嗨%用户名%!
最近,Highload ++会议结束了(再次感谢组织者和
olegbunin的整个团队。这真是太酷了!)。
在会议前夕,阿列克谢·
费舍尔 (Alexey
fisher)建议在会议上创建一个由“缠扰者”组成的主动小组。 在报告期间,我们写了一些小笔记,以供交流。 一些注释被证明是非常详细和详尽的。
社交网络中的社区积极评价了这种格式,因此我(在获得许可的情况下)决定发布第一份报告的摘要。 如果这种格式很有趣,那么我可以再准备几篇文章。

驾驶
Avito有很多服务,它们之间有很多连接。 这会导致问题:
- 很多存储库。 很难一次到处更改代码
- 团队受其上下文的限制。 最大重叠略有重叠
- 添加了数据碎片。
大量的基础架构元素:
- 记录中
- 请求跟踪(Jaeger)
- 错误汇总(哨兵)
- Kubernetes的状态/消息/事件
- 竞赛极限/断路器(Hystrix)
- 服务连接性(Istio)
- 监控(Grafana)
- 大会(团队)
- 沟通交流
- 任务追踪器
- 该文件
- ...
有许多层;该报告仅描述了一层(PaaS)。
该平台包括3个主要部分:
- cli控制的发电机
- 聚集器(收集器),通过仪表板进行控制
- 带有某些动作触发器的存储。
标准微服务开发管道
CLI推送-> CI->烘焙->部署->测试-> Canary->生产CLI推
长期教导做正确的开发人员。 尽管如此,它仍然是一个弱点。
通过cli实用程序自动化,可帮助创建微服务基础:
- 创建模板服务(支持多个PL的模板)。
- 自动部署基础架构以进行本地开发
- 连接数据库(不需要配置,开发人员不会考虑访问任何数据库)。
- 现场制作
- 自动测试光盘生成。
该配置在toml文件中描述。
示例文件:
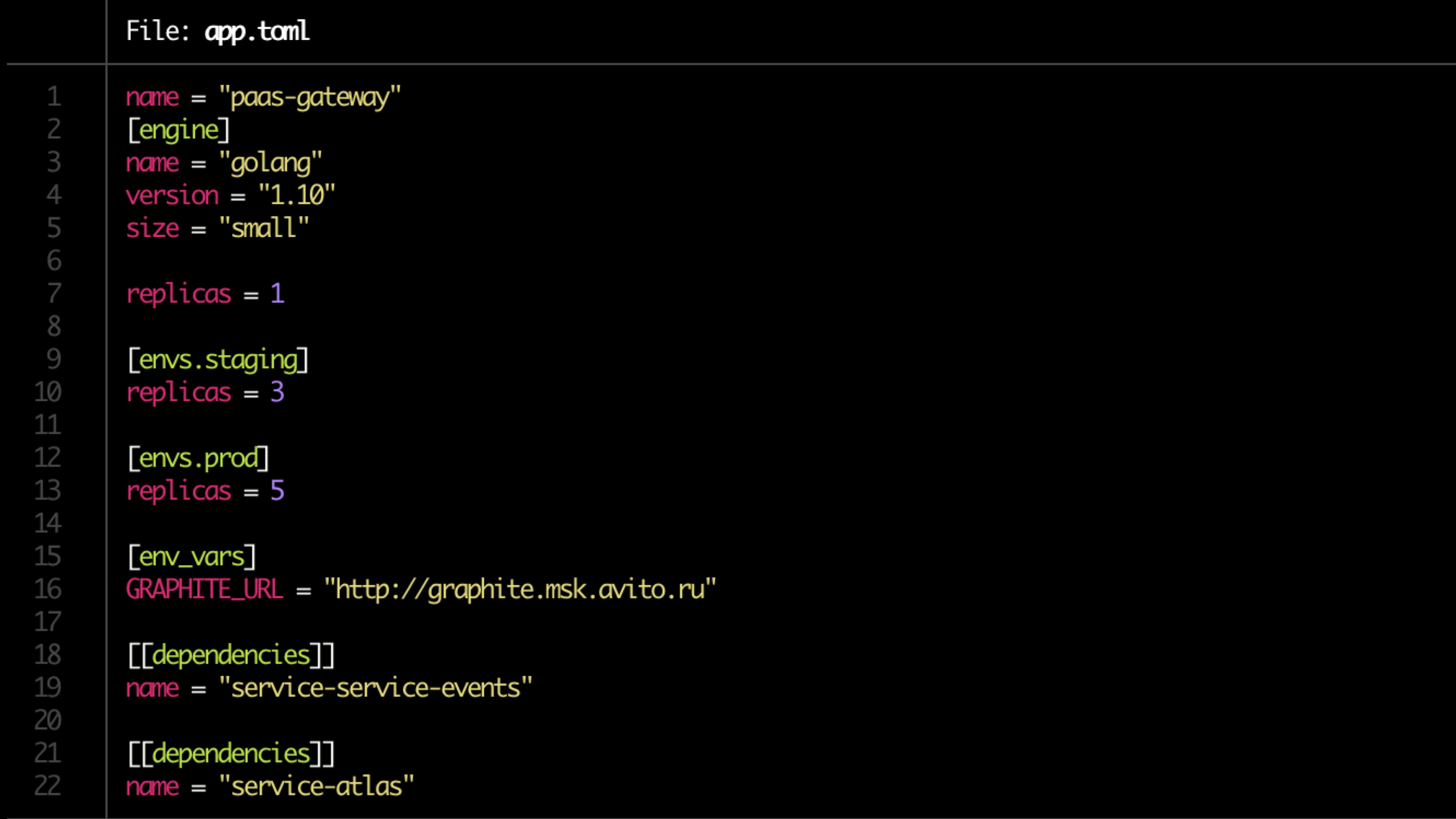
验证方式
基本验证检查:
- Dockerfile的可用性
- app.toml
- 文件的提供
- 依存关系
- 用于监视的警报规则(由服务所有者设置)
该文件
每个人都应该有文件,但几乎没有人有
该文档应包括:
- 服务描述(简短)
- 链接到架构图
- Runbook
- 常见问题
- 端点API说明
- 标签(绑定到产品,功能,结构划分)
- 服务的所有者(可能有多个,在大多数情况下可以自动确定)。
文档需要审查。
管道准备
- 烹饪库
- 在TeamCity中建立管道
- 我们设定权利
- 我们正在寻找所有者(两个,一个不可靠)
- 在Atlas中注册服务(内部产品)
- 检查迁移。
烤
- 在Docker映像中构建应用程序。
- 为服务本身和相关资源(数据库,缓存)生成头盔图表
- 创建票证供管理员打开端口,并考虑了内存和cpu限制。
- 运行单元测试。 代码覆盖率得到维护。 如果低于某个确定,则部署结束。 如果覆盖范围没有进展,则推送通知。
所有者搜索由推送决定(推送的次数和其中的代码量)。
如果存在潜在的危险迁移(更改),则在Atlas中注册触发器,并隔离服务。
通过推送给所有者解决隔离(在手动模式下?)
约定检查
我们检查:
- 服务端点
- 符合计划答案
- 日志格式
- 设置标头(包括在向总线发送消息以跟踪通过总线的连接时的X-Source-ID)
测验
测试是在闭环中执行的(例如hoverfly.io)-记录了典型负载。 然后在闭环中对其进行仿真。
检查资源消耗的对应关系(我们在极端情况下单独查看-资源太少/太多),被rps切断。
负载测试还显示了版本之间的性能差异。
金丝雀测试
我们仅在极少数用户(<0.1%)上启动发布。
最小负荷5分钟。 主2小时。 如果一切正常,那么用户数量就会增加。
我们看:
- 产品指标(首先)-其中有很多(100500)
- 哨兵错误
- 响应状态
- 受访者时间-准确和平均的响应时间
- 延迟时间
- 异常(已处理和未处理)
- 更特定于公制语言(例如php-fpm worker)
挤压测试
挤压测试。
我们将实际用户1个实例加载到故障点。 我们看它的天花板。 接下来,添加另一个实例并加载它。 我们看下一个天花板。 我们来看回归。 我们丰富或替换了Atlas中负载测试的数据。
缩放比例
只有cpu不好,您需要添加产品指标。
最终方案:
扩展时,请不要忘记查看服务依赖性。 记住缩放级联(+1级)。 我们查看初始化服务的历史数据。
选配
- 触发器处理-如果在X之下还没有版本,则进行迁移
- 服务很长时间没有更新
- 隔离区
- 安全更新
仪表板
我们以汇总的形式从上方查看所有内容并得出结论。
- 服务和标签过滤
- 与跟踪,记录,监视集成
- 单点服务文档
- 单点显示所有服务事件
一个例子:
