大家好!
在写了
第一部分之后,我的良心就把我吞没了。 我决定结束我的工作。 也就是说,选择相同的神经网络实现以在Rasperry Pi Zero W上实时运行(当然,尽可能在此类硬件上运行)。 驱使她了解现实生活中的数据,并在Habré上阐明结果。
注意事项 与第一部分相比,有一个可行的代码,并且裁减的猫更多。 在图片中,婴儿床和鳕鱼分别。
选择什么网络?
我记得由于覆盆子铁的弱点,神经网络实现的选择很小。 即:
1. SqueezeNet。
2. YOLOv3 Tiny。
3. MobileNet。
4. ShuffleNet。
在
第一部分中选择SqueezeNet的选择有多正确?..在您的硬件上运行上述每个神经网络是一个漫长的过程。 因此,由于含糊的疑问,我决定谷歌搜索是否有人在我面前问过这样的问题。 原来,他想知道并进行了详细调查。 那些希望的人可以参考
消息来源 。 我将仅限于一张照片:
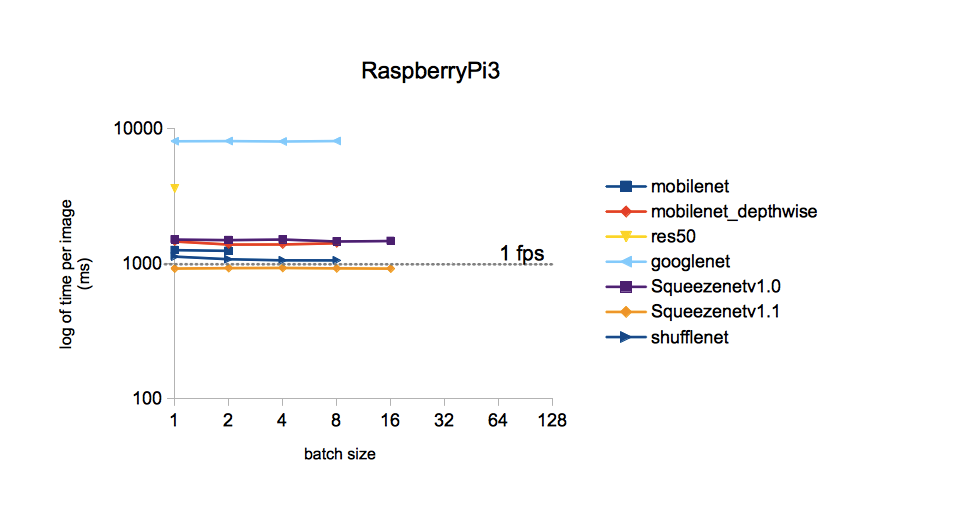
从图片可以看出,使用SqueezeNet v.1.1,在ImageNet数据集上训练的不同模型对一张图像的处理时间最少。 我们将以此为行动指南。 YOLOv3没有包含在比较中,但是据我所知,YOLO比MobileNet贵。 即 它的速度也应不如SqueezeNet。
所选网络的实施
可在
GitHub上找到在ImageNet数据集(Caffe框架)上训练的SqueezeNet的权重和拓扑。 以防万一,我下载了两个版本,以便以后可以进行比较。 为什么选择ImageNet? 这组所有可用的类具有最大数量的类(1000个),因此神经网络的结果很有意思。
这次,我们将了解Raspberry Zero如何处理相机的帧识别。 在这里,他是我们今天工作的谦卑勤奋工作者:

我将
第一部分提到的Adrian Rosebrock博客的源代码作为代码的基础,即
从此处 。 但我必须大力耕种:
1.用SqueezeNet上的MobileNetSSD替换您的模型。
2.条款1的实施导致将类别数扩展到1000。但是,与此同时,消除了用多色框架突出显示对象的功能(SSD功能)。
3.通过命令行删除对参数的接收(由于某种原因,这样的参数输入会困扰我)。
4.删除VideoStream方法,并删除Adrian钟爱的imutils库。 最初,该方法用于从摄像机获取视频流。 但是,当我将相机连接到Raspberry Zero时,它却无法正常工作,发出了“非法指令”之类的信息。
5.将帧频(FPS)添加到识别的图片,重写FPS计算。
6.进行保存以撰写此帖子。
在具有Rapbian Stretch OS,树莓派(Python 3.5.3)并通过pip3安装的树莓派上安装OpenCV 3.4.1,结果如下所示并开始运行:
在这里编码import picamera from picamera.array import PiRGBArray import numpy as np import time from time import sleep import datetime as dt import cv2
结果
该代码显示在连接到Raspberry的显示器的屏幕上,此形式是下一个可识别的帧。 在框架的顶部,仅显示最可能的类别。

因此,计算机鼠标被确定为具有很高概率的鼠标。 同时,图像以0.34 FPS的频率更新(即大约每三秒钟更新一次)。 握住相机并等待下一帧处理会有些烦人,但是您可以活下来。 顺便说一句,如果您删除SD卡上的保存帧,处理速度将提高到0.37 ... 0.38 FPS。 当然,还有其他分散方法。 我们将拭目以待,无论如何,我们将把这个问题留在以后的文章中。
另外,我对白平衡表示歉意。 事实是,打开了背光灯的红外摄像机已连接到Rapberry,因此大多数帧看起来都有些奇怪。 但是神经网络的每次点击都更有价值。 显然,训练集上的白平衡更为正确。 另外,我决定只插入原始框架,以便读者看到它们的方式大致与看神经网络相同。
首先,让我们比较SqueezeNet版本1.0(在左框架)和1.1(在右框架)的工作:

可以看出,1.1版的工作速度比1.0快两倍四分之一(0.34 FPS对0.15)。 速度增益明显。 在此示例中,不值得对识别精度做出结论,因为该精度很大程度上取决于相机相对于物体的位置,照明,眩光,阴影等。
鉴于将来v1.1将比v.1.0具有如此显着的速度优势,因此仅使用了SqueezeNet v.1.1。 为了评估模型的性能,我将相机对准了即将
出现的各种物体,并在输出端收到了以下帧:

键盘比鼠标差。 也许在培训中,大多数键盘是白色的。

如果打开屏幕,则手机的定义非常好。 屏幕关闭的单元格不会将神经网络视为单元格。

一个空杯子完全可以被定义为咖啡杯。 到目前为止,一切进展顺利。

剪刀的状况更糟;它们被网子顽固地定义为发夹。 但是,如果不是靶心,进入苹果树)
让任务复杂化
让我们尝试对
猪的神经网络进行一些棘手的工作。 我刚遇到一个自制的儿童玩具。 我相信大多数读者都将其视为玩具猫。 我想知道我们的基础人工智能将如何考虑它。
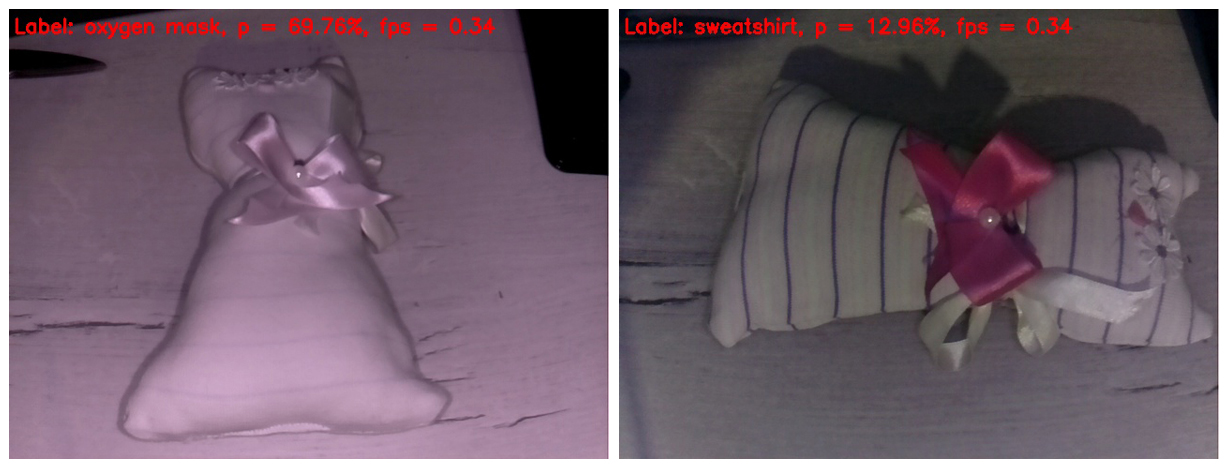
在左侧的框架中,红外光擦除了织物上的所有条带。 结果,该玩具被定义为氧气面罩的概率相当高。 为什么不呢 玩具的形状确实类似于氧气面罩。
在右边的框架中,我用IR高光遮住了手指,因此条纹出现在玩具上,并且白平衡变得更加可信。 实际上,这是本文中看起来或多或少正常的唯一框架。 但是神经网络在图像中具有如此丰富的细节。 她将玩具确定为运动衫。 我必须说,这看起来也不像是“空中的手指”。 如果不在“苹果树”中,请点击,然后至少在苹果园中)。
好吧,我们顺利地达到了行动的高潮。 在
第一篇文章中详细介绍的战斗中杰出的胜利者进入了比赛。 从一开始,它就很容易将我们的神经网络的大脑取出来。

奇怪的是,一只猫实际上不会改变其位置,但是每次确定它的位置都是不同的。 从这个角度来看,它最像是臭鼬。 其次是与仓鼠的相似之处。 让我们尝试更改角度。

是的,如果您从上方拍摄猫的照片,则可以正确确定它的位置,但是如果只是稍微改变猫的身体在框架中的位置,对于神经网络来说,它就变成了一只狗-西伯利亚雪橇犬和雪橇犬(爱斯基摩雪橇犬)。

这种选择很漂亮,因为在猫的每个单独的框架上都定义了不同品种的狗。 和品种不重复)

顺便说一下,在神经网络的姿势中,很明显这仍然是猫,而不是狗。 也就是说,即使在难以分析的对象上,SqueezeNet v.1.1仍然可以证明自己。 假设神经网络在测试开始时就成功地识别了物体,并在结束时将猫识别为猫,则成功了,这一次我们宣布了坚实的战斗力)
好,仅此而已。 我邀请大家在他们的树莓派和任何有生命和无生命的对象视图中尝试建议的代码。 我特别感谢那些在Rapberry Pi B +上测量FPS的人。 我保证会在本文中引用发送数据的人的结果。 我相信结果应该超过1 FPS!
我希望这篇文章中的某些信息对娱乐或教育目的有用,甚至有人会提出新的想法。
一周工作愉快! 待会见)

UPD1:在Raspberry Pi 3B +上,上面的脚本以2的频率和较小的FPS起作用。
UPD2:在具有Movidius NCS的RPi 3B +上,脚本以6 FPS运行。