我想谈谈我们在基于Apache Solr全文搜索平台开发应用程序方面的经验。
我们的任务是为联络中心开发语音分析系统。 该系统基于两种基本技术:语音识别和索引搜索。 为了识别,我们使用了引擎,对于索引和搜索,我们选择了Solr。
为什么选择Solr? 我们没有进行索引搜索引擎的比较研究,而是仔细研究
了同事的
意见 。 当然,可以选择使用Elasticsearch或Sphinx,但是显然,我们项目中的明星是支持Solr的,所以我们“锯”了一下。 在项目进行过程中,我们已经确定Solr中可用的设置足以配置我们的任务。
我们项目的特点
该系统是为分析客户呼叫而开发的,记录在联系中心以监控服务质量。 它不分析声音,而是分析由于自动识别对话而获得的文本。 公认的语音文本与我们在网站或电子邮件上经常遇到的文本有根本的不同。 即使具有100%的识别准确度,被识别的自发语音文本也似乎没有任何意义。
这是由于两个主要因素。 首先,在口头演讲中,非语言和面部表情经常被使用,虽然在文本中没有被识别,但是对于理解已经说过的话很重要。 其次,在语音中,经常使用语言结构的缩写和省略,这可以从交际情况的上下文中恢复。 语言学中的这种现象称为省略号。
要用自己的眼睛查看已识别语音的文本及其所有功能,请在关闭声音的情况下查看youtube上视频的自动字幕。 就是关于这个内容,材料进入语音分析系统的输入。
复杂查询
尽管Solr支持标准
条件语句和
分组 ,但是这些功能通常不足以为分析师实现所有方案。
通常,分析人员需要使用Solr索引中未包含的参数来构建查询。 例如,找到对话的最后30秒钟说出的所有单词“谢谢”。 单词由Solr索引,但没有临时的单词位置。 我们将此类查询称为“复杂”查询-包含Solr索引的参数以及Solr索引中未包含的任何其他数据选择参数的查询。
分析师如何查询?
分析师对Solr索引的组成一无所知,对他来说,搜索并切掉通话的语音图及其文字记录的所有属性非常重要。 因此,分析人员使用“复杂查询”的概念纯粹是实用的:查询中有很多选择参数,或者查询按层次结构排列。
用集合论的语言描述分析师的行为,可以说,借助查询,分析师探索了不同子集之间的关系:交集,差异,加法。 使用分层查询,分析人员将数据数组解析为所需的结构细节级别。
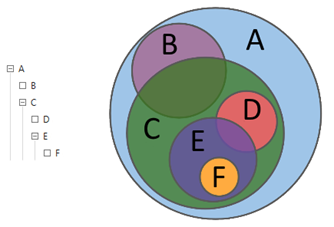 图1.分层查询
图1.分层查询图2显示了同时包含文本和数字选择标准的复杂查询的经典示例。
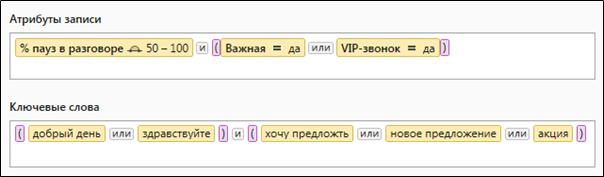 图2.包含定量和词法数据选择参数的复杂查询
图2.包含定量和词法数据选择参数的复杂查询Solr的查询是什么样的?
考虑图1中查询
B的示例在Solr中执行查询的一般机制。如我们所见,查询
B具有父查询
A ,即
B⊆A 。 在语音分析中,当至少一个“父级”未实现时,请求无法实现。 因此,查询
A首先执行,然后才执行
B。 显然,
B必须包含查询
A的条件
。首先想到的是通过
AND合并两个查询的条件,并将其粘贴到
query :
q=key:A AND key:B但是,如果我们仅将所有连续的查询合并为一个
query ,则该
query将很大,每个查询将有所不同,并且将进行整体计算。 同样,条件
A将影响查询
B的结果的相关性,这是不希望的。
让我们尝试将父查询添加为
FilterQuery 。 在这种情况下,查询
A不会受到不相关性的影响,我们可以期望它已经完成并且其结果在缓存中。 因此,Solr将只需要计算查询
B ,而Solr将以我们需要的方式对结果选择进行排序:
q=keyword:B &fq=keyword:A如果我们以示意图方式考虑对Solr的请求格式,则可以区分两个主要实体:
MainQuery具有一组必须满足的参数的主查询。 例如,对礼貌操作员的搜索请求应如下所示: text_operator: ” ” 。
这意味着搜索文档的text_operator字段必须包含短语“ ”
FilterQuery一组限制结果选择的附加过滤器。 FilterQuery格式与MainQuery匹配
将请求分为“
Main和“
Filter ,您可以:
- 明确指出哪些查询参数应影响选择中文档的排名,哪些仅用于结果选择中的选择。 在执行MainQuery查询的一部分时计算构建文档等级的相关性,并在执行FilterQuery查询的一部分时计算不符合查询条件的文档。
- 由于
FilterQuery计算之后获得的结果样本被完全缓存,而MainQuery计算的结果仅存储在50个值中的第一个样本中,因此大大减少了搜索引擎的负载
MainQuery和
FiletrQuery对Solr函数的影响不同。 例如,对于
突出显示 ,负责突出显示相关文档片段的功能,仅
MainQuery ,而
FilterQuery参数不影响
highlighting 。 这是合乎逻辑的,因为相关性是在
MainQuery查询的一部分中精确计算的。 这就是在实际搜索带有“ hello”和“ services”字样的文本时
highlighting结果的样子。
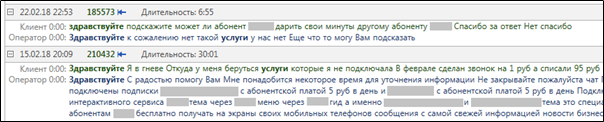 图3.完成
图3.完成MainQuery查询后高亮显示相关单词。
Solr中的复杂查询
让我们回到有礼貌的运算符的示例。 在此示例中,我们通过在话务员语音中出现“下午好”一词来确定适当的通话,但未指出相对于对话开始或结束搜索关键字的时间间隔。
看来,这一切都有必要-电话对话的文字记录包含每个单词的时间戳,以及有关该对话属于哪个参与者的信息。 该数据也可以在搜索中使用。
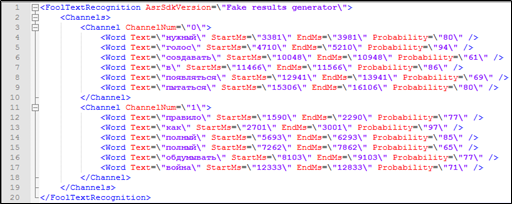 图4. Solr索引中未包含带标记的文本解密片段:说话者的从属关系,时间戳。
图4. Solr索引中未包含带标记的文本解密片段:说话者的从属关系,时间戳。但是,如果查询中涉及不可索引的参数(单词的发音时间),如何处理对Solr的搜索查询?
解决此问题的两种明显方法出现:
- 将未索引的参数添加到Solr索引中。 同时,内存消耗将略有增加,但索引将显着增加
- 通过不可索引的参数选择数据应使用其服务,并且在选择后获得的文档集中,应使用Solr索引进行搜索。 同时,内存消耗将明显大于第一种情况,但是性能是可以预测的
我们选择了第二个选项。 为此,我们开发了一项服务,该服务可以通过包含Solr索引中未包含的任何逻辑和数字参数的请求来计算集合。 由于这项服务的结果,不满足要求的集合部分被标记为特殊标记(“转义”),然后不参与查询结果的计算。
想象一下,我们只想在对话框的前30秒内对我们已经知道的查询
B进行搜索限制。 在第一阶段,我们将
B作为简单查询执行,然后“筛选”超出选定范围的单词,以使它们不属于Solr索引,但是与此同时,我们可以从中恢复原始文档。 结果文档放置在单独的Solr集合中,并在其
上重新开始对查询
B的搜索。
在这里我必须说,对话开始或结束的限制是花朵,浆果是对父请求结果的限制。 考虑执行这样的请求。
想象一下,我们的文档由带数字的球组成。 让我们尝试找到位于“ 5”右侧不超过两个球中的所有“ 6”球。
您已经意识到,球号已包含在Solr索引中,并且球之间没有距离。
|  |
查找带有“ 6”和“ 5”球的所有文档。 作为MainQuery将查询球“ 5”,并将查询“ 6”发送给FilterQuery 。 因此,Solr将在搜索结果中突出显示“ 5”球,这将大大简化下一步的生活。 | 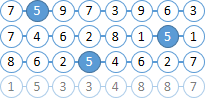 |
| 我们筛选所有与“ 5”相距所需距离的球除外的球。 收到的文件(带有所需球的文件)将被放置在单独的集合中。 |  |
让我们对结果集合中的球“ 6”执行FilterQuery ,结果就是我们要FilterQuery的文档。 |  |
实际上,第5和第6个球通常会隐藏以文本表示形式占据多个屏幕的查询。 我很高兴我们没有白费力气地实现了这种搜索-分析师经常使用带有父级限制的查询。
结论
通过该项目,我们学到了什么,学到了什么以及实现了什么?
我们知道如何有效地使用Solr处理各种类型的数据,我们可以“教导” Solr使用其搜索索引中未包含的参数来处理查询。
我们已经开发了可在高负载下运行的工业语音分析系统:可以为多达500万个文本文档的样本计算出分析人员的复杂搜索查询。 可能还有更多,但没有实际需要。 分析师通常的工作样本是最多可识别50万条已识别的电话文本,而电话总数可达到1500万。
对于联络中心的客户,该系统为性质不同的分析提供了前所未有的机会:主题和请求原因的分析,客户满意度的分析等。
现在,我们正在将新的资源与我们的分析联系起来-客户与运营商的文字聊天。 我们实现了一个应用程序,可用于分析联络中心所有渠道上的客户呼叫:电话,聊天,网站表格等。
我们很乐意回答您的问题。
谢谢啦
PS Solr是一件非常困难的事情,需要进行良好的调整以获得良好的结果。 我们将在以下文章中介绍我们在该领域的经验。