
大家好!
继续研究
深度 学习这一主题,我们曾经想与您谈谈
为什么绵羊似乎在神经网络中无处不在 。 在Francois Scholl的书的第9章中
讨论了这个主题。
因此,我们进行了
哈布雷(Habré)上关于“积极技术”的精彩研究,以及两位麻省理工学院员工的出色工作,他们认为“恶意机器学习”不仅是障碍和问题,而且是一种出色的诊断工具。
下一步-切下。
在过去的几年中,恶意干扰案例在深度学习社区中引起了严重的关注。 在本文中,我们将概括地概述这种现象,并讨论它如何适合更广泛的机器学习可靠性上下文。
恶意干预:一种有趣的现象为了概述我们的讨论范围,我们列举了一些此类恶意干扰的示例。 我们认为,莫斯科地区的大多数研究人员都遇到过类似的照片:
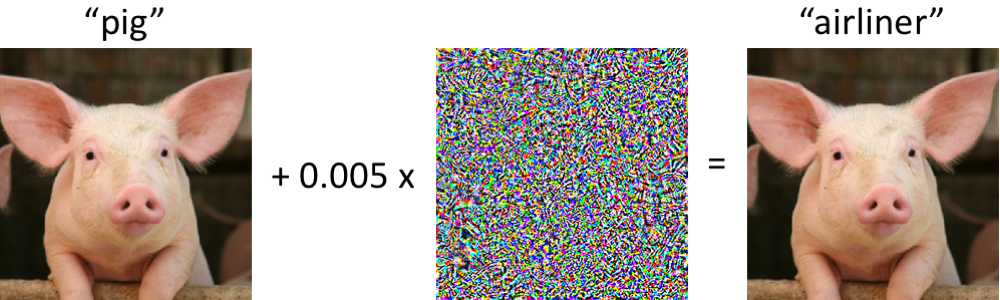
左侧是一头小猪,已被现代卷积神经网络正确分类为小猪。 一旦我们对图片进行了最小限度的更改(所有像素都在[0,1]范围内,并且每个像素的更改幅度均不超过0.005),现在网络将以高度可靠性返回“班机”类。 至少从2004年起就对受过训练的分类器进行了此类攻击(
链接 ),有关恶意干扰图像分类器的第一项工作可追溯到2006年(
链接 )。 从2013年左右开始,这种现象开始引起人们的极大关注,当时事实证明神经网络很容易受到这种攻击(请参阅
此处和
此处 )。 从那时起,许多研究人员提出了构建恶意示例的选项,以及增加分类器对此类病理干扰的抵抗力的方法。
但是,重要的是要记住,不必为了观察此类恶意示例而深入神经网络。
恶意软件示例的鲁棒性如何?首先,计算机将小猪与班机混淆的情况也许令人担忧。 但是,应该注意的是,在这种情况下使用的分类器(
Inception-v3网络 )并不像乍看起来那样脆弱。 尽管在尝试对变形的仔猪进行分类时网络可能会出错,但这仅在经过特殊选择的违规情况下才会发生。
网络对相当数量的随机扰动具有更大的抵抗力。 因此,主要问题是,是否是恶意干扰导致了网络的脆弱性。 如果这样的恶意严重取决于对每个输入像素的控制,那么在现实条件下对图像进行分类时,此类恶意样本似乎并不是一个严重的问题。
最近的研究则相反:在特定的物理场景中,可以确保对各种通道效应的扰动的稳定性。 例如,恶意样本可以在常规的办公室打印机上打印,因此通过智能手机的相机拍摄的样本图像
仍未正确分类 。 您还可以制作贴纸,因为这些贴纸会错误地将各种真实场景分类(例如,请参阅
link1 ,
link2和
link3 )。 最后,最近,研究人员在3D打印机上打印了3D乌龟,标准的Inception网络错误地
认为这是步枪的几乎任何视角。
错误的分类攻击准备如何制造这种恶意干扰? 有很多方法,但是优化使我们可以将所有这些方法简化为广义的表示。 如您所知,分类器训练通常被公式化为寻找模型参数
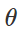
对于给定的一组示例,以最小化经验损失函数

:
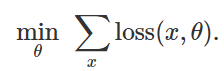
因此,为了引起对固定模型的错误分类
和“无害”输入
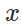
自然地尝试找到有限的干扰

这样的损失

原来是最大的:
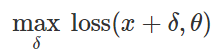
基于此措辞,可以将许多用于创建恶意输入的方法视为针对各种约束集(较小)的各种优化算法(各个梯度步骤,投影梯度下降等)。
-正常干扰,像素变化很小等)。 以下文章中提供了许多示例:
link1 ,
link2 ,
link3 ,
link4和
link5 。
如上所述,用于生成恶意样本的许多成功方法都可以与固定的目标分类器一起使用。 因此,重要的问题是:这些干扰是否仅影响特定的目标模型? 有趣的是,没有。 当使用许多扰动方法时,将得到的恶意样本从分类器传输到使用不同的一组初始随机值(随机种子)或不同的模型体系结构训练的分类器。 此外,您可以创建仅对目标模型具有有限访问权限的恶意样本(有时在这种情况下,它们谈论的是“黑匣子攻击”)。 例如,请参阅以下五篇文章:
link1 ,
link2 ,
link3 ,
link4和
link5 。
不只是图片不仅在图像分类中发现恶意样本。 在
语音识别 ,
问答系统 ,
强化学习和解决其他问题中也已知类似现象。 如您所知,对恶意样本的研究已经进行了十多年:
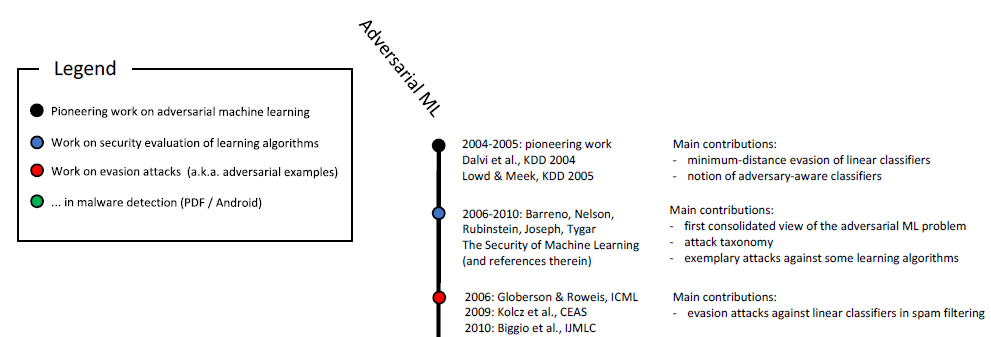
恶意机器学习的时间顺序规模(开始)。 完整比例如图2所示。
本研究 6。
此外,与安全相关的应用程序是研究机器学习的恶意方面的自然媒介。 如果攻击者可以欺骗分类器并将恶意输入(例如,垃圾邮件或病毒)传递为无害的,那么基于机器学习的垃圾邮件检测器或防病毒扫描程序将
无效 。 应该强调的是,这些考虑并非纯粹是学术性的。 例如,早在2011年,Google安全浏览团队发布了
一项针对攻击者如何规避其恶意软件检测系统
的多年研究报告 。 另请参阅有关GMail邮件中垃圾邮件过滤环境中的恶意样本的本文。
不仅安全很明显,所有关于恶意样本研究的最新工作都是确保安全性的关键。 这是一个合理的观点,但我们认为应在更广泛的范围内考虑此类样本。
可靠度首先,恶意样本提出了整个系统可靠性的问题。 在从安全性角度合理讨论分类器的属性之前,必须确保该机制提供较高的分类精度。 最后,如果我们要在实际场景中部署训练有素的模型,那么在更改基础数据的分布时必须证明它们具有高度的可靠性-无论这些更改是由于恶意干扰还是自然波动引起的。
在这种情况下,恶意软件样本是评估机器学习系统可靠性的有用诊断工具。 尤其是,基于恶意软件的方法使您可以超越标准评估协议,在受评估的分类器上运行的分类器是经过精心选择(通常是静态)的测试集。
因此,您可以得出惊人的结论。 例如,事实证明,即使不求助于复杂的优化方法,也可以轻松创建恶意样本。 在
最近的一篇论文中,我们显示出尖端的图像分类器出乎意料地容易受到小的病理转变或转折的影响。 (有关此主题的其他作品,请参见
此处和
此处 。)

因此,即使我们不重视,∞ℓ∞放电引起的扰动,也经常会出现由于旋转和跃迁引起的可靠性问题。 从广义上讲,有必要先了解我们分类器的可靠性指标,然后才能将它们作为真正可靠的组件集成到更大的系统中。
分类器的概念要了解训练有素的分类器是如何工作的,您需要查找其明显成功或不成功的操作的示例。 在这种情况下,恶意样本说明受过训练的神经网络通常不符合我们对“学习”特定概念意味着什么的直观理解。 这在深度学习中尤为重要,因为在深度学习中,人们通常认为其成功程度不亚于人类成功的生物学上合理的算法和网络(例如,参见
此处 ,
此处或
此处 )。 恶意样本显然在许多情况下对此表示怀疑:
- 在对图像进行分类时,如果最小程度地改变像素集或稍微旋转图片,则很难防止有人将其分配给正确的类别。 但是,最现代的分类器完全无法实现此类更改。 如果将对象放置在不寻常的地方(例如, 绵羊放在树上 ),也很容易确保神经网络对场景的解释与人类截然不同。
- 如果您在文本段落中替换必要的单词,则可能会严重混淆问答系统 ,尽管从人的角度来看,文本的含义不会因插入而改变。
- 在本文中 ,精心选择的文本示例显示了Google Translate的局限性。
在这三种情况下,恶意示例均有助于测试我们当前的模型的强度,并强调这些模型在哪种情况下的行为与人的行为完全不同。
安全性最后,恶意样本的确在机器学习已经对“无害”材料实现一定准确性的领域中带来了危险。 就在几年前,诸如图像分类之类的任务仍然执行得很差,因此在这种情况下,安全问题似乎是次要的。 最后,只有当机器学习系统开始以足够的质量处理“无害”输入时,机器学习系统的安全性才变得重要。 否则,我们仍然不能相信她的预测。
现在,在各个主题领域中,此类分类器的准确性已得到显着提高,并且在安全考虑很关键的情况下部署它们只是时间问题。 如果我们想以负责任的方式进行处理,则必须在安全性背景下准确研究其属性,这一点很重要。 但是安全问题需要整体的方法。 伪造某些特征(例如,一组像素)比其他感觉模态,分类特征或元数据要容易得多。 最后,在确保安全性时,最好精确地依靠那些难以改变甚至几乎不可能改变的标志。
结果(失败为时过早吗?)尽管近年来我们在机器学习方面取得了令人瞩目的进步,但是有必要考虑到我们所拥有的工具功能的局限性。 存在各种各样的问题(例如与诚实,隐私或反馈影响有关的问题),可靠性是最重要的问题。 人类的感知和认知可以抵抗各种背景环境干扰。 但是,恶意样本表明,神经网络距离可比的弹性还很远。
因此,我们确信研究恶意示例的重要性。 它们在机器学习中的适用性不仅限于安全性问题,还可以作为评估训练模型的
诊断标准 。 使用恶意样本的方法与标准评估程序和静态测试相比,具有优势,因为它可以识别潜在的明显缺陷。 如果我们想了解现代机器学习的可靠性,那么从攻击者的角度进行研究(正确选择恶意样本)就很重要。
只要我们的分类器失败,即使训练和测试分布之间的变化很小,我们也无法获得令人满意的保证可靠性。 最后,我们努力创建不仅可靠而且与我们对“研究”问题意味着什么的直觉想法相一致的模型。 然后,它们将是安全,可靠并且易于在各种环境中部署的。