弗拉基米尔·伊万诺夫(Vladimir Ivanov) NVIDIA的深度学习工程师继续谈论强化学习。 本文将着重于培训代理以完成任务以及神经网络如何使用过滤器识别图像。
在
上一篇文章中,讨论了针对简单射手的特工训练。
弗拉基米尔(Vladimir)将在11月22日的
AI会议上讨论强化学习在实践中的应用。
上次我们看电子游戏的例子时,加强训练有助于解决问题。 奇怪的是,对于神经网络的成功发挥,只需要视觉信息。 每四帧神经网络都会分析屏幕截图并做出决定。
乍一看,它看起来像魔术。 某个复杂的结构(即神经网络)在输入端接收图片并发出正确的解决方案。 让我们弄清楚里面发生了什么:是什么将一组像素变为行动?
在继续使用计算机之前,让我们弄清楚一个人看到的东西。当一个人看着图像时,他的目光紧紧抓住了小细节(面部,人物,树木)以及整个图片。 无论是在巷子里玩游戏还是足球比赛,一个人都可以根据自己的生活经历来了解图片的内容,心情和背景。

当我们欣赏美术馆主人的作品时,我们的生活经验仍然告诉我们,人物被隐藏在油漆层后面。 您可以在图片中猜测他们的意图和动作。

对于抽象绘画,眼睛会在图像中找到简单的图形:圆形,三角形,正方形。 它们更容易找到。 有时,这就是所有可见的内容。

可以安排项目,使图片呈现出意外的色调。

也就是说,我们可以从图片的特定组成部分中抽象出一个整体。 与我们不同,计算机最初不具备此功能。 我们有丰富的生活经验,可以告诉我们哪些项目很重要以及它们具有哪些物理特性。 让我们考虑一下如何为机器配备工具,以便它可以研究图像。
在将照片从手机发布到社交网络之前,许多使用高品质相机的手机的快乐所有者会对其施加各种过滤器。 使用滤镜,您可以更改照片的气氛。 您可以更清楚地突出显示某些对象。
此外,滤镜可以突出显示照片中对象的边缘。
由于滤镜具有突出显示图像上不同对象的能力,因此让计算机有机会拾取它们。 什么是数字图像? 这是一个数字方阵,在每个点上都有三个颜色通道的强度值:红色,绿色和蓝色。 现在我们将给出神经网络,例如32个过滤器。 每个滤镜依次叠加在图像上。 滤波器核心应用于相邻像素。
最初,每个过滤器的核心值都是随机的。 但是我们将赋予神经网络根据任务配置它们的能力。 在具有过滤器的第一层之后,我们可以再添加一些。 由于我们有很多过滤器,因此需要大量数据来设置它们。 为此,一些较大的标记图片是合适的。 例如,MSCoco数据集。

神经网络将调整权重以解决此问题。 在我们的情况下,对于图像分割,即每个图像像素的类别的定义。 现在,让我们看看在每层滤镜之后图像的外观。
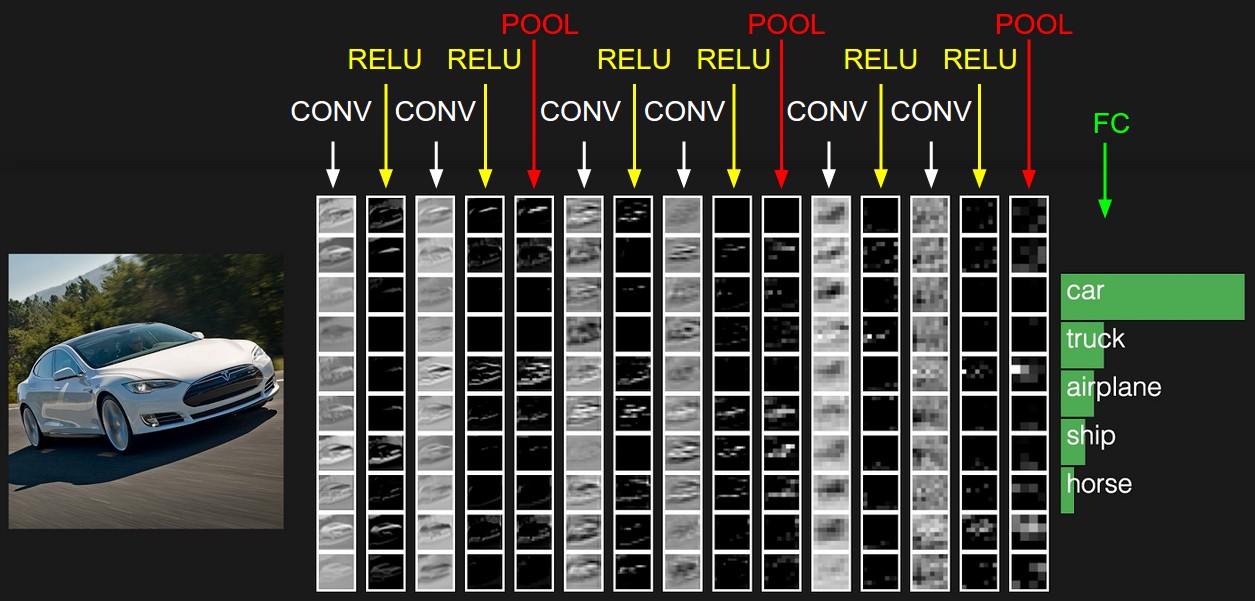
如果仔细观察,您会发现过滤器在某种程度上会离开汽车,并清洁周围区域-道路,树木和天空。
回到学习玩游戏的代理商。 例如,以Mario Kart赛车游戏为例。
我们为他提供了强大的图像分析工具-神经网络。 让我们看看他为学习如何骑行而选择的过滤器。 让我们为初学者准备一个开放区域。
让我们看一下前24部电影后的图像。 在这里,它们以8x3表格的形式放置。
完全可选的是,24个输出中的每一个都有明显的含义,因为图片使用以下过滤器可以更进一步到达入口。 依赖关系可以完全不同。 但是,在这种情况下,您可以在输出中找到一些逻辑。 例如,第一行中的第二个滤镜以黑色突出显示道路。 第七行的第一个过滤器复制了它的功能。 在其他大多数过滤器上,我们控制的卡片清晰可见。
在这个游戏中,周围地区发生变化,隧道相遇。 赛车神经网络遇到隧道入口时应注意什么?
第一层过滤器的输出:
在第六行中,第一个过滤器突出显示隧道的入口。 因此,在行驶过程中,网络学会了识别它们。
当机器进入隧道时会发生什么?
前24个过滤器的结果:
尽管场景的照明以及环境已经发生变化,但神经网络仍捕获最重要的东西-道路和地图。 再次,第一行中的第二个过滤器保留了其功能,该第二个过滤器负责在隧道中寻找空旷的路径。 同样,第七行的第一个过滤器也像以前一样找到了出路。
既然我们已经弄清楚了神经网络所看到的东西,让我们尝试使用它来解决更复杂的问题。 在此之前,我们考虑了您实际上不需要提前思考的任务,但是您需要解决当前面临的问题。 在射击游戏和比赛中,您需要“自觉地”采取行动,快速应对游戏中的突然变化。 如何完成任务游戏? 例如,游戏“蒙特祖玛复仇”,您需要找到钥匙并打开上锁的门才能离开金字塔。

上次我们讨论代理不会学习寻找新的钥匙和门,因为这些动作需要花费大量的游戏时间,因此以点数形式发出的信号将非常罕见。 如果您使用点数击败被打败的敌人作为对特工的奖励,他将不断击倒滚动的头骨并且不会寻找新的动作。
让我们奖励开新房的经纪人。 我们将使用先验已知的事实,即这是一项任务,并且其中的所有房间都不同。

因此,如果屏幕上的图像与我们之前看到的图像根本不同,则代理商将获得奖励。
在此之前,我们考虑过在训练过程中完全依赖视觉数据的游戏代理商。 但是,如果我们可以访问游戏中的其他数据,我们也会使用它们。 例如,考虑点游戏。 在这里,网络在入口处收到2万个数字,这些数字完全描述了游戏的状态。 例如,盟友的位置,塔楼的健康状况。

玩家分为两队,每队五人。 一场比赛平均持续40分钟。 每个玩家选择一个具有独特能力的英雄。 每个玩家都可以购买改变伤害,速度和视野参数的物品。
尽管乍一看游戏与《毁灭战士》有很大不同,但学习过程仍然相同。 除了几点。 由于此游戏中的计划范围比《毁灭战士》中的要高,因此我们将处理最后16帧进行决策。 代理商收到的奖励信号会更加复杂。 它包括被击败的敌人的数量,造成的伤害以及在游戏中赚到的钱。 为了使神经网络共同发挥作用,我们将包括代理商团队成员的福利作为奖励。
结果,机器人团队
击败了实力强大的团队,但输给了冠军。 失败的原因是机器人很少玩一个小时的比赛。 与真人玩的游戏比在模拟器上玩的游戏持续时间更长。 也就是说,如果一个特工发现自己处于未经训练的境地,他就会开始出现困难。