背景)的程度,并且是必要的仍转换为最终的二进制答案。 [1]
U-Net由压缩和解压缩路径以及它们之间的“转发”组成。 在这种体系结构中,压缩路径由两个块组成(原始版本为四个)。 每个块有两个带3x3滤波器的卷积(在卷积后使用Tanh激活函数),以及具有2x2滤波器大小的池(以2为步长)。每级下降的通道数加倍。
压缩路径也包含两个块。 它们中的每一个都包括一个2x2的滤镜大小的“扫描”,通道数量减半,与来自压缩路径的相应裁剪特征图的连接(“转发”)以及两个3x3滤镜的卷积(在卷积后使用Tanh激活函数)。 接下来,在最后一层,进行1x1卷积(使用Sigmoid激活函数)以获得输出平面图像。 请注意,由于每次卷积会损失边界像素,因此在级联期间修剪特征图至关重要。 选择亚当作为随机优化方法。
通常,体系结构是卷积+池化层的序列,可降低图像的空间分辨率,然后通过预先将其与图像数据组合并通过其他卷积层来提高图像的空间分辨率。 因此,网络充当一种过滤器。 [2]
测试样本由相似的图像组成,不同之处仅在于噪声纹理和文本。 网络测试在此图像上进行。

在卷积神经网络的输出处,获得大小为[16,112,112,1]的数字数组。 每个数字都是由网络处理的单独像素。 图像的格式为112x112像素,与以前一样,它被切成碎片。 她需要出卖原来的外表。 我们将获得的图像合并为一个部分,因此图片的格式为448x448。 接下来,我们将数组中的每个数字乘以255,以获得从0到255的范围,其中0为黑色,255为白色。 和以前一样,我们将图像恢复为原始大小。 结果如下图所示。

在此示例中,可以看到卷积网络可以应对大部分噪声,并证明是高效的。 但是可以清楚地看到,图片变得更阴暗,看不见杂音。 将来,这可能会影响文本识别的准确性。
基于这一事实,决定使用另一个神经网络-多层感知器。 在预期的结果中,网络应使图像中的文本更清晰,并消除卷积神经网络中缺少的噪声。
卷积网络已经处理过的图像被发送到多层感知器的输入。 在这种情况下,此网络的训练样本将与卷积网络的样本不同,因为网络对图像的处理方式不同。 卷积网络被认为是主要网络,可去除图像中的大部分噪声,而多层感知器则处理卷积失败的内容。
以下是多层感知器训练集中的一些示例。

通过使用多层感知器处理卷积网络的训练样本获得图像数据。 同时,感知器是在相同的样本上训练的,但样本数量较少且时代较短。
对于感知器训练,处理了36张图像。 网络是逐像素训练的,即图像中的一个像素被发送到网络输入。 在网络的输出处,我们还获得了一个输出神经元-一个像素,即网络响应。 为了提高处理的准确性,制作了29个输入神经元。 在由卷积网络处理后获得的图像上,叠加了28个滤镜。 结果是使用不同滤镜的29张图像。 我们将每29个图像中的一个像素发送到网络输入,而在网络输出处仅接收一个像素,即网络响应。
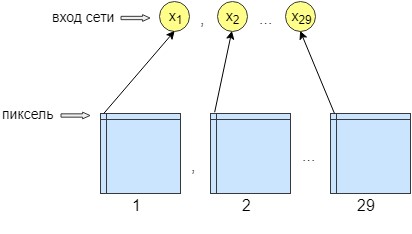
这样做是为了更好地进行培训和建立网络。 此后,网络开始提高图像的准确性和对比度。 它还清除了无法清除卷积网络的小错误。
结果,神经网络有29个输入神经元,每个图像一个像素。 经过实验,发现只需要一个隐藏层,其中有500个神经元。 网络只有一种出路。 由于训练是逐像素进行的,因此该网络被访问了n * m次,其中n是图像宽度,m是高度。

通过两个神经网络对图像进行顺序处理后,剩下的主要工作就是识别文本。 为此,采用了现成的解决方案,即Python库Pytesseract。 Pytesseract没有提供真正的Python绑定。 而是,它是tesseract二进制文件的简单包装。 在这种情况下,tesseract将单独安装在计算机上。 Pytesseract将映像保存到磁盘上的临时文件中,然后调用tesseract二进制文件并将结果写入文件中。
这个包装器是由Google开发的,免费且免费。 它既可以单独使用也可以用于商业目的。 该库无需互联网连接即可工作,支持多种语言进行识别并以其快速的速度给人留下深刻的印象。 它的应用程序可以在各种流行的应用程序中找到。
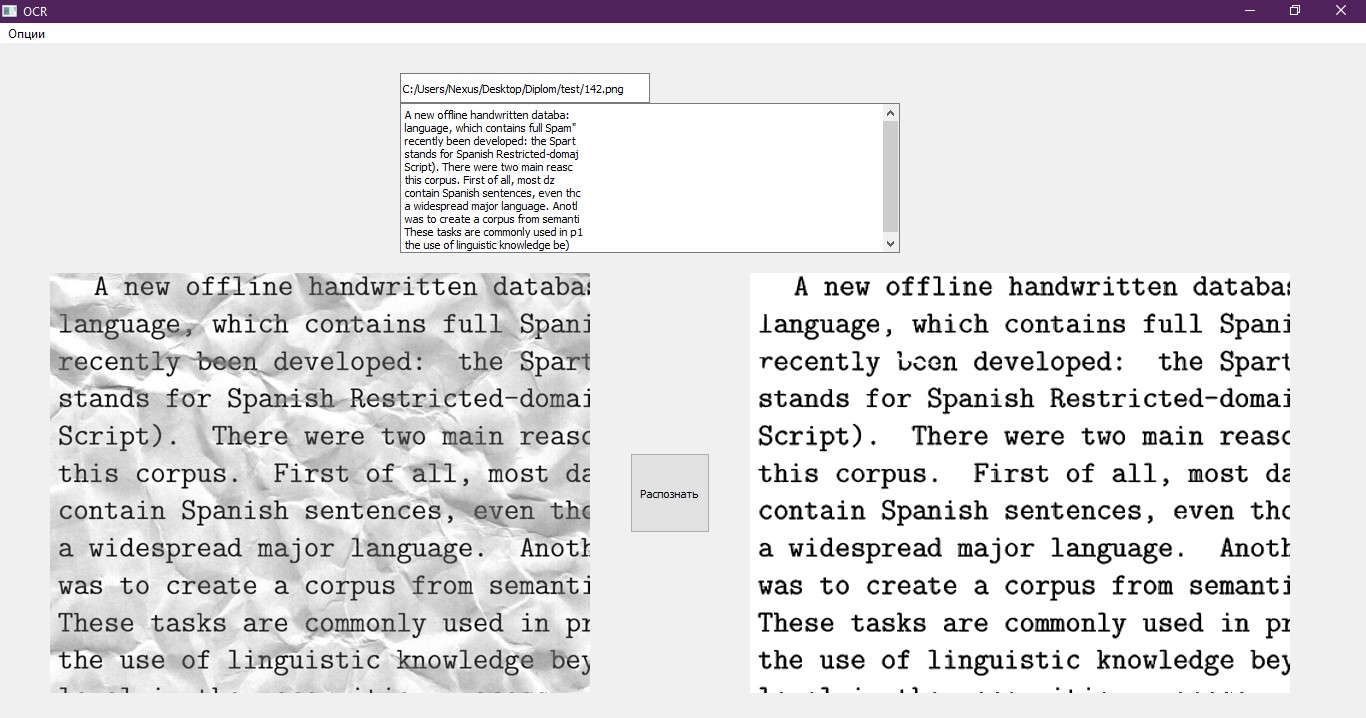
剩下的最后一项是将识别的文本以适合于处理文本的格式写入文件。 为此,我们使用普通笔记本,该笔记本在程序完成后会打开。 此外,文本将显示在测试界面上。 接口的一个很好的例子。
参考文献:
- SmartEngines团队[电子资源]在国际文档识别竞赛中的胜利故事。 访问模式: https : //habr.com/company/smartengines/blog/344550/
- 使用神经网络进行图像分割:U-Net [电子资源]。 访问模式: http : //robocraft.ru/blog/machinelearning/3671.html
> Github存储库